
创建数据集并导入
创建数据集
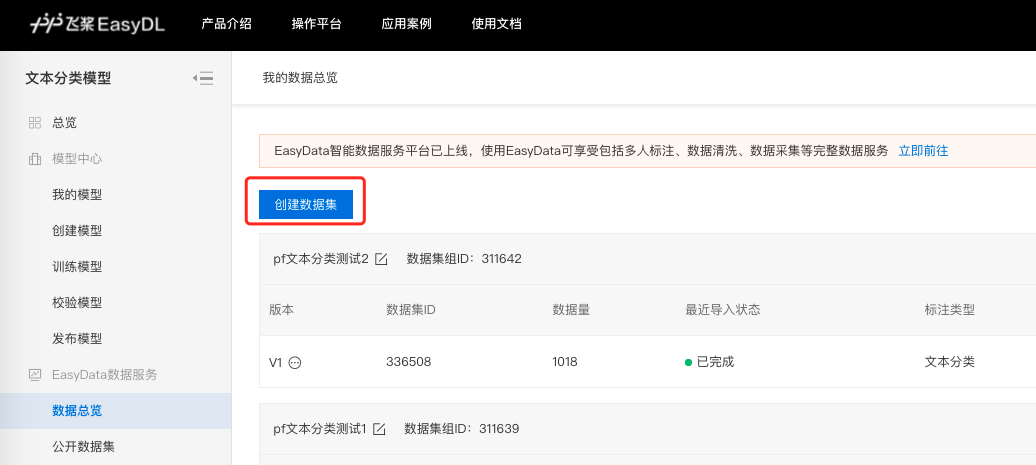
在训练模型之前,需要创建数据集。需输入数据集名称、选择相应的标注模版、选择数据去重策略,即可创建一个空数据集。
数据自动去重即平台对您上传的数据进行重复样本的去重。建议创建数据集时选择「数据自动去重」
如果待导入数据集是中文简体/繁体,请选择『短文本单标签』;如果待导入数据集是非中文的其他语言,请选择『多语种文本单标签』,点击可查看支持的全部语言种类。
导入数据
创建数据集后,在「数据总览」页面中,找到该数据集,点击右侧操作列下的「导入」,即可进入导入数据页面。
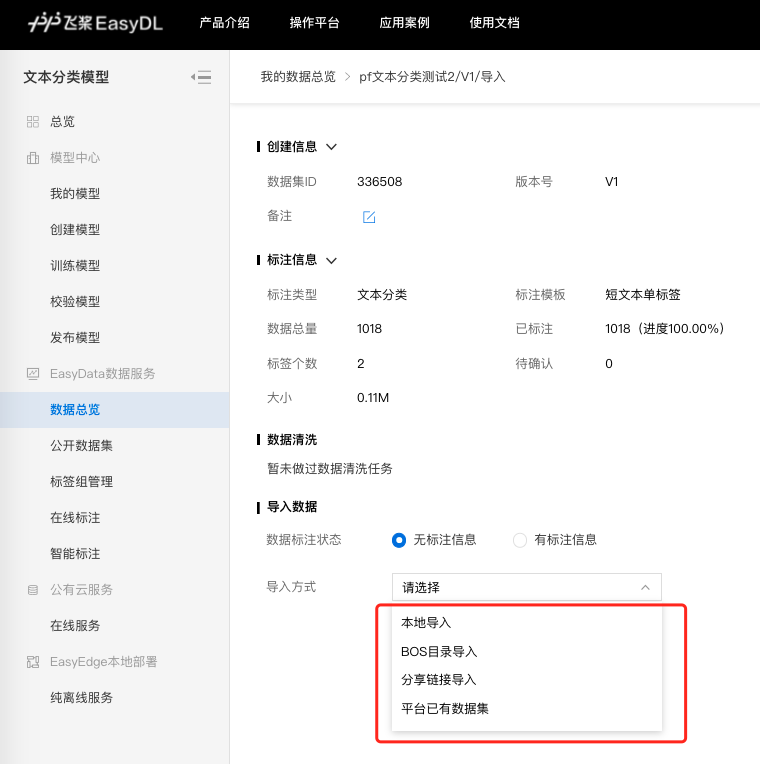 您可以使用4种方案上传文本分类的数据,分别为:
您可以使用4种方案上传文本分类的数据,分别为:
- 本地导入
- BOS目录导入
- 分享链接导入
- 平台已有数据集
本地导入
您可以通过以下三种方式进行本地数据的导入:
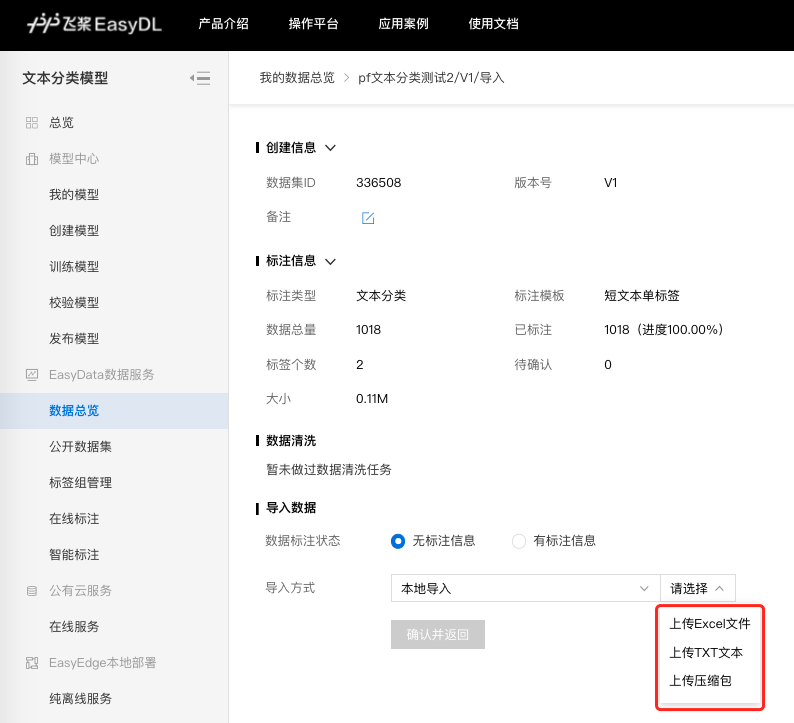
- 以压缩包的方式上传
- 以TXT文本文件方式上传
- 以Excel文件的方式上传
以压缩包方式上传
如果您想上传的数据为压缩包,请根据您的数据是否已标注,按照以下格式要求完成数据上传。
无标注数据
- 压缩包内包含上传的所有文本数据,每一个文本文件将作为一个样本上传,详见示例压缩包
- 压缩包格式为.zip格式,压缩包内文件类型支持txt,文件编码仅支持UTF-8
有标注数据
- 压缩包格式为.zip格式,同时压缩包大小在5GB以内,文本编码仅支持UTF-8,每个文本文件最长不能超过4096个字符
- 标注文件中标签由数字、中英文、中/下划线组成,长度上限256字符。
有标注数据可以使用以下两种格式组织压缩包的内容:
- 以文件夹命名样本的标签:压缩包内按照文本类别数量分为多个文件夹,以文件夹的名称作为文本类别标签,文件夹下的所有txt文件作为样本,详细请见示例压缩包
- 用json文件标记分类:压缩包内仅支持单个文本文件(txt)及同名的json格式标注文件的上传,可传多组样本,详细请见示例压缩包
以TXT文本文件上传
