
14. 智能垃圾箱
项目说明
业务背景
2017年3月底,国家发展改革委、住建部共同发布了《生活垃圾分类制度实施方案》,要求在直辖市、省会城市、计划单列市以及第一批生活垃圾分类示范城市,先行实施生活垃圾强制分类工作。但是距离居民养成垃圾分类的习惯,这条路还很长,日本花了27年,德国花了40年。因此对于居民的垃圾分类监控,辅助分类等成为了政府、环保部门的痛点问题。某江浙地区的环保科技公司希望通过AI能力对居民投放的垃圾进行分类,以智能垃圾箱的形态来监管居民的垃圾投放以及建立垃圾回收的生态。
业务难点
AI模型的训练需要有图片对应标注的数据集,海量的垃圾图片需要进行标注,成本高,且人工标注效率低;模型效果调优周期长,需要反复添加数据进行模型迭代,效率低下;智能垃圾箱处于户外,联网条件不稳定,需要边缘硬件部署AI能力,批量硬件部署成本高,部署效率低下。
解决方案
使用EasyDL图像分类任务,无需了解AI算法知识,提交少量图片进行训练,很快即可获得能够识别各类垃圾照片的AI模型。标注少量数据后可使用智能标注功能,完成大量原始数据的标注,来进行模型训练与迭代。EasyDL还提供软硬一体方案,将AI模型部署在性价比高的百度EdgeBoard智算盒,多路摄像头分别对应不同垃圾箱传送带推理,高性能进行AI应用,满足实施识别居民垃圾投放的场景需求。
数据准备
数据采集
- 客户最终的应用场景是在智能垃圾箱中提供投放的垃圾分类功能,因此数据采集的照片要尽量贴合用户拍摄的场景,具备真实性,包含多种光照条件(一定需要包括早/晚/开灯/未开灯的情况),这样才能保证训练模型的效果。切勿使用网络图片进行训练。
