
模型训练
概述
Sugar BI 中已经内置了一些如 K-MEANS 等无需训练就可以使用的预测服务,可直接在数据模型中进行引用并进行数据的预测。
在一些场景下,您可能希望用自己的业务数据训练出更加有针对性的模型对数据进行预测。Sugar BI 也支持模型的训练和发布流程,支持深度神经网络,分布式随机森林,梯度提升机,XGBoost 等多种训练算法。针对不熟悉算法的用户 Sugar BI 还支持 AutoML ,无需专业配置即可训练出预测模型。
目前支持对 Excel/CSV、内置数据填报数据源、MySQL 5.X、 MySQL 8、Apache Doris (Baidu Palo)、PostgreSQL、 Greenplum、MariaDB、Oracle、 TiDB、CockroachDB、Apache Impala、Clickhouse、DM-达梦、KingbaseES-人大金仓、openGauss-华为GaussDB、GaussDB(DWS)-华为数仓 数据源中的数据进行模型训练。
功能开启准备
1、模型训练在私有部署中支持,需要购买包含智能预测功能的 License,SaaS 版本暂不支持。
2、按照开启智能预测功能中的步骤完成训练和推理服务的部署。
都准备好后,就可以进行模型的训练了。
新建训练
进入空间工作台,在左侧的管理中心中进入训练管理页面,并选择新建训练:
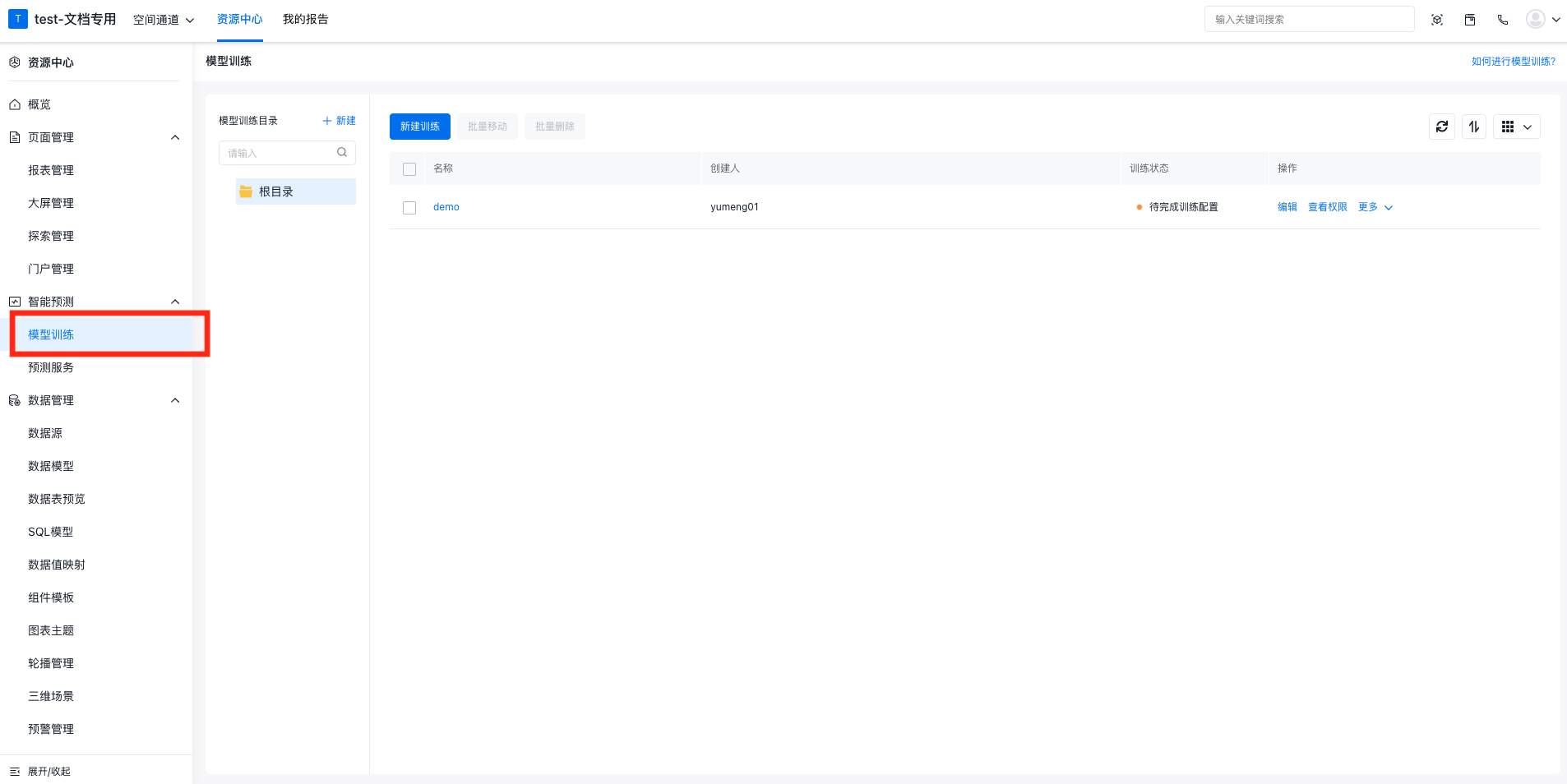
填写训练名称后可以进入训练编辑器。
选择数据模型和目标字段
第一步需要指定训练数据所在的数据模型和目标字段,目标字段就是将来要预测的那个字段,在用于模型训练的数据集中,这个字段的值需要是已知的,在将来需要预测的数据集中,这个字段将由预测服务推理生成:
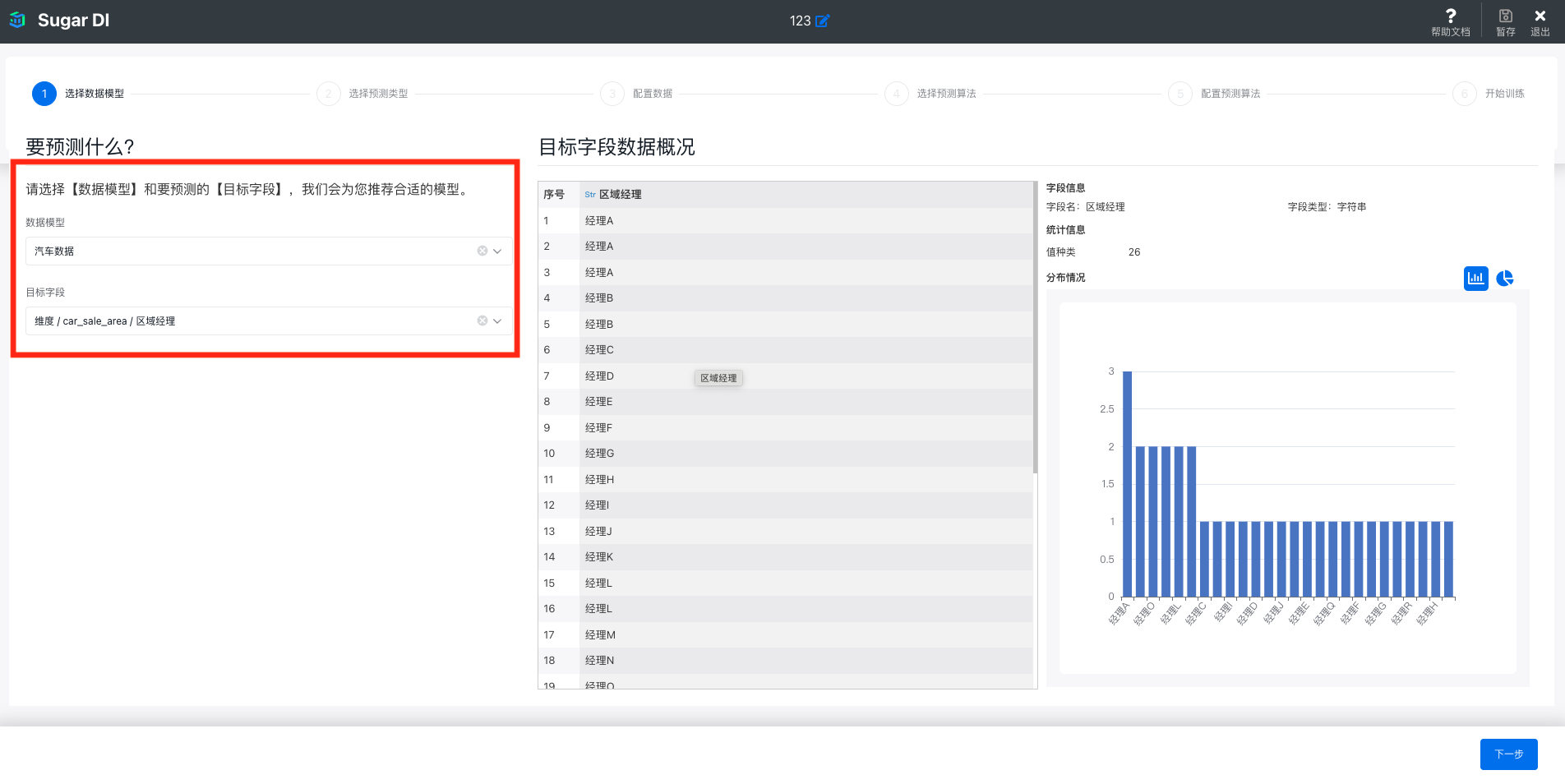
选择好目标字段后,在右侧还可以对目标字段的数据进行预览,并查看数据的分布和统计信息。针对不同的数据类型,可查看的统计信息和图表也不同。
选择训练算法类型
