
图像分类模型效果评估
可通过模型评估报告或模型校验了解模型效果:
- 模型评估报告:训练完成后,可以在列表中看到模型效果,以及详细的模型评估报告。
- 模型在线校验:可以在左侧导航中找到【模型校验】,在线校验模型效果。校验功能示意图:
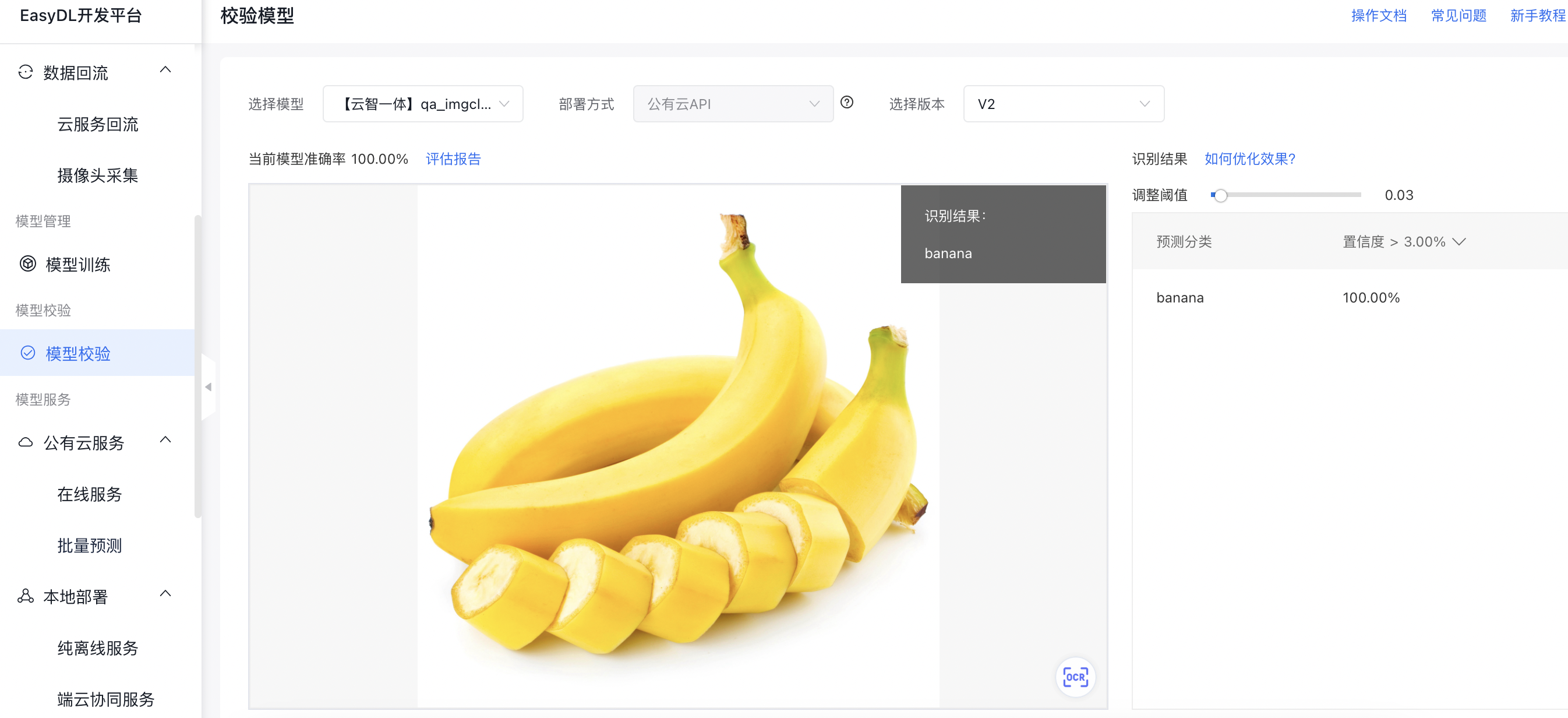
模型评估报告
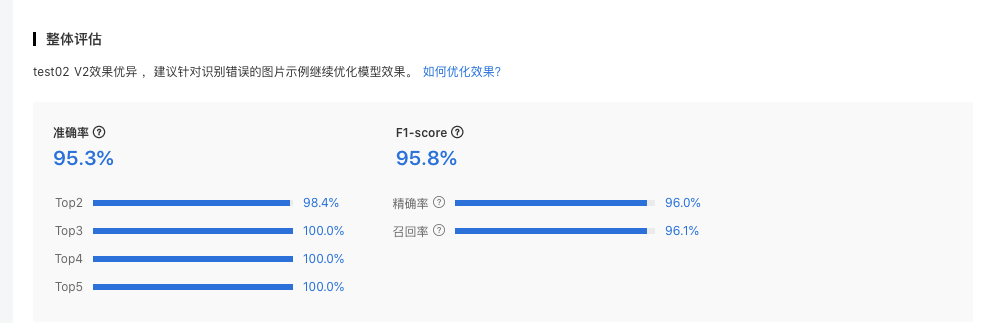
整体评估
在这个部分可以看到模型训练整体的情况说明,包括基本结论、准确率、F1-score等。这部分模型效果的指标是基于训练数据集,随机抽出部分数据不参与训练,仅参与模型效果评估计算得来。所以当数据量较少时(如图片数量低于100个),参与评估的数据可能不超过30个,这样得出的模型评估报告效果仅供参考,无法完全准确体现模型效果。
