
开发机实践
使用conda+PFS开发及提交任务
在AI模型开发场景中,可以使用conda 统一管理 AI 作业的环境依赖。conda安装在PFS中,保证开发机和训练集群共享envs,所有任务均使用一个基础镜像在容器内按需选择conda env,而无需为每个开发项目打包镜像。
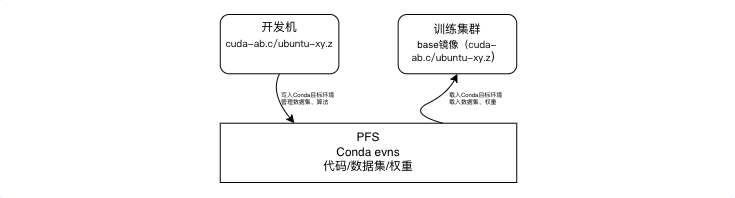
以下以一个简单的 DeeepSpeed nccl-test 任务为例,说明如何将开发完成的代码在集群中提交为任务。
在开发机中创建目标环境
- 打开开发机,进入Terminal
- 将 conda 安装到 PFS 共享存储中,默认部署开发机 PFS 挂载在
/mnt/cluster,Conda 安装在/mnt/cluster/test/conda中
1# 下载 miniconda
2wget http://mirrors.baidubce.com/anaconda/archive/Anaconda3-2023.03-Linux-x86_64.sh
3
4#安装 miniconda 到 PFS 目录,默认pfs挂载路径为 /mnt/cluster为共享文件
5bash Anaconda3-2023.03-Linux-x86_64.sh -p /mnt/cluster/test/conda
6# -p 参数指定为 conda 安装的目录 prefix,需指定一个 PFS 的路径
7# 最后一步会提示输入 yes 在 .bashrc 中默认初始化 conda 环境
8
9# 初始化conda
10source /mnt/cluster/test/conda/etc/profile.d/conda.sh如存在网络问题需要修改conda源为国内源,具体方法可自行网络搜索
- 创建PyTorch + DeepSpeed的conda环境
1# 创建名为 ds 的 conda 环境,指定python版本
2conda create --name ds python=3.8
3# 激活此 conda 环境
4conda activate ds
5# 为该环境安装 pip,后续则可使用 pip 在次环境安装依赖
6conda install pip
7
8# 安装前检查 pip 源是否为百度源
9pip config list
10# 如果不是百度源执行下面命令
11pip config set global.index-url http://mirrors.baidubce.com/pypi/simple
