
避免大 Key 热 Key 实践指南
更新时间:2023-12-20
该如何设计数据结构以避开大Key和热Key?
老生常谈的大Key和热Key,需要拆、需要打散,如上,我们也给出各种类型Value建议大小,怎么拆呢?又如何打散呢? 除了拆和打散,还有没有别的办法呢?下面举一些常见的场景案例。
| 业务使用场景 | 举例 |
|---|---|
| 消息队列 任务记录 |
用户任务记录(读文章,签到,看视频...),比如: Key的设计最好以时间段划分 按月记录 uid:task:202209 而非将所有任务记录到一个Key: uid:task:all 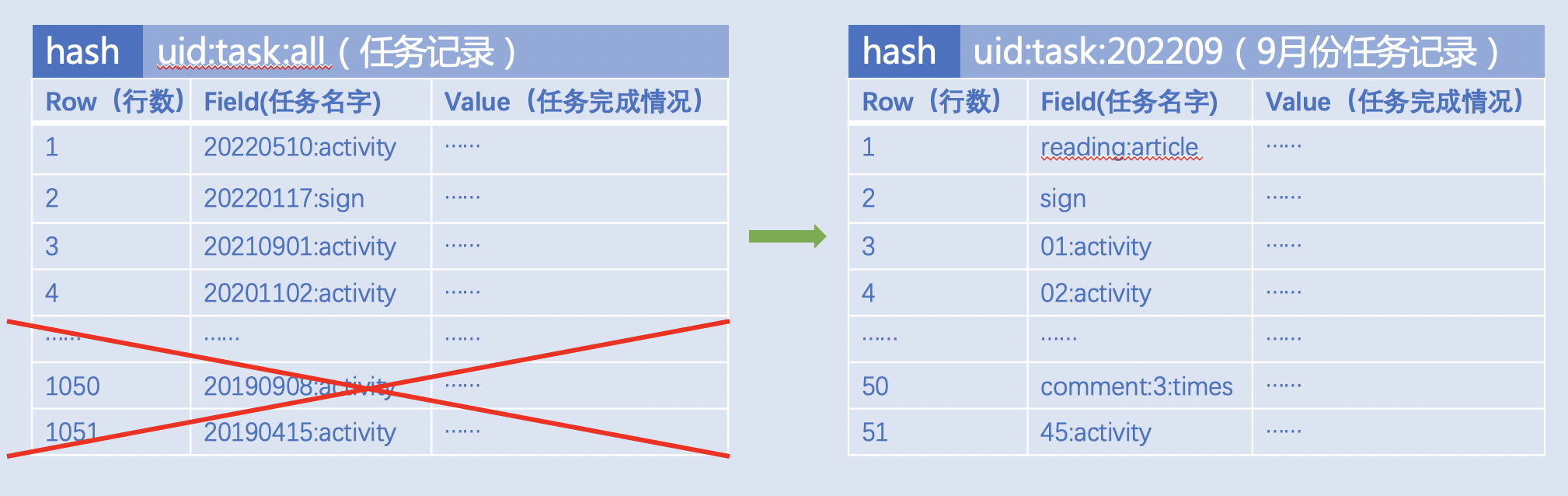 |
注意事项:
- Key名字要设置合理过期时间,避免一个Key中堆积很长时间历史数据。
- 如果预期Key的成员会随着时间增加而变多,建议“HSCAN,SSCAN......”的方式定期清理。
- 消息队列要监控上下游的生产消费速度,或者监控队列长度,避免任务堆积。
| 业务使用场景 | 举例 |
|---|---|
