
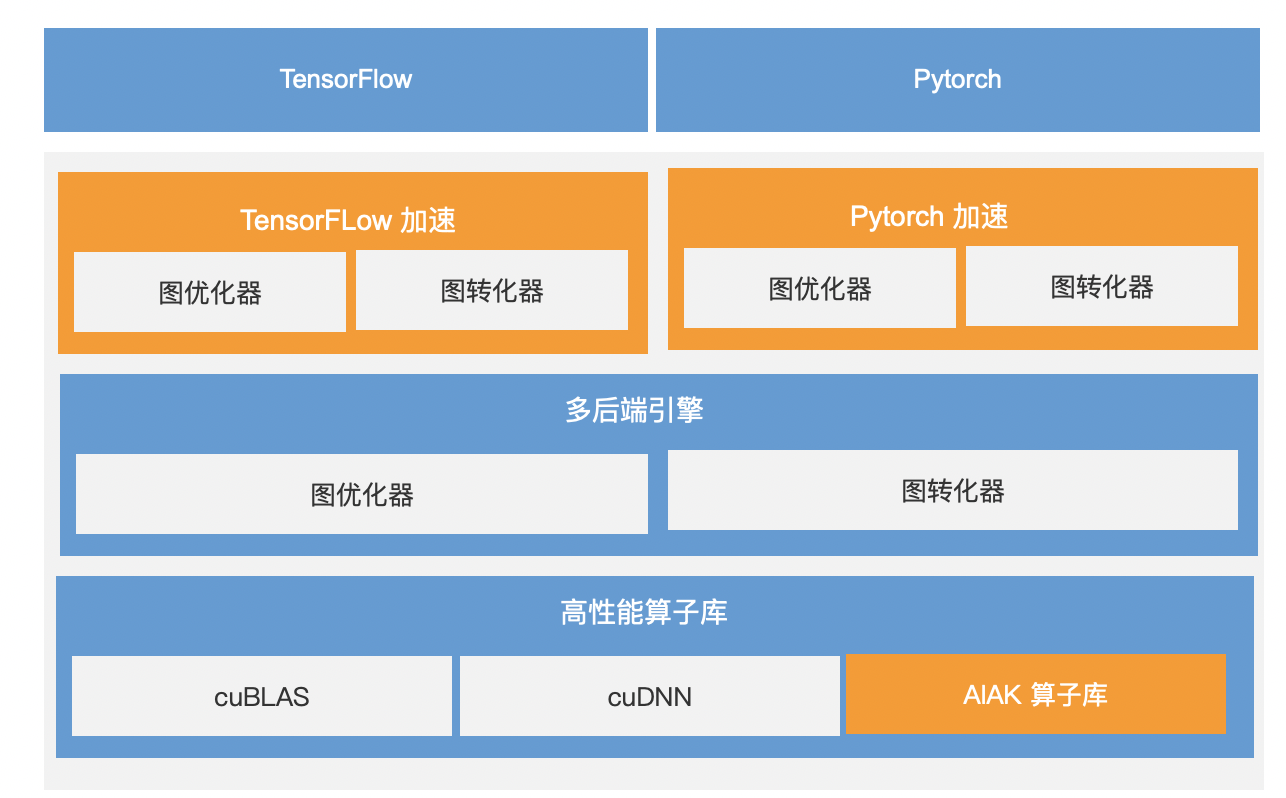
AIAK推理加速组件
更新时间:2023-07-21
概览
AIAK是面向人工智能任务提供的加速引擎,用于优化基于AI主流计算框架搭建的模型,能显著提升AI任务开发、部署的运行效率。
其中,AIAK推理加速套件是通过优化主流的AI框架,例如:Tensorflow、PyTorch产出的模型,降低在线推理延迟、提升服务吞吐,大幅增加异构资源使用效率的推理优化引擎,结合百度智能云的IaaS资源,可进一步提升用户AI场景下的计算效率。
应用场景
AIAK推理加速可支持但是不限于以下场景模型:
- 自然语言处理,例如Bert、Transformer等。
- 图像识别,例如ResNet50、MobileNetSSD等。
方案优势
AIAK推理加速组件具有以下优势。
- 多框架兼容:提供对TensorFlow和PyTorch等框架兼容。
- 多模型支持:支持对业界主流模型的加速。
- 轻量便捷:只需少量代码适配即可开启加速能力。
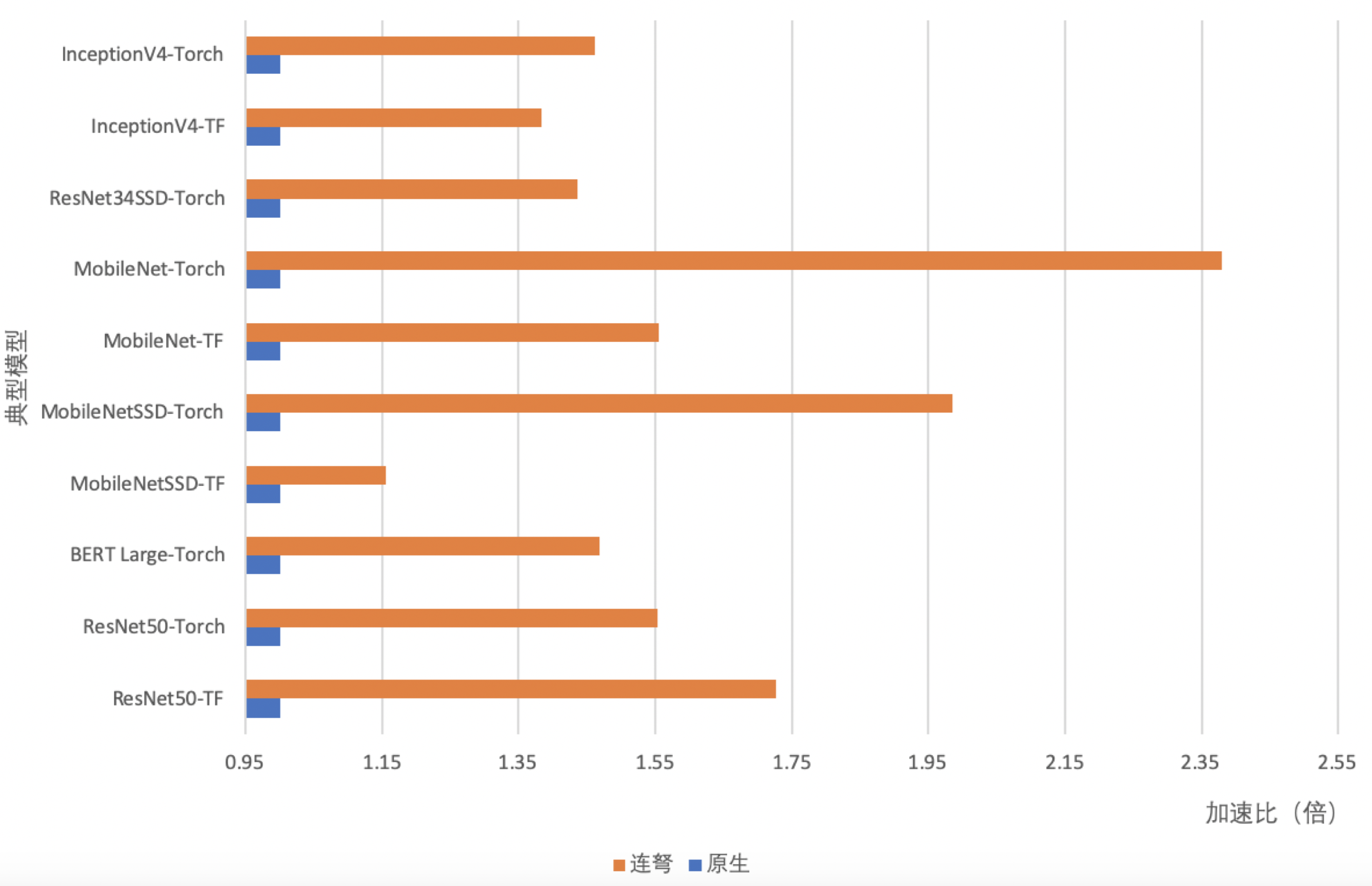
以下列举了一些典型模型基于AIAK和NVIDIA Tesla T4 GPU的推理时延收益,数值越高代表时延越低。
配置步骤
环境准备
- GPU云服务器资源。
-
AIAK推理加速的部署需满足以下运行环境。
- AI开发框架版本:Pytorch 1.8及以上版本,Tensorflow 1.15及以上版本。
- GPU运行环境:Cuda 10.2及以上版本,TensorRT 7及以上版本。
- Python版本:3.6版本。
使用方法
AIAK推理加速支持多产品使用,本文档以加速ResNet50为例子介绍如何在GPU云服务器中使用AIAK推理加速组件,如您需要结合百度智能云容器服务引擎,可参考云原生AI使用文档。
TensorFlow框架
- 登录百度智能云GPU实例。
- 提交工单获取最新的加速包下载链接。
- 准备业务需要的模型,此处以ResNet50为示例。
Plain Text
1import os
2import numpy as np
3import tensorflow.compat.v1 as tf
4tf.compat.v1.disable_eager_execution()
5
6def _wget_demo_tgz():
7 # 此处以下载一个公开的resnet50模型为例。
8 url = 'https://cce-ai-native-package-bj.bj.bcebos.com/aiak-inference/examples/models/resnet50.pb'
9 local_tgz = os.path.basename(url)
10 local_dir = local_tgz.split('.')[0]
11 if not os.path.exists(local_dir):
12 luno.util.wget(url, local_tgz)
13 luno.util.unpack(local_tgz)
