
使用 CCE AITraining Operator 实现弹性容错训练
更新时间:2022-12-01
在CCE中使用AI Training Operator与Horovod训练框架实现分布式训练的弹性与容错功能。
模型训练是深度学习中重要的环节,模型复杂的训练任务有运行时间长、算力需求大的特征。传统分布式深度学习任务中,一旦提交训练任务,无法在运行中动态调整Workers的数量。通过弹性模型训练,可以为深度学习的模型训练任务提供动态修改Workers数量的能力。同时容错的功能能保证在训练任务异常情况下如节点异常故障导致Pod驱逐,重新为异常的Worker调度新的节点继续执行任务,而不会某因某个Worker异常中断整个训练任务。
环境需求
- CCE中安装AI Training Operator组件。
- 使用Horovod/paddlepaddle作为分布式训练框架。
组件安装
- 在CCE控制台安装AITrainingOperator组件。
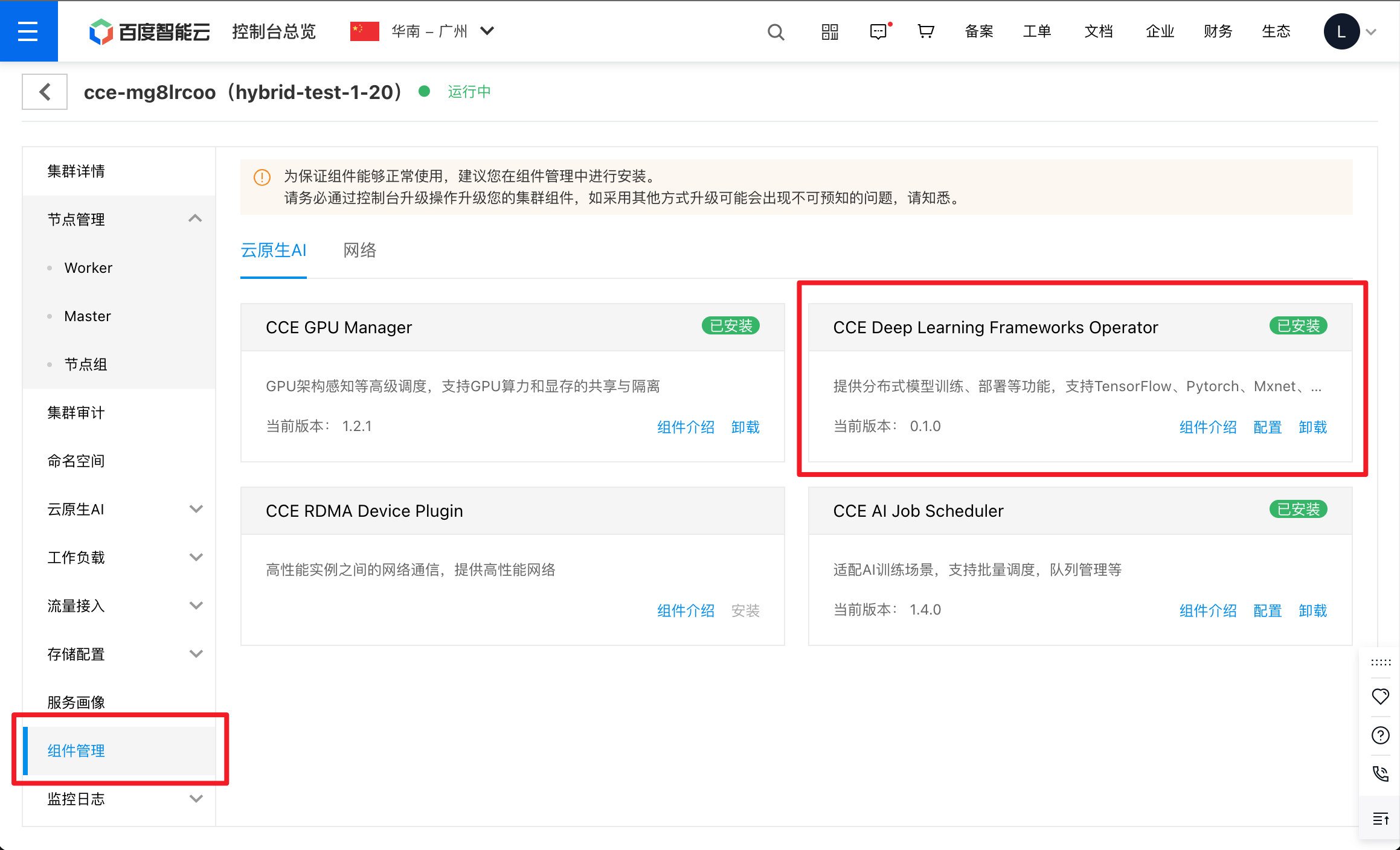
- 勾选CCE Training确认安装。
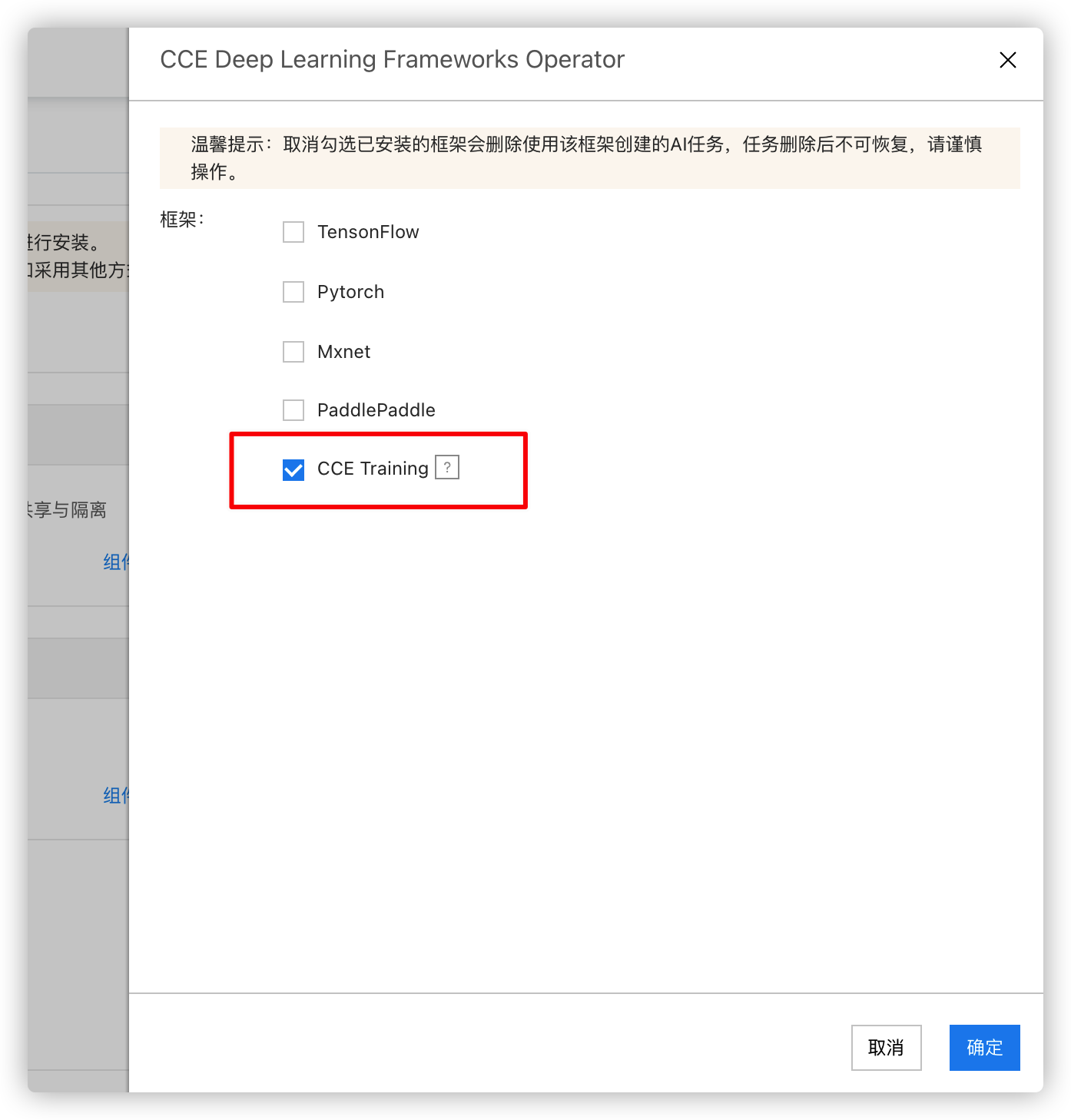
任务提交
在CCE集群控制台 → 云原生 AI → 任务管理中提交任务,选择框架:AITrainingJob,若需要支持任务容错需要勾选容错功能以开启(弹性任务训练也需开启容错支持)。
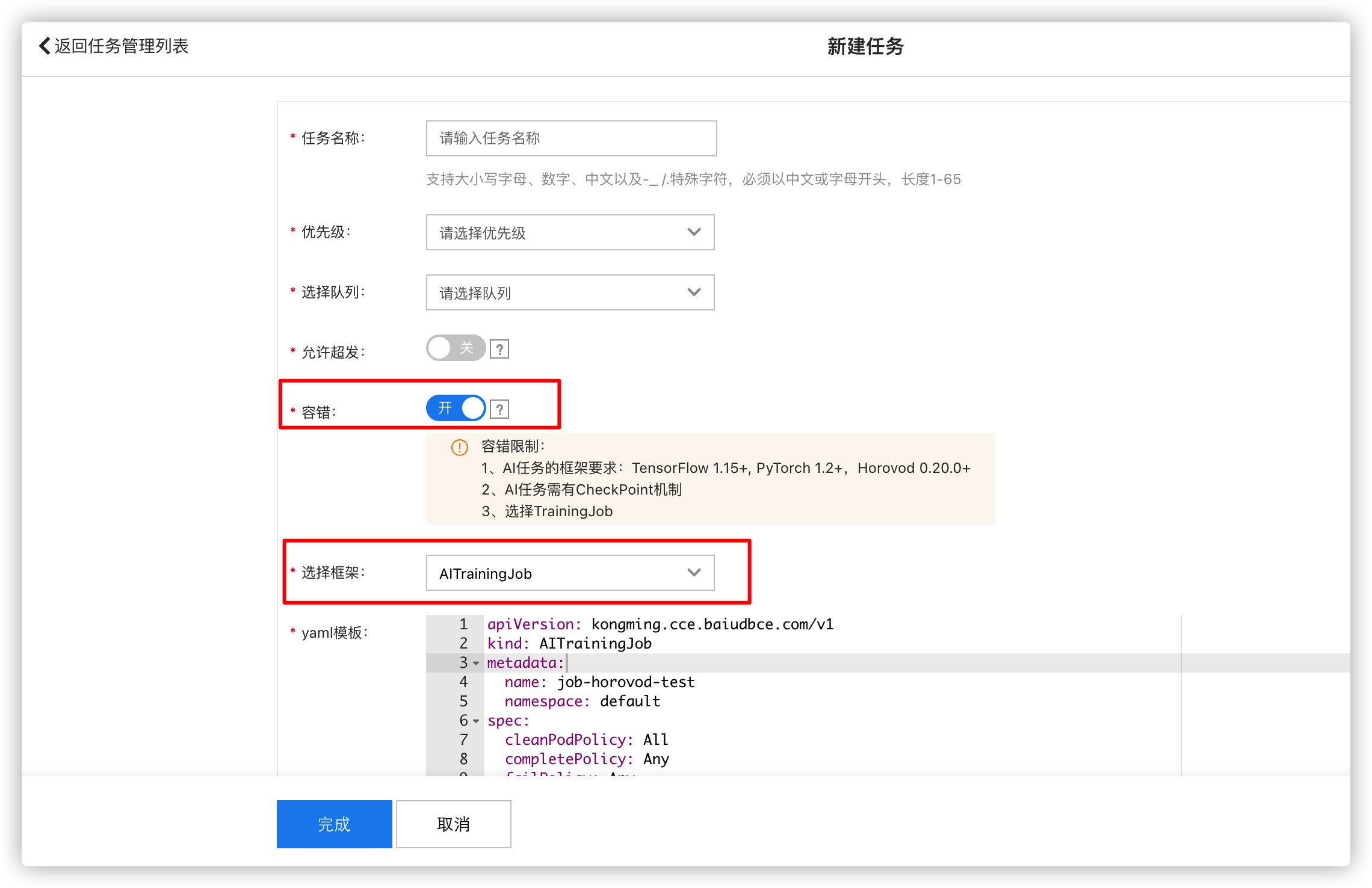
生成弹性容错训练任务YAML模版:
YAML
1apiVersion: kongming.cce.baiudbce.com/v1
2kind: AITrainingJob
3metadata:
4 name: test-horovod-elastic
5 namespace: default
6spec:
7 cleanPodPolicy: None
8 completePolicy: Any
9 failPolicy: Any
10 frameworkType: horovod
11 faultTolerant: true
12 plugin:
13 ssh:
14 - ""
15 discovery:
16 - ""
17 priority: normal
18 replicaSpecs:
19 launcher:
20 completePolicy: All
