
离线预测
概述
通常情况,在您新建预测服务后,可以直接数据模型中新建要使用的预测服务字段从而在大屏和报表中使用,但这样会存在一些问题,例如:
- 图表中的数据一般都是聚合之后的结果,在聚合之后的结果上做预测,预测的结果可能并不如意。
- 对于内置模型,它是无监督机器学习算法来进行预测,也就是说给它多少数据,它会在此数据量的基础上来进行计算,当图表中的数据很少,这几乎很难预测准确。
- 每次图表获取预测字段数据的时候都要进行计算,虽然可以设置缓存,但是缓存时间有限,再次获取需要重新计算,造成资源浪费。
而离线预测可以解决上述问题,离线预测会将预测结果写入到数据库中达到永久存储。在数据模型中,可以像使用其他字段一样使用预测字段。
目前支持对 Excel/CSV、内置数据填报数据源、MySQL 5.X、 MySQL 8、GaiaDB、Apache Doris (Baidu Palo)、PostgreSQL、 Greenplum、MariaDB、Oracle、CockroachDB、TiDB、DM-达梦、KingbaseES-人大金仓、openGauss-华为GaussDB、GaussDB(DWS)-华为数仓 数据源中的数据进行离线预测。
如何新建离线预测
在离线预测的管理页面,可以通过新建离线预测按钮创建离线预测,弹出的配置界面中会包含写回至原表,新建表,选择已有表三种数据写入位置。下面会分别介绍这三种数据写入位置。
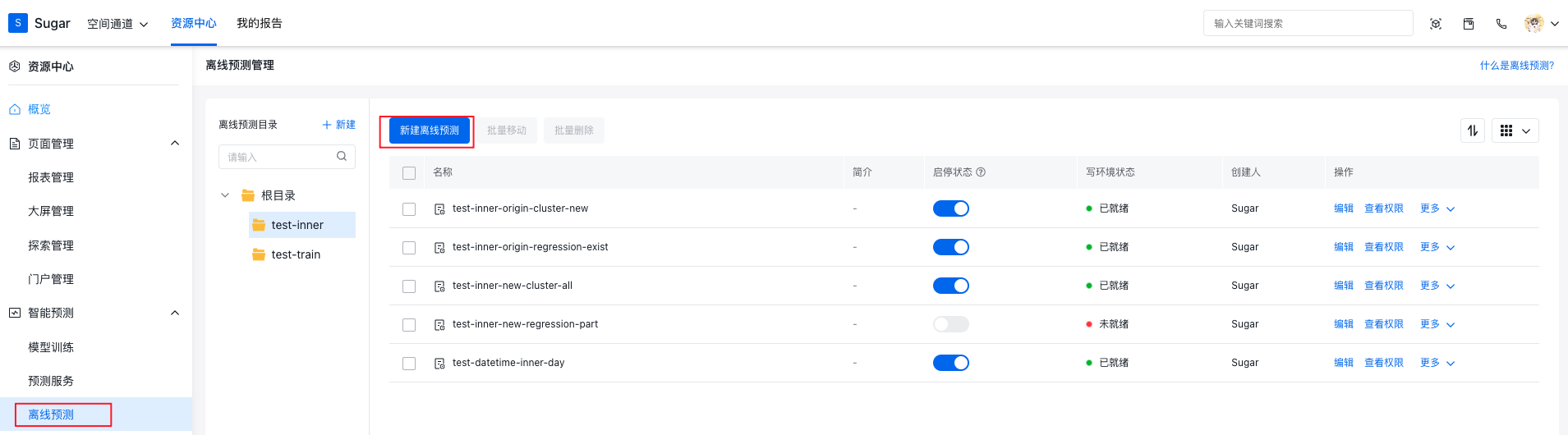
此外也可以在预测服务管理页面中,选择已有的预测服务快速新建离线预测。这样新建的离线预测会直接使用此预测服务来进行数据的预测和写入。
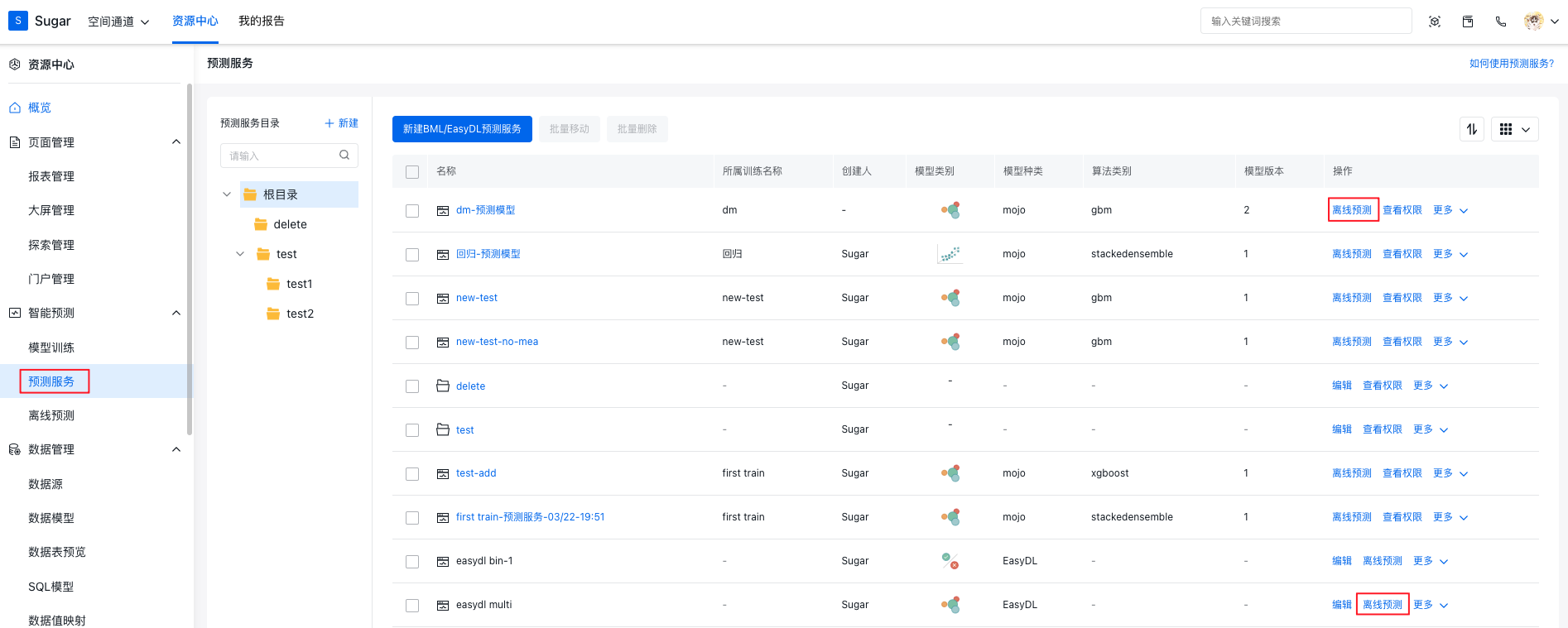
预测服务使用限制
预测服务包含三种,一种是内置预测服务,包含一些常用的分类算法和回归算法。一种是训练预测服务,用户可以使用机器学习平台选择更丰富的算法来训练模型并发布为预测服务。还有一种是BML/EasyDL 预测服务,用户可以使用 BML 或 EasyDL 提供的表格数据在线预测服务 API 来进行数据预测。内置预测服务在 SaaS 高级版和多账号版本(非 2 账号版本)的私有部署中支持。