
智能诊断
功能简介
面向做大模型服务训练的用户,百度智能云云监控BCM产品基于内部专家长期积累出的丰富诊断经验,推出大模型训练服务观测功能,能够诊断出训练任务的性能问题(slow)并生成诊断报告,提供关键故障特征的分析结果。用户结合诊断结论及建议解决方案,可快速定位并解决问题。
使用流程
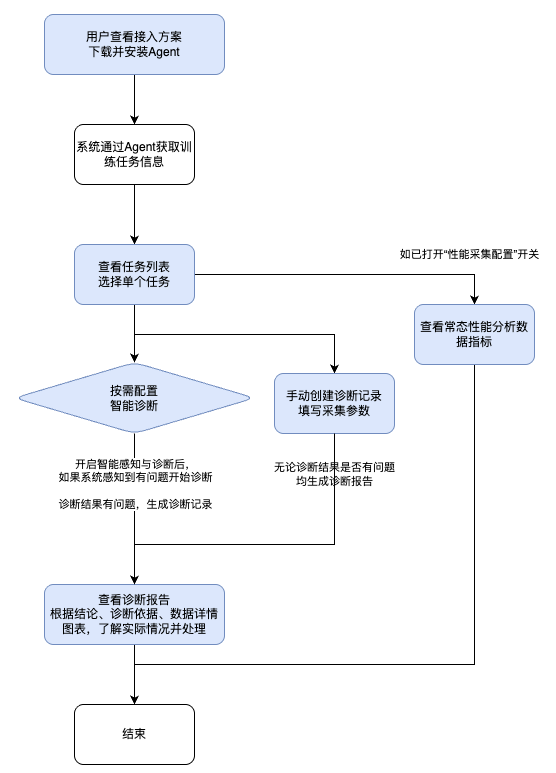
核心概念
-
支持的训练框架
PyTorch框架
-
可感知及诊断的训练状态
slow(任务性能问题):可感知该状态、可发起诊断并生成诊断报告
hang(任务停滞问题):可感知该状态、不可发起诊断
- 智能诊断和单次诊断
| 智能诊断 | 单次诊断 | |
|---|---|---|
| 生成诊断记录的方式 | 开启“智能感知与诊断”开关后,系统通过采集的常态性能分析数据指标持续感知任务是否有异常。 如果异常,会自动开始诊断,诊断出有问题时才会在诊断记录列表中新增一条数据。无需用户自行持续关注。 |
用户手动创建诊断记录。 无论是否有问题,诊断记录列表中均会出现一条新数据。 |
| 诊断配置 | 用户无需配置采集模式(按训练步数采集或按时长采集),系统根据任务当前训练状况,自行判定选择。 | 用户手动选择数据采集模式(按训练步数采集或按时长采集)、采集窗口(步数范围、时长范围)。 |