| “可分类的数据” 地域信息 配置信息 活动种类 业务种类 |
根据考生分数查询可报考学校,比如: 将多个地域存一个Key拆开,改为多个地域对应多个Key,比如: “全国考生分数学校对应信息(key)—— 省份_分数段_政史地(field)—— 可以报考学校的信息(value)”, 可以优化成: “云南考生(key)—— 政史地:分数段(field)—— 可以报考学校的信息(value)” 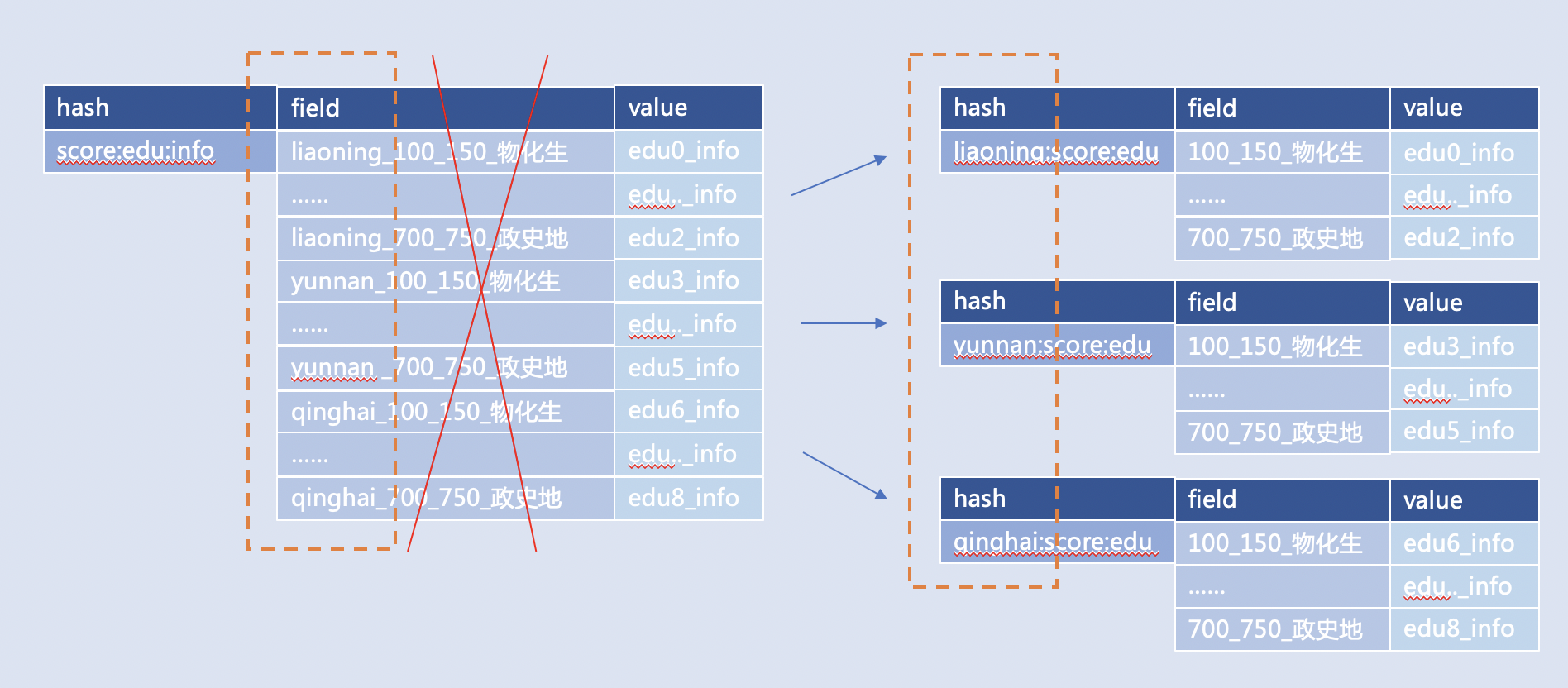 |
注意事项:
- 对于地域,时间,业务种类这种数据,设计Key的粒度要尽可能小,避免出现地域级别热点Key,利用分类将Key打散。
- 有时候设计Key的时候习惯用Key名字对应MySQL表名字,那这个Key的范围就容易很大,我们建议将Key拆开,用一些常用数据库字段对应到Key上。
| 业务使用场景 | 举例 |
|---|---|
| “属性相关信息” 用户信息 设备规格 聊天记录 商品规格 |