训练预测服务在开启智能预测功能的私有部署中支持。BML/EasyDL 预测服务在 Saas 高级版支持,私有部署版本中则和训练预测服务一致,需要有开启智能预测功能的 License。
写入数据源的写权限要求
三种数据写入位置所需要的数据库相关的写权限请对照下表
| 数据写入位置 | 更新数据权限 | 插入数据权限 | 清空表权限 | 删除数据权限 | 新建表权限 | 新建字段权限 |
|---|---|---|---|---|---|---|
| 写回至原表 | 需要 | - | - | - | - | 当字段写入位置为新建字段时需要 |
| 新建表 | - | 需要 | 数据写入位置为覆盖时需要 |
数据写入位置为追加,导出频率为定时导出,则在使用重跑时需要 |
需要 | - |
| 选择已有表 | - | 需要 | 数据写入位置为覆盖时需要 |
数据写入位置为追加,导出频率为定时导出,则在使用重跑时需要 |
- | - |
Sugar BI 提供了写权限验证的测试,但是由于不同数据源权限配置很复杂,写权限验证是将上述权限全部进行验证,因此特定的写入位置下,可能并不需要相应的权限,例如写回至原表就不需要有创建表的权限等。此时您可以关闭写权限验证,但是对应写入位置所需要的写权限需要您自己保证,否则会出现写库失败的情况。
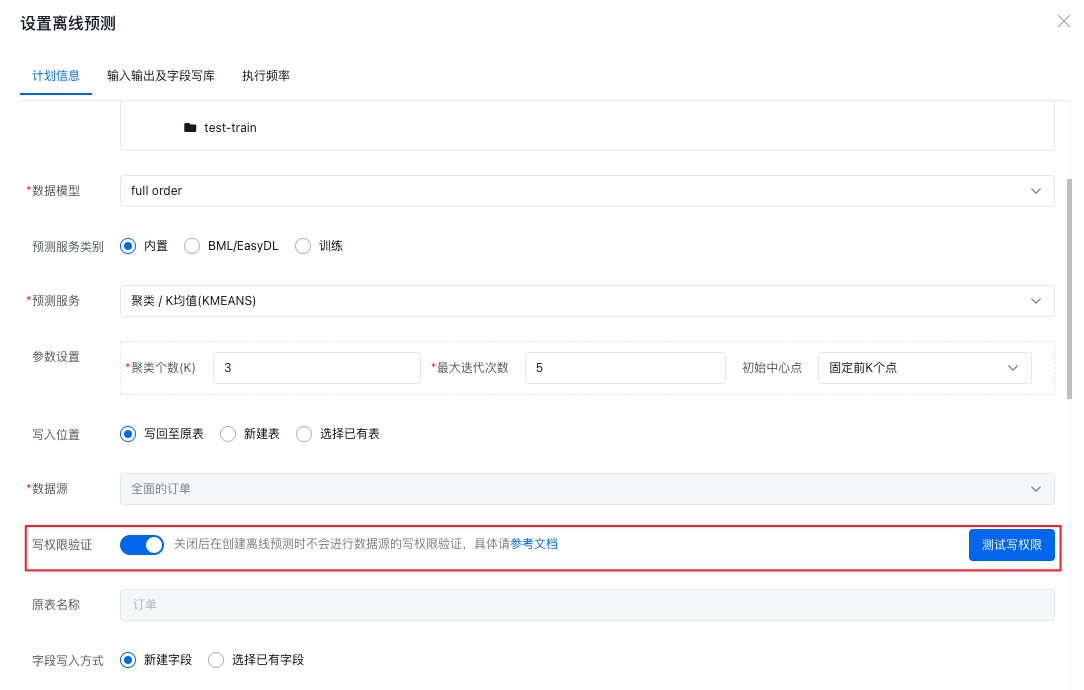
写回至原表
写回至原表的前提要求如下:
- 数据模型没有使用示例数据源和公开数据源
- 数据模型中只使用了一个数据源
- 数据模型中只使用了一个物理表,如果您使用的是数据库中的视图,会出现写入失败的情况
- 数据模型中不能使用自定义 SQL 视图
- Apache Doris (Baidu Palo) 类型的数据源由于不支持 update, alter 等操作,因此也不支持写回至原表
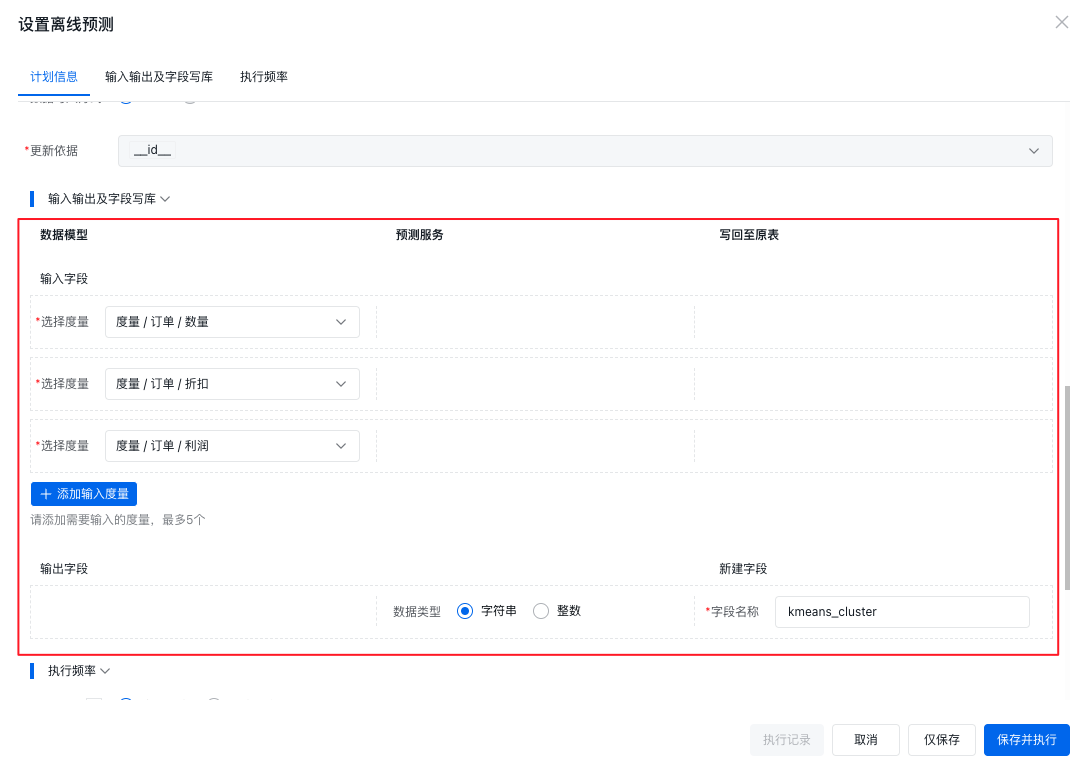
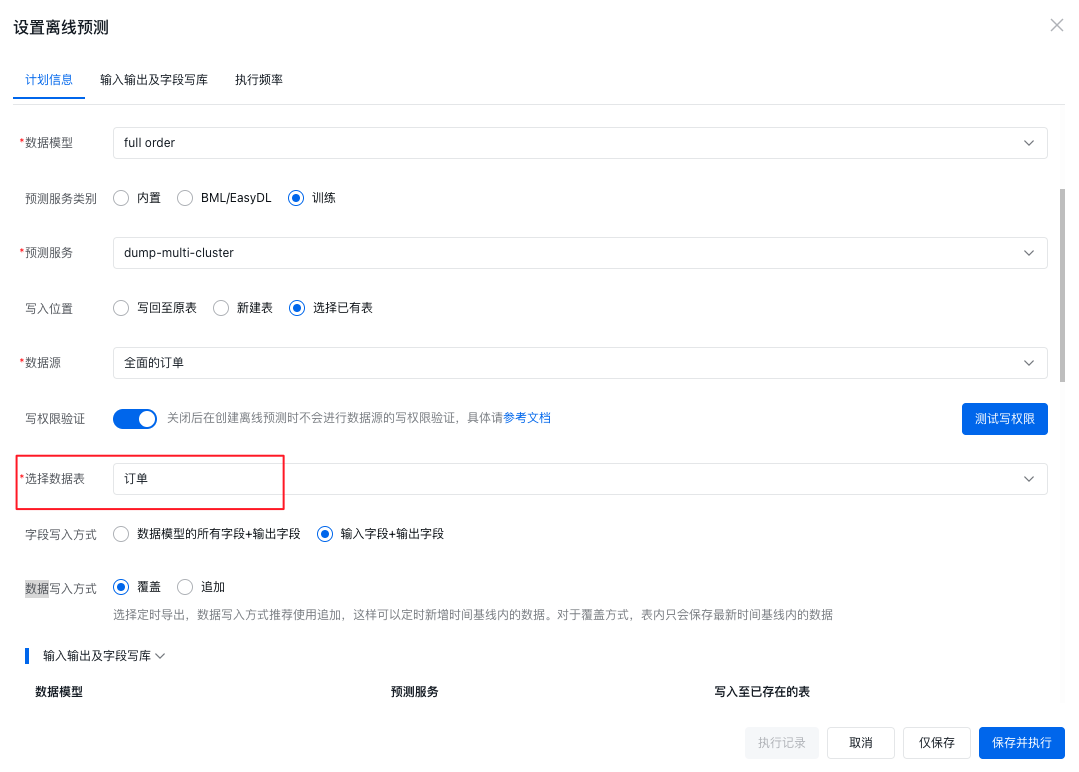