- 无标注数据文本文件内数据格式要求为"文本内容\n"(即每行一个未标注样本,使用回车换行),详见数据样例。有标注数据中文本文件内数据格式要求为"文本内容\t标签\n"(即每行一个标注样本,使用tab键将文本内容与标签分开,使用回车换行),详见数据样例。每一行表示一组数据,每组数据的字符数建议不超过4096个字符,超出将被截断;训练的字符数不超过512个字符,超出的字符可正常保存,但不参与训练。
- 文本文件类型支持txt,编码仅支持UTF-8,单次上传限制100个文本文件,最多可上传100万个文本文件
以Excel文件上传
- Excel文件内数据格式要求为:每行是一个样本详见数据样例,如果您上传的为有标注数据,则每行的样本包含两列,第一列为数据文本内容,第二列为文本对应标签,详见数据样例;如果您上传的为无标注数据,则每行样本仅包含第一列数据文本内容,每个数据样本文本内容的字符数建议不超过4096个,超出将被截断。
- 文件类型支持xlsx格式,单次上传文件个数上限为100个
- 请确保您上传的样本在sheet1中,注意,首行作为表头将被系统忽略
BOS目录导入
需选择Bucket地址与对应的文件夹地址。
请确保将全部文本已通过txt文件保存至同一层文件目录,该层目录下子文件目录及非相关内容(包括压缩包格式等)不导入。
分享链接导入
需输入链接地址。分享链接导入的要求如下:
- 仅支持来自百度BOS、阿里OSS、腾讯COS、华为OBS的共享链接
平台已有数据集
- 导入无标注数据时,选择需要导入的数据集名称,可导入其不带标注的全部数据,或未标注的数据
- 导入已标注数据时,选择需要导入的数据集名称,可导入其某个或全部标签下的数据
准备数据集的技巧
文本分类任务中,可参考以下准备数据集的技巧:
设计分类
首先想好分类如何设计,每个分类为你希望识别出的一种结果,如要识别新闻的内容类型,则可以以“科技”、“体育”、“农业”等分别作为一个分类标准;如果审核场景中通过文本判断是否出现广告,可以设计为两类设计为“正常”、“不正常”两类,或者“正常”、“异常原因一”、“异常原因二”、“异常原因三”等多类。
注意:目前单个模型的上限为1000类,暂不支持扩容
数据量