记录不同分数段对应的学校信息,比如: 上例中“edu0_info”对应“100-150分数段物化生考生”可报考所有学校的信息,那么所有学校的信息本身是超过4KB的JSON,此时不建议Hash类型Value存储JSON,可以存JSON的Key名字“edu0_info_key” 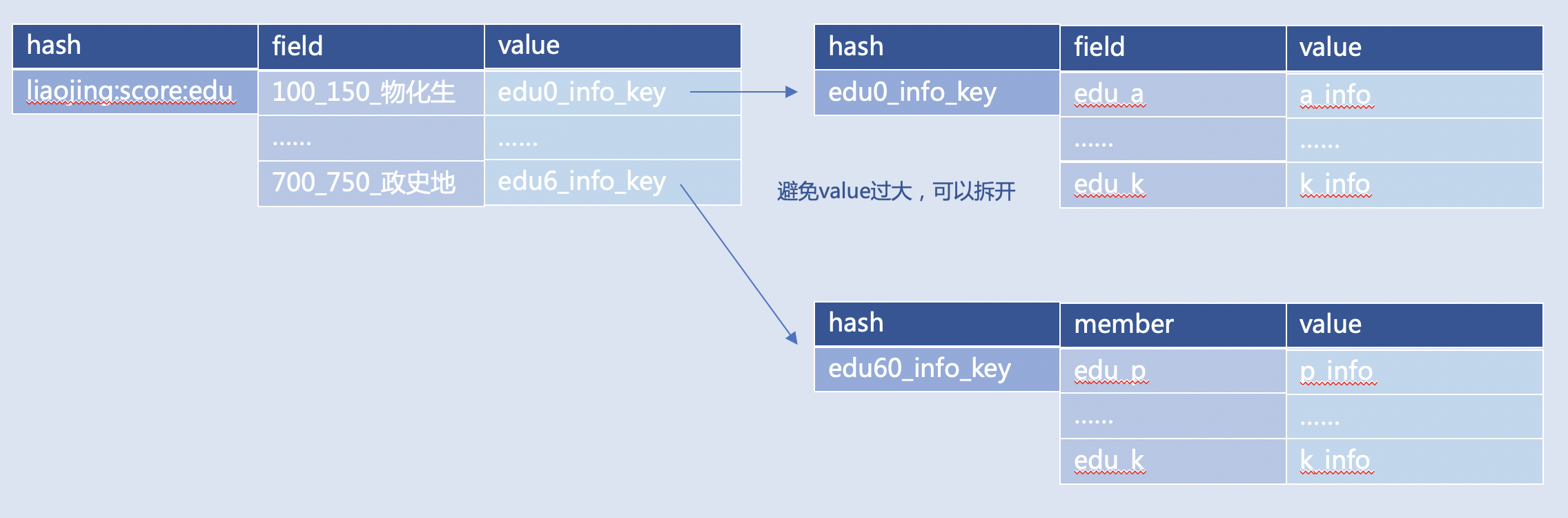 |
注意事项:
- 复合类型元素或者成员的Value建议小于4k,避免HGETALL,LRANGE 0 -1,SMEMBERS 取全集导致Redis压力过大。
- 建议将HGETALL换成HMGET,将LRANGE 0 -1换成LRANGE 0 50获取,SMEMBERS换成SISMEMBER,ZRANGE 0 -1换成ZRANGEBYSCORE加LIMIT。
- 元素或者成员Value建议是字符串,而不建议使用大JSON或者数组,可以将JSON存到单独的Hash或者String类型的Key中。
| 业务使用场景 | 举例 |
|---|---|
| “各种ID” 粉丝列表 视频收藏列表 歌单歌曲列表 文章信息库 关注用户列表 |