21 failPolicy: Any
22 faultTolerantPolicy:
23 - exitCodes: 129,101
24 restartPolicy: ExitCode
25 restartScope: Pod
26 - exceptionalEvent: nodeNotReady
27 restartPolicy: OnNodeFail
28 restartScope: Pod
29 maxReplicas: 1
30 minReplicas: 1
31 replicaType: master
32 replicas: 1
33 restartLimit: 100
34 restartPolicy: OnNodeFailWithExitCode
35 restartScope: Pod
36 restartTimeLimit: 60
37 restartTimeout: 864000
38 template:
39 metadata:
40 creationTimestamp: null
41 spec:
42 initContainers:
43 - args:
44 - --barrier_roles=trainer
45 - --incluster
46 - --name=$(TRAININGJOB_NAME)
47 - --namespace=$(TRAININGJOB_NAMESPACE)
48 - --dns_check_svc=kube-dns
49 image: registry.baidubce.com/cce-plugin-dev/jobbarrier:v0.9-1
50 imagePullPolicy: IfNotPresent
51 name: job-barrier
52 restartPolicy: Never
53 schedulerName: volcano
54 terminationMessagePath: /dev/termination-log
55 terminationMessagePolicy: File
56 securityContext: {}
57 containers:
58 - command:
59 - /bin/bash
60 - -c
