
手动安装GPU驱动以及Cuda(Linux)
背景
GPU的驱动和CUDA是使用GPU计算的必备组件。如果您在创建实例始时,没有选择自动安装驱动以及CUDA版本,则需要在创建实例后,手动安装。本页面介绍如何手动安装驱动,以及如何使用工具测试GPU的重要性能。
前提条件
已创建GPU计算型实例,例如GN3或者GN2规格族。本流程不适合需要安装GRID驱动的vGPU规格族。
安装前准备工作
- 确认GPU型号和操作系统版本,本示例中以V100以及操作系统为Centos 7.5.1804进行操作。
-
准备GPU驱动和CUDA 11.1软件包,在nvidia官网进行驱动包和CUDA包下载
- linux系统均选择 Linux 64-bit
- CUDA Toolkit选择最新版本
- 如您需要老版本CUDA,请前往老版本CUDA下载
本示例中使用CUDA 11.1.1。
-
检查服务器GPU识别情况
安装GPU驱动之前需要在操作系统下查看GPU卡是否能够完全识别,如不能识别需要进行重新插拔、对调测试等步骤进行硬件排查。
查看到所有的GPU
Plain Text1lspci | grep -i nvidia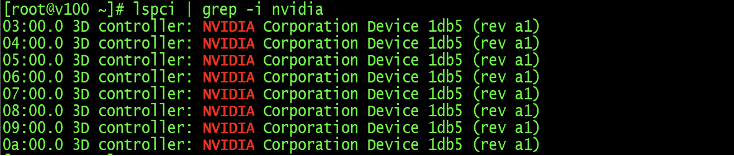
-
老版本软件包卸载(可选)
-
GPU驱动卸载
Plain Text1/usr/bin/nvidia-uninstall -
CUDA卸载方法:
Plain Text1/usr/local/cuda/bin/cuda-uninstaller
-

1- 如您的CUDA是老版本卸载
2
3 /usr/local/cuda/bin/uninstall_cuda_X.Y.pl-
安装gcc、g++编译器
CUDA安装samples测试程序进行make时需要g++,但安装CUDA软件包时不需要。
Plain Text1 检查版本 2 gcc -v 3 g++ -v
软件包安装
1 yum install gcc
2 yum install gcc-c++-
禁用系统自带的nouveau模块
检查nouveau模块是否加载,已加载则先禁用
Plain Text1 lsmod | grep nouveau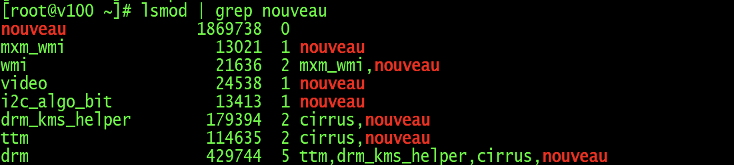
没有blacklist-nouveau.conf文件则创建
Plain Text1 vim /usr/lib/modprobe.d/blacklist-nouveau.conf 2 blacklist nouveau 3 options nouveau modeset=0
执行如下命令使内核生效(需要重启服务器后才可真正禁用nouveau)
1 dracut -force重启操作系统
-
修改系统运行级别为文本模式 GPU驱动安装必须在文本模式下进行
Plain Text1 systemctl set-default multi-user.target -
重启系统,然后检查禁用nouveau模块配置与文本模式是否生效。
Plain Text1 lsmod | grep nouveau
GPU驱动安装
-
root用户下进行GPU驱动
Plain Text1chmod +x NVIDIA-Linux-x86_64-450.80.02.run 2./NVIDIA-Linux-x86_64-450.80.02.run --no-opengl-files --ui=none --no-questions --accept-license -
配置GPU驱动内存常驻模式
Plain Text1nvidia-persistenced
设置开机自启动
1 vim /etc/rc.d/rc.local在文件中添加一行
1 nvidia-persistenced
2赋予/etc/rc.d/rc.local文件可执行权限
3
4 chmod +x /etc/rc.d/rc.local若无/etc/rc.d/rc.local,也可修改
1 vim /etc/rc.local
2 chmod +x /etc/rc.local-
安装完GPU驱动后查看GPU状态查看及相关配置。
Plain Text1nvidia-smi
CUDA安装
- 安装CUDA
安装CUDA时需注意,如果已经安装过GPU驱动,安装CUDA时就不要再选择GPU驱动安装了。
1 chmod +x cuda_11.1.1_455.32.00_linux.run
2 ./cuda_11.1.1_455.32.00_linux.run --no-opengl-libs新版本CUDA安装界面: 注意Driver选项,表示是否安装GPU驱动,如果已经安装了GPU驱动,这里不要再勾选。
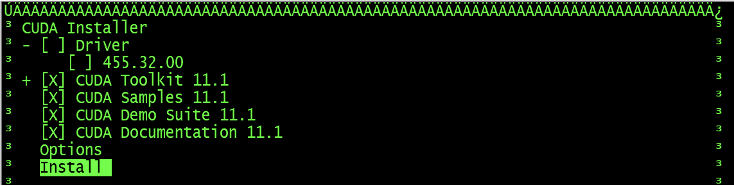
- 配置环境变量