查看模型评估结果时,需要思考在当前业务场景,更关注精确率与召回率哪个指标。是更希望减少误识别,还是更希望减少漏识别。前者更需要关注精确率的指标,后者更需要关注召回率的指标。同时F1-score可以有效关注精确率和召回率的平衡情况,对于希望准确率与召回率兼具的场景,F1-score越接近1效果越好。评估指标具体的说明如下。
F1-score: 对某类别而言为精确率和召回率的调和平均数,评估报告中指各类别F1-score的平均数
准确率: 基于随机测试集进行计算,为正确分类的样本数与总样本数之比
注意:若想要更充分了解模型效果情况,建议发布模型为API后,通过调用接口批量测试,获取更准确的模型效果。
top1-top5准确率
对于每一个评估的图片文件,模型会给根据置信度高低,依次给出top1-top5的识别结果,其中top1置信度最高,top5的置信度最低。那么top1的准确率值是指对于评估标准为“top1结果识别为正确时,判定为正确”给出准确率。top2准确率值是指对于评估标准为“top1或者top2只要有一个命中正确的结果,即判定为正确”给出的准确率。……以此类推。
模型调优建议
在模型评估中,EasyDL将会通过智能算法对误识别的样本进行归因分析,可推断出误识别的样本对某个模型评估指标的具体影响以及影响程度,并提供对应优化的方案。同时还可针对某个具体表现不好的标签进行归因分析,针对性优化识别效果
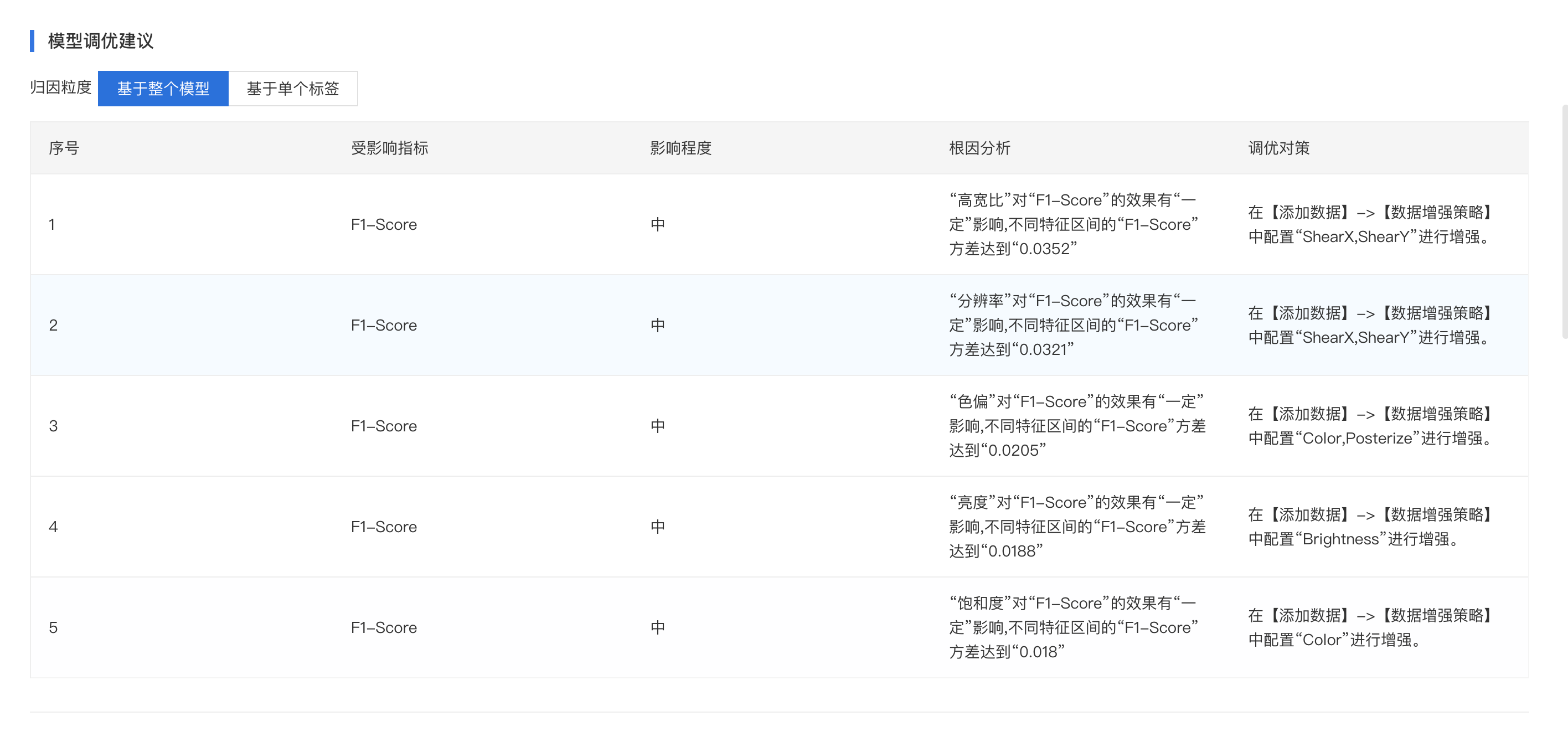
详细评估
这个部分支持查看模型识别错误的图片示例,以及使用混淆矩阵定位易混淆的分类。
识别错误图片示例
通过分标签查看模型识别错误的图片,寻找其中的共性,进而有针对性的扩充训练数据。

例如,你训练了一个将小番茄和樱桃分类的模型。在查看小番茄分类的错误示例时,发现错误示例中有好几张图片都是带着绿色根茎的小番茄(与樱桃比较相似)。这种情况下,就需要在小番茄分类的训练集中,多增加一些带绿色根茎的图片,让模型有足够的数据能够学习到带根茎的小番茄和樱桃的区别。