61 - export HOROVOD_GLOO_TIMEOUT_SECONDS=300 && horovodrun -np 3 --min-np=1 --max-np=5 --verbose --log-level=DEBUG --host-discovery-script /etc/edl/discover_hosts.sh python /horovod/examples/elastic/pytorch/pytorch_synthetic_benchmark_elastic.py --num-iters=1000
62 env:
63 image: registry.baidubce.com/cce-plugin-dev/horovod:master-0.2.0
64 imagePullPolicy: Always
65 name: aitj-0
66 resources:
67 limits:
68 cpu: "1"
69 memory: 1Gi
70 requests:
71 cpu: "1"
72 memory: 1Gi
73 volumeMounts:
74 - mountPath: /dev/shm
75 name: cache-volume
76 dnsPolicy: ClusterFirstWithHostNet
77 terminationGracePeriodSeconds: 30
78 volumes:
79 - emptyDir:
80 medium: Memory
81 sizeLimit: 1Gi
82 name: cache-volume
83 trainer:
84 completePolicy: None
85 failPolicy: None
86 faultTolerantPolicy:
87 - exceptionalEvent: "nodeNotReady,PodForceDeleted"
88 restartPolicy: OnNodeFail
89 restartScope: Pod
90 maxReplicas: 5
91 minReplicas: 1
92 replicaType: worker
93 replicas: 3
94 restartLimit: 100
95 restartPolicy: OnNodeFailWithExitCode
96 restartScope: Pod
97 restartTimeLimit: 60
98 restartTimeout: 864000
99 template:
100 metadata:
