
CCE 支持 GPUSharing 集群
更新时间:2020-11-24
K8S GPUSharing 介绍
K8S 基于 nvidia-device-plugin 的 GPU 调度通常使用"GPU 卡"作为最小粒度,每个 Pod 至少绑定一张卡,这种方式提供了很好的隔离性,但以下场景存在不足:
- AI 开发和推理场景 GPU 利用率较低,通过多个 Pod 挂载一张卡,可以提高 GPU 利用率,;
- K8S 集群存在多种不同类型 GPU 卡的混布,不同 GPU 卡的算力差别较大,调度时需要考虑卡的类型。
基于以上原因,CCE 将内部 KongMing GPUSharing 方案对外开放,提供 GPUSharing 功能,既支持多 Pod 共享 GPU 卡,也支持按卡类型进行调度。
在 CCE 使用 GPUSharing
新建集群
CCE 支持直接新建 GPUSharing 集群,先按照正常创建集群流程选完参数,在提交前切换为"自定义集群配置"模式:
修改 clusterType 为 gpuShare,直接发起创建:
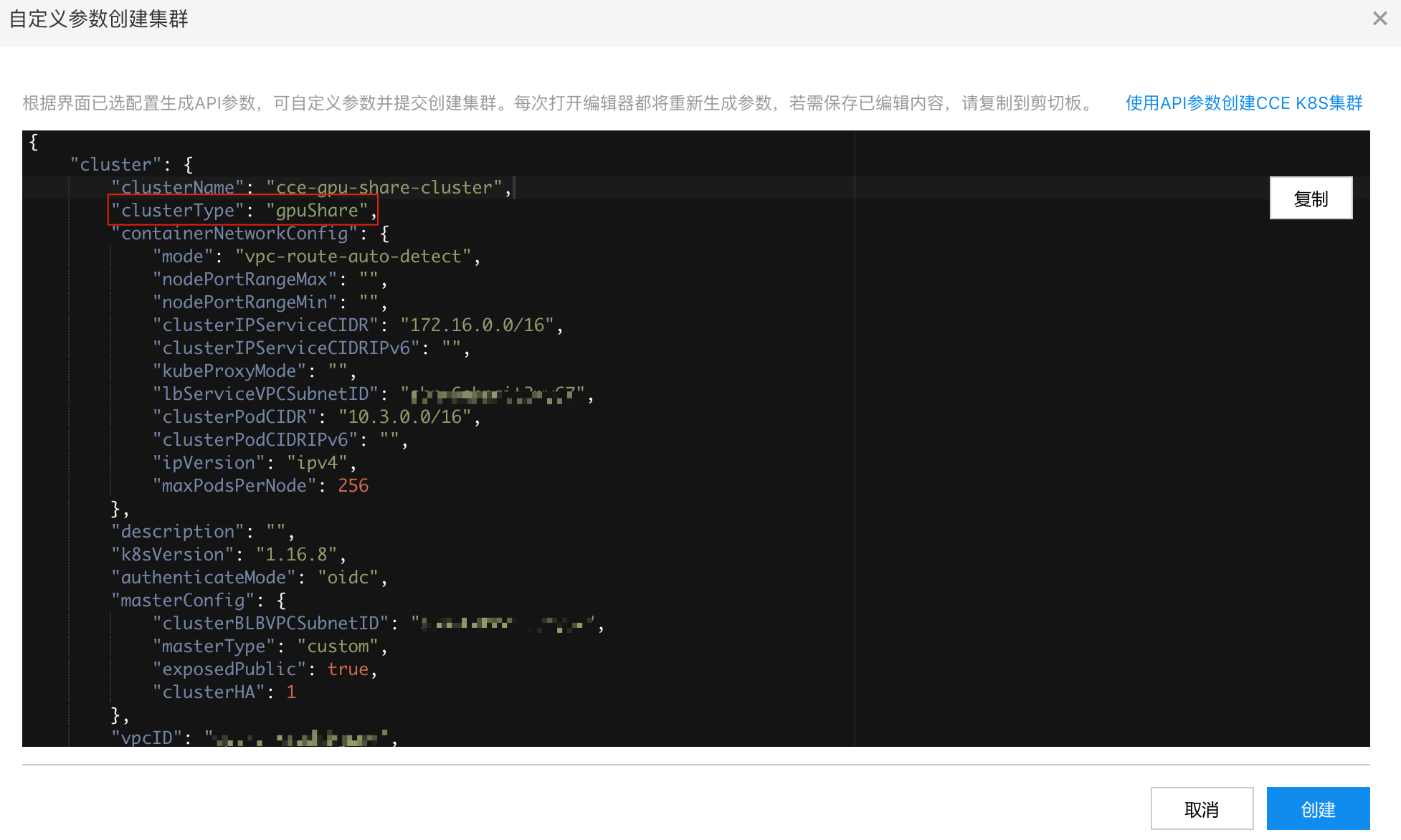
ps:后续会直接支持 GPUSharing 类型集群,更加方便。
已有集群
已有集群可按照下面文档描述,自行修改组件配置,建议修改配置前先备份。下面操作都在 Master 机器上进行,仅支持自定义类型集群。
部署 extender-scheduler
修改 /etc/kubernetes/scheduler-policy.json 配置
备份已有配置:
$cp /etc/kubernetes/scheduler-policy.json /etc/kubernetes/scheduler-policy.json.bak修改 scheduler-policy.json,下面配置支持 v100、k40、p40、p4 等常见 GPU 卡类型,可根据实际情况进行调整:
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [{"name":"PodFitsHostPorts"},{"name":"PodFitsResources"},{"name":"NoDiskConflict"},{"name":"CheckVolumeBinding"},{"name":"NoVolumeZoneConflict"},{"name":"MatchNodeSelector"},{"name":"HostName"}],
"priorities": [{"name":"ServiceSpreadingPriority","weight":1},{"name":"EqualPriority","weight":1},{"name":"LeastRequestedPriority","weight":1},{"name":"BalancedResourceAllocation","weight":1}],
"extenders":[
{
"urlPrefix":"http://127.0.0.1:39999/gpushare-scheduler",
"filterVerb":"filter",
"bindVerb":"bind",
"enableHttps":false,
"nodeCacheCapable":true,
"ignorable":false,
"managedResources":[
{
"name":"baidu.com/v100_cgpu_memory",
"ignoredByScheduler":false
},
{
"name":"baidu.com/v100_cgpu_core",
"ignoredByScheduler":false
},
{
"name":"baidu.com/k40_cgpu_memory",
"ignoredByScheduler":false
},
{
"name":"baidu.com/k40_cgpu_core",
"ignoredByScheduler":false
},
{
"name":"baidu.com/p40_cgpu_memory",
"ignoredByScheduler":false
},
{
"name":"baidu.com/p40_cgpu_core",
"ignoredByScheduler":false
},
{
"name":"baidu.com/p4_cgpu_memory",
"ignoredByScheduler":false
},
{
"name":"baidu.com/p4_cgpu_core",
"ignoredByScheduler":false
}
]
}
],
"hardPodAffinitySymmetricWeight": 10
}修改 /etc/systemd/system/kube-extender-scheduler.service 配置
[Unit]
Description=Kubernetes Extender Scheduler
After=network.target
After=kube-apiserver.service
After=kube-scheduler.service
[Service]
