
Redis Pipeline 机制介绍
概述
Redis Pipeline 是一种将多个命令打包并一次性发送到 Redis 服务器的机制,它可以有效提高执行命令的效率,可大幅提升吞吐量,从而增强性能。
工作原理
在传统的客户端与 Redis 通信模式(Ping-pong 模式)中,客户端发送一个命令后需等待其执行结果,收到结果后才发送下一个命令。这种模式适合交互式操作,但在处理大量命令时,网络往返时延(Round-trip time, RTT)可能成为性能瓶颈。 相比之下,Pipeline 模式允许客户端将多个命令一次性发送给服务器,无需等待每个命令的响应。客户端在发送完所有命令后,再开始接收响应。下图为Ping-Pong模式与Pipeline模式的示意图:
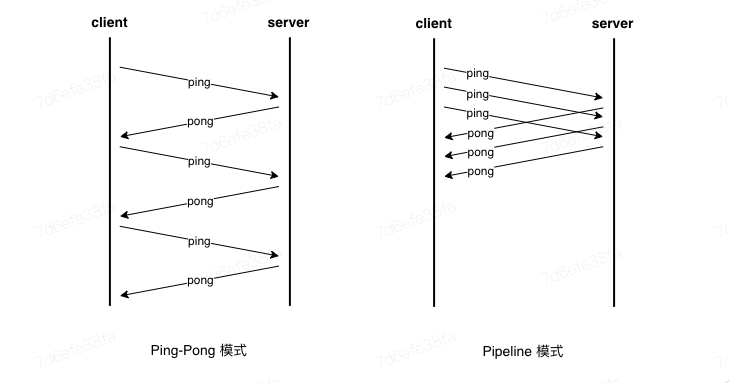
客户端无需等待前面命令执行完成就发送后续命令,命令可以源源不断地到达 server 被处理,这就消除了网络延迟的影响。在需要批量写入和批量查询时,使用 pipeline 可以有效提升单位时间内处理的命令数量。 另外,一次性发送多条命令,可大幅减少执行 write 的次数,同时 server 一个 read 操作就可以从 socket 中读取出多条命令,而执行命令的代价常常低于从 socket 中读取命令,因此合理的使用 pipeline 可有效降低处理同等数据量的命令的耗时CPU资源消耗。
使用 pipeline 的注意事项
pipeline 不保证原子性
一个 Pipeline 中的命令不保证被原子性地执行,因为 pipeline 模式仅仅是一次性发送多条命令,在 server 端,这些命令不能保证被一次性从 socket 中读取出来,也不会保证被一次性处理。一个 pipeline 中的命令在处理时,可能会穿插执行其他客户端的命令。
pipeline 不支持回滚
如果在 Pipeline 执行过程中发生错误,不支持回滚。如果命令之间存在依赖关系,应避免使用 Pipeline。
避免使用过长的 pipeline
当需要大批量地写入数据时,有的用户常常采用很长的 pipeline 来写入数据,而这很可能不够高效。云数据库 Redis集群中包含多个 Proxy 节点,客户端发送 pipeline 时会选择一条连接来发送。如果 pipeline 很长,则这些命令均会由某一个 proxy 来处理,而其他的 proxy 可能会处于空闲状态。 在需要大批量地写入数据时,推荐使用较短的 pipeline 并配合连接池来使用,这样可以将长度适中的 pipeline 发送给不同的 Proxy 来处理,这样不至于让某个 Proxy 成为性能瓶颈。
注意 Python 客户端的实现差异
Python 客户端支持使用事务命令 MULTI、EXEC 来模拟 Pipeline,这种方式下,一批命令会被放在在 multi 和 exec 中,这种方式可以保证 pipeline 中命令被原子性地执行。但如果仅仅是为了提升吞吐量,不推荐使用这种方式。
1conn = redis.Redis("127.0.0.1", 6379)
2pipe = conn.pipeline(transaction=True)
3for i in range(1024):
4 pipe.set(f"key_{i}", "value_{i}")
5pipe.execute()评价此篇文章