101 creationTimestamp: null
102 spec:
103 containers:
104 - command:
105 - /bin/bash
106 - -c
107 - /usr/sbin/sshd && sleep infinity
108 image: registry.baidubce.com/cce-plugin-dev/horovod:master-0.2.0
109 imagePullPolicy: Always
110 name: aitj-0
111 env:
112 - name: NVIDIA_DISABLE_REQUIRE
113 value: "true"
114 - name: NVIDIA_VISIBLE_DEVICES
115 value: "all"
116 - name: NVIDIA_DRIVER_CAPABILITIES
117 value: "all"
118 resources:
119 limits:
120 baidu.com/v100_32g_cgpu: "1"
121 baidu.com/v100_32g_cgpu_core: "20"
122 baidu.com/v100_32g_cgpu_memory: "4"
123 requests:
124 baidu.com/v100_32g_cgpu: "1"
125 baidu.com/v100_32g_cgpu_core: "20"
126 baidu.com/v100_32g_cgpu_memory: "4"
127 volumeMounts:
128 - mountPath: /dev/shm
129 name: cache-volume
130 dnsPolicy: ClusterFirstWithHostNet
131 terminationGracePeriodSeconds: 300
132 volumes:
133 - emptyDir:
134 medium: Memory
135 sizeLimit: 1Gi
136 name: cache-volume
137 schedulerName: volcano指定3个Worker并提交运行:
Plain Text
1NAME READY STATUS RESTARTS AGE
2test-horovod-elastic-launcher-vwvb8-0 0/1 Init:0/1 0 6s
