
使用Nsight工具分析优化应用程序
概览
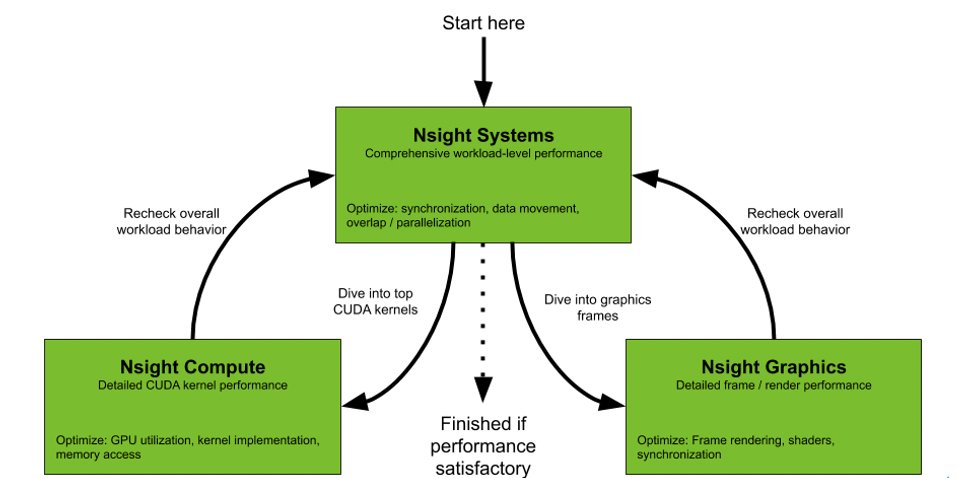
Nsight是NVIDIA面相开发者提供的开发工具套件,能提供深入的跟踪、调试、评测和分析,以优化跨 NVIDIA GPU和CPU的复杂计算应用程序。Nsight主要包含Nsight System、Nsight Compute、Nsight Graphics三部分。
- Nsight System
所有与NVIDIA GPU相关的程序开发都可以从Nsight System开始以确定最大的优化机会。Nsight System给开发者一个系统级别的应用程序性能的可视化分析。开发人员可以优化瓶颈,以便在任意数量或大小的CPU和GPU之间实现高效扩展。详情可访问NVIDIA官网。
- Nsight Compute
Nsight Compute是一个CUDA应用程序的交互式kernel分析器。它通过用户接口和命令行工具的形式提供了详细的性能分析度量和API调试。Nsight Compute还提供了定制化的和数据驱动的用户接口和度量集合,可以使用分析脚本对这些界面和度量集合进行扩展,以获得后处理的结果。详情可访问NVIDIA官网。
- Nsight Graphics
Nsight Graphics是一个用于调试、评测和分析Microsoft Windows和Linux上的图形应用程序。它允许您优化基于Direct3D 11, Direct3D 12, DirectX,Raytracing 1.1, OpenGL,Vulkan和KHR Vulkan Ray Tracing Extension的应程序的性能。详情可访问NVIDIA官网。
需求场景
- 人工智能训练性能分析
- 图形渲染的性能分析
配置步骤
环境准备
此次典型实践通过在云端进行人工智能训练,并将运算结果导出并发送给本地进行离线Nsight System分析,并快速优化训练性能。
- 本地:可以连接到Internet的PC或者笔记本电脑
- 云端:创建并挂载EIP的GPU云服务器
创建GPU云服务器时通过自定义驱动或者使用GPU镜像安装后即可自动安装Nisght System,如需手动安装可访问Nsight System的下载地址,根据本地和云端的运行环境分别下载对应的版本。
Nsight System使用示例
以手写数字数据库MNIST作为训练数据集,使用PyTorch框架进行神经网络训练。通过Nsight System对训练过程进行性能分析,进而找到性能瓶颈,指导优化训练过程。