- 应用场景需要对「厨余垃圾」、「可回收垃圾」、「有害垃圾」、「其他垃圾」进行分类,而同种垃圾类别下的不同物品之间的视觉感官差异太大,如果将所有「厨余垃圾」定义为同一种标签,AI识别效果会比较差,例如猪肉和白菜同时定义为厨余垃圾,但AI识别时可能猪肉和白菜的识别效果都不尽人意。因此我们需要采集在垃圾传送带中主体(具体垃圾)明确的原始图片,并将其具体物品定义为一种标签,例如猪肉垃圾照片被定义为「猪肉」,白菜照片被定义为「白菜」,再在开发应用时,将猪肉和白菜标签对应到「厨余垃圾」的逻辑中。
- 应用场景中,对于包装为垃圾袋整体扔入垃圾箱的居民,需要及时进行反馈和警告。因此「垃圾袋」要单独被设定为一种标签类别。
数据导入与标注
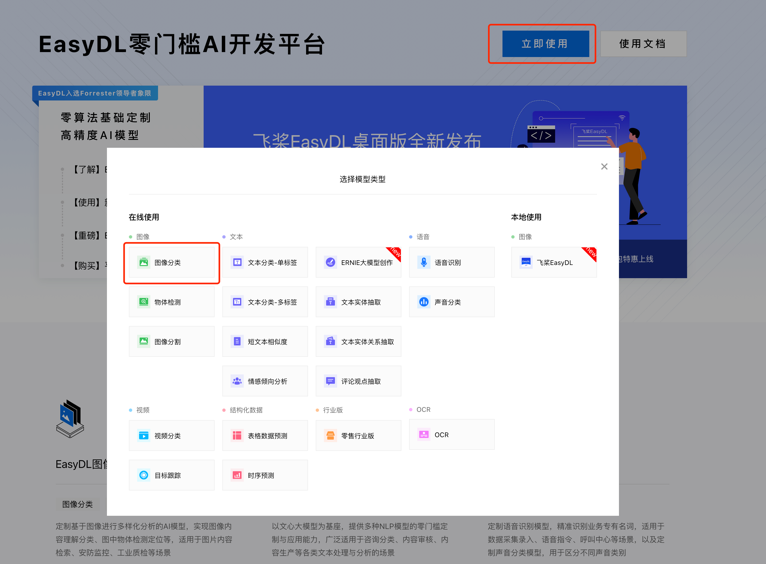
第一步,在EasyDL官网点击立即使用,选择图像分类任务,进入图像分类操作台。
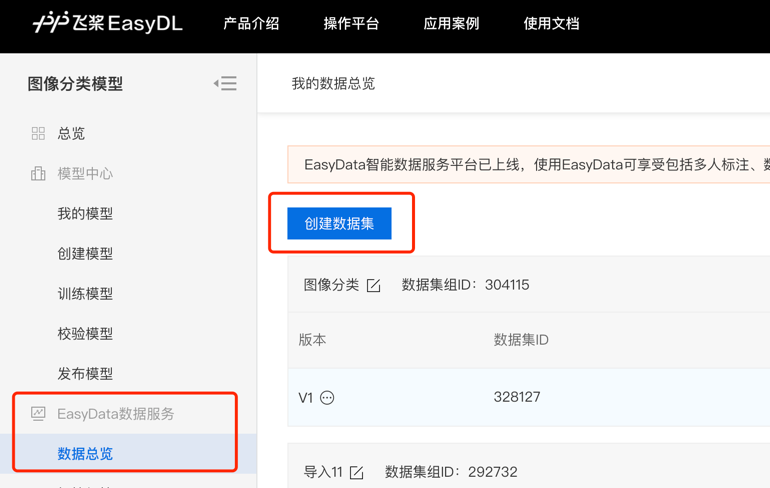
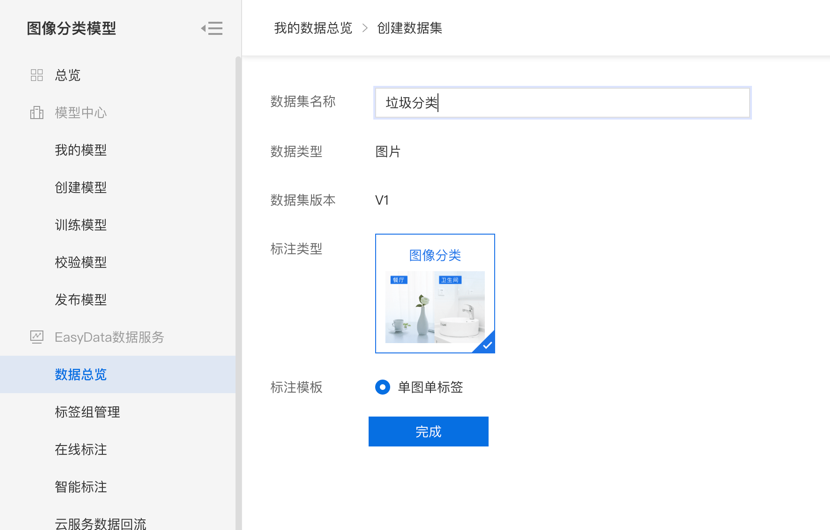
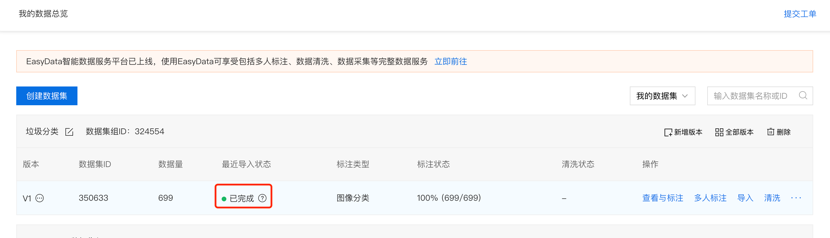
第二步,在数据总览页中点击创建数据集,创建一个“垃圾分类”数据集,点击完成。