3test-horovod-elastic-trainer-q7gmp-0 1/1 Running 0 7s
4test-horovod-elastic-trainer-spkb8-1 1/1 Running 0 7s
5test-horovod-elastic-trainer-sxf6s-2 1/1 Running 0 7s弹性场景
在CCE控制台中对正在运行的训练任务动态修改Worker数量,并指定扩容超时时间。
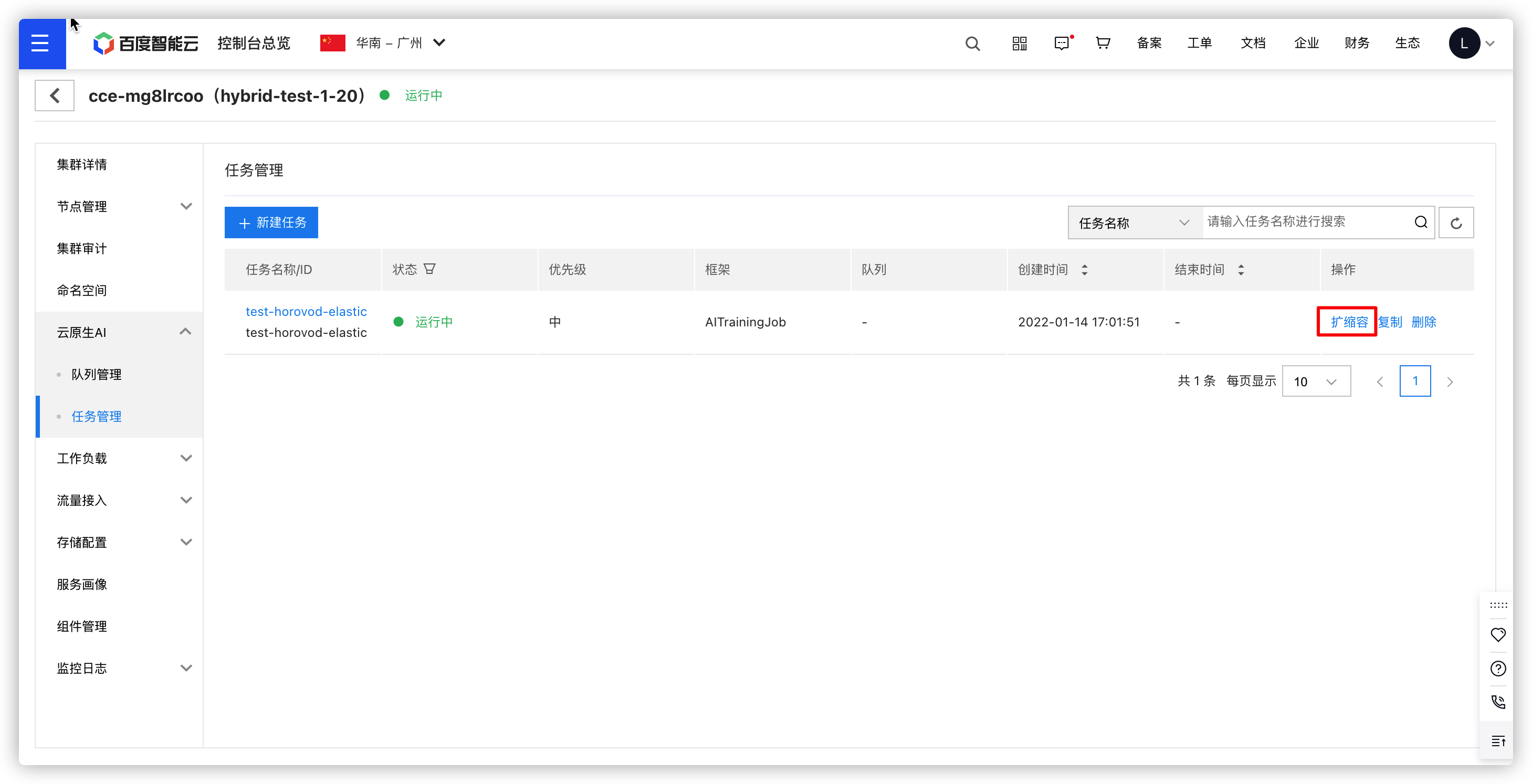
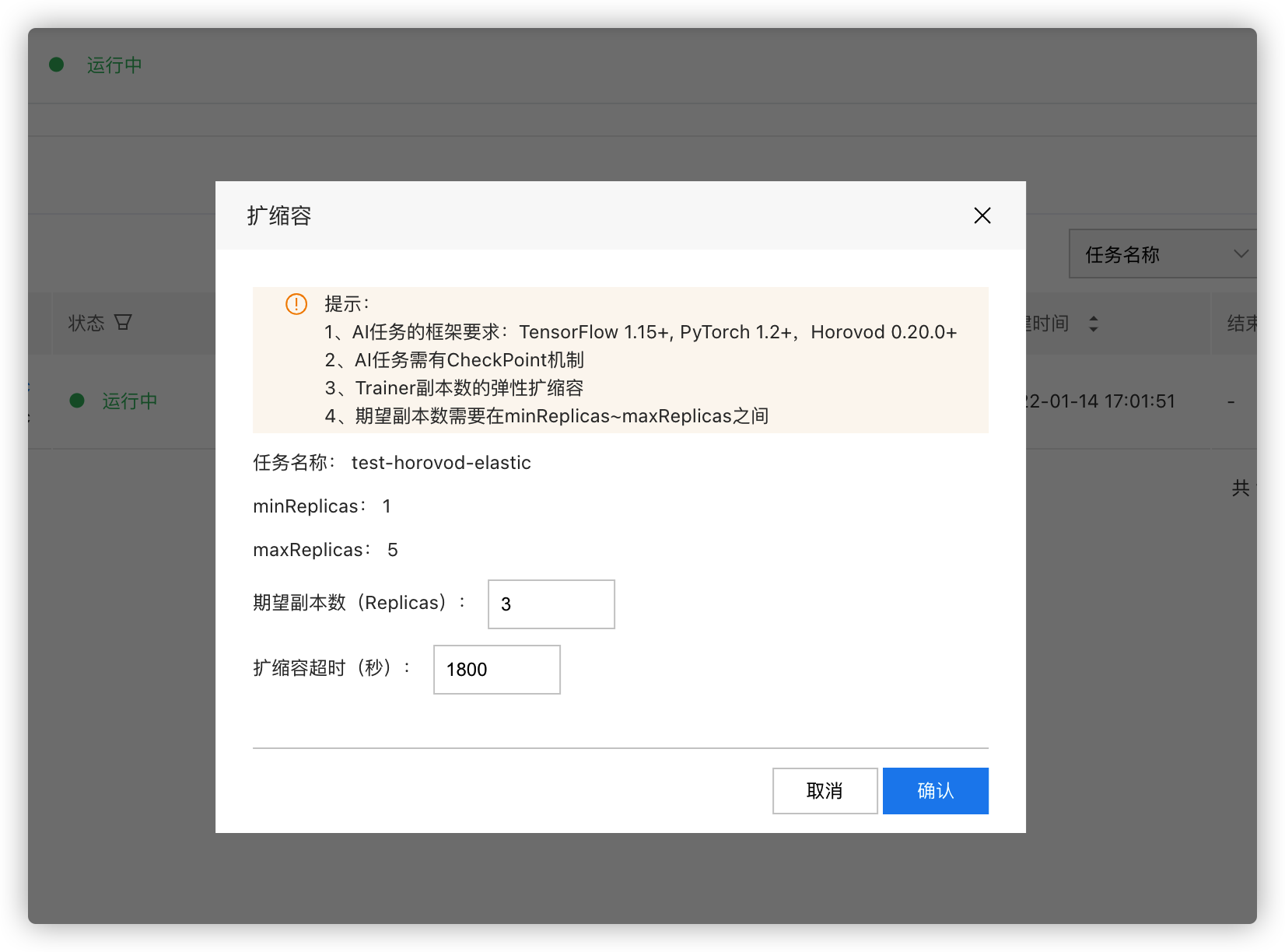
或直接在集群中修改此CR的YAML,修改spec.replicaSpecs.trainer.replicas的值指定期望Worker数量来执行弹性。
可以看到有相应的扩容事件,集群中也创建了新的Worker Pod加入运行。
YAML
1status:
2 RestartCount:
3 trainer: 0
4 conditions:
5 - lastProbeTime: "2022-01-14T09:01:52Z"
6 lastTransitionTime: "2022-01-14T09:01:52Z"
7 message: all pods are waiting for scheduling
8 reason: TrainingJobPending
9 status: "False"
10 type: Pending
11 - lastProbeTime: "2022-01-14T09:01:53Z"
12 lastTransitionTime: "2022-01-14T09:01:53Z"
13 message: pods [test-horovod-elastic-launcher-vk9c2-0] creating containers
14 reason: TrainingJobCreating
15 status: "False"
16 type: Creating
17 - lastProbeTime: "2022-01-14T09:02:27Z"
18 lastTransitionTime: "2022-01-14T09:02:27Z"
19 message: all pods are running
20 reason: TrainingJobRunning