| 对训练性能影响 | 常态性能分析过程:对训练性能几乎无影响。 采集过程: CPU分析类型对训练性能几乎无影响; GPU分析类型采集过程中,因采集模式和采集窗口均由系统配置,可能会带来数秒的性能抖动,但不会影响训练任务的正常进行。 |
CPU分析类型对训练性能几乎无影响; GPU分析类型采集过程中,因为采集模式和采集窗口由用户配置,因此为了避免对训练任务正常进行带来影响,在相应情况出现时,请按照页面提示信息操作。 |
- GPU与CPU分析类型
| GPU分析类型 | CPU分析类型 | |
|---|---|---|
| 定位 | 利用采集到的全栈(CPU+GPU)数据做性能瓶颈诊断 CPU层面执行函数:Python、C GPU层面执行函数:Kernel |
利用采集到的CPU层面数据做性能瓶颈诊断 |
| 采集信息 | 采集选项:Python堆栈信息、张量形状、PyTorch Module层级信息等 采集的函数类型:各层级函数,主要类型有GPU通信、GPU计算、GPU内存、Python函数、CUDA运行时 结果加工特征:GPU利用率、SM利用率、Warp利用率、GPU计算核函数平均耗时、GPU通信和函数平均耗时、GPU通信堆叠时间占比、主机等待时间、设备等待时间、内核发射延迟 |