这个例子中,我们找到的是识别错误的图片中,目标特征上的共性。除此之外,还可以观察识别错误的图片在以下维度是否有共性,比如:图片的拍摄设备、拍摄角度,图片的亮度、背景等等。

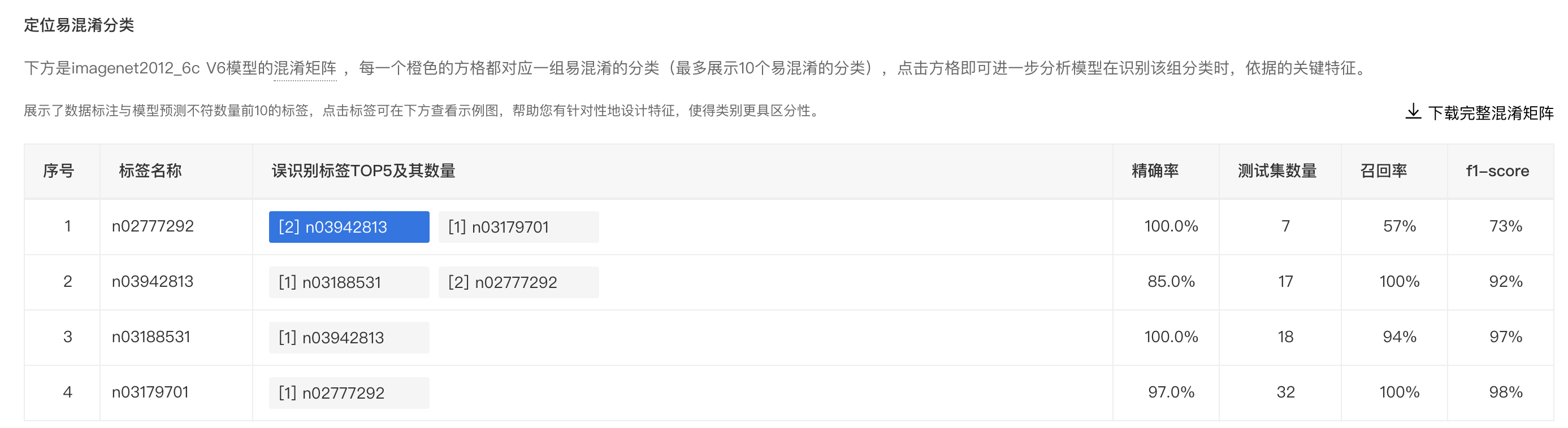
定位易混淆分类
支持按识别错误样本量的绝对数值/相对数值查看混淆矩阵,获得具体到数据级别的精度评价信息。同时支持下载完整的混淆矩阵进行更深入的分析。
分析热力图
点击混淆矩阵中带有数字的方格,可以进一步分析对应易混淆分类的示例图,非常直观地对影响模型精度的因素进行判断。
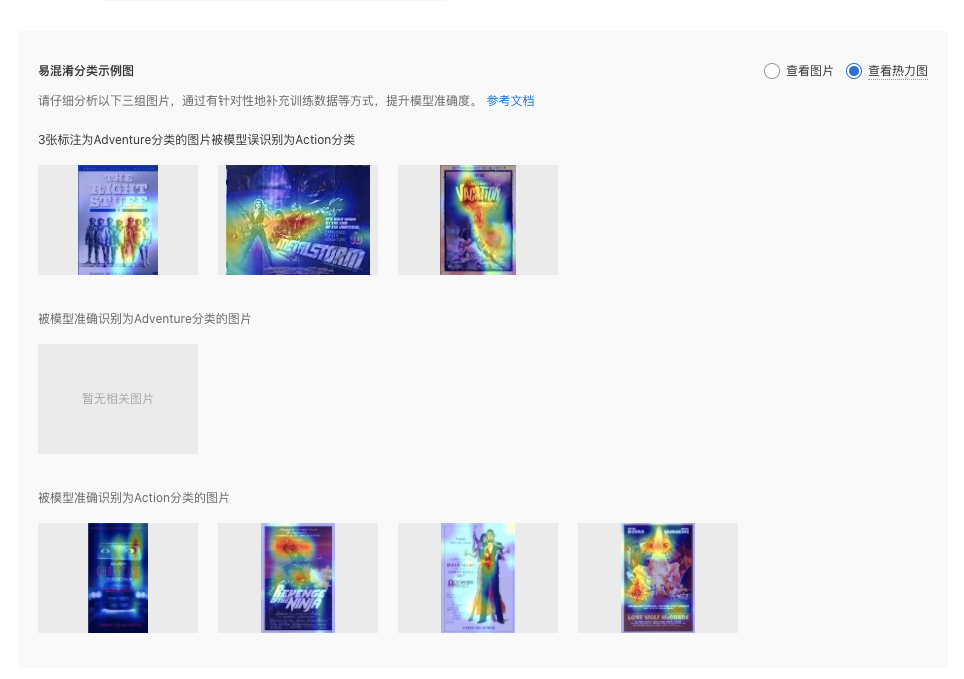
示例图共分为3组,假设选定的易混淆分类是「A分类被误识别为B分类」:
1、实际标注为A分类,但被模型识别为B分类的所有图片
2、被模型准确识别为A分类的图片