12pip config set global.extra-index-url http://mirrors.baidubce.com/pypi/simple
13
14# 安装 torch + deepspeed
15pip install torch -i http://mirrors.baidubce.com/pypi/simple/ --trusted-host mirrors.baidubce.com
16pip install deepspeed -i http://mirrors.baidubce.com/pypi/simple/ --trusted-host mirrors.baidubce.com
17
18# 在激活的 conda 环境中安装 ipykernel,它允许你将这个环境添加为 Jupyter Notebook 的内核
19conda install ipykernel
20# 将 Conda 环境添加为 Jupyter 内核
21python -m ipykernel install --user --name ds --display-name "Python (ds)"
22# --name myenv 是内核的名称。
23#--display-name "Python (ds)" 是在 Jupyter Notebook 中显示的名称。开发及本地测试
- 准备代码
1# 使用 DeepSpeed example 代码,放到 PFS 的 /mnt/cluster/test/code 目录
2# cd /mnt/cluster/test/code
3# git clone https://github.com/microsoft/DeepSpeedExamples.git
4
5cd /home/jovyan/bd/linux-bcecmd-0.4.6
6./bcecmd bos cp bos://cce-ai-datasets/DeepSpeedExamples/DeepSpeedExamples.tar.gz /mnt/cluster/test/code
7tar -xvf /mnt/cluster/test/code/DeepSpeedExamples.tar.gz- 开发机测试代码可正常运行
1cd /mnt/cluster/code/DeepSpeedExamples/benchmarks/communication