第三步,在数据总览页中找到刚才创建的数据集,点击操作栏的“导入”,EasyDL提供多种数据导入方式,可在页面中参考各个方式对应的要求来导入数据。提示:为方便开展模型训练,示例数据已经在本地通过文件夹分隔进行好分类。请选择“有标注信息”-“本地导入”-“上传压缩包”-“以文件夹命名分类”,上传压缩包【garbage.zip】,并确认。
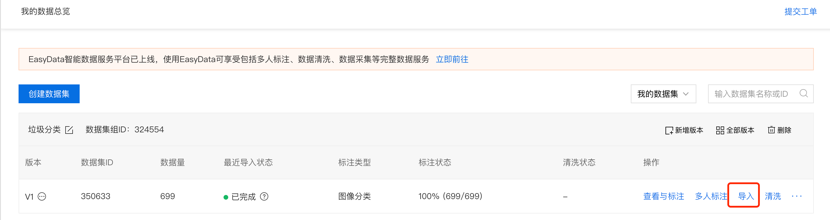

第四步,在数据总览中可以看到数据已经导入,点击右侧的查看与标注就可以去标注上传的原始图片数据。如果上传的是EasyDL提供的示例数据,则无需标注。
模型训练
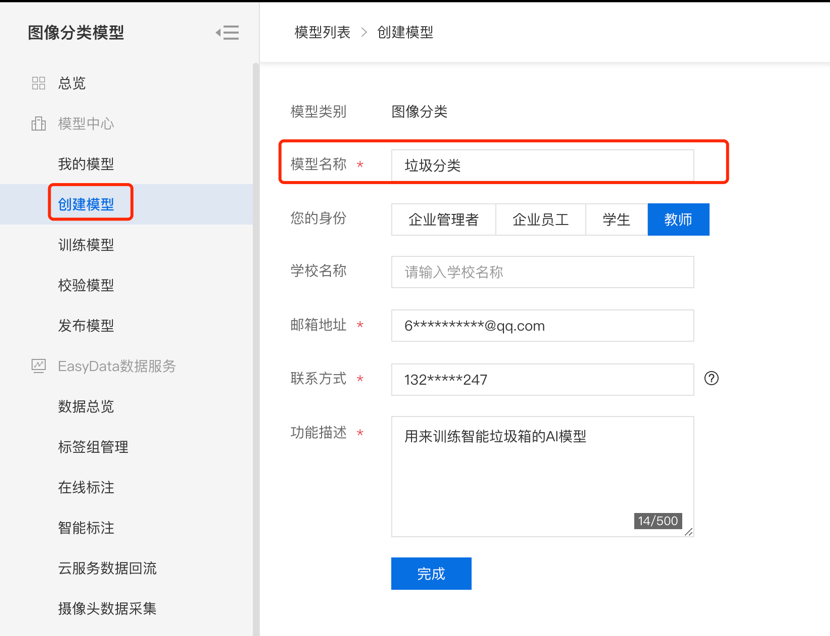
第一步,在我的模型页创建模型,填写真实信息,方便EasyDL团队后续提供更好的服务。
第二步,在刚才创建好的模型操作栏点击训练,准备开始配置训练任务。

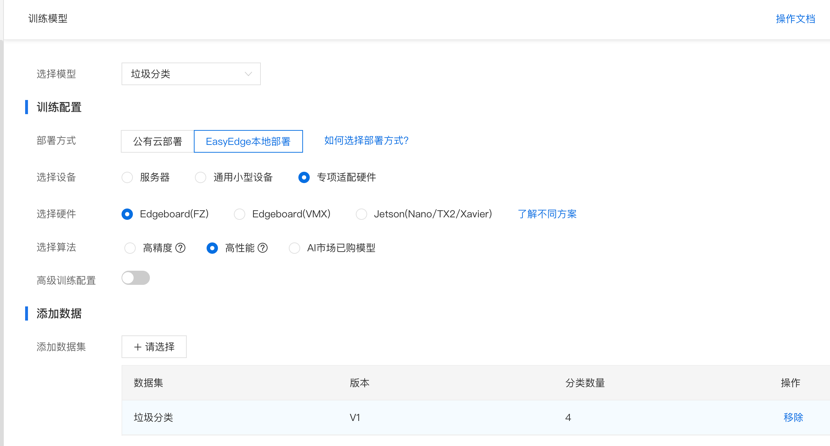
第三步,配置训练任务。训练配置有很多功能,可根据业务的需求考虑后选择。部署方式分为公有云部署和本地部署,因为垃圾分类的AI能力是应用在智能垃圾箱中,是网络环境不稳定,且智能垃圾箱需遍布城市各个角落,是需要控制硬件成本的应用场景,因此选择本地部署中的专项适配硬件EdgeBoard部署。在选择算法时可根据应用场景是更加看重识别精度还是识别结果返回的速度,来决定是选择高精度还是高性能算法。在垃圾分类的应用场景中,更加看重性能,需要实时推理返回结果来提示居民是否正确投放垃圾。因此这里我们选择高性能模型。配置完训练策略后即可添加刚才导入的数据集作为训练数据,即可点击开始训练啦!