关键python函数的执行信息 |
| 采集窗口 | 一般采集数秒~十秒或相应的步数 | 固定窗口5分钟 |
| 采集开始时机 | 无论是智能诊断还是单次诊断,创建诊断记录后才会开始采集 | 只要开启了“智能感知与诊断”开关,就持续有CPU采集的信息 |
| 诊断报告 | 1、诊断结论 2、诊断依据:异常Rank及特征 3、图表分析:各项特征的图表 |
1、诊断结论 2、诊断依据:异常Rank及函数 3、图表分析:函数运行时长表 |
- 推荐使用诊断方式
| 推荐度 | 智能诊断+GPU分析类型 | 智能诊断+CPU分析类型 | 单次诊断+GPU分析类型 | 单次诊断+CPU分析类型 | 性能指标采集 |
|---|---|---|---|---|---|
| 推荐度高 (方便省力、问题发现及时、分析效果最佳) |
✔️ 日常开启 | 保持开启 | |||
| 推荐度中 | ✔️ 日常开启 | ✔️ 按需发起 | 保持开启 | ||
| 推荐度低 | ✔️ 按需发起 | ✔️ 按需发起 | 保持开启 |
操作指南
接入任务
训练任务的接入当前可通过安装采集agent获取。
- 登录百度智能云控制台。
- 在左侧导航栏点击<大模型训练服务观测>-<智能诊断>。
- 点击左上角的“接入任务”按钮。
- 进入<接入任务>页面后,根据页面上的采集器部署说明,下载采集器并启动,任务信息将被自动发现。