21 status: "False"
22 type: Running
23 - lastProbeTime: "2022-01-14T09:06:16Z"
24 lastTransitionTime: "2022-01-14T09:06:16Z"
25 message: trainingJob default/test-horovod-elastic scaleout Operation scaleout
26 scale num 1 scale pods [test-horovod-elastic-trainer-vdkk6-3], replicas name
27 trainer job version 1
28 status: "False"
29 type: Scaling
30 - lastProbeTime: "2022-01-14T09:06:20Z"
31 lastTransitionTime: "2022-01-14T09:06:20Z"
32 message: all pods are running
33 reason: TrainingJobRunning
34 status: "True"
35 type: Running
Plain Text
1NAME READY STATUS RESTARTS AGE
2test-horovod-elastic-launcher-vk9c2-0 1/1 Running 0 7m4s
3test-horovod-elastic-trainer-4zzk4-0 1/1 Running 0 7m5s
4test-horovod-elastic-trainer-b5rc2-2 1/1 Running 0 7m5s
5test-horovod-elastic-trainer-kdjq2-1 1/1 Running 0 7m5s
6test-horovod-elastic-trainer-vdkk6-3 1/1 Running 0 2m40s容错场景
在CCE中创建训练任务并开启容错后,会在提交的YAML的 faultTolorencePolicy 字段中指定容错策略如下:
YAML
1faultTolerantPolicy:
2 - exceptionalEvent: nodeNotReady,PodForceDeleted
3 restartPolicy: OnNodeFail