以内置预测服务为例,下图使用的 KMEANS 算法的内置预测服务,内置预测服务的相关配置介绍请参考预测服务,字段写入方式为新建字段,也就是说在保存此离线预测时,Sugar BI 会将预测结果字段写入到新建的字段中,如果您的数据表中已经有了相应存储预测结果的字段,则可以使用选择已有字段即可。
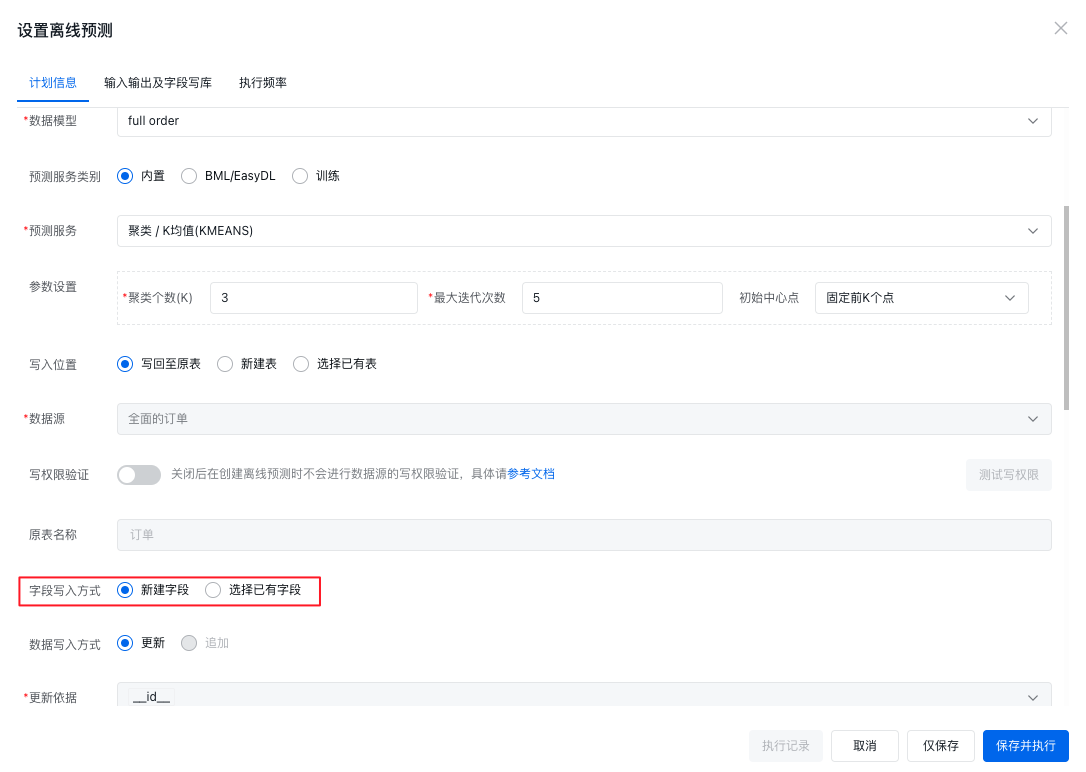
配置完计划信息后,则要配置输入输出及字段写库,输入字段中,要选择给 KMEANS 使用哪些度量来进行计算。输出字段中,可以设置输出的数据格式是字符串还是整数,然后填写新建字段的名称即可,这个新建的字段就是写入预测结果的字段,如果使用的是选择已有字段,那么这里就是选择要写入的字段。
新建表
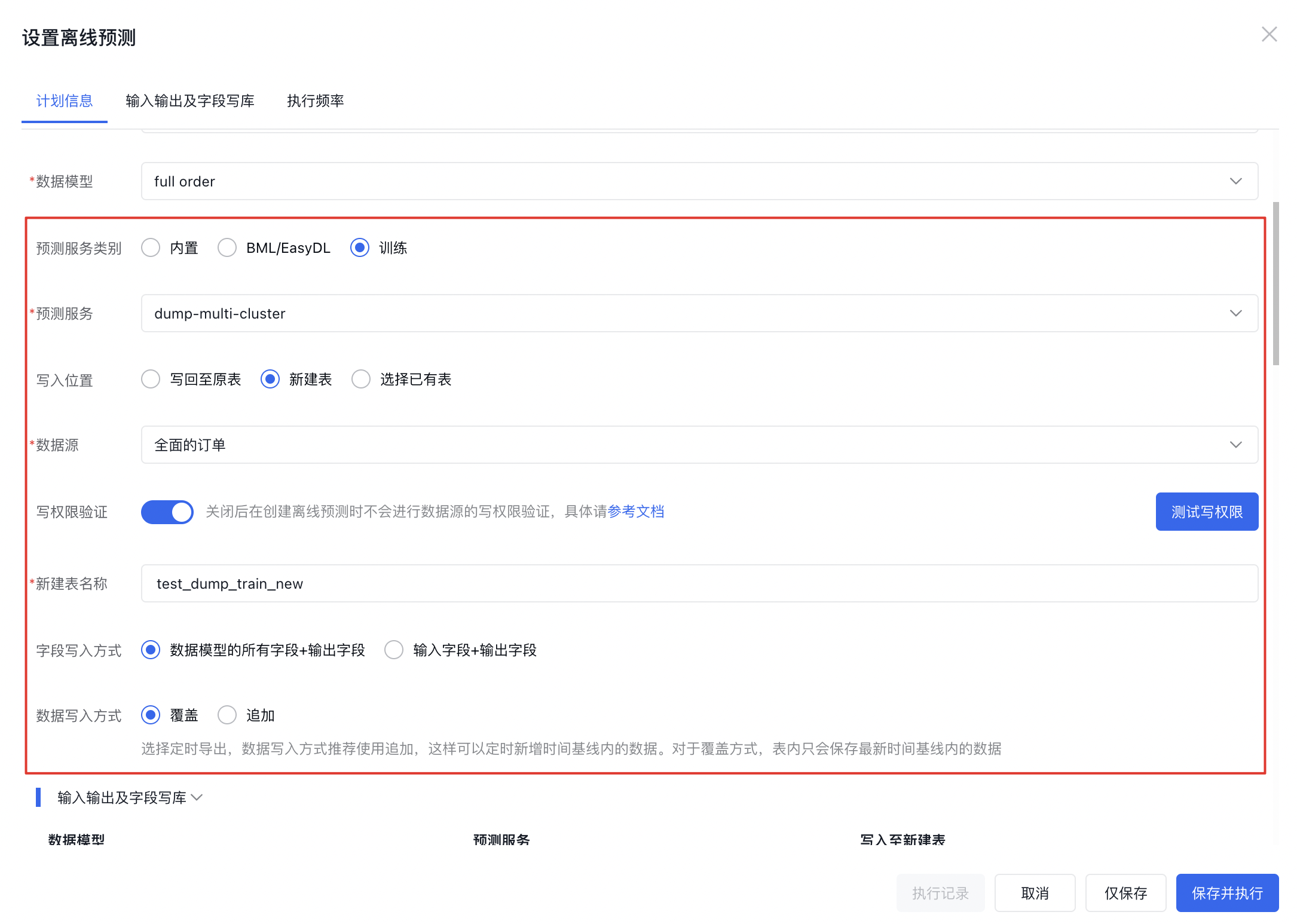
以训练预测服务为例,在选择需要写入的数据源,并设置好新建表的名称。
对于字段写入方式,如果设置为数据模型的所有字段+输出字段,则会将数据模型中非聚合、非表计算、非预测的字段全都写入到新表中,如果设置为输入字段+输出字段,则只是将预测服务需要的输入字段和预测结果的输出字段写入到数据表中。