2torchrun all_reduce.py
- 使用进行代码开发,在 JupyterLab 中,新建或打开一个笔记本,点击菜单栏中的 "Kernel" -> "Change kernel",选择 "Python (ds)"。这样,你的开发电脑中将使用 ds 环境中的 Python 解释器和库。
使用YAML方式提交多机任务
以llama2-7b模型训练为例,权重和数据集存放在/mnt/cluster目录下,实际使用时根据需要修改为自己的路径地址
- 在 PFS 中创建一个 CCE 环境的多机任务启动脚本(本例将运行脚本保存与 PFS 的
/mnt/cluster/test/run.sh中),该脚本在base镜像的容器中使用 PFS 上保存的与开发机相同的conda ds环境
1#!/bin/bash
2
3# -------------------------------
4# 在原有的启动脚本中增加以下加载conda环境的命令,其他命令保持不变
5# 初始化 PFS 中的 conda
6source /mnt/cluster/test/conda/etc/profile.d/conda.sh
7# 激活与开发机上相同conda 环境ds
8conda activate ds
9# -------------------------------
10
11cd /mnt/cluster/test/code/DeepSpeedExamples/benchmarks/communication
12
13torchrun --nnodes $WORLD_SIZE --node-rank $RANK --nproc-per-node 8 --master-addr $MASTER_ADDR --master-port $MASTER_PORT all_reduce.py --warmups 5 --trials 200 --dist torch --maxsize=28 --debug --scan- 提交测试任务
修改yaml文件启动命令 command 修改为第一步中保存的启动脚本
1apiVersion: "kubeflow.org/v1"
2kind: PyTorchJob
3metadata:
4 name: ds-nccl-test # 任务名称,提交不同任务时需修改不同的任务名
5 namespace: default