第二步是选择算法类型,Sugar BI 会根据目标字段的类型给出可选的类型列表,例如字符串类型的字段不能选择回归类型的算法:
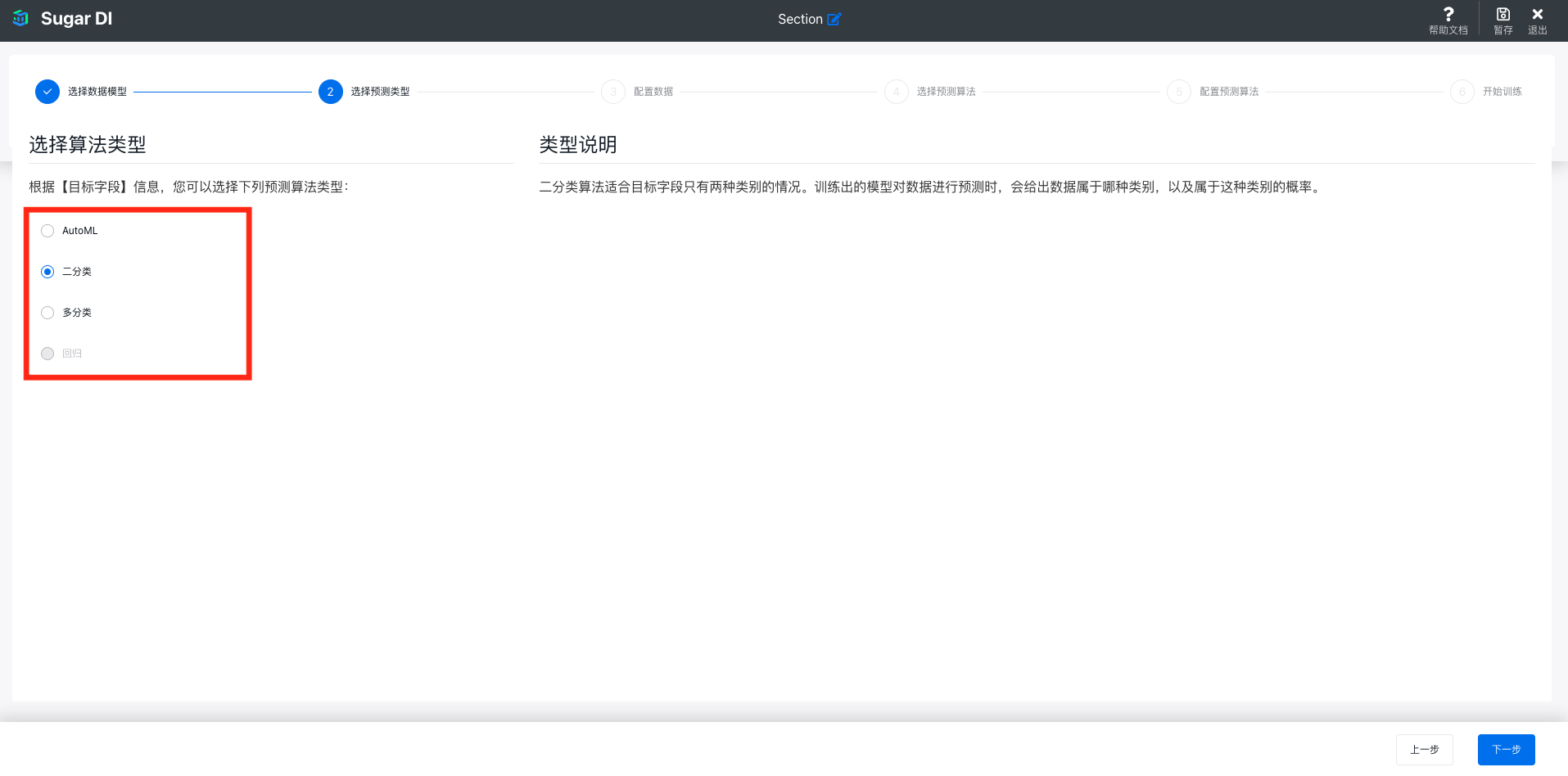
可选的算法类型说明如下:
- AutoML:AutoML 会根据目标字段和训练数据自动执行算法选择、特征生成和超参数调整,使训练和评估机器学习模型变得容易,让您更加专注于数据和业务问题。
- 二分类:二分类算法适合目标字段只有两种类别的情况。训练出的模型对数据进行预测时,会给出数据属于哪种类别,以及属于这种类别的概率。
- 多分类:多分类算法适合目标字段有多种类别,但类别数量有限且可枚举的情况。训练出的模型对数据进行预测时,会给出数据属于哪种类别,以及属于这种类别的概率。
- 回归:回归算法适合目标字段为连续数值的情况。训练出的模型对数据进行预测时,会给出数据对应的数值。
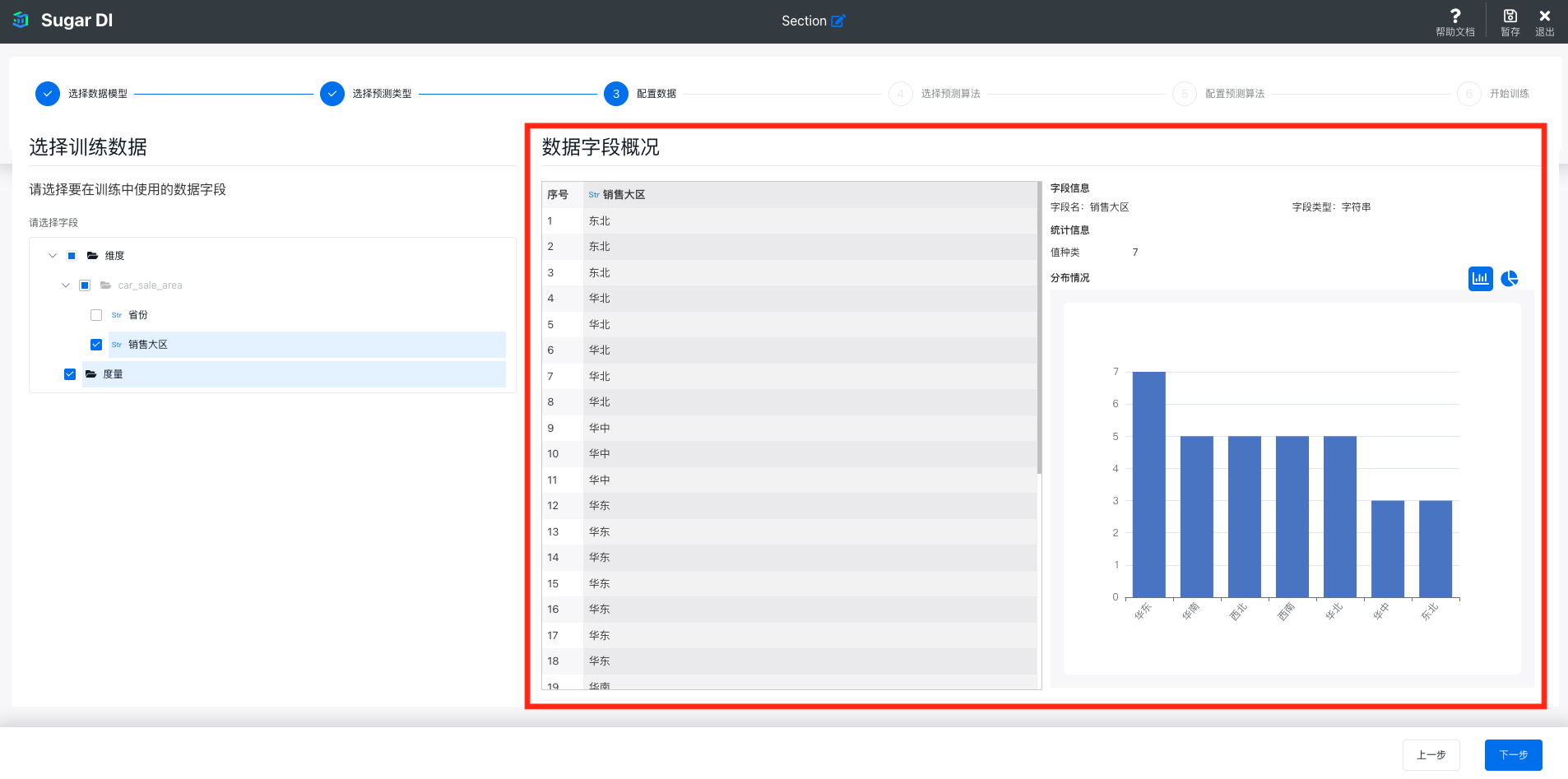
