
经典版语音识别介绍
HI,您好,欢迎使用EasyDL语音识别。
原语音自训练平台即日已结束公测正式上线,品牌升级更名为“EasyDL语音识别”,平台和语音识别通用接口全面打通,语音技术下任一接口开通付费即可免费训练语音识别模型,无需额外费用。
——————————————————————
如果您在调用通用语音识别模型时遇到如下困难:
1、在垂直业务领域下通用语音识别模型准确率不满足需求,语音识别应用的场景专业词汇较集中,如医疗词汇、金融词汇、教育用语、交通地名、人名等,识别结果存在“同音不同字”的情况。例如“虹桥机场”识别为“红桥机场”;“债券”识别为“在劝”。
2、语音识别结果不准带来更高的后处理成本,并且语音识别模型针对性优化训练存在技术门槛、成本高、训练周期长。
欢迎使用EasyDL语音识别,可以通过自助训练语言模型的方式有效提升您业务场景下的识别准确率。
使用流程概述
平台使用的基本流程如下图所示,全程可视化简易操作,在数据已经准备好的情况下,最快一天内即可获得专属模型。

1、创建模型:选择您需要训练的语音识别接口,目前支持训练短语音识别-中文普通话、短语音识别极速版、实时语音识别-中文、呼叫中心语音解决方案接口。填写基础信息为您的模型进行命名和功能描述,并留下您的联系方式以便于我们和您联系。
2、系统评估:上传您业务场景中的真实音频和对应的正确标注文本(尽可能覆盖全部的场景),客观科学地评估基础模型的识别率。根据评估结果,系统自动推荐最佳的基础模型,您可以选择任一基础模型进行训练。
3、训练模型:上传您业务场景中出现的高频词汇或者是长句文本,可以有效提升业务用语的识别率;并可以迭代训练,持续优化。
5、上线模型:得到满意的训练模型即可申请上线,审批通过自动上线模型。模型上线后,在语音识别的接口中配置模型参数即可使用训练后的效果。
开始使用平台前,先了解以下您需要提前准备的物料及准备建议:
11、【测试集(包括业务音频+准确100%的标注文本)】,用于评估基础模型识别率和训练后模型识别率,相当于准备一份“标准答案”。如果模型使用业务范围较广(例如某行业领域模型),建议测试集在1000-3000条左右评估会相对客观;如果是针对某些特定场景训练,可只提供该场景的音频测试集几十条-几百条均可,包含希望评估的业务内容即可。
2
32、【训练集(投入平台进行训练的文本)】,用于语言模型训练,建议文本要和测试集的内容强相关。训练文本可以放置希望提升识别效果的词汇,如业务上的固定搭配和业务关键词等,或者可以将某个词汇放在不同句式的句子中,高频出现。**影响训练效果的关键因素为“文本出现的频率”和“上下文的句意理解”等**。无需重复提交大量文本,少量关键文本即可有训练效果。输入用户名及密码,点击“登录”,进入EasyDL语音识别。可以看到整体训练流程,点击创建模型可以直接进行模型创建,点击模型中心可以进入到模型列表页面。
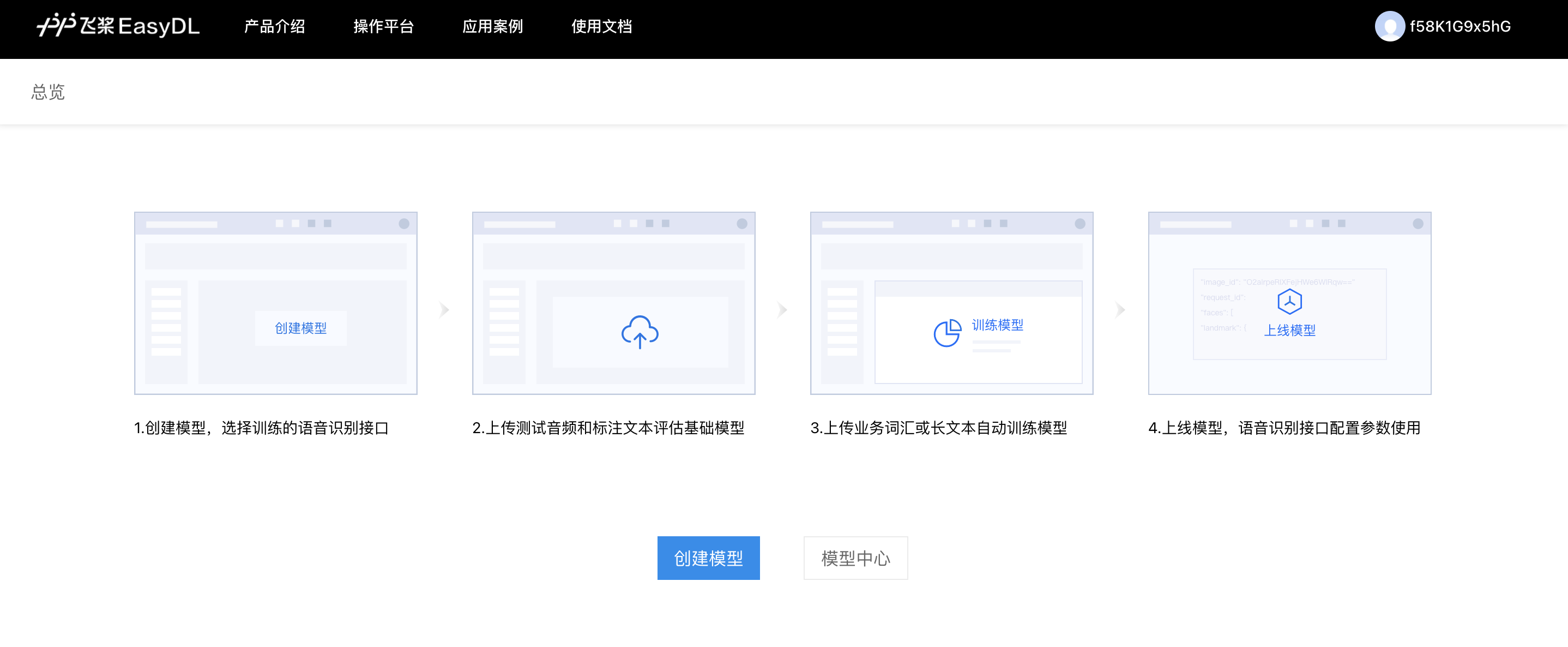
整体训练流程将按照目录栏的顺序依次操作即可。
下面将详细介绍每一步的操作方式和注意事项。若遇到的问题在此文档没有找到答案,可以加入官方QQ群(群号: 686267521)咨询群管。
评价此篇文章