6spec:
7 pytorchReplicaSpecs:
8 Master:
9 replicas: 1 # 分布式任务中 Master 数量固定 1,就是 RANK=0 的特殊 Worker 也参与计算
10 restartPolicy: OnFailure
11 template:
12 spec:
13 containers:
14 - name: pytorch
15 image: registry.baidubce.com/cce-ai-native/pytorch:22.08-py3-ds-example
16 resources:
17 limits:
18 nvidia.com/gpu: 8
19 rdma/hca: "1"
20 env:
21 - name: NCCL_DEBUG
22 value: INFO
23 command:
24 - /bin/bash
25 - /mnt/cluster/test/run.sh # 启动脚本位于 PFS
26 volumeMounts:
27 - mountPath: /dev/shm
28 name: shm
29 - mountPath: /mnt/cluster # PFS 存储在容器中的挂载点,与开发机挂载保持一致
30 name: data
31 securityContext:
32 capabilities:
33 add: ["IPC_LOCK"]
34 schedulerName: volcano
35 volumes:
36 - hostPath:
37 path: /dev/shm
38 name: shm
39 - name: data
40 persistentVolumeClaim:
41 claimName: pvc-pfs
42 Worker:
43 replicas: 3 # 此处可修改为期望的 Worker 数量,此例为 Master+Worker (1+3)*8 共 32 张卡
44 restartPolicy: OnFailure
45 template:
46 spec:
47 containers:
48 - name: pytorch
49 image: registry.baidubce.com/cce-ai-native/pytorch:22.08-py3-ds-example
50 env:
51 - name: NCCL_DEBUG
52 value: INFO