添加到/etc/profile文件中,对所有用户生效
1vim /etc/profile
2export PATH=/usr/local/cuda/bin:$PATH
3export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
4source /etc/profile测试CUDA安装是否正确,环境变量是否识别成功
1nvcc -VCUDA samples程序测试
- BandwidthTest测试
BandwidthTest测试GPU卡与主机server、GPU与GPU卡之间的显存带宽,测试结果中Host to Device Bandwidth和Device to Host Bandwidth分别为主机server至GPU卡和GPU卡至主机server的显存带宽,Device to Device Bandwidth测试的是GPU卡之间的显存带宽。
编译、测试
1 cd /usr/local/cuda/samples/1_Utilities/bandwidthTest/
2 make
3 ./bandwidthTest测试结果参考 Host to Device Bandwidth和Device to Host Bandwidth两项数值在6.6GB/s-7.1GB/s之间
1 Device to Device Bandwidth测试显存带宽,该值根据GPU显存硬件配置而异,
2 下表列出个GPU理论显存带宽,实测值在理论值70%以上即认定状态正常。| GPU型号 | 显存带宽理论值 |
|---|---|
| P100-PCIE-12GB | 548GB/s |
| P100-PCIE-16GB/P100-SXM2-16GB | 732GB/s |
| P40 | 346GB/s |
| P4 | 192GB/s |
| V100-PCIE/SXM2全系列 | 900GB/s |
- P2pBandwidthLatencyTest测试
P2pBandwidthLatencyTest测试GPU卡之间的带宽。可查看是否使用GPU中NVLINK的性能结果
编译、测试
1cd /usr/local/cuda/samples/1_Utilities/p2pBandwidthLatencyTest/
2make
3./p2pBandwidthLatencyTest 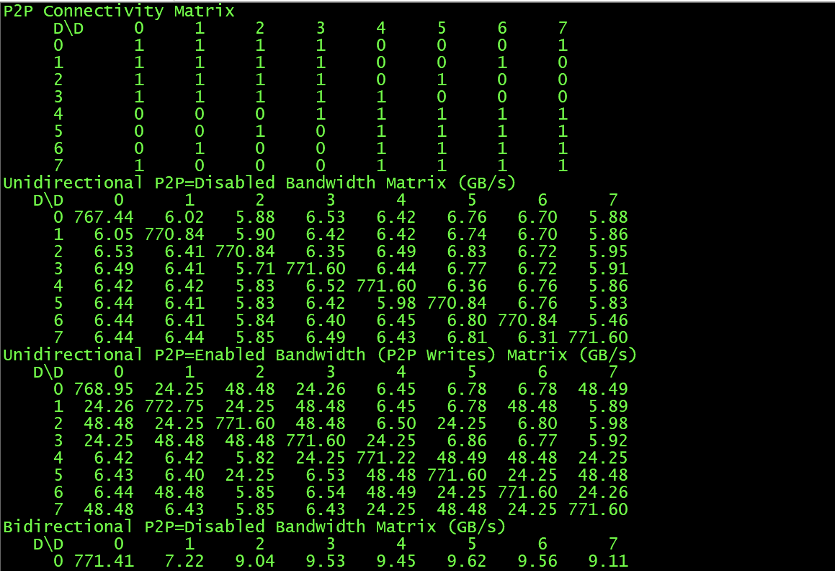
解释:
- 互联矩阵中,有1标记即表示GPU间有P2P访问支持功能,0表示没有支持。
- Unidirection测试单向P2P带宽,Bidirectiona测试双向P2P带宽。同时提供是否使用NVLINK的性能测试结果。
根据GPU硬件版本不同,带宽和延迟存在差异,按照GPU型号,提供参考数据如下
参考带宽:
| GPU型号(带宽实测均值) | 支持P2P | 不支持P2P |
|---|---|---|
| PCIE GPU | 22-26GB/s | 17-20GB/s |
| P100-SXM2(NVLINK1.0) | 35-38GB/s | 17-20GB/s |
| V100-SXM2(NVLINK2.0) | 90-96GB/s(双link)和45-48GB/s (单link) | 15-20GB/s |
参考时延:
| GPU型号(延迟实测均值) | 矩阵值1 | 矩阵值0 |
|---|---|---|
| PCIE GPU | ≤10us | ≤20us |
| P100-SXM2(NVLINK1.0) | ≤10us | ≤20us |
| V100-SXM2(NVLINK2.0) | ≤10us | ≤20us |
- BatchCuBlas
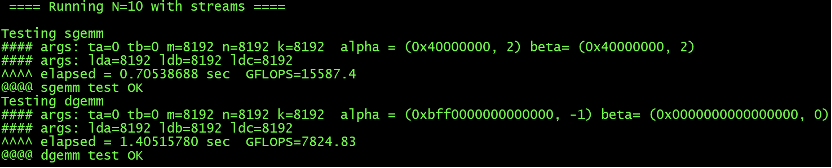
BatchCuBlas为GPU浮点运算能力测试、加压。测试包括sgemm(测试单精度浮点计算能力)和dgemm(双精度)两部分,关注GFLOPS测试值。测试值达到理论值90%以上认定状态正常。
编译、测试
1在测试命令中m、n、k值可调整,一般GPU缓存大小16G时可选8192。
2在测试命令中,使用--device=1参数指定测试ID号为1的GPU卡,默认测试ID号为0的GPU卡。
3 cd /usr/local/cuda/samples/7_CUDALibraries/batchCUBLAS/
4 make
5 ./batchCUBLAS -m8192 -n8192 -k8192 ##默认测试ID号为0的GPU卡
6 ./batchCUBLAS -m8192 -n8192 -k8192 --device=1 ##指定测试ID号为1的GPU卡测试结果中,可重点关注Running N=10 with streams部分,包含单精度和双精度测试,
评价此篇文章