基于设计好的分类准备文本数据,每个分类建议至少需要准备50个文本文件以上,如果想要较好的效果,建议文件1000个起,如果某些分类的文本具有相似性,需要增加更多文本。
文本的基本格式要求: 目前文本文件类型支持txt,文本文件大小限制长度最大4096,格式为UTF-8字符。一个模型的文本总量限制10万个文本文件。
数据分布
- 训练集文本需要和实际场景要识别的文本环境一致
- 考虑实际应用场景的种种可能性,每个分类的文本需要覆盖实际场景里面存在的可能性,训练集若能覆盖的场景越多,模型的泛化能力则越强
可能的疑问
- 如果训练文本数据无法全部覆盖实际场景要识别的文本,怎么办?
答:训练的模型算法会有一定的泛化能力,尽可能覆盖即可。
- 多语种模型支持全球94种语言:
南非语, 阿姆哈拉语, 阿拉伯语, 阿萨姆语, 阿塞拜疆语, 白俄罗斯语, 保加利亚语, 孟加拉语, 孟加拉语(拉丁化), 布列塔尼语, 波斯尼亚语, 加泰隆语, 捷克语, 威尔士语, 丹麦语, 德语, 希腊语, 英语, 世界语, 西班牙语, 爱沙尼亚语, 巴斯克语, 波斯语, 芬兰语, 法语, 弗里斯兰语, 爱尔兰语, 苏格兰盖尔语, 加利西亚语, 古吉拉特语, 希伯来语, 印地语, 印地语(拉丁化), 克罗地亚语, 匈牙利语, 亚美尼亚语, 印尼语, 冰岛语, 意大利语, 日语, 爪哇语, 格鲁吉亚语, 哈萨克语, 高棉语, 康纳达语, 韩语, 库尔德语, 柯尔克孜语, 拉丁语, 老挝语, 立陶宛语, 拉脱维亚语, 马拉加斯语, 马其顿语, 马拉亚拉姆语, 蒙古语, 马拉提语, 马来语, 缅甸语, 尼泊尔语, 荷兰语, 挪威语, 奥里亚语, 旁遮普语, 巴利语, 普什图语, 葡萄牙语, 罗马尼亚语, 俄语, 梵语, 信德语, 僧伽罗语, 斯洛伐克语, 斯洛文尼亚语, 索马里语, 阿尔巴尼亚语, 塞尔维亚语, 巽他语, 瑞典语, 斯瓦希里语, 泰米尔语, 泰米尔语(拉丁化), 泰卢固语, 泰卢固语(拉丁化), 泰语, 他加禄语, 土耳其语, 维吾尔语, 乌克兰语, 乌尔都语, 乌尔都语(拉丁化), 乌兹别克斯坦语, 越南语, 意第绪语。
如果需要寻求第三方数据采集团队协助数据采集,请在百度云控制台内提交工单反馈
评价此篇文章