53 resources:
54 limits:
55 nvidia.com/gpu: "8"
56 rdma/hca: "1"
57 command:
58 - /bin/bash
59 - /mnt/cluster/test/run.sh # 启动脚本位于 PFS
60 volumeMounts:
61 - mountPath: /dev/shm
62 name: shm
63 - mountPath: /mnt/cluster # PFS 存储在容器中的挂载点,与开发机挂载保持一致
64 name: data
65 securityContext:
66 capabilities:
67 add: ["IPC_LOCK"]
68 schedulerName: volcano
69 volumes:
70 - hostPath:
71 path: /dev/shm
72 name: shm
73 - name: data
74 persistentVolumeClaim:
75 claimName: pvc-pfs运行kubectl apply -f ./job.yaml提交任务到集群
- 查看任务运行状态与日志
kubectl get pods查看 Pod 列表
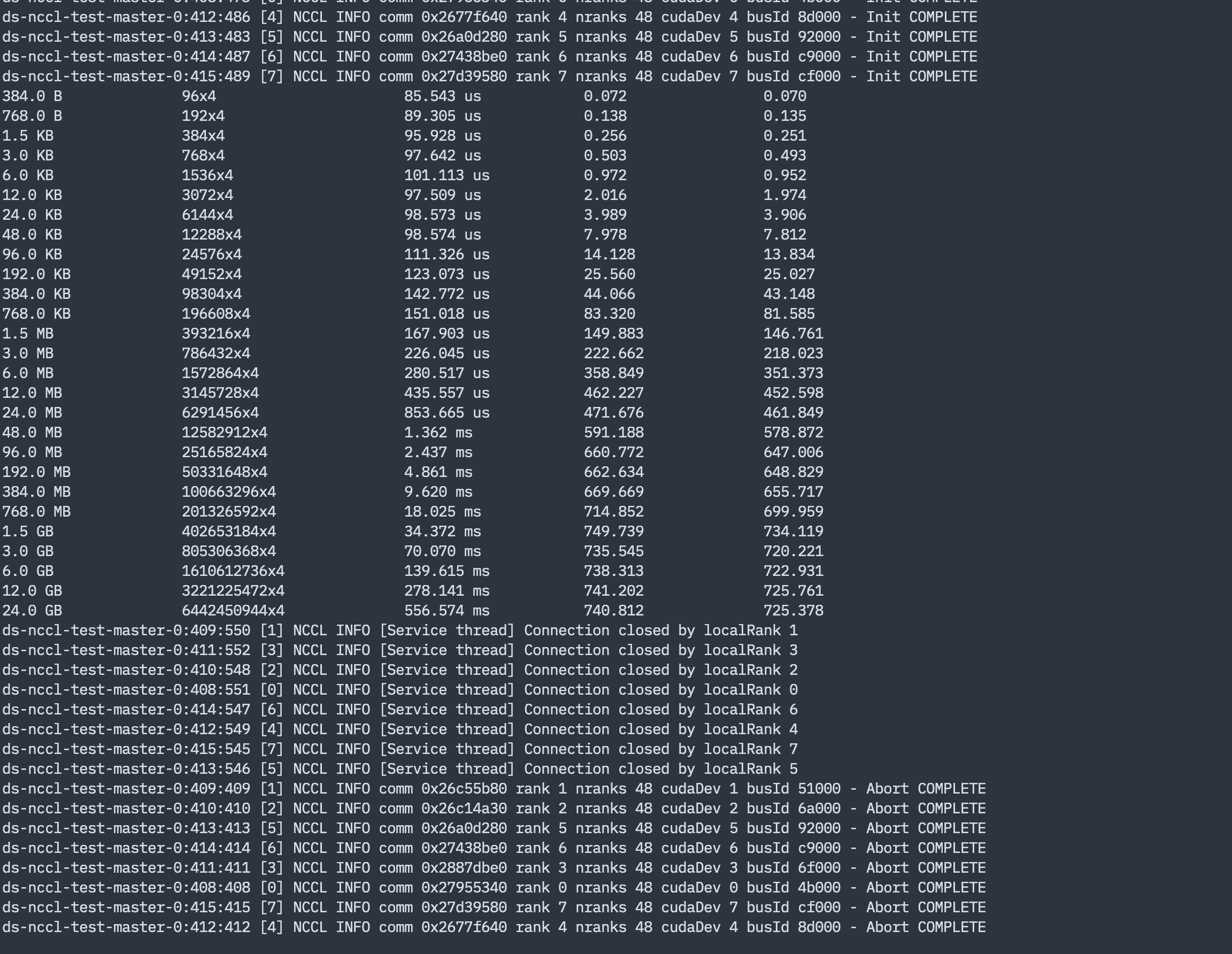
kubectl logs ds-nccl-test-master-0 查看 ds-nccl-test-master-0 Master 容器日志
- 删除任务
两种方式删除任务
kubectl delete -f ./job.yaml指定创建时的使用的任务 YAML 文件来删除对应的任务kubectl delete pytorchjob ds-nccl-test直接指定任务名来删除任务
使用百舸平台提交任务
- 进入百舸控制台,选择 训练任务>创建任务,在镜像地址中输入 registry.baidubce.com/cce-ai-native/pytorch:22.08-py3-ds-example
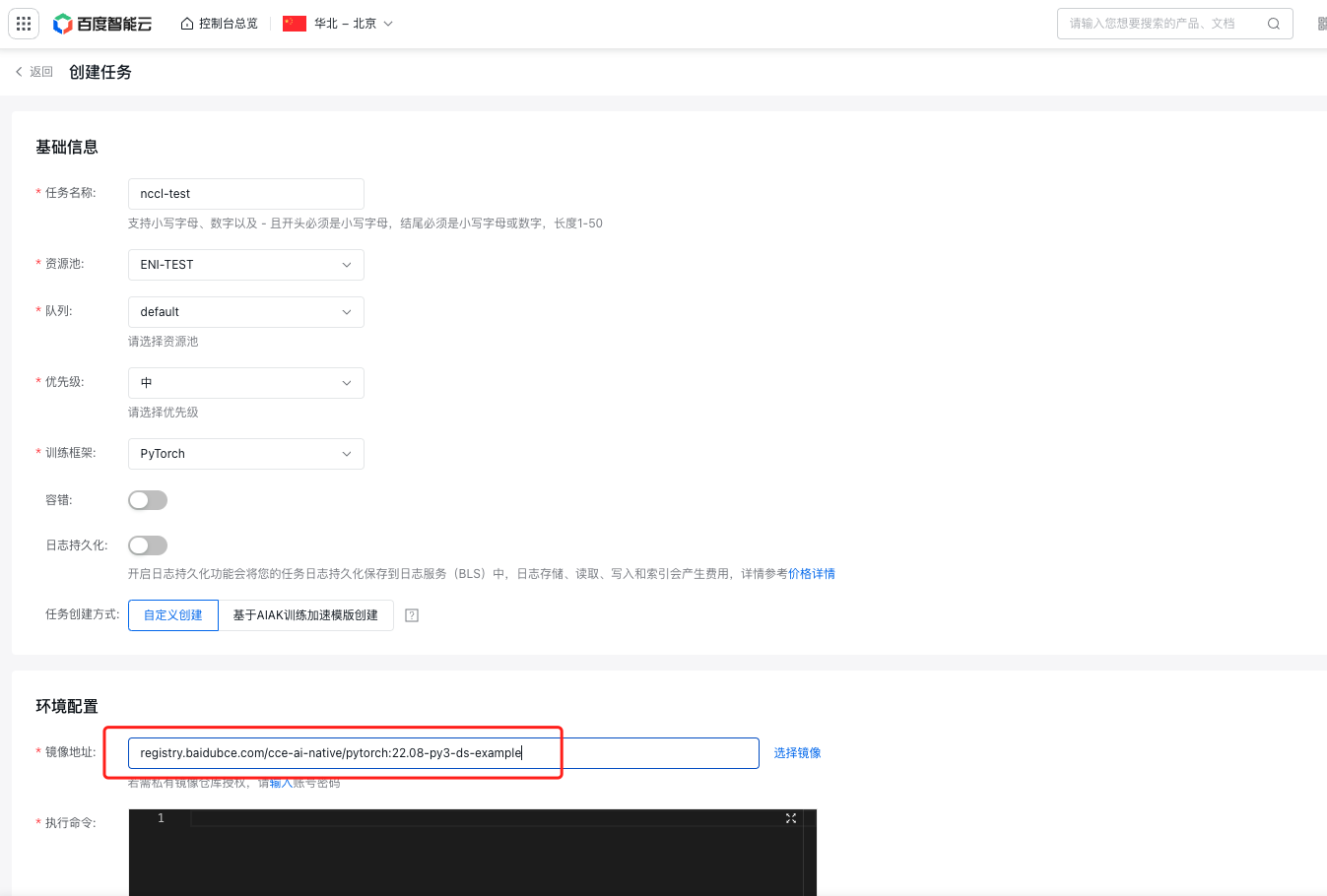
- 在执行命令中输入
run.sh中的命令,点击【完成】提交任务
1#!/bin/bash
2
3# -------------------------------
4# 在原有的启动脚本中增加以下加载conda环境的命令,其他命令保持不变