3、被模型准确识别为B分类的图片
3组图片均支持查看原图与热力图。其中,热力图可以进一步地解释模型的决策依据,在整图范围内给出影响模型识别结果的像素重要程度,热力图的色度如下图,颜色越靠右代表像素重要性越高。

以猫狗分类为例:
如果分类为狗,但被模型误识别为猫的示例图里出现的狗,与模型准确识别为狗的示例图的图片性状大不一致,那可以判断出数据集对某种性状的狗的识别能力不足,需要继续增加该性状的狗的数据。
如下猫狗的图片,模型给出预测结果为狗,通过热力图的查看,可以看到支持模型给出狗的预测结果的决策依据正是图中狗脸附近像素区域。


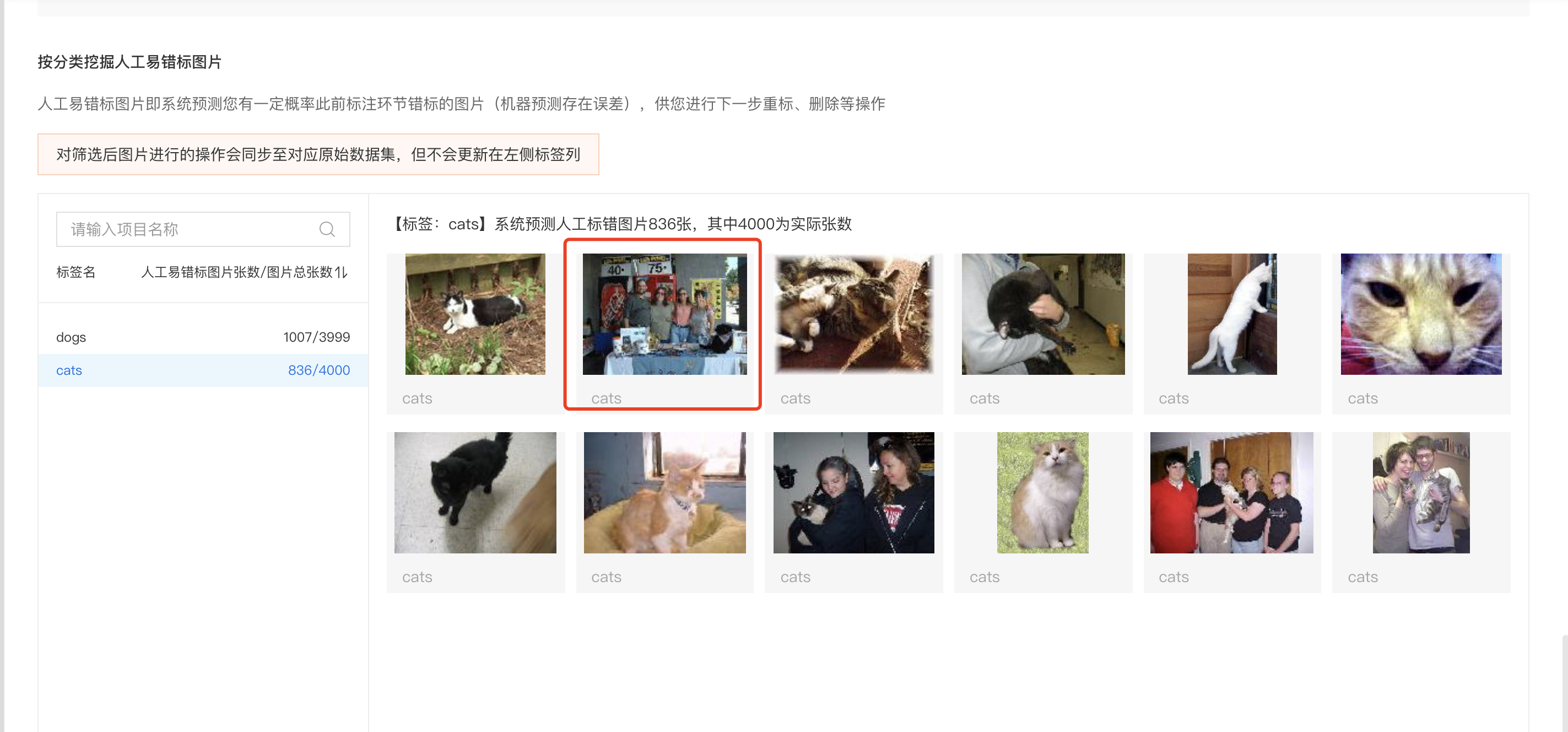
按分类挖掘人工易错标图片
在标注数据时可能由于粗心将不属于某类别的图片标注为了该类别,这种情况十分常见。在评估报告中的「按分类挖掘人工易错标图片」中即可快速检查到这些图片,并同时完成标签修改。
评价此篇文章