完成后,返回上级页面,可查看到当前所有已接入的训练任务列表。
训练任务列表
训练任务列表中展示当前已接入的全部训练任务,可以根据任务运行时间、训练任务名称、任务状态等信息来查询任务。
点击列表上的任务名称,可以进入<任务详情>页面查看性能指标分析图表及诊断记录。
对于训练中的任务,点击操作列的“编辑任务host”,查看该任务所使用的host。如需在任务详情中查看训练性能指标分析的相关图表,或需对任务发起诊断,请保持“性能指标采集”开关在开启状态。
点击操作列的“查看诊断结论”,可跳转到到该任务的诊断记录列表。
训练任务性能指标分析
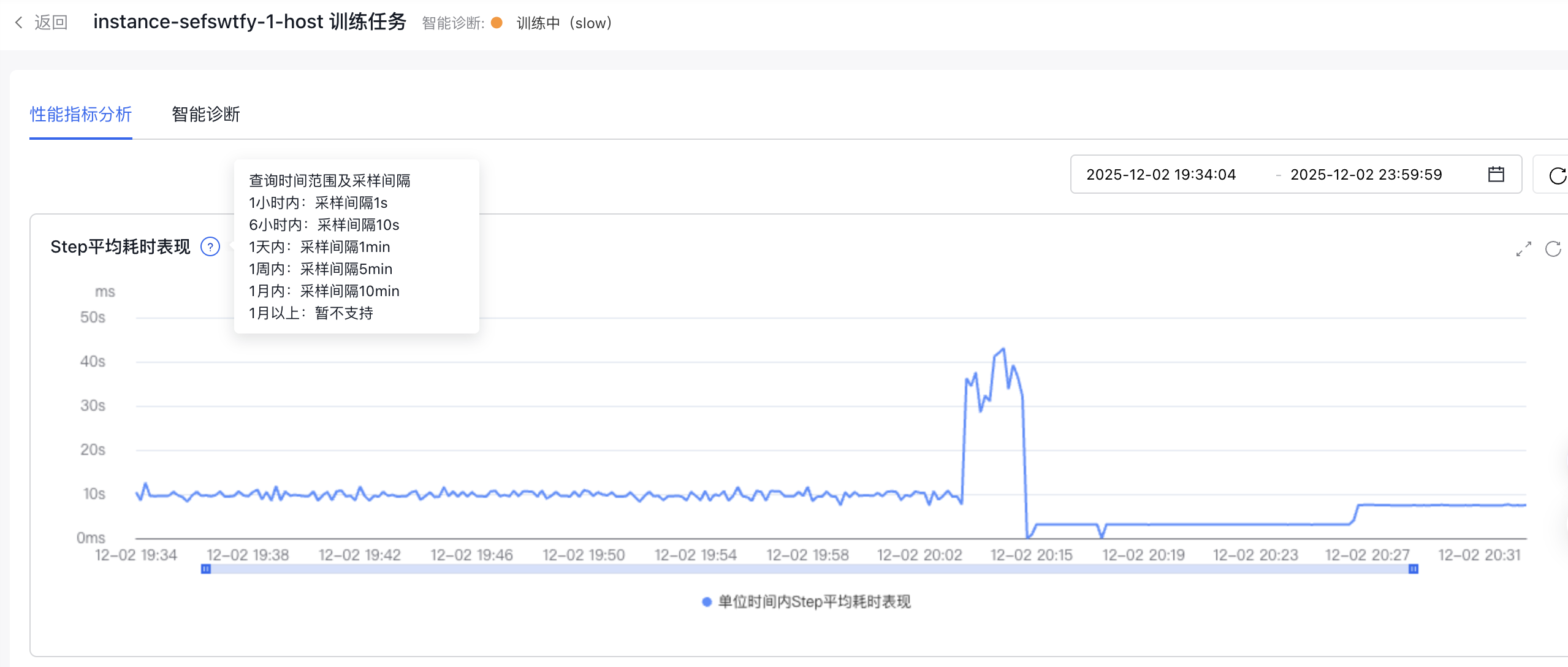
进入所选任务的详情页面,可在“性能指标分析”tab中查看到本任务在指定时间范围内的step平均耗时表现。
Step平均耗时表现
根据所查询的时间范围跨度,对该任务的Step平均耗时做降采样处理,以单位时间内Step的平均耗时表现,来观察任务在此方面的变化趋势。
| 查询时间范围 | 采样间隔 |
|---|---|
| 1小时内 | 采样间隔1s |
| 6小时内 | 采样间隔10s |
| 1天内 | 采样间隔1min |
| 1周内 | 采样间隔5min |