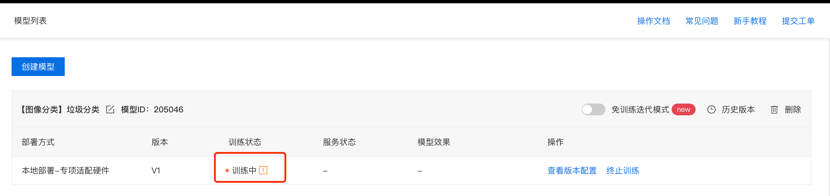
在我的模型页面可以查看模型的训练状态,一般1000张数据集等待几个小时即可完成训练。在模型训练完成后即可进行模型部署。
模型部署
在模型训练完成后,可点击对应操作栏的申请发布,将模型发布为EdgeBoard专项适配的SDK-纯离线服务。
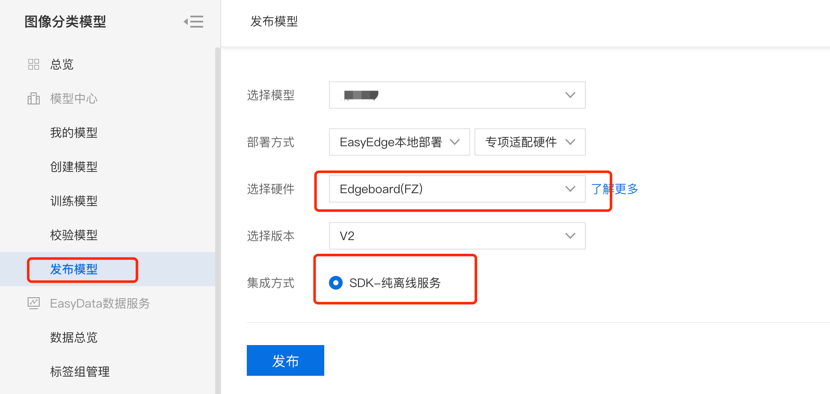
在模型发布完成后,即可在纯离线服务下载SDK进行本地部署啦,如和在本地部署可参考操作文档:https://ai.baidu.com/ai-doc/EASYDL/Ek38n38zs
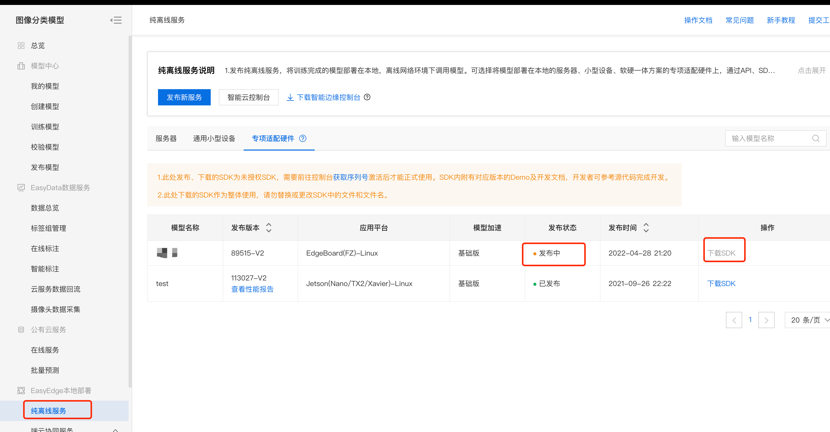
批量部署
智能垃圾箱正式投入应用后,会遍布城市的各个角落,此时各个智算盒子的管理就成为了难题,模型SDK-纯离线服务的部署成本也极高,需要手动一个一个操作。这种情况下,EasyEdge智能边缘控制台就可以很好解决问题,智能边缘控制台-多节点版是及边缘资源管理和模型服务应用的智能边缘平台,可在中心节点统一纳管海量边缘盒子,支持一键模型服务批量下发,灵活部署AI模型。详情请看https://ai.baidu.com/ai-doc/EASYDL/sl138yv75

常见问题
问题1:我应该采集多少数据?
如果是为了体验模型训练和使用的流程,每个类别准备20张即可开始训练。如果需要保证模型效果,模型将投入业务中使用,建议每个类别准备300-500张图片,且覆盖光照和角度都比较全面,从而保证模型的泛化性。
问题2:我有些标签数据量很少,会不会影响模型效果?如果影响,我应该怎么办?
某类标签的数据量相比其他标签的量较少,会影响模型对此类标签的识别准确率。在无法采集到更多原始数据的情况下可以在EasyDL上配置多个策略来优化效果。第一,可在训练配置页面-高级训练配置中打开「数据不平衡优化」开关,优化某类标签数据量少带来的效果问题。第二,可打开数据增强开关,并自己选择数据增强算子来生成更多训练数据,选择算子时需要结合自己的应用场景来选择。例如从肉眼上判断,光照不太影响识别率,就可以选择配置「Brightness」算子来调节光照条件来增加数据。
问题3:模型训练免费吗?你们平台什么时候收费? 数据标注、模型训练都是免费的,公有云服务API调用和本地部署SDK都提供免费试用的额度
评价此篇文章