某次活动中奖用户记录,比如: 用户ID用1000取模,就可以将用户ID全集的1个Key拆成1000个Key,如果ID很多,可以用ID和ID前2个字符取模两次,按需分段uid#0#0,uid#1#1 ,......, uid#999#99 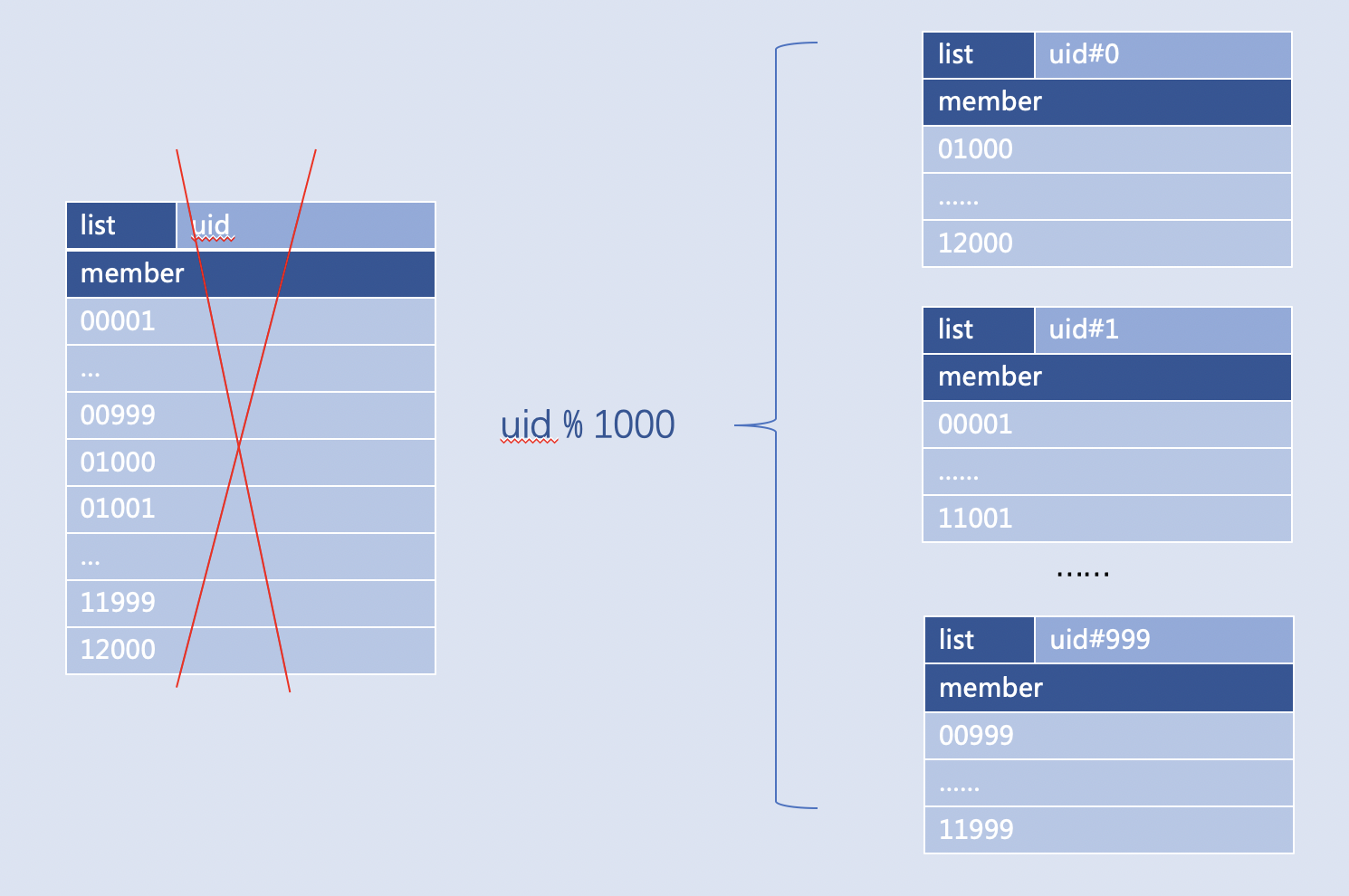 |
注意事项:
- 利用Value在Key的名字上取模,常用在各种ID,即Value是整型,比如用户ID、书籍ID、文章ID。
- Key名字使用的分隔符号不建议使用空格和可能引起运算的符号(“-”,“.”,“+”,“=”,......),建议用 “#”,“:”,“_”。
| 业务使用场景 | 举例 |
|---|---|
| “排序场景” 音乐历史记录排序 文章取热门评论排序 歌手热门歌曲排序 |
音乐播放历史,比如: 使用ZREMRANGEBYRANK 定期控制成员个数在1000左右,减轻ZREVRANK的O(log(N))开销 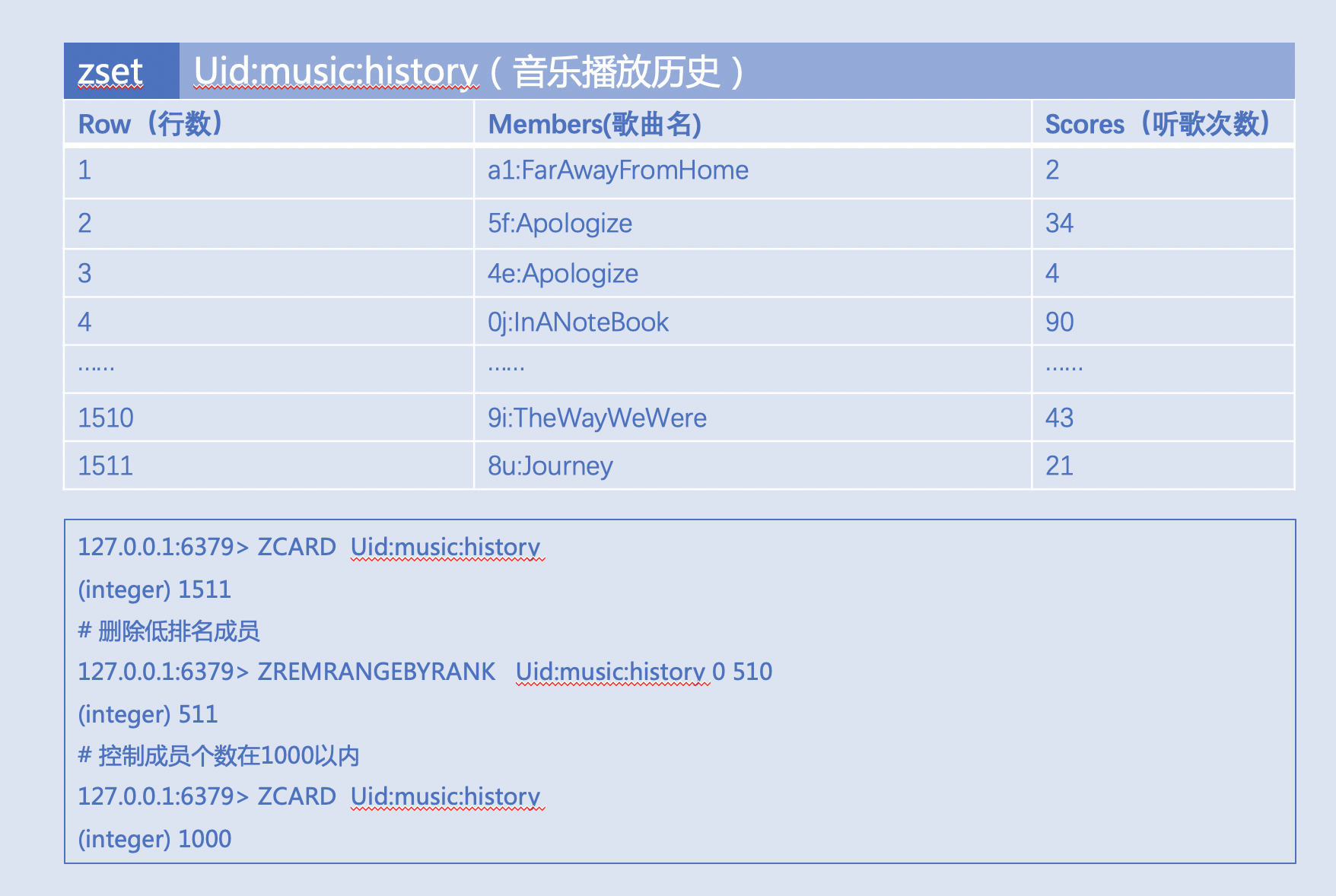 |
注意事项:
- 预期会经常排序的数据,建议控制元素(成员)个数在1000以内。
- ZREMRANGEBYRANK本身复杂度为O(log(N)+M) ,注意使用频率,天级别或者整点或者业务低峰期执行为好。
| 业务使用场景 | 举例 |
|---|---|
| “一对多的关系” 作弊规则 反攻击规则限制 配置应用 权限管理 |
屏蔽黑名单用户,比如: 大Set拆成单个String类型的Key,JSON格式的大String换Hash类型的Key 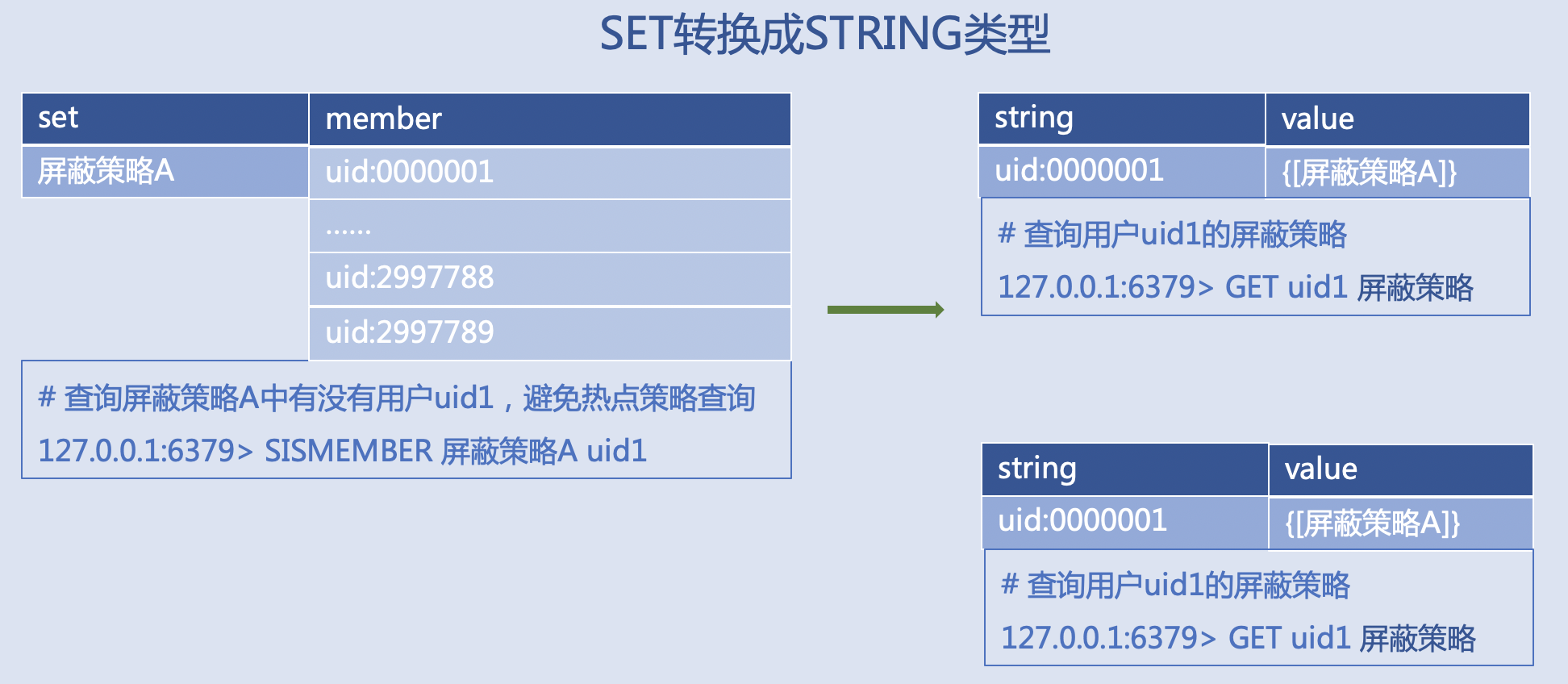 |
注意事项:
- 使用合理的数据类型。
| 业务使用场景 | 举例 |
|---|---|
| “热门场景” 热门直播间商品信息 热门赛事赛程信息 |
查询直播间的商品,比如: 同样的数据存多份备份,随机读一个,读不到再从DB回写 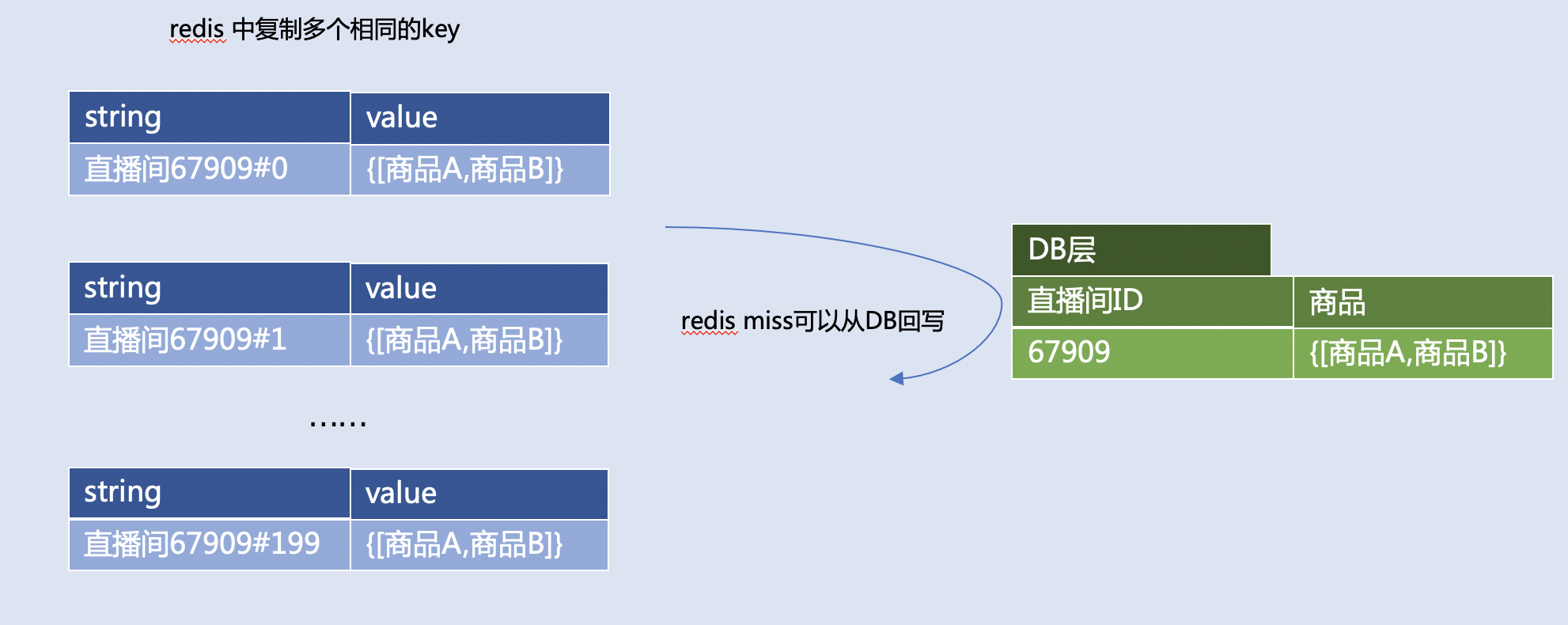 |
注意事项:
- 适合读多写少的数据。
- 最佳实践是,分布式Redis中,备份数据份数可以用Redis集群分片数评估QPS分布,份数最好是集群分片数的一倍及以上。