5# 初始化 PFS 中的 conda
6source /mnt/cluster/test/conda/etc/profile.d/conda.sh
7# 激活与开发机上相同conda 环境ds
8conda activate ds
9# -------------------------------
10
11cd /mnt/cluster/test/code/DeepSpeedExamples/benchmarks/communication
12
13torchrun --nnodes $WORLD_SIZE --node-rank $RANK --nproc-per-node 8 --master-addr $MASTER_ADDR --master-port $MASTER_PORT all_reduce.py --warmups 5 --trials 200 --dist torch --maxsize=28 --debug --scan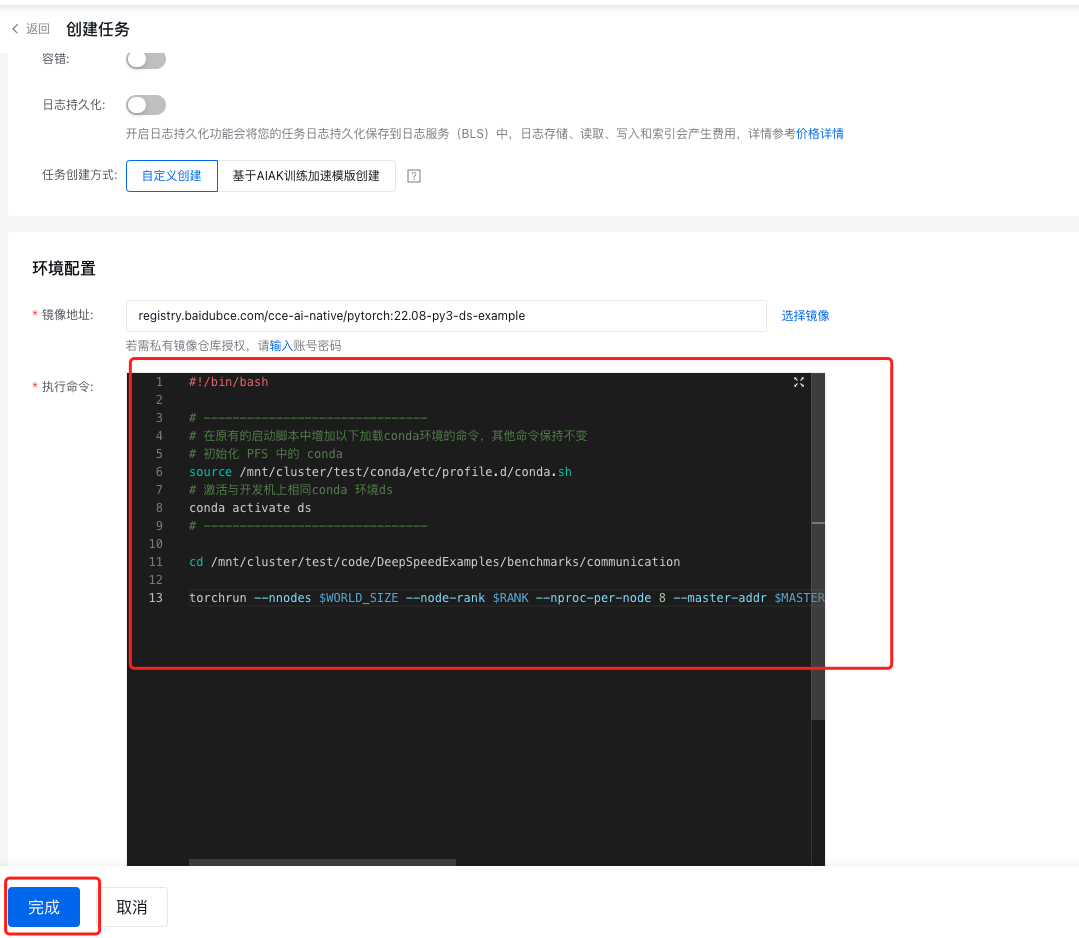
构建自定义基础镜像
使用conda on PFS提交任务最佳实践中方式进行训练时我们需要选择一个环境,并将这个基础环境制作成一个基础镜像供后续训练使用。 以下介绍如何基于百舸基础镜像创建自定义镜像,并利用自定义镜像创建百舸训练任务。
前置准备
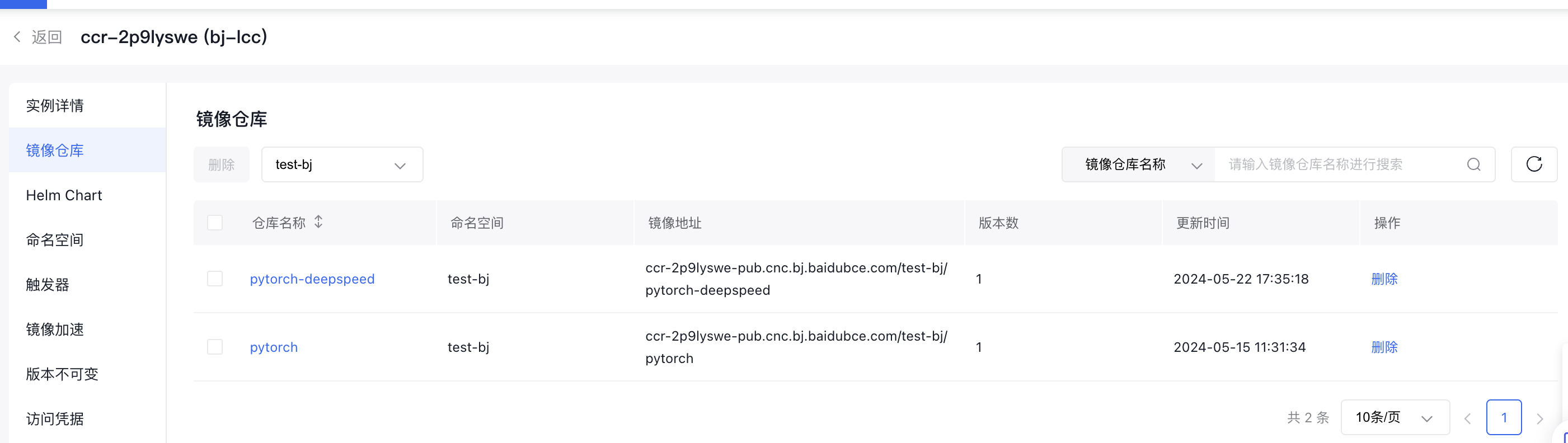
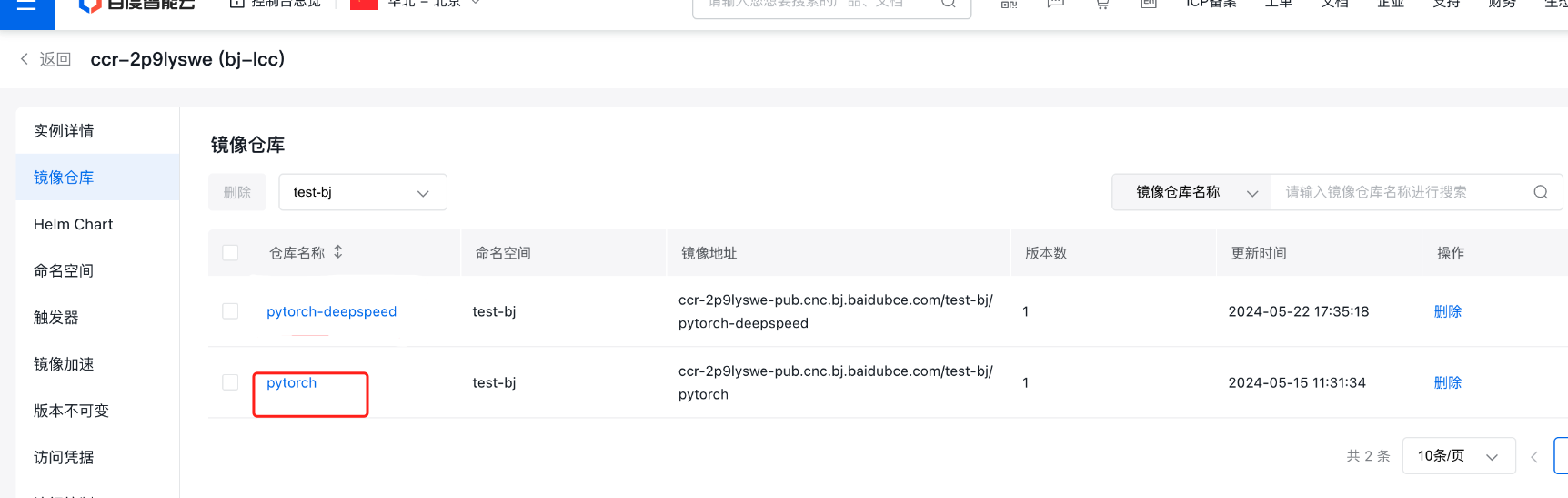
- 开通百度容器镜像服务-CCR(https://cloud.baidu.com/product/ccr.html)(下图中 test-bj为命名空间名称,pytorch-deepspeed为镜像仓库名称)
- 在一台有访问外网权限且装有docker环境的办公PC或本地开发机(非所述的Jupyter Notebook开发机)上登录百度容器镜像服务
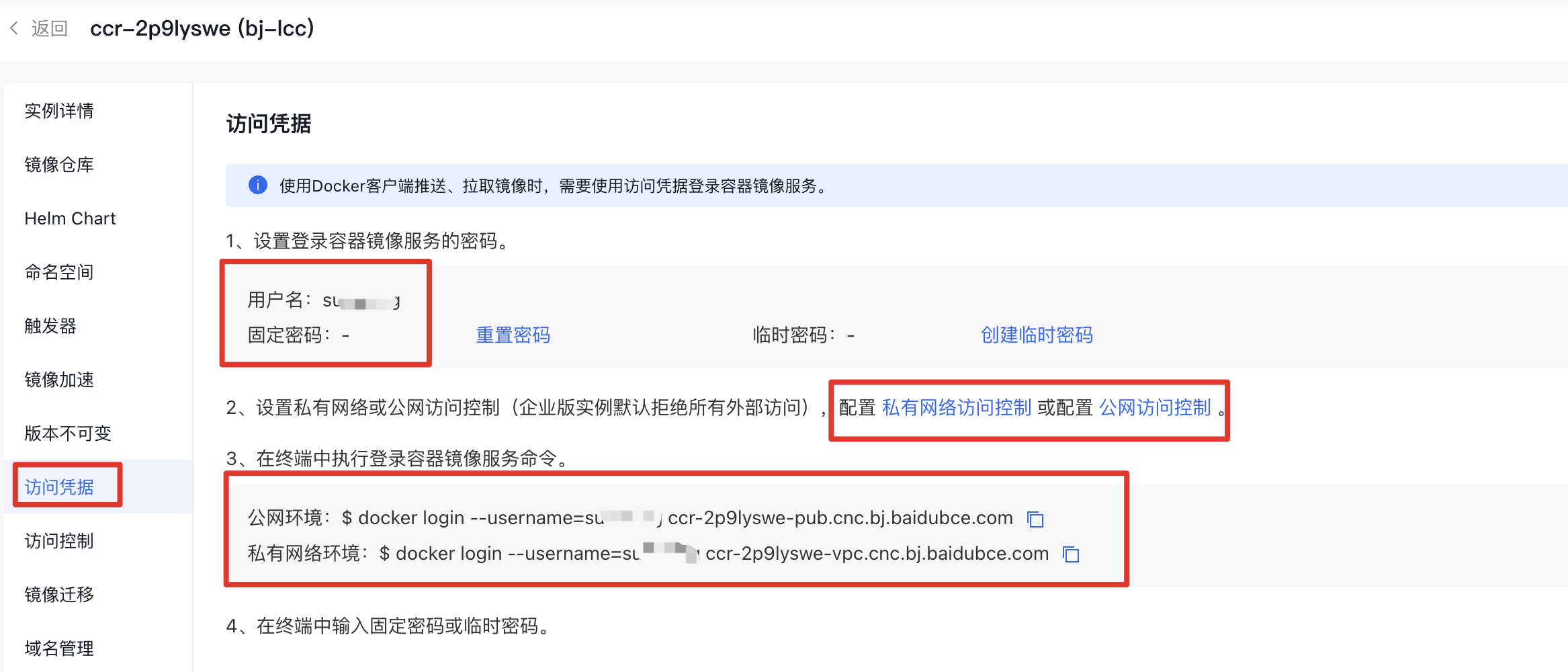
1# 登录百度容器镜像服务
2# 示例 docker login --username=<百度智能云用户名> <实例名称>-<公网或私有网络访问域名>
3docker login --username=xxxxxx ccr-2p9lyswe-pub.cnc.bj.baidubce.com如果有可以远程访问的百度云主机节点,也可以使用云主机进行操作