对于数据写入方式,如果是覆盖,则在向新建的表中写入数据时,每次都会提前清空,然后再写入数据,这种对于定时频率为导出一次比较友好,但如果定时频率为定时导出时,表内只会保存最新时间基线内的数据。如果是追加,则会一直向表中添加数据,这种对于定时频率为定时导出比较友好,可以定时新增时间基线内的数据。但如果定时频率为导出一次时,则每运行一次就会向表中添加一次数据,会出现数据冗余的情况。
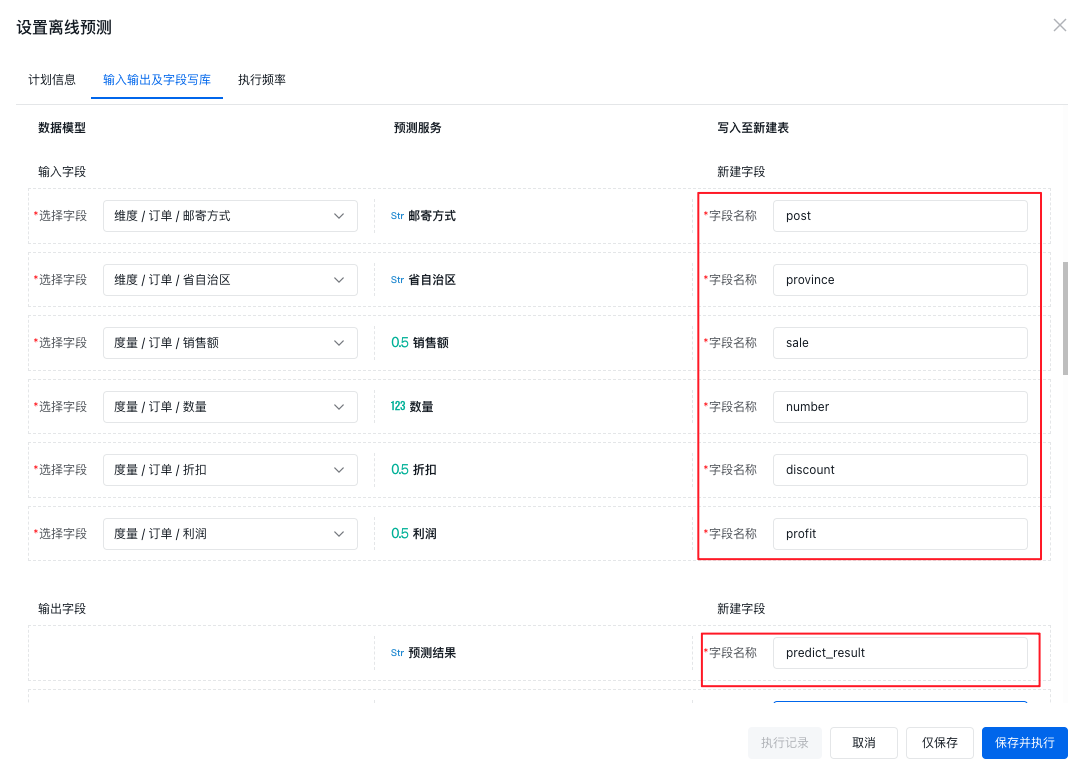
配置完计划信息后,则要配置输入输出及字段写库,输入字段要选择给此训练预测服务使用哪些字段来计算,以及要在新表中新建的字段名称。输出字段,填写要新建的字段名称即可。注意新建的字段名称是不能重复的。
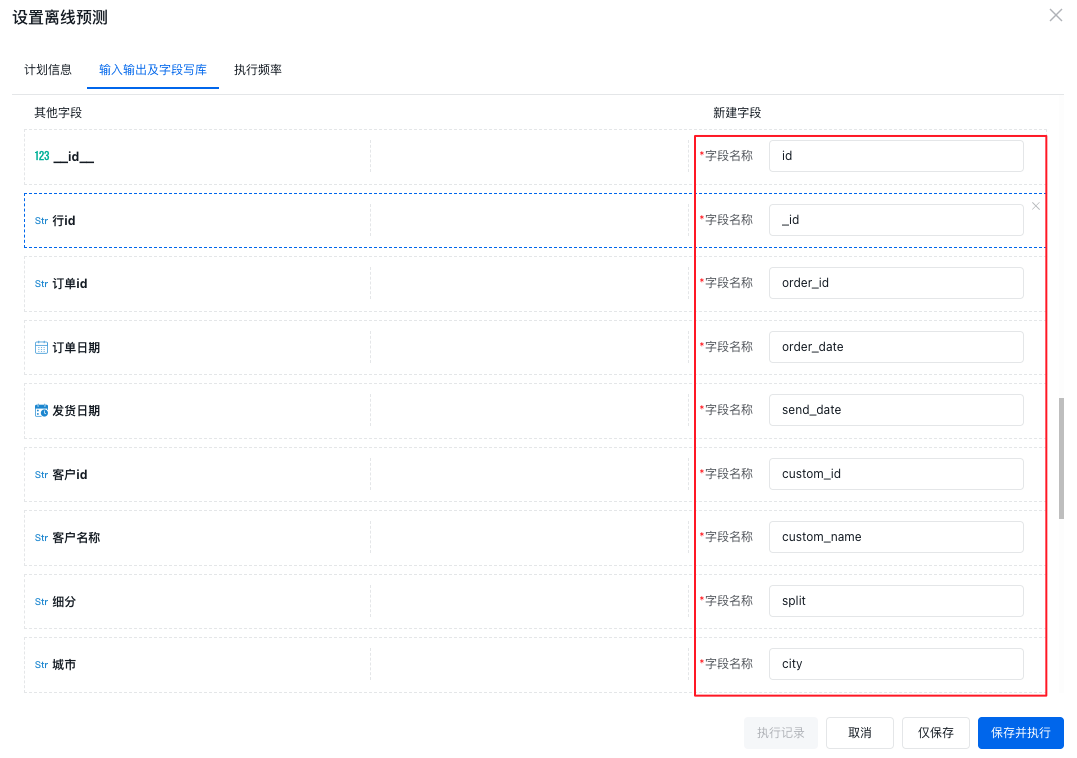
如果设置字段写入方式为数据模型的所有字段+输出字段,那么还需要配置其他字段。
选择已有表
对于选择已有表,其实和新建表很类似,在选择要写入的数据源后,新建表是填写表名称,而选择已有表是从此数据源中选择要写入数据的表,其余操作和新建表是一样的。唯一区别就是,新建表的字段名称是手动填写,而选择已有表是通过下拉选择来匹配目标表中的字段。