选择训练数据
第三步是从数据模型中选择除目标字段外,用于训练的其他数据字段。算法会根据这些字段和目标字段的关系,学习如何通过这些字段推理出目标字段。这些字段也是将来在进行预测时,需要提供给预测服务的输入字段。
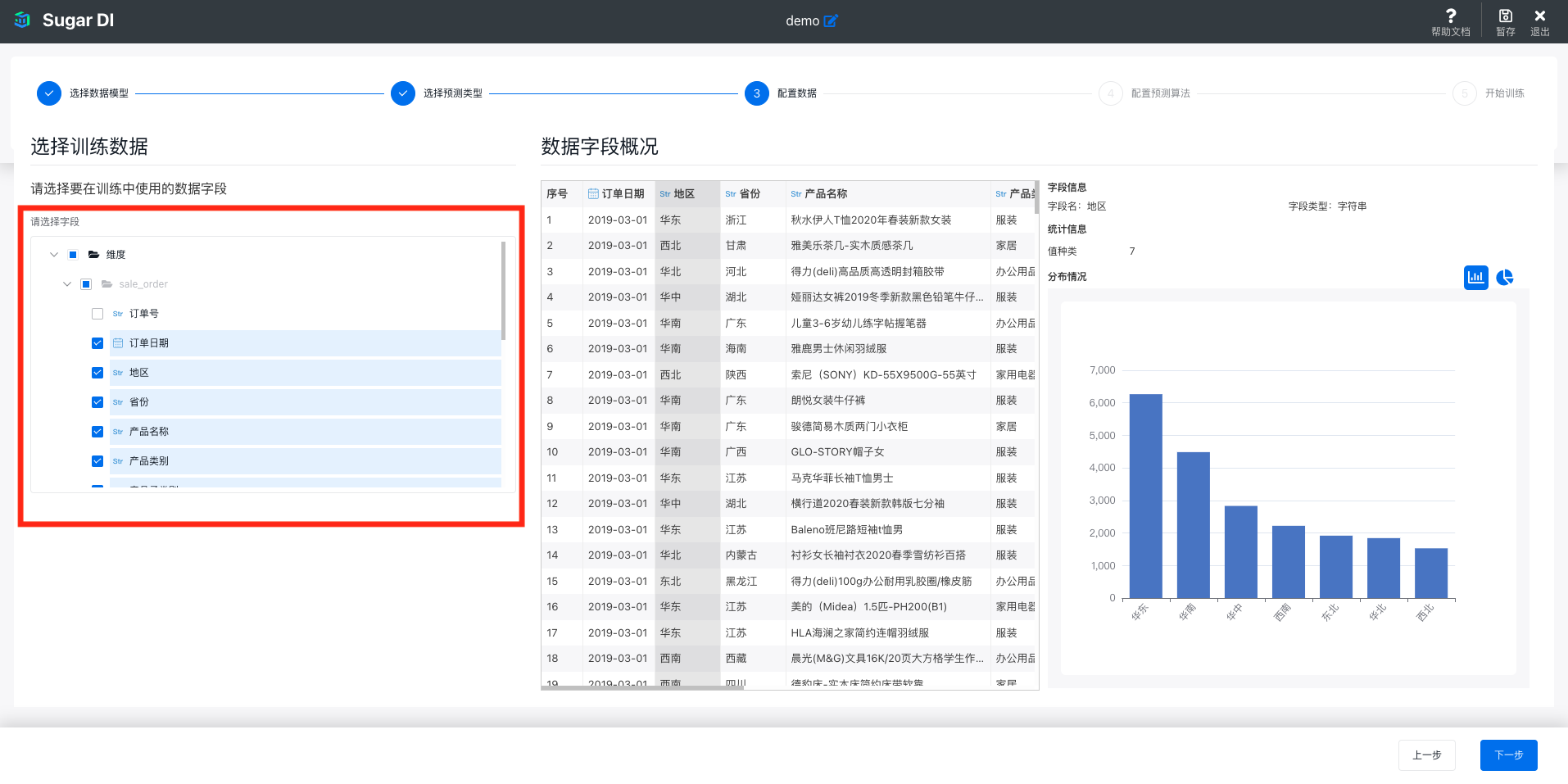
同样的,在选择字段后,可以在右侧查看这些字段的数据预览,选择某个具体字段后,可以查看这个字段中数据的统计信息和图表:
选择预测算法
如果在第二步选择算法类型中选择的是 AutoML,这一步会自动跳过。
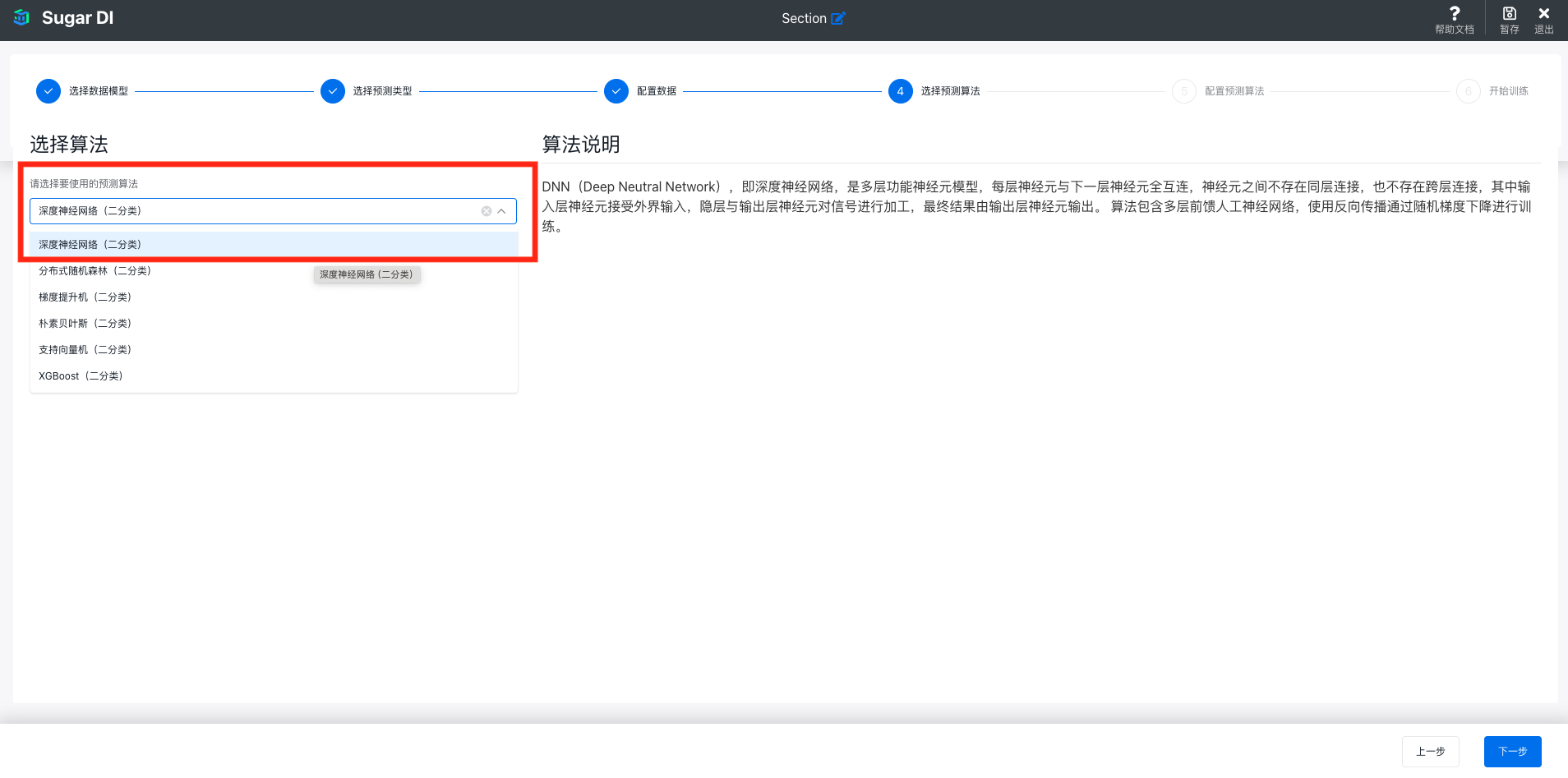
如果选择的是其他的选项,需要在这里选择使用哪种算法训练模型。
目前支持的算法种类如下:
-
二分类
- 分布式随机森林
- 梯度提升机
- 朴素贝叶斯
- 支持向量机
- 深度神经网络
- XGBoost
-
多分类
- 分布式随机森林
- 梯度提升机
- 朴素贝叶斯
- 支持向量机
- 深度神经网络