14 model_path = os.path.abspath(os.path.join(local_dir, "frozen_inference_graph.pb"))
15 graph_def = tf.GraphDef()
16 with open(model_path, 'rb') as f:
17 graph_def.ParseFromString(f.read())
18 # 以随机数作为测试数据,可替换为自己的数据集
19 test_data = np.random.rand(1, 800, 1000, 3)
20 return graph_def, {'image_tensor:0': test_data}
21
22graph_def, test_data = _wget_demo_tgz()
23
24input_nodes=['image_tensor']
25output_nodes = ['detection_boxes', 'detection_scores', 'detection_classes', 'num_detections', 'detection_masks']- 运行模型并获取benchmark推理时延。
Plain Text
1import time
2
3def benchmark(model):
4 tf.reset_default_graph()
5 with tf.Session() as sess:
6 sess.graph.as_default()
7 tf.import_graph_def(model, name="")
8 # Warmup!
9 for i in range(0, 1000):
10 sess.run(['image_tensor:0'], test_data)
11 # Benchmark!
12 num_runs = 1000
13 start = time.time()
14 for i in range(0, num_runs):
15 sess.run(['image_tensor:0'], test_data)
16 elapsed = time.time() - start
17 rt_ms = elapsed / num_runs * 1000.0
18 # Show the result!
19 print("Latency of model: {:.2f} ms.".format(rt_ms))
20
21# original graph
22print("=====Original Performance=====")
23benchmark(graph_def)- 引入AIAK推理优化组件。
Plain Text
1import luno
2optimized_model = luno.optimize(
3 graph_def, # 待优化的模型,此处是tf.GraphDef, 也可以配置为SavedModel的路径。
4 'o1', # 优化级别,o1或o2。
5 device_type='gpu', # 目标设备,gpu/cpu