4 restartScope: Pod当Pod因指定退出码异常退出、节点NotReady造成的Pod驱逐、Pod被强行删除场景时,Operator会自动拉起新的训练Pod替代错误的Pod继续完成训练任务。
如当强行删除一个Pod后,最终会创建新的Pod补充进来恢复原本的4个训练实例:
Plain Text
1➜ kubectl get pods -w
2NAME READY STATUS RESTARTS AGE
3test-horovod-elastic-launcher-vk9c2-0 1/1 Running 0 7m59s
4test-horovod-elastic-trainer-4zzk4-0 1/1 Terminating 0 8m
5test-horovod-elastic-trainer-b5rc2-2 1/1 Running 0 8m
6test-horovod-elastic-trainer-kdjq2-1 1/1 Running 0 8m
7test-horovod-elastic-trainer-vdkk6-3 1/1 Running 0 3m35s
8
9
10test-horovod-elastic-trainer-4zzk4-0 0/1 Terminating 0 8m7s
11test-horovod-elastic-trainer-4zzk4-0 0/1 Terminating 0 8m8s
12test-horovod-elastic-trainer-4zzk4-0 0/1 Terminating 0 8m8s
13test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 0s
14test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 1s
15test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 1s
16test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 1s
17test-horovod-elastic-trainer-htbz4-0 0/1 ContainerCreating 0 1s
18test-horovod-elastic-trainer-htbz4-0 1/1 Running 0 3s评价此篇文章