1、下载训练所需的数据集和脚本 数据集采用MNIST,训练脚本我们采用该位置的PyTorch代码,基于单块NVIDIA Volta GPU我们将完成多batches和epochs的训练。一次完整的迭代过程包括如下几个方面:
- 从磁盘载入数据
- 数据加载到GPU设备端
- 前向传播
- 反向传播
运行以下命令,可完成一次训练,本次实践以bcc.gn3.c10m80.1v100-32g实例为例,约花费90s左右。
1python main.py2、利用Nsight system进行性能分析
(可选)开发者可通过添加NVIDIA Tools Extension(NVTX);来对应用程序逻辑上的时间线进行注释,帮助分析人员理解应用算法的上下文逻辑,在main.py中的训练代码部分增加nvtx函数如下:
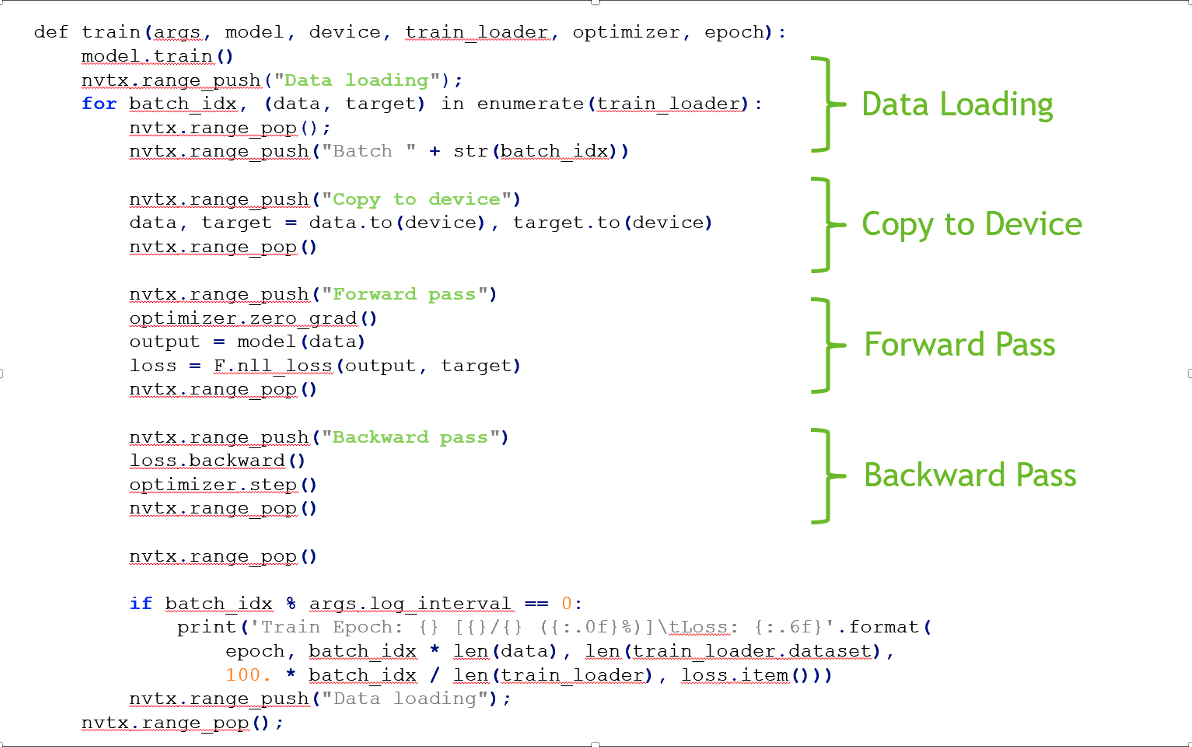 通过Nsight System的命令行方式,生成分析结果文件:
通过Nsight System的命令行方式,生成分析结果文件:
1nsys profile –t cuda,osrt,nvtx –o baseline –w true python main.py在这个例子中,采用的参数解释如下:
- -t 后面跟定的参数是我们要追踪的API,即需要CUDA API,OS runtime API以及NVTX API
- -o 给定的是输出的文件名称
- -w 后面表明是或否要在命令行中同时输出结果
- python main.py为程序的执行命令
将导出的baseline输出文件下载到本地,并拖拽到本地的Nsight System窗口即可获取性能结果展示,示例如下:
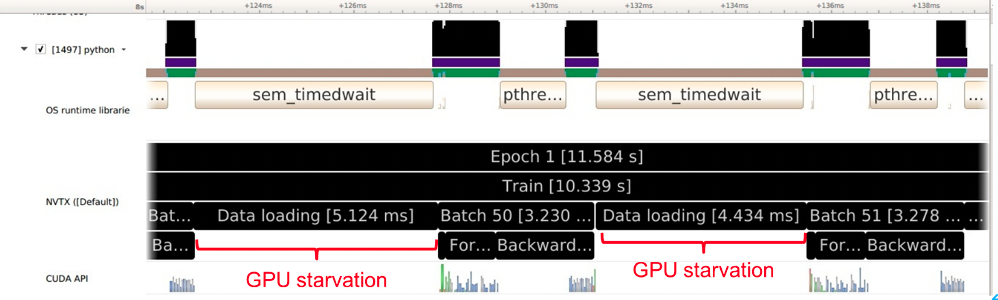 可以看到,通过产生的分析文件,我们发现训练的过程中,有很大一段时间GPU都处于空闲状态。
可以看到,通过产生的分析文件,我们发现训练的过程中,有很大一段时间GPU都处于空闲状态。
3、性能优化 可以发现,GPU空闲状态主要是因为CPU在处理数据加载耗时过多。我们可以对收据加载进行优化,优化的方式如下: 原有的数据加载采用的是一个CPU worker 线程:
1kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}我们可以将num_workers的数量调大,这里我们调整为8
1kwargs = {'num_workers': 8, 'pin_memory': True} if use_cuda else {}重新按照步骤2执行,可观察到如下结果:

可以发现,经过优化之后,数据加载的时间明显缩短了。整体的训练时间也从原来的90s变成了21s,获得了显著的加速效果。
相关产品(必选)
评价此篇文章