自定义镜像制作
登录百舸控制台,在 AI加速套件 菜单下,找到要使用的镜像,获取镜像地址
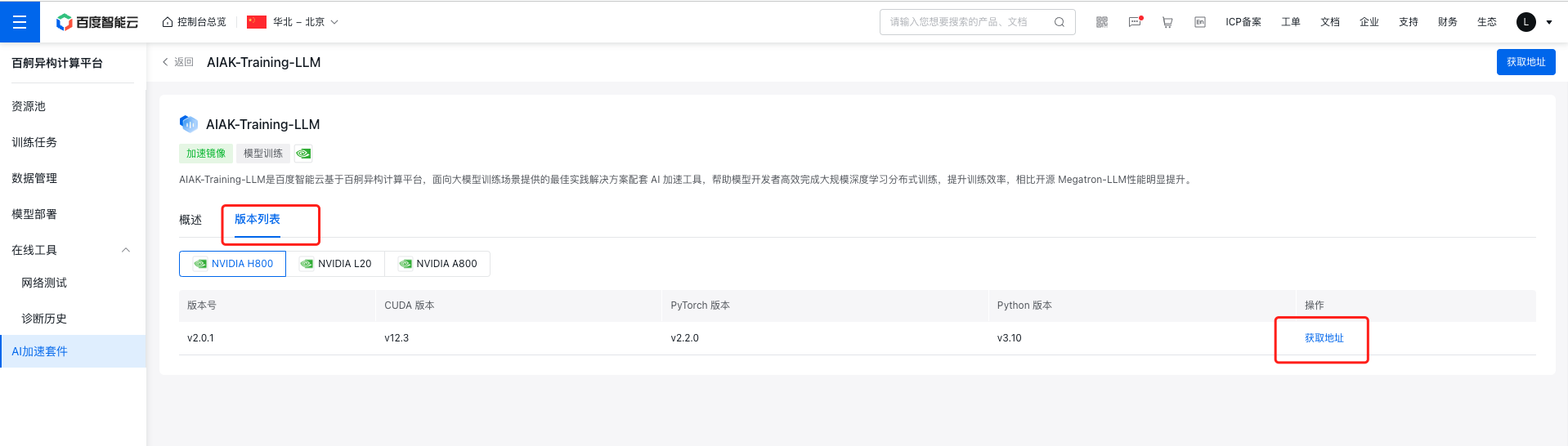
现在以v2.0.1镜像为基础,制作支持自定义镜像(命令中的容器名称、镜像名称、仓库地址需要替换为用户实际名称)
1#启动docker容器
2docker run -itd --net=host --ipc=host --name llm_test --runtime=nvidia registry.baidubce.com/aihc-aiak/aiak-training-llm:ubuntu22.04-cu12.3-torch2.2.0-py310-bccl1.2.4.1_v2.0.1.0_release /bin/bash
3#进入docker容器
4docker exec -it llm_test bash
5
6#安装deepspeed库(使用百度镜像源加速)
7pip3 install deepspeed -i http://mirrors.baidubce.com/pypi/simple/ --trusted-host mirrors.baidubce.com
8#下载测试代码,放在/workspace下
9git clone https://github.com/microsoft/DeepSpeedExamples.git
10#退出容器
11exit
12
13#将当前容器打包成镜像存到本地仓库
14docker commit llm_test pytorch:v1.0
15#查看本地镜像列表,会有名为pytorch的镜像
16docker images
17#标记本地pytorch镜像,镜像id:0b8cffe6e027
18docker tag 0b8cffe6e027 ccr-2p9lyswe-pub.cnc.bj.baidubce.com/test-bj/pytorch:v1.0
19#将标记后镜像推送至实例镜像仓库
20docker push ccr-2p9lyswe-pub.cnc.bj.baidubce.com/test-bj/pytorch:v1.0推送后,CCR仓库中会出现我们自定义的镜像
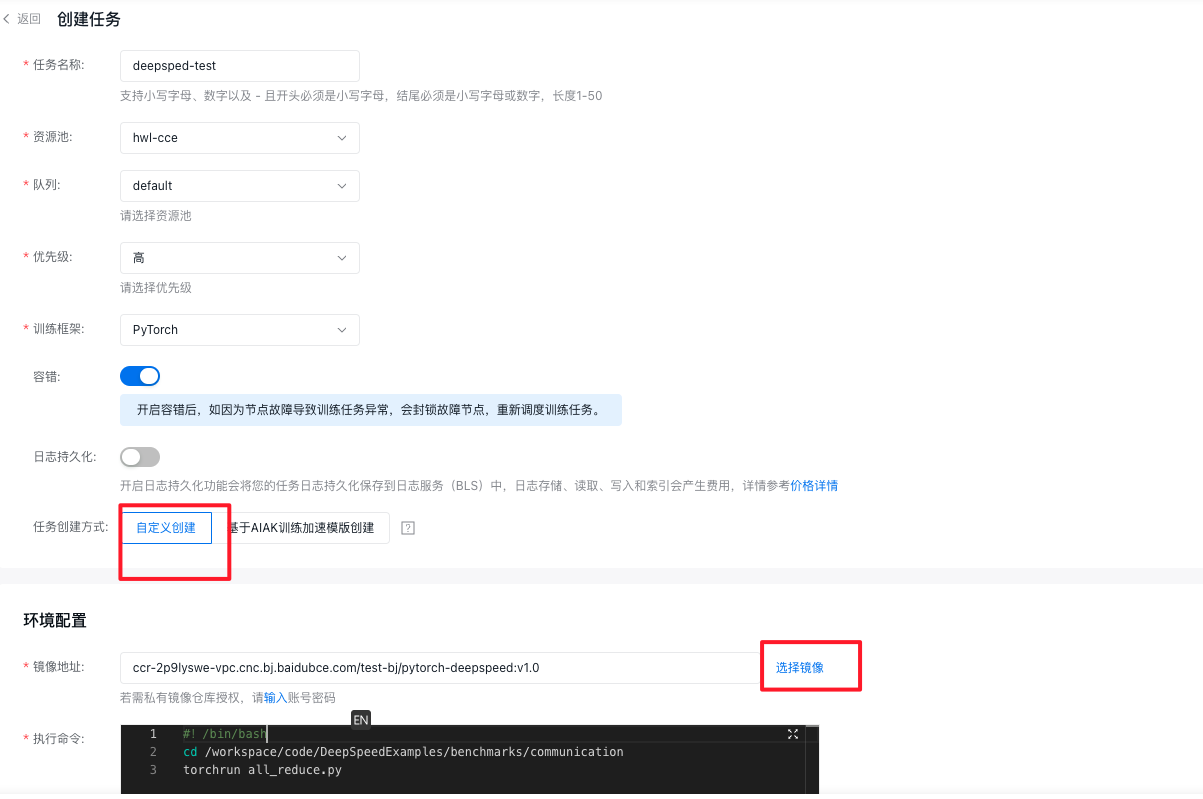
在百舸控制台使用自定义镜像
进入百舸控制台:
- 任务创建方式选择自定义创建
- 在镜像地址中选择上一步上传好的镜像