- XGBoost
-
回归
- 分布式随机森林
- 梯度提升机
- 深度神经网络
- XGBoost
算法的说明可以在选择之后在右侧查看:
配置预测算法
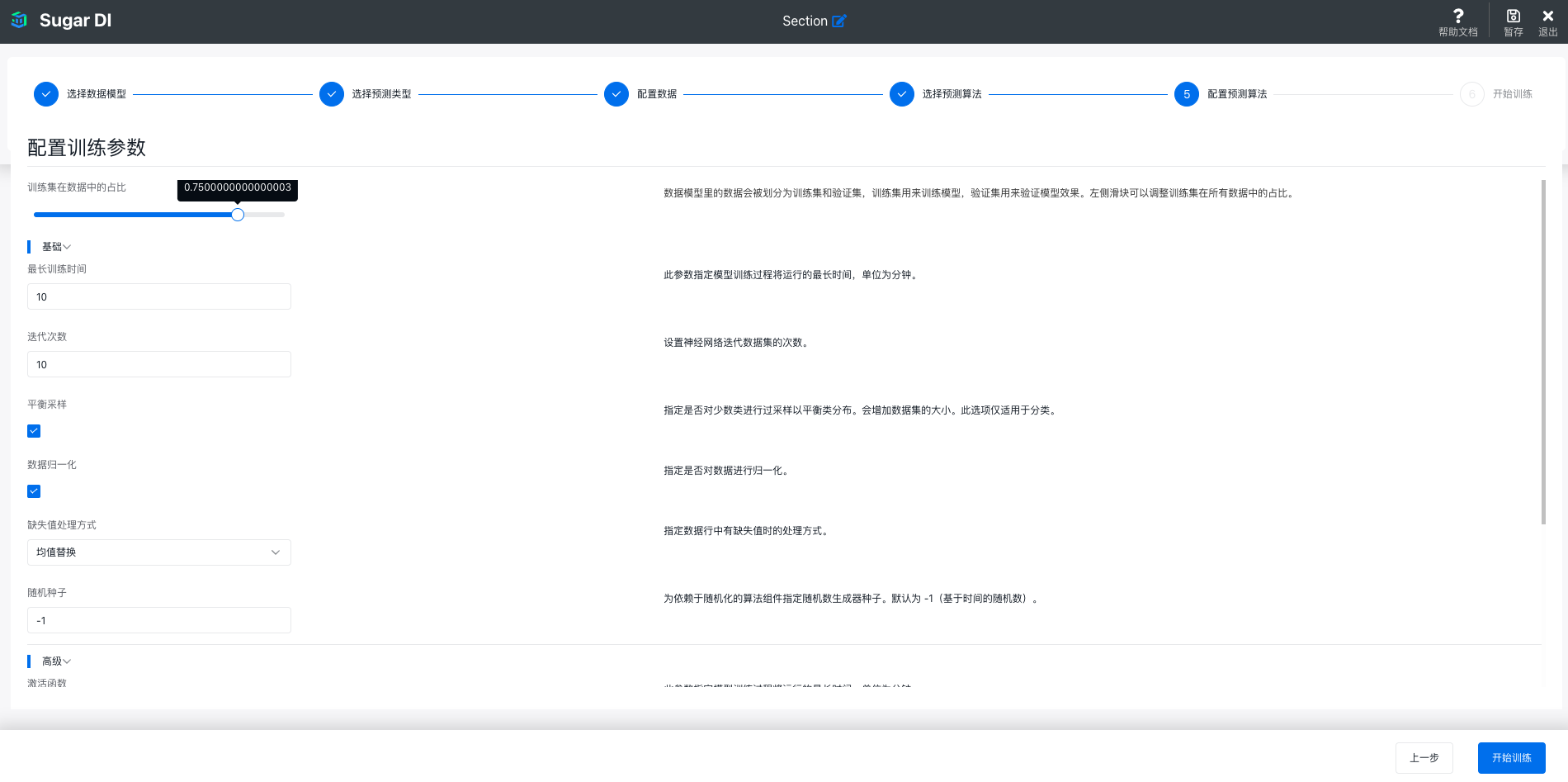
最后一步是配置预测算法的参数,如果选择 AutoML,这里只需要配置训练 / 验证集划分比例,最长训练时间等参数即可,每一项参数的意义在配置的后面有说明:
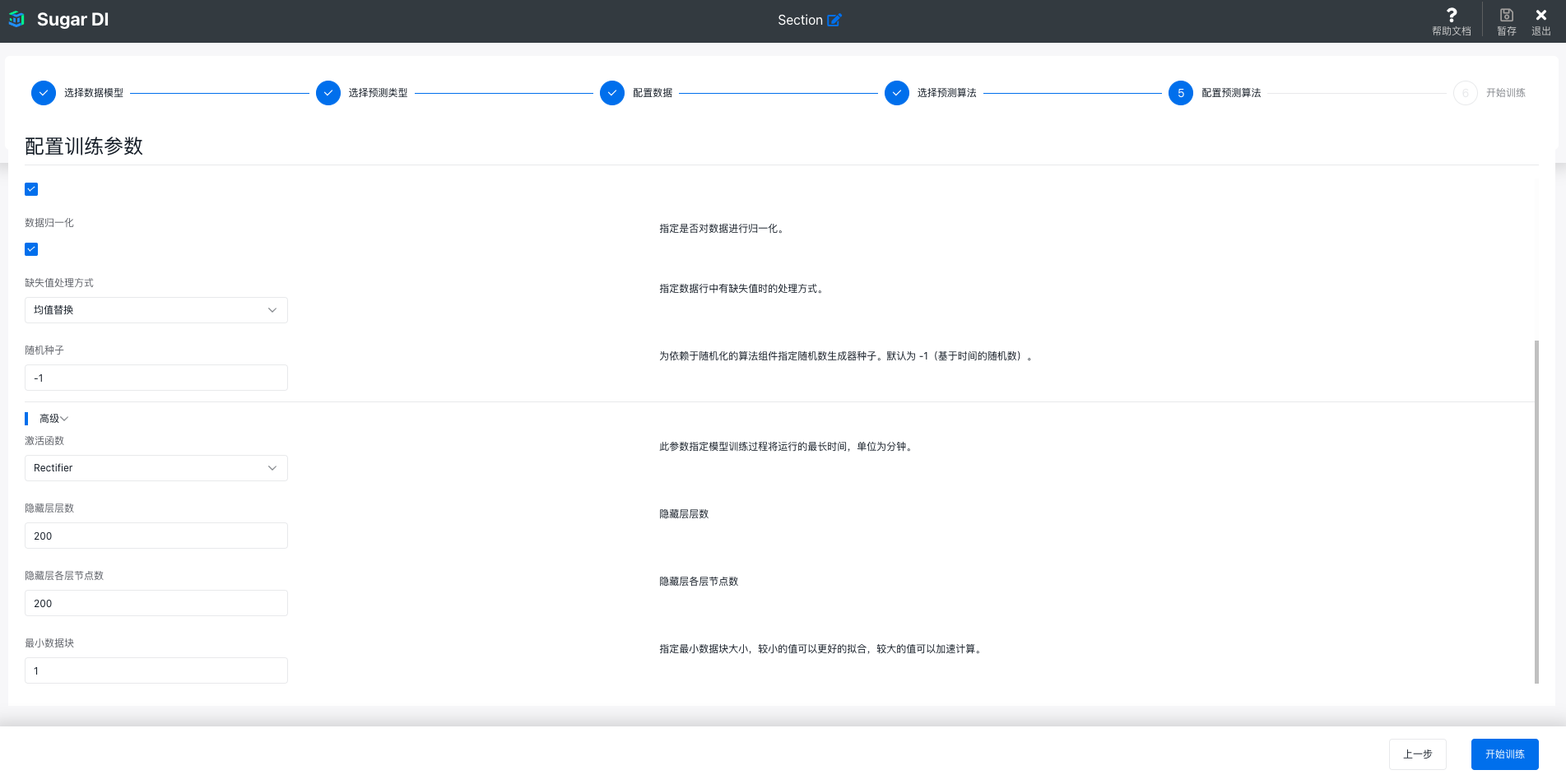
如果选择了某种具体的算法,在这步可以根据数据和业务的具体需要,配置算法的训练参数,每一项参数的意义在配置的后面有说明:
进行好上述配置之后点击开始训练即可触发训练任务。
训练状态管理
已经触发管理的训练任务可以在训练管理列表中查看状态:
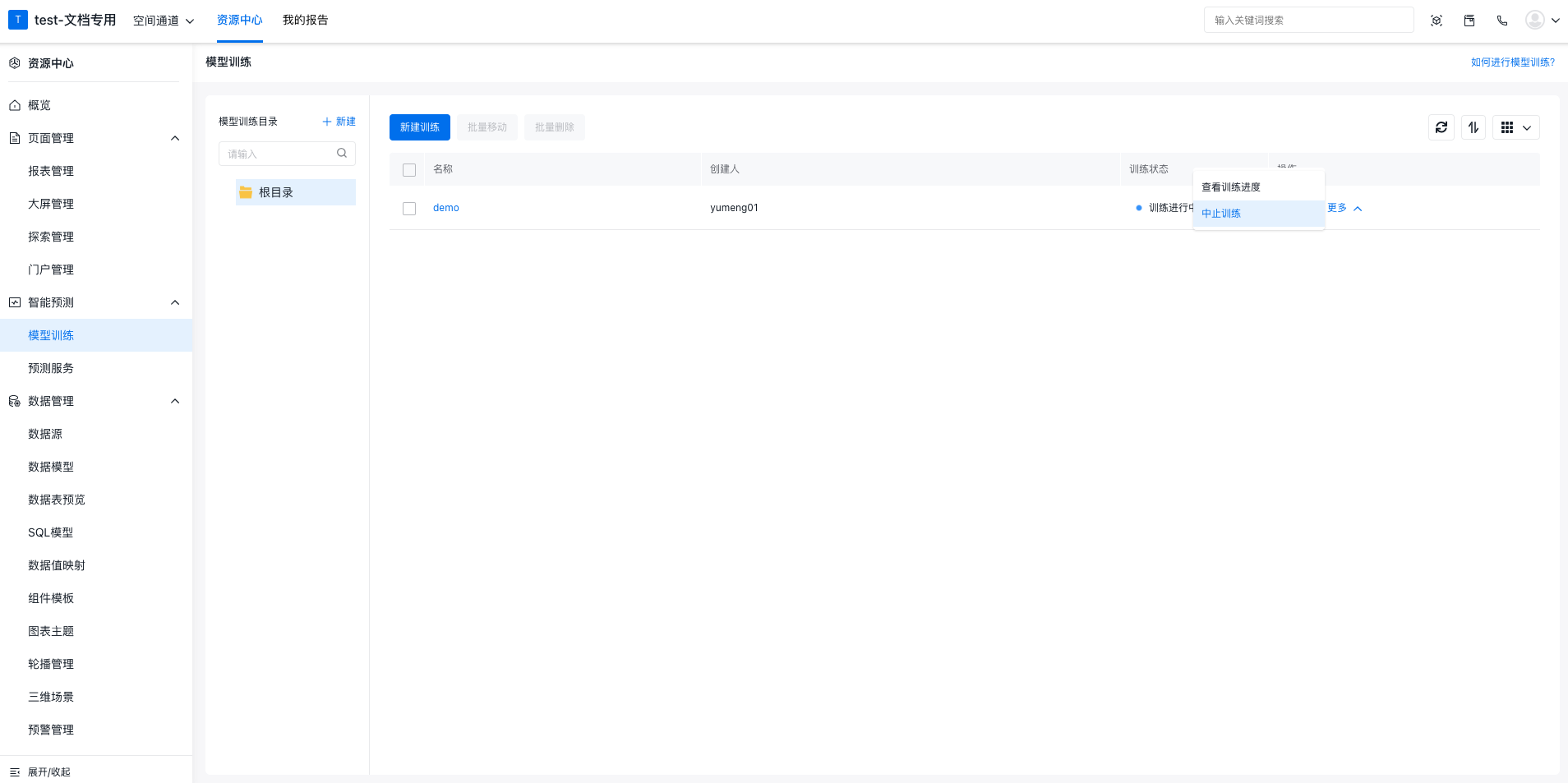
状态有如下几种:
- 待完成训练配置:需要进入训练编辑器完成训练配置后再触发训练。