| 1月内 | 采样间隔10min |
| 1月以上 | 暂不支持 |
训练任务诊断
对于训练中的任务,有两种方式可以发起诊断。
1、在智能诊断配置中开启“智能感知与诊断”,系统在感知到任务出现性能异常时,将会自动发起诊断。如诊断出问题将在诊断记录列表中新增一条数据。
2、用户手动发起单次诊断,发起后将在诊断记录中新增一条数据。
无论是智能诊断配置中开启“智能感知与诊断”,还是创建单次诊断记录,均需要开启“性能指标采集”开关。下面就两种方式分别说明。
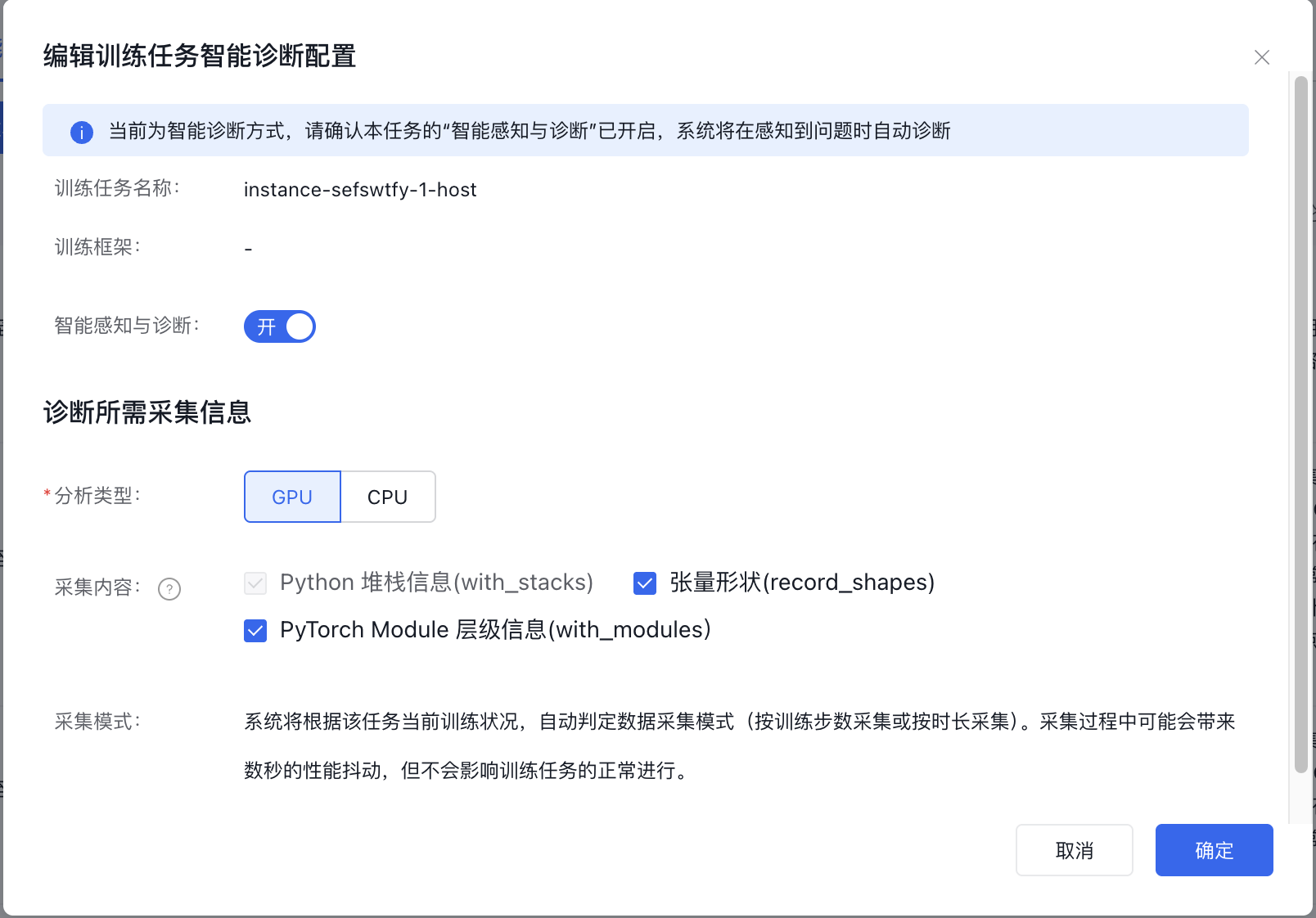
智能诊断配置
在训练任务详情页面的“智能诊断”tab中,点击左上角“智能诊断配置”按钮。在“编辑训练任务智能诊断配置”弹窗中,开启“智能感知与诊断”,选择分析类型及采集内容。
已经训练完成的任务,不可修改智能诊断配置。
- 分析类型:GPU或CPU,详情可参考前文对比表格。
- 采集模式:无需用户手动配置,系统将根据该任务当前训练状况,自动判定数据采集模式(按训练步数采集或按时长采集)。
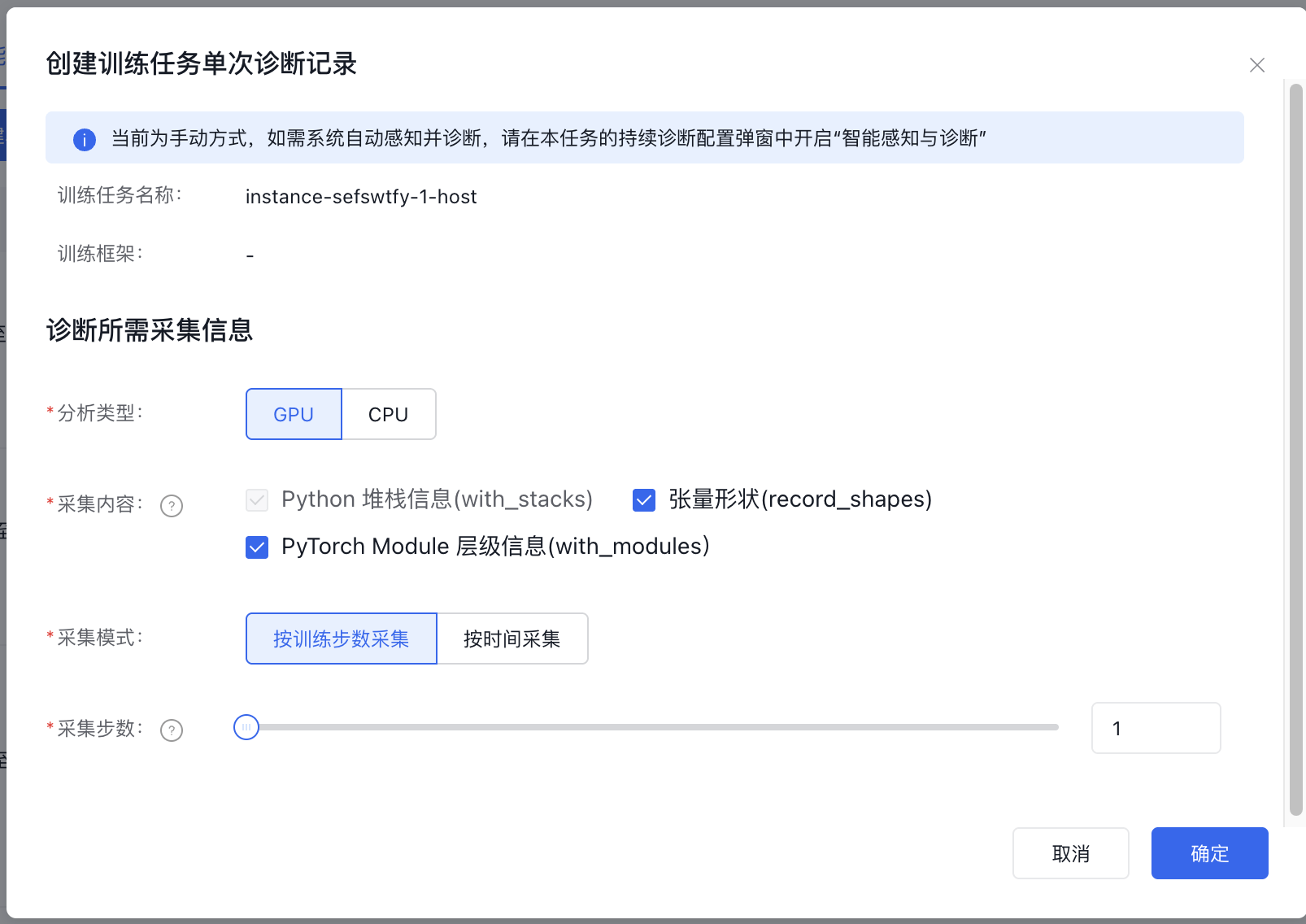
创建单次诊断记录
在训练任务详情页面的“智能诊断”tab中,点击左上角“创建单次诊断记录”按钮,按需选择分析类型及采集内容。