- 添加执行命令,即可运行
数据/文件上传到开发机
开发机与训练集群使用相同的PFS存储保存数据,因此开发过程中需要使用的权重、数据集、代码等文件只需要上传到PFS中即可在开发机中操作使用 百度云PFS产品提供从百度云对象存储BOS中转存文件,建议将需要使用的文件先上传到对象存储再转存储到PFS
特别注意:开发机从非当前账号下的对象存储中下载文件须具备访问外网的权限
- 安装BOS命令行工具
1# 下载bcecmd程序
2wget https://doc.bce.baidu.com/bce-documentation/BOS/linux-bcecmd-0.3.8.zip
3# 解压
4unzip linux-bcecmd-0.3.8.zip
5cd linux-bcecmd-0.3.8- 下载数据到PFS 在bcecmd中执行如下操作完成将百舸demo数据(存储在百度云对象存储BOS)同步到PFS,存放在/mnt/cluster目录下(以下以LLaMA 7B训练模型及数据下载为例):
1# 数据及模型下载用以下命令
2# 下载测试数据集
3./bcecmd --conf-path conf bos sync bos://cce-ai-datasets/cce-ai-datasets.bj.bcebos.com/megatron_llama/pile_llama_test/ /mnt/cluster/llama/pile_llama_test/
4# 下载模型参数权重
5./bcecmd --conf-path conf bos sync bos://cce-ai-datasets/cce-ai-datasets.bj.bcebos.com/megatron_llama/megatron_llama_7b_checkpoint_tp1_pp1_dp8_zero1/ /mnt/cluster/llama/megatron_llama_7b_checkpoint_tp1_pp1_dp8_zero1/
6# 下载tokenizer
7./bcecmd --conf-path conf bos sync bos://cce-ai-datasets/cce-ai-datasets.bj.bcebos.com/megatron_llama/llama_tokenizer/ /mnt/cluster/llama/tokenizer/更多操作方法参考BOS、PFS产品操作手册
评价此篇文章