| 业务使用场景 | 举例 |
|---|---|
| 页面 “默认” 展示 | 查询高考分数线的功能,比如: 需要显示类如【北京】【211】【北京邮电大学】,那么对于这种前端页面打开默认显示的数据不建议从Redis每次动态读取,可以业务侧本地缓存 |
注意事项:
- 如果是常用枚举,或者默认参数的数据,建议代码里保存。
| 业务使用场景 | 举例 |
|---|---|
| “大文本” 大图文 图片内容 小说 长篇文章 博客 评论内容 客服对话 |
将小说文章压缩后存储 |
注意事项:
- JSON和XML换成轻量级的Protobuf。
- 使用Snappy或GZIP压缩。
- 预期Key可能过大,灌入数据的时候,使用EXPIREAT设置过期时间,不要集中到某个时间戳,最好加上随机时间。
| 业务使用场景 | 举例 |
|---|---|
| 所有场景 注意命令时间复杂度及其使用频率 |
比如O(n),O(log(n))以及更高复杂度的,控制元素个数,以及命令使用频率,时间复杂度详见:https://redis.io/commands/ 比如INCR的Key需要设置一天的过期时间,那么可以根据返回结果判断,如果已经大于1,就不需要重复 PEXPIREAT 比如Redis4系及以上可以使用MEMORY USAGE查询Key的内存占用,避免未知Key大小,执行DEBUG OBJECT 造成阻塞 比如 O(N) 的N是成员(元素)总数的慎用或者降低使用频率 |
注意事项:
列举常见又常用的高复杂度命令如下:
- List类型:LRANGE 范围取0 -1时慎用,LREM。
- Hash类型:HKEYS,HVALS,HGETALL。
- Set类型:SINTER / SINTERSTORE,SUNION / SUNIONSTORE,SMEMBERS。
- Sorted Set类型:ZRANGE(...) 范围取0 -1时慎用,ZREVRANGE(...)。ZREMRANGEBY(...),ZUNION(...)。
- Geo 类型:GEOHASH,GEORADIUS(...),GEOSEARCH(...)。
- 其他:KEYS,MONITOR,DEBUG。
评价此篇文章