Environment=KUBECONFIG=/etc/kubernetes/admin.conf
ExecStart=/opt/kube/bin/kube-extender-scheduler \
--logtostderr \
--policy-config-file=/etc/kubernetes/scheduler-policy.json \
--mps=false \
--core=100 \
--health-check=true \
--memory-unit=GiB \
--mem-quota-env-name=GPU_MEMORY \
--compute-quota-env-name=GPU_COMPUTATION \
--v=6
Restart=always
Type=simple
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target部署 extender-scheduler
不同地域二进制地址:
- 北京:http://baidu-container.bj.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- 广州:http://baidu-container-gz.gz.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- 苏州:http://baidu-container-su.su.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- 保定:http://baidu-container-bd.bd.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- 香港:http://baidu-container-hk.hkg.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- 武汉:http://baidu-container-whgg.fwh.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
下载二进制:
$wget -q -O /opt/kube/bin/kube-extender-scheduler http://baidu-container.bj.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler启动服务 extender-scheduler:
$chmod +x /opt/kube/bin/kube-extender-scheduler
$systemctl daemon-reload
$systemctl enable kube-extender-scheduler.service
$systemctl restart kube-extender-scheduler.service重启 scheduler
$systemctl restart kube-scheduler.service一般 Master 为 3 副本,依次完成上述操作。
部署 device-plugin
备份 nvidia-device-plugin,删除 ,可以和 nvidia-device-plugin:
$ kubectl get ds nvidia-device-plugin-daemonset -n kube-system -o yaml > nvidia-device-plugin.yaml
$ kubectl delete ds nvidia-device-plugin-daemonset -n kube-system部署 kongming-device-plugin,all-in-one YAML 如下:
# RBAC authn and authz
apiVersion: v1
kind: ServiceAccount
metadata:
name: cce-gpushare-device-plugin
namespace: kube-system
labels:
k8s-app: cce-gpushare-device-plugin
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cce-gpushare-device-plugin
labels:
k8s-app: cce-gpushare-device-plugin
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- ""
resources:
- pods
verbs:
- update
- patch
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- update
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: kube-system
name: cce-gpushare-device-plugin
labels:
k8s-app: cce-gpushare-device-plugin