- 训练准备中:训练任务已排队,待执行。
- 训练进行中:训练任务执行中。
- 训练完成:训练已完成,可以查看和发布预测模型。
- 训练失败:训练任务出错。
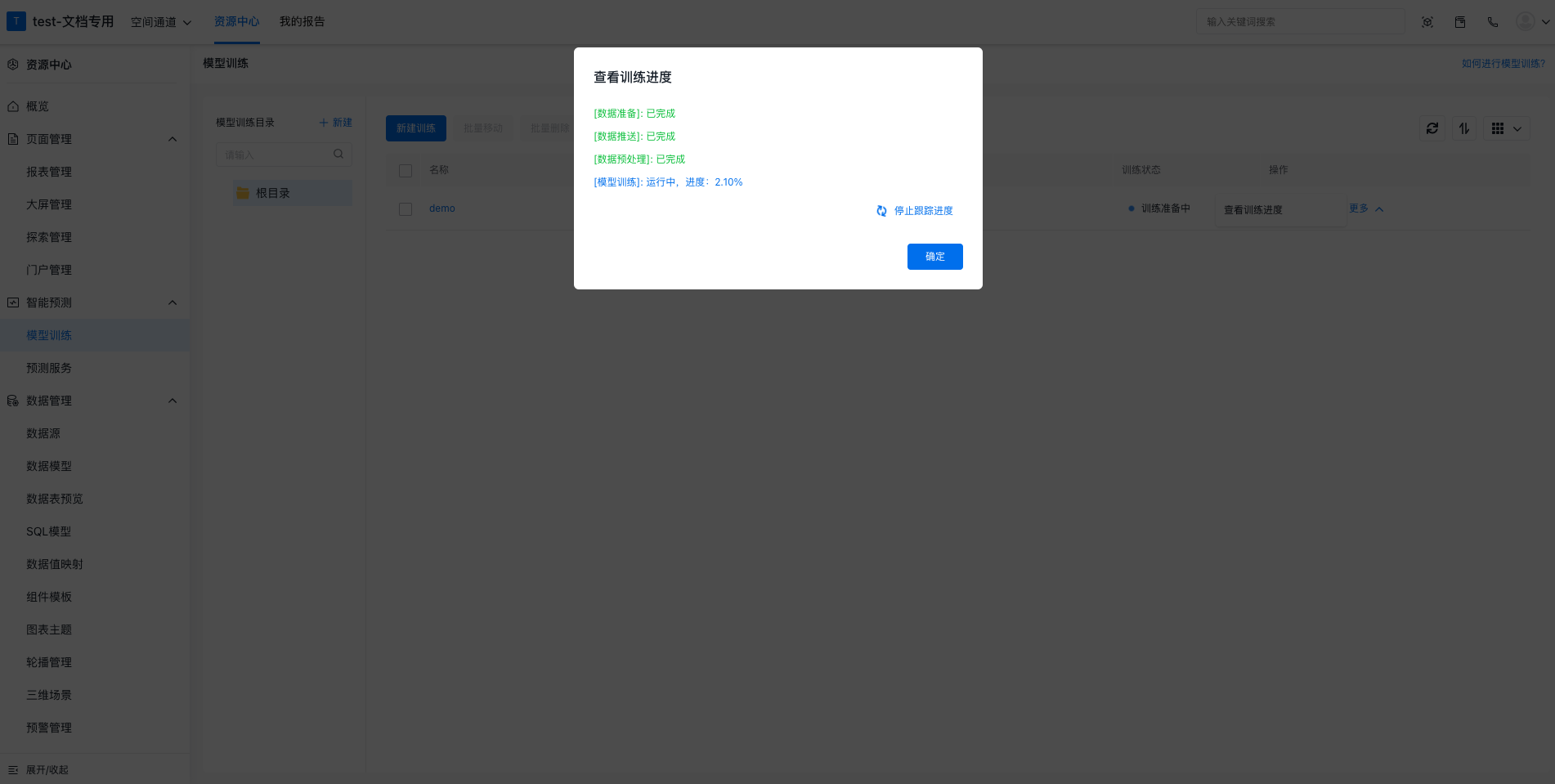
其中,训练进行中和训练失败两种状态,可以通过点击查看训练进度按钮来查看每一步的执行进度和报错信息:
如果在训练进行时想对训练进行重新编辑,需要先点击中止训练按钮停止训练后,再进行编辑和重新训练:
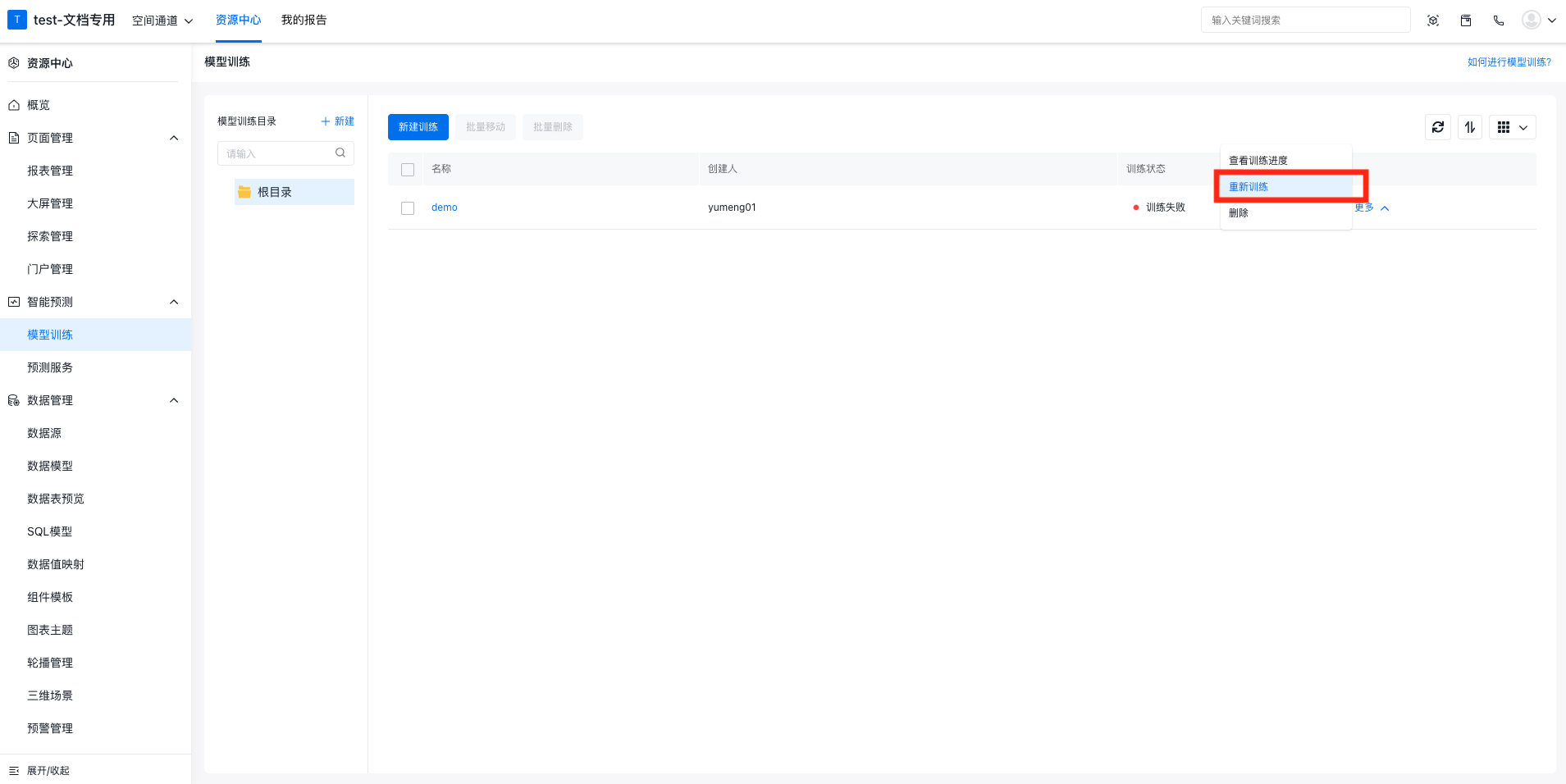
根据训练集群的机器配置不同,对同时训练的任务数有限制,如正在运行的训练任务已达上限,请等待有任务完成后再触发训练。
评价和模型发布
训练完成的预测模型会被暂存,需要进行发布后才能用于后续流程中。在发布前,您可以查看预测模型的性能参数来决定是否发布模型为服务。
模型的评价
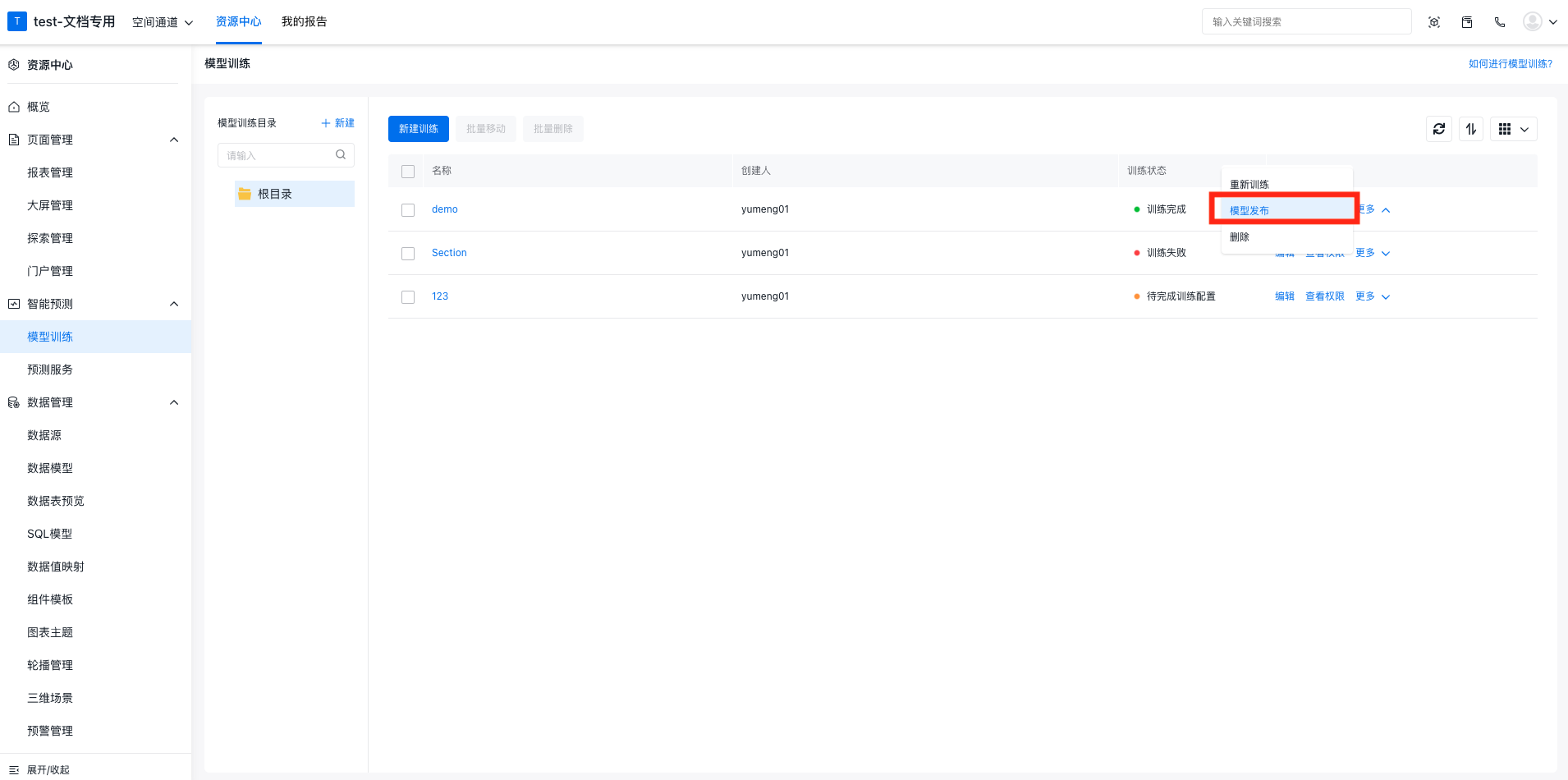