执行频率
配置完计划信息和输入输出及字段写库后,再设置执行频率,此离线预测就算配置完成了。在保存的时候有两种方式,一种是仅保存,一种是保存并执行,仅保存是说,您如果不确定数据源的写权限问题,可以只保存配置先不执行,后续可以再次编辑计划信息中的数据源、数据模型、数据表、预测服务、导出频率等信息。可以一旦保存并执行,上述写数据相关的配置是不能更改的,因为 Sugar BI 已经在后端配置好了写环境。
如果您的数据不是随着时间增加的,那么导出频率设置导出一次即可。这样可以将数据模型下的数据一次性写入数据表。
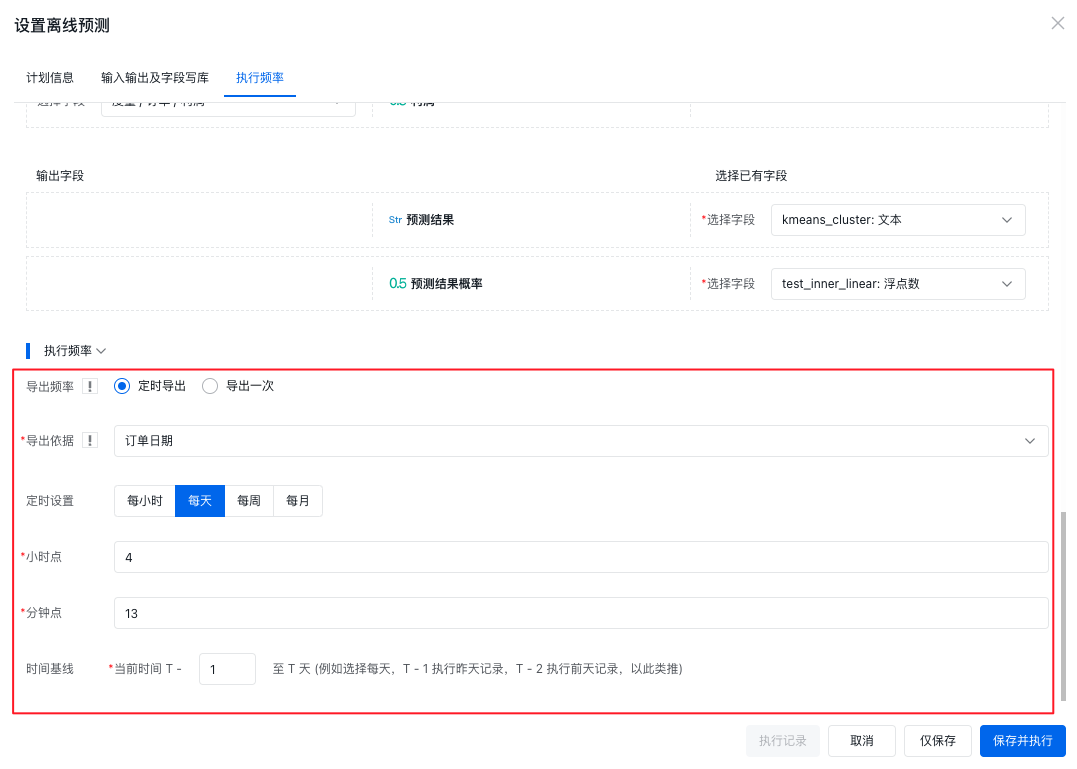
如果您的数据随着时间变化而增多,那么可以选择定时导出,根据您数据的更新情况,如果是每天增加,那么定时设置为每天就好,然后设置好定时任务的执行时间,并设置时间基线。那么到达执行时间时,会将时间基线内的数据进行预测并写入数据表。