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: cce-gpushare-device-plugin
namespace: kube-system
apiGroup: ""
roleRef:
kind: ClusterRole
name: cce-gpushare-device-plugin
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: cce-gpushare-device-plugin
labels:
app: cce-gpushare-device-plugin
spec:
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
app: cce-gpushare-device-plugin
template:
metadata:
labels:
app: cce-gpushare-device-plugin
spec:
serviceAccountName: cce-gpushare-device-plugin
nodeSelector:
beta.kubernetes.io/instance-type: GPU
containers:
- name: cce-gpushare-device-plugin
image: hub.baidubce.com/jpaas-public/cce-nvidia-share-device-plugin:v0
imagePullPolicy: Always
args:
- --logtostderr
- --mps=false
- --core=100
- --health-check=true
- --memory-unit=GiB
- --mem-quota-env-name=GPU_MEMORY
- --compute-quota-env-name=GPU_COMPUTATION
- --gpu-type=baidu.com/gpu_k40_4,baidu.com/gpu_k40_16,baidu.com/gpu_p40_8,baidu.com/gpu_v100_8,baidu.com/gpu_p4_4
- --v=1
resources:
limits:
memory: "300Mi"
cpu: "1"
requests:
memory: "300Mi"
cpu: "1"
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
dnsPolicy: ClusterFirst
hostNetwork: true
restartPolicy: Always检查 Node 资源
通过 kubectl get node -o yaml,能够看到 node 上有新的 GPU 资源:
allocatable:
baidu.com/gpu-count: "1"
baidu.com/t4_cgpu_core: "100"
baidu.com/t4_cgpu_memory: "14"
cpu: 23870m
ephemeral-storage: "631750310891"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: "65813636449"
pods: "256"
capacity:
baidu.com/gpu-count: "1"
baidu.com/t4_cgpu_core: "100"
baidu.com/t4_cgpu_memory: "14"
cpu: "24"
ephemeral-storage: 685492960Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 74232212Ki
pods: "256"提交测试任务
提交测试任务:
apiVersion: v1
kind: ReplicationController
metadata:
name: paddlebook
spec:
replicas: 1
selector:
app: paddlebook
template:
metadata:
name: paddlebook
labels:
app: paddlebook
spec:
containers:
- name: paddlebook
image: hub.baidubce.com/cce/tensorflow:gpu-benckmarks
command: ["/bin/sh", "-c", "sleep 3600"]
#command: ["/bin/sh", "-c", "python /root/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50 --variable_update=parameter_server"]
resources:
requests:
baidu.com/t4_cgpu_core: 10
baidu.com/t4_cgpu_memory: 2
limits:
baidu.com/t4_cgpu_core: 10
baidu.com/t4_cgpu_memory: 2