点击对应模型后面的发布按钮可进入模型的评价页面。
对于 AutoML 来说,会给出多个模型训练结果。默认按照该类型模型的主要指标排列,排在第一的是性能最好的模型。如果您对指标比较熟悉,可以按照您需要的指标重新对模型排序。例如下图的二分类模型,就是使用 AUC 作为主指标进行排序的:
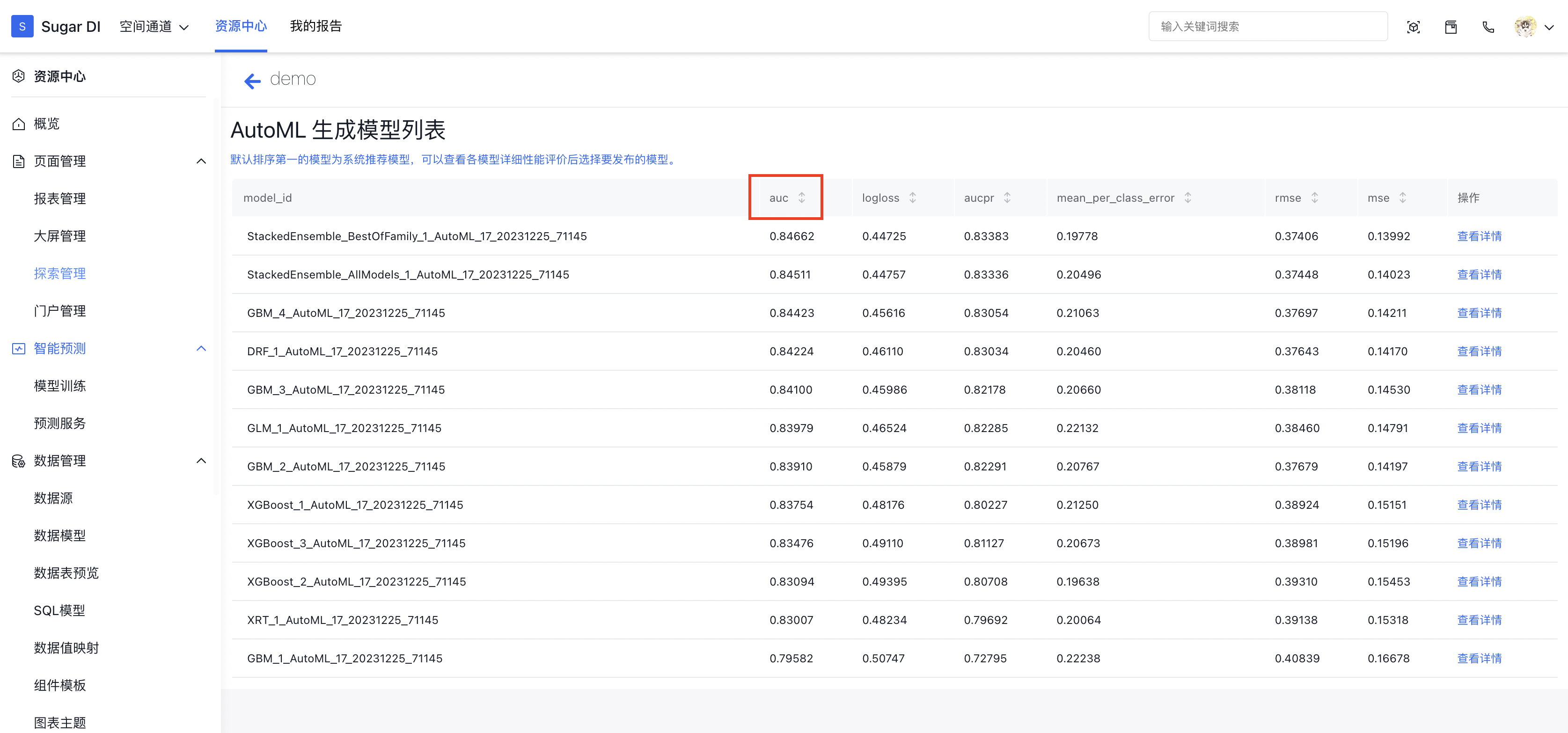
对于感兴趣的模型,可以点击模型后面的查看详情来查看模型的详细参数:
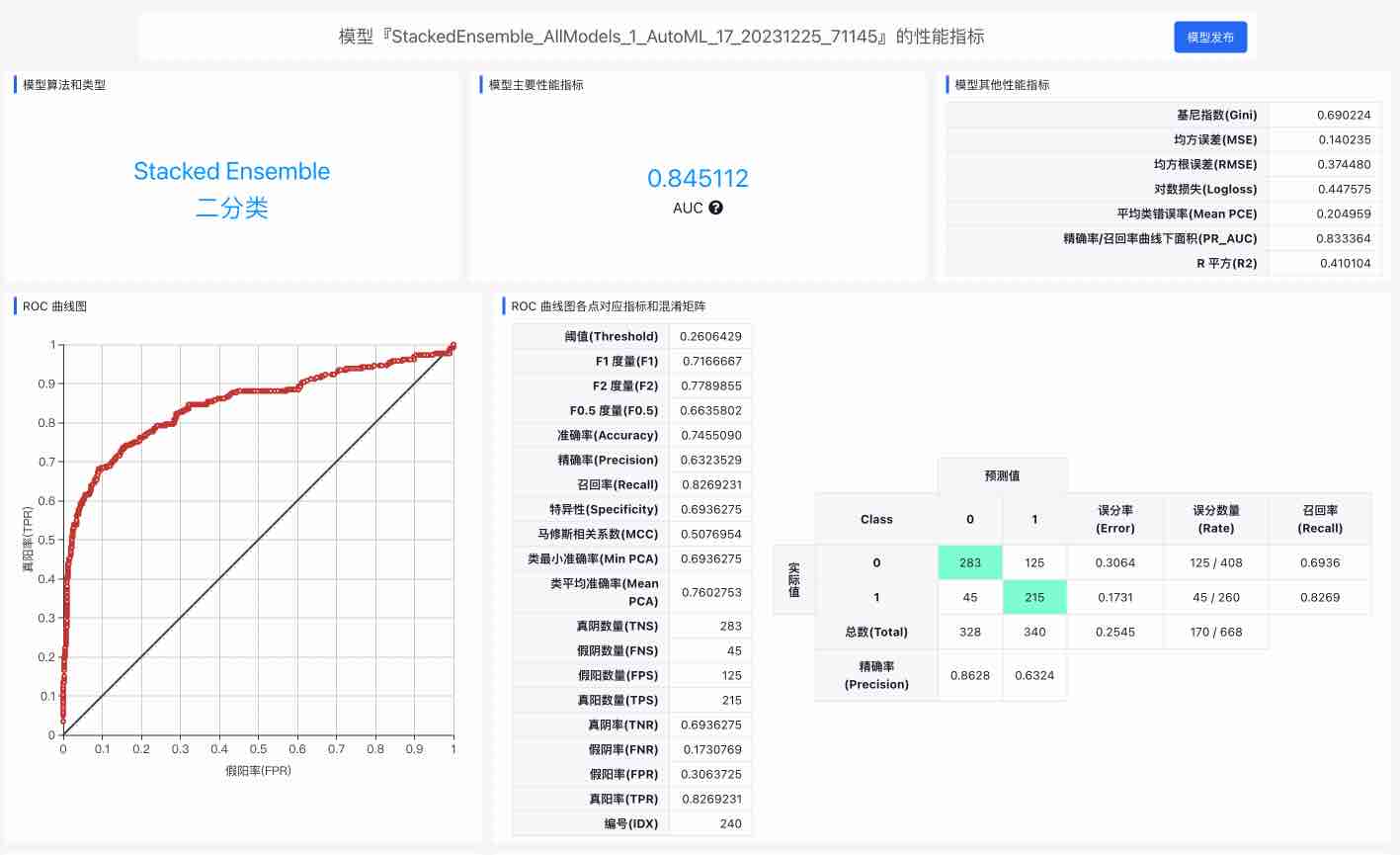
对于非 AutoML 训练来说,模型的评价页面直接就是上图这样展示单个模型的详细参数。
不同类型的预测模型可查看的性能参数和图表不同,您可以根据这些图表和参数决定要发布的模型。
在确定好要发布的模型后,可以点击模型发布按钮进行发布。
训练好但未发布的预测模型会根据训练集群资源使用情况自动清理,如需在后续流程中使用,请及时发布模型。如发现模型被清理,重新训练模型后再发布即可。