6 outputs=['detection_boxes', 'detection_scores', 'detection_classes', 'num_detections', 'detection_masks']
7)- 运行优化后的模型并获取benchmark推理时延。
Plain Text
1# optimized graph
2print("=====Optimized Performance=====")
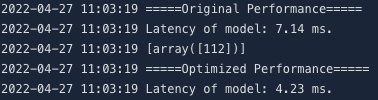
3benchmark(optimized_model)可看到同模型在使用AIAK组件后在推理时延上的收益。
Pytorch框架
- 登录百度智能云GPU实例。
- 提交工单获取最新的加速包下载链接。
- 准备业务需要的模型,此处以ResNet50为示例。
Plain Text
1import os
2import time
3import torch
4import torchvision.models as models
5
6model = models.resnet50().float().cuda()
7model = torch.jit.script(model).eval() # 使用jit转为静态图
8dummy = torch.rand(1, 3, 224, 224).cuda()- 运行模型并获取benchmark推理时延。
Plain Text
1@torch.no_grad()
2def benchmark(model, inp):
3 for i in range(100):
4 model(inp)
5 start = time.time()
6 for i in range(200):
7 model(inp)
8 elapsed_ms = (time.time() - start) * 1000
9 print("Latency: {:.2f}".format(elapsed_ms / 200))
10
11# benchmark before optimization
12print("before optimization:")
13benchmark(model, dummy)- 引入AIAK推理优化组件。
Plain Text
1import luno
2
3optimized_model = luno.optimize(
4 model,
5 'gpu',
6 input_shapes=[[1, 3, 224, 224]],
7 test_data=[dummy],
8)- 运行优化后的模型并获取benchmark推理时延。
Plain Text
1# benchmark after optimization
2print("after optimization:")
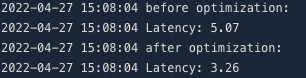
3benchmark(optimized_model, dummy)可看到同模型在使用AIAK组件后在推理时延上的收益。
评价此篇文章