
创建人工评估任务
什么是评估数据集
在人工智能模型开发过程中,通常是将数据集划分为训练集、验证集和测试集三个部分。其中,训练集用来训练模型,验证集则用于调整模型的超参数和选择合适的模型,而测试集则是在模型训练完成后,用于最终评估模型的性能,这就是评估数据集(即测试集)。
评估数据集通常是在与训练数据集相似的情况下收集的,因此可以用来代表真实世界的样本数据。通过对评估数据集的评估,可以了解模型在不同场景下的表现,从而更好地优化模型。同时,评估数据集还可以用来验证模型的泛化能力,即模型在未见过的数据上的表现如何。
创建人工评估任务
人工评估可综合人类专家的主观见解、经验等从不同评价维度对模型回复进行打分,用于评估模型回复的效果。
登录百度千帆,在左侧功能导航依次选择「模型服务-模型评估-效果评估」,进入人工评估主任务界面。

点击“创建评估任务”按钮,进入新建评估任务页面,并填写任务所需的基本信息及评估配置。
基本信息
填写评估任务名称、描述。
GSB对比评估
支持对两个模型进行效果好坏的对比或者对同一模型在不同Prompt/参数配置下的效果好坏对比。 评估时可选择Good、Same、Bad三个选项。Good表示:基准模型比对比模型好;Same表示:基准模型和对比模型一样好或一样差;Bad表示:基准模型比对比模型差。
新建推理结果集
推理结果集的位置可以选择平台共享存储或对象存储BOS(开通BOS),如果您选择对象存储BOS,需要另外指定存储Bucket和文件夹。
对象存储BOS,指定结果集(已包含模型批量推理结果)后续的存储方式。非平台存储的数据集,在进行数据管理、评估、处理时需用户自行保证数据地址有效。
注: 若数据集保存在BOS中,请勿在提交任务后修改BOS数据。修改后可能会导致任务失败!
评估模型将按照模型服务的批量推理进行计费。
选择已有推理结果集
您最多可选择5个已有的推理结果集。
评估方法配置
评估方法分为评估场景、评估指标和评估量级,每项分别支持不同的评估选项。
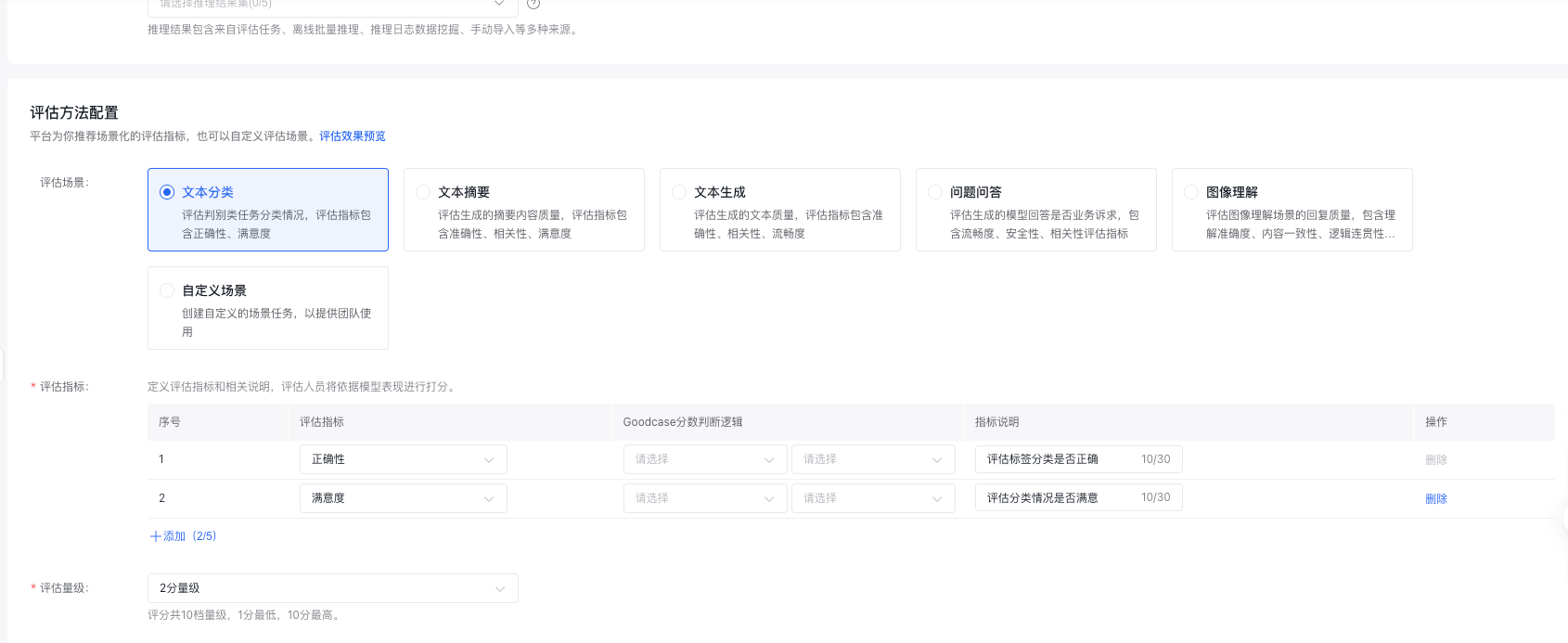
- 评估场景