时间基线的含义,例如定时设置为每天,T - 1 表示执行昨天的记录,T - 2 表示执行前天的记录,以此类推。如果设置为每周,T - 1 表示执行上周的记录,T - 2 表示执行上上周的记录。而导出依据则是设置数据模型中的日期或日期时间字段来进行数据的筛选。
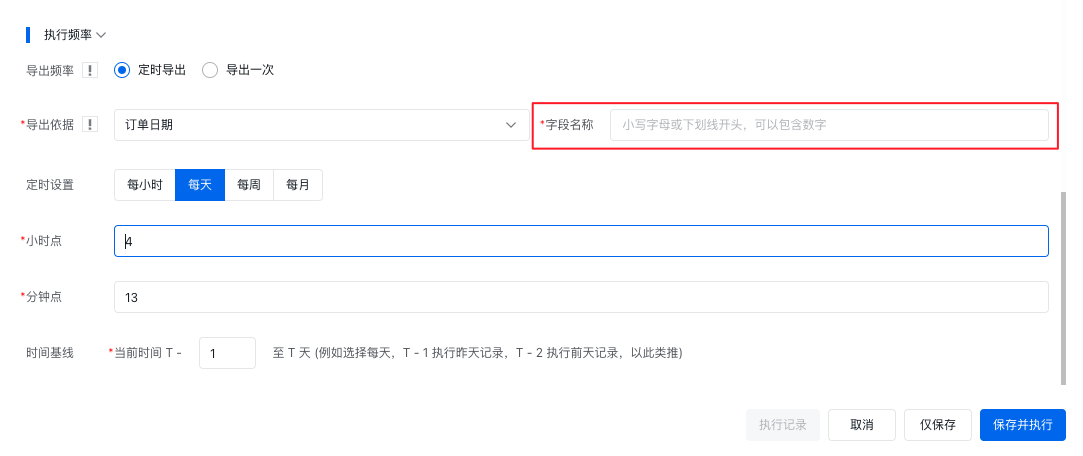
对于新建表或选择已有表,且没有将数据模型的所有字段都写入到表中的话,还需要配置对应字段,将更行依据字段也写入到表中。目的是为了在执行重跑时,可以只需要跑时间基线内的数据。
离线预测管理
在离线预测的管理页面,可以对离线预测进行编辑、查看权限、删除、排序等相关管理操作。
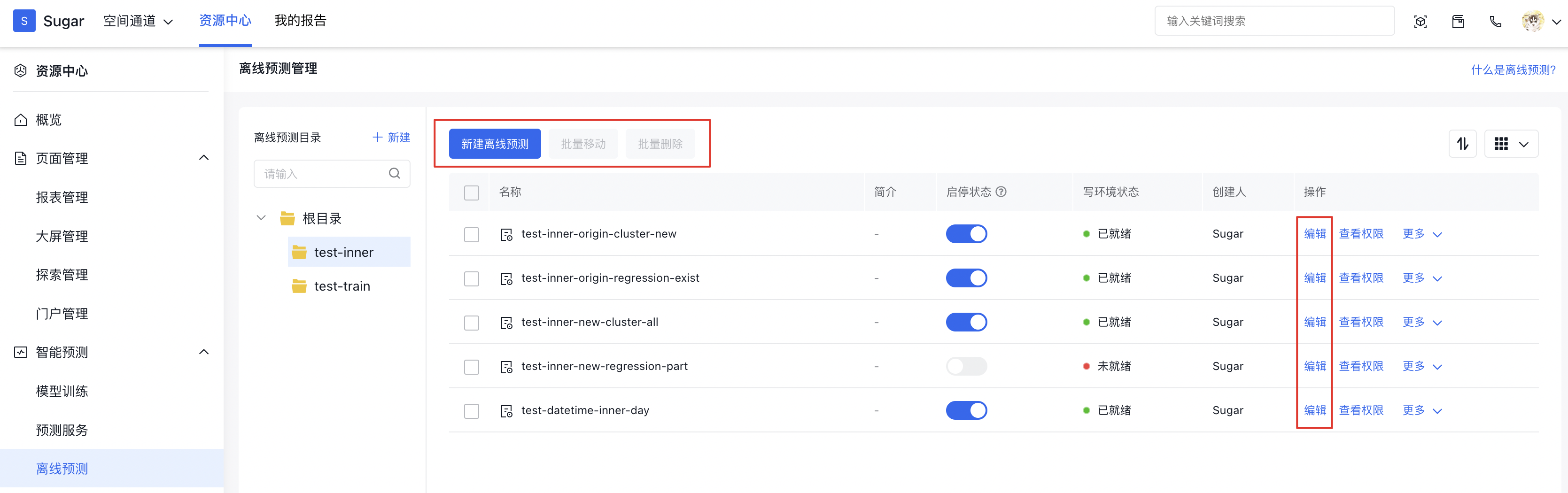
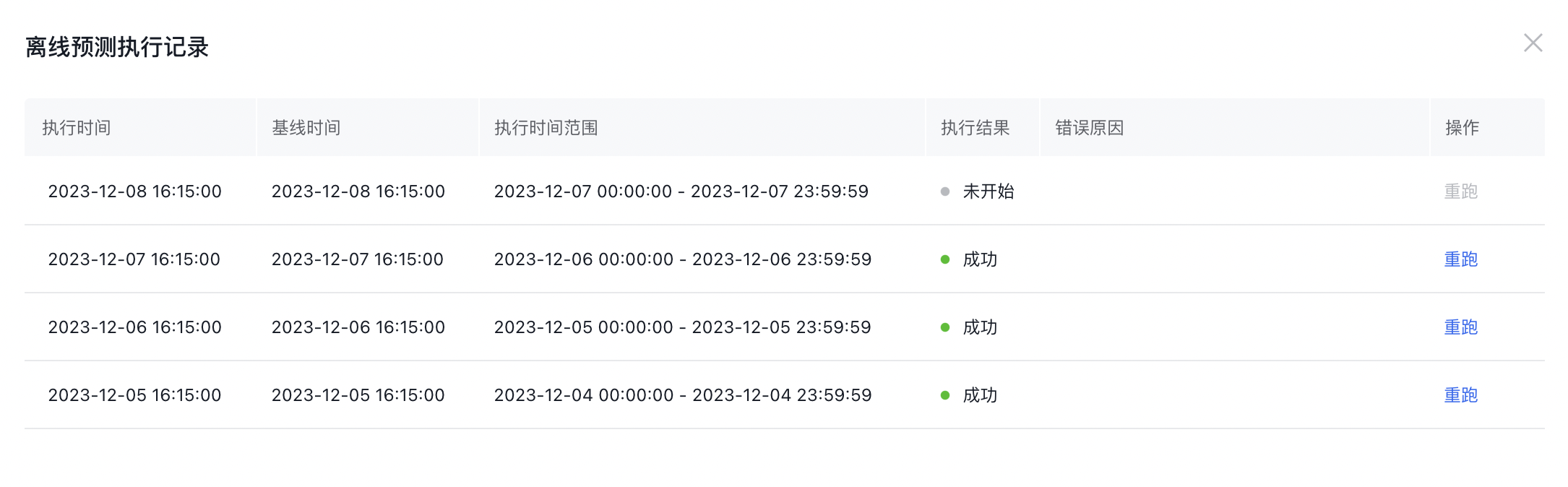
这重点说明一下执行记录的查看以及重跑的使用,在更多中选择执行记录(也可以通过编辑然后点击执行记录),会出现执行记录的表格。
例如下图是使用每天的定时导出,会在每天的16:15执行前一天范围内的数据预测并写库。点击重跑可以重新预测对应时间范围内的数据。
评价此篇文章