模型的发布
模型的发布有两种发布模式,新增和更新现有服务:
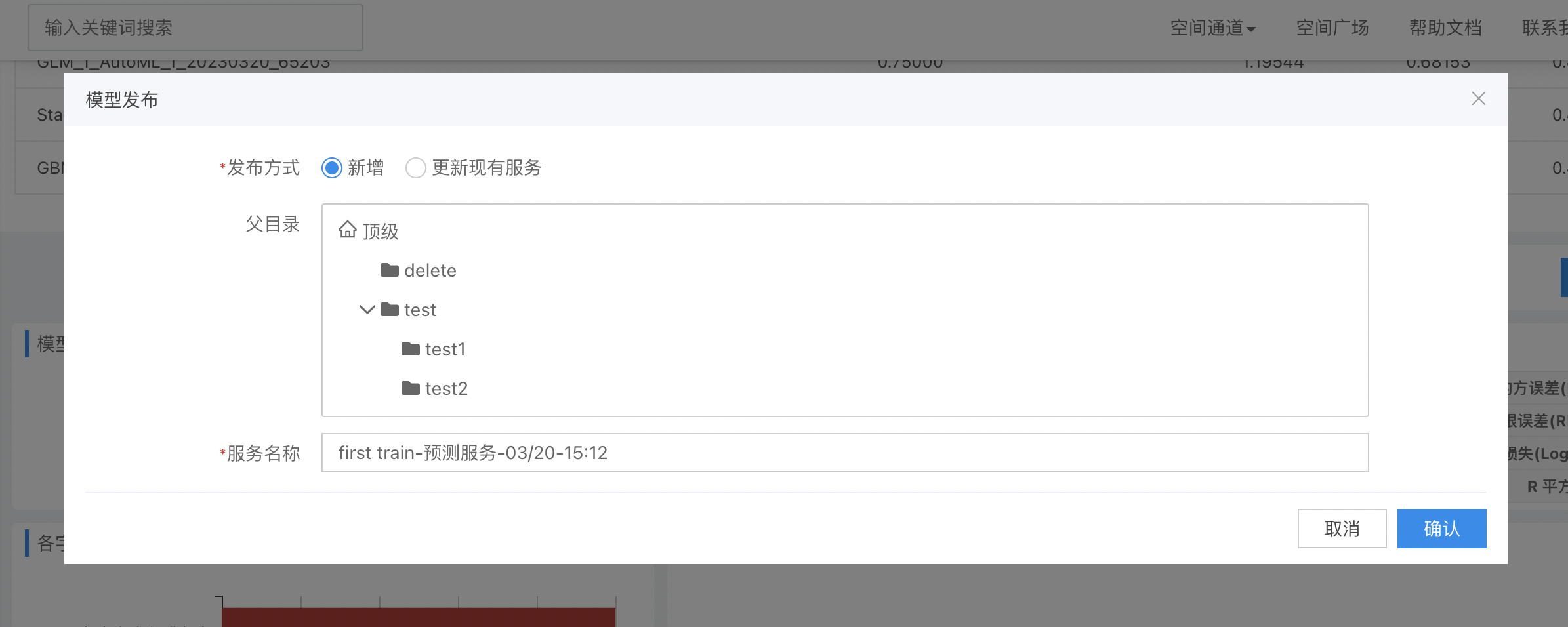
新增模式下选择文件夹填好服务名称即可发布。
更新现有服务时需要注意,此时的更新会直接覆盖已发布的预测服务,后续流程中使用原预测服务的地方,会被新版本的预测服务替代。所以被更新的预测服务需要符合以下要求:
- 新旧预测服务属于同一个训练
- 新旧预测的输入字段相同
- 新旧预测服务的预测模型属于同一个类型,如都是二分类模型
模型发为服务后,会出现在预测服务的列表中
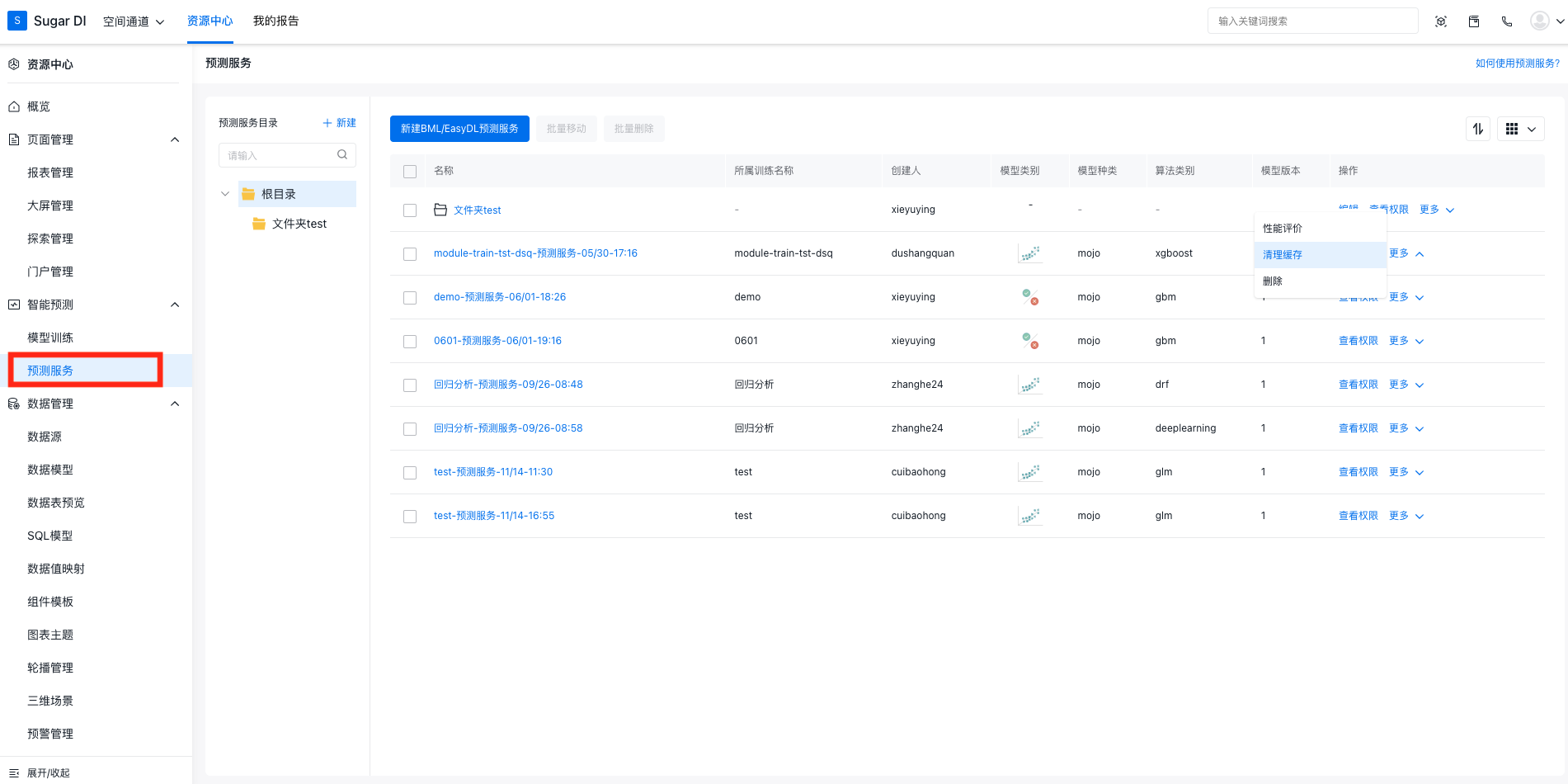
预测服务的管理
从左侧导航栏进到「预测服务」页面中,可以看到当前空间中所有的预测服务。在这里,对于模型训练所产出的服务可以查看服务的性能评价、管理预测服务的权限以及清理该服务的数据缓存。
预测服务的使用
已发布的预测服务可以在后续的数据模型和报表中使用,使用方式请参考预测服务。
评价此篇文章