包含文本分类、文本摘要、文本生成、问题问答、图像理解、自定义场景六大场景,可以选择最适合当前数据集的场景进行配置。
- 评估指标
最多支持5个指标(默认2个),可选范围包含正确性、满意度、准确性、相关性、流畅度、安全性、理解准确度、内容一致性和逻辑连贯性。
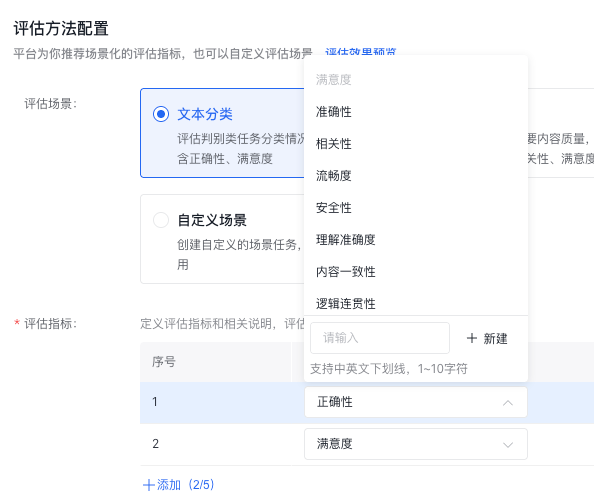
还可以自由设置Good case分数判断逻辑,以及说明,如图所示:

- 评估量级
可以指定人工裁判按照多少个分级来打分,可选范围1-10(最少1级,最多10级)。选完后Good case分数判断逻辑可选项也会相应变化。
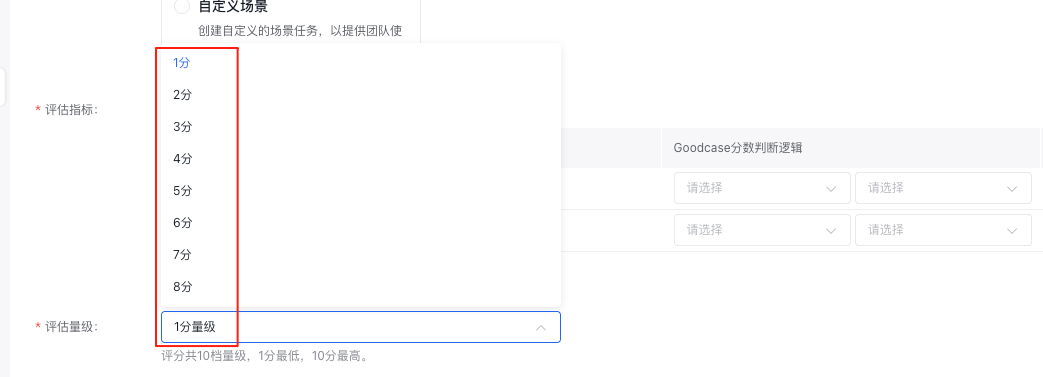
当评估任务在待评估状态下,您可以在操作列点击在线评估对数据进行标注。
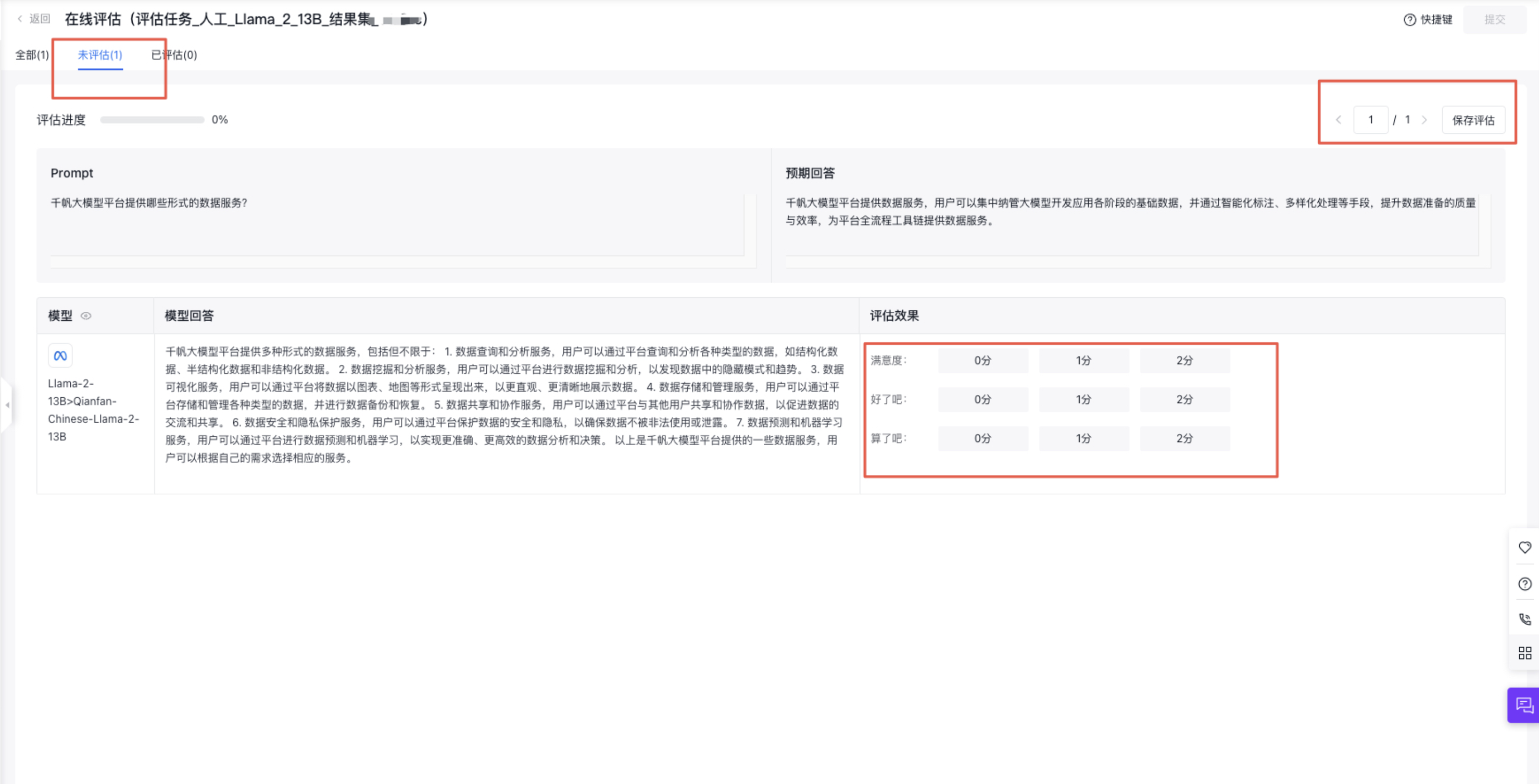
在线评估
当您任务创建成功后,即可在人工评估首页,选择任务的“在线评估”按钮,进行如下数据集的评估任务。
评价此篇文章