填写过程中,为了避免对训练任务正常进行带来影响,请按照页面提示信息合理配置。
对于已经训练完成的任务,不可发起单次诊断。
智能诊断记录列表
在训练任务详情页面的“智能诊断”tab中,可以查看历史发起过的智能诊断记录。可通过诊断状态、诊断创建来源筛选需要查看的记录,列表上也提供了发起诊断时的配置以及诊断结论等信息。点击智能诊断记录列表操作列中的“查看报告”后,即可查看该次诊断的报告详情。
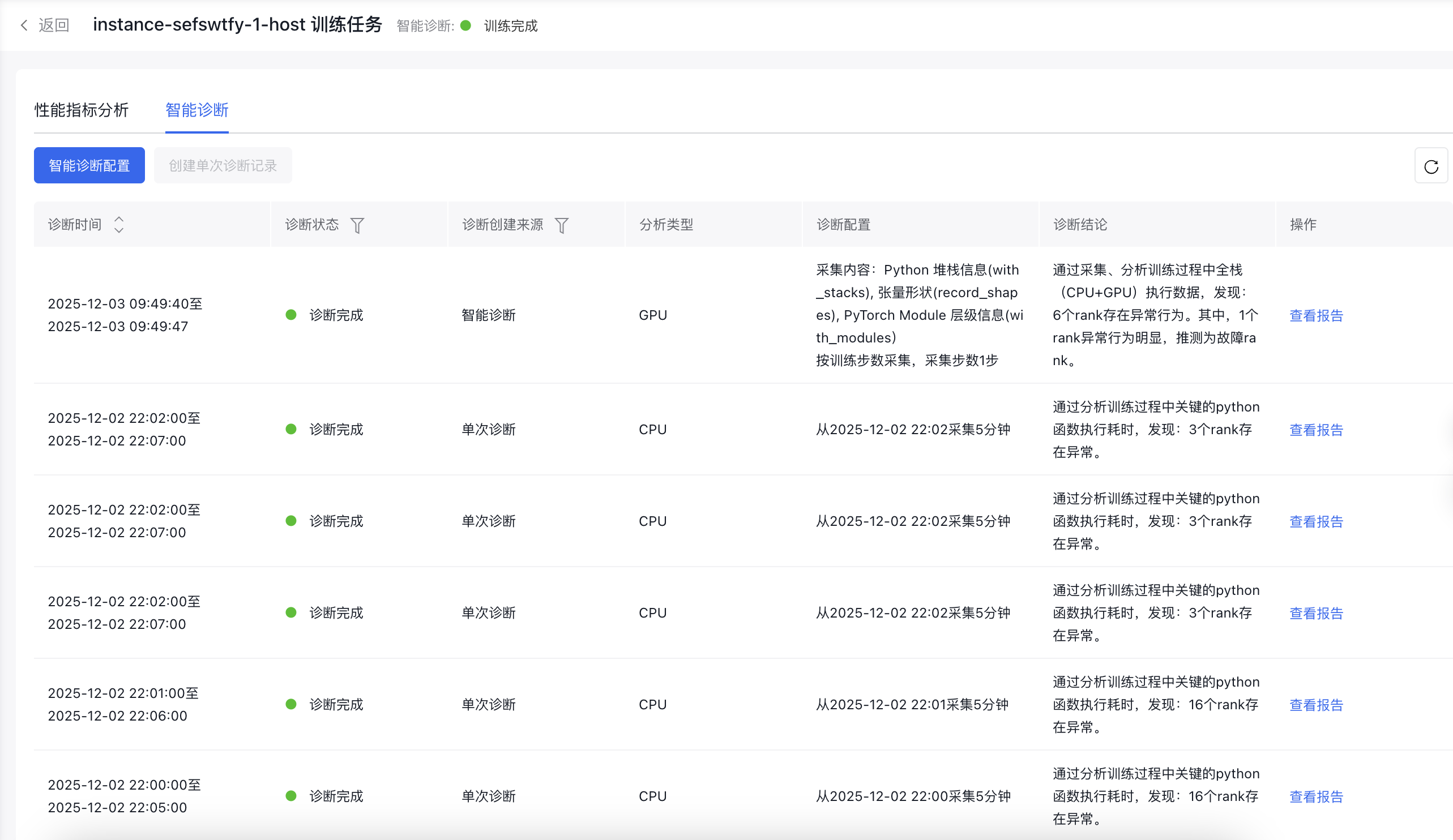
查看报告(分析类型GPU)
报告由三部分组成:
1、诊断结论与建议
2、诊断依据:异常Rank及特征
3、图表分析:各项特征的图表
用户可参考结论对故障做排查与修复,也可进一步在诊断依据中查看每个异常Rank上的异常特征。
如果想查看某个Rank的某项特征详情,可以点击标签,页面将自动定位至下方的特征图表。
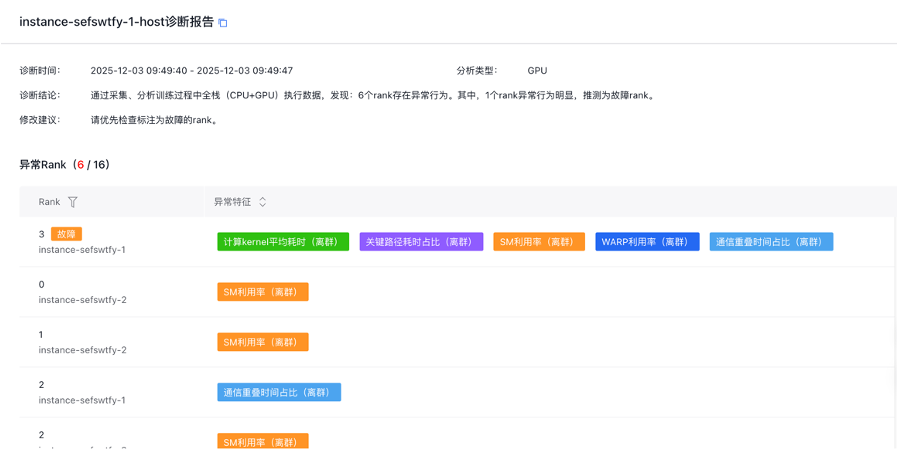
在特征图表中,可以查看每个Rank在该特征上的详细数据。

查看报告(分析类型CPU)
报告由三部分组成:
1、诊断结论
2、诊断依据:异常Rank及函数
3、图表分析:函数运行时长表
用户可参考结论对故障做排查与修复,也可进一步在诊断依据中查看每个异常Rank上的异常函数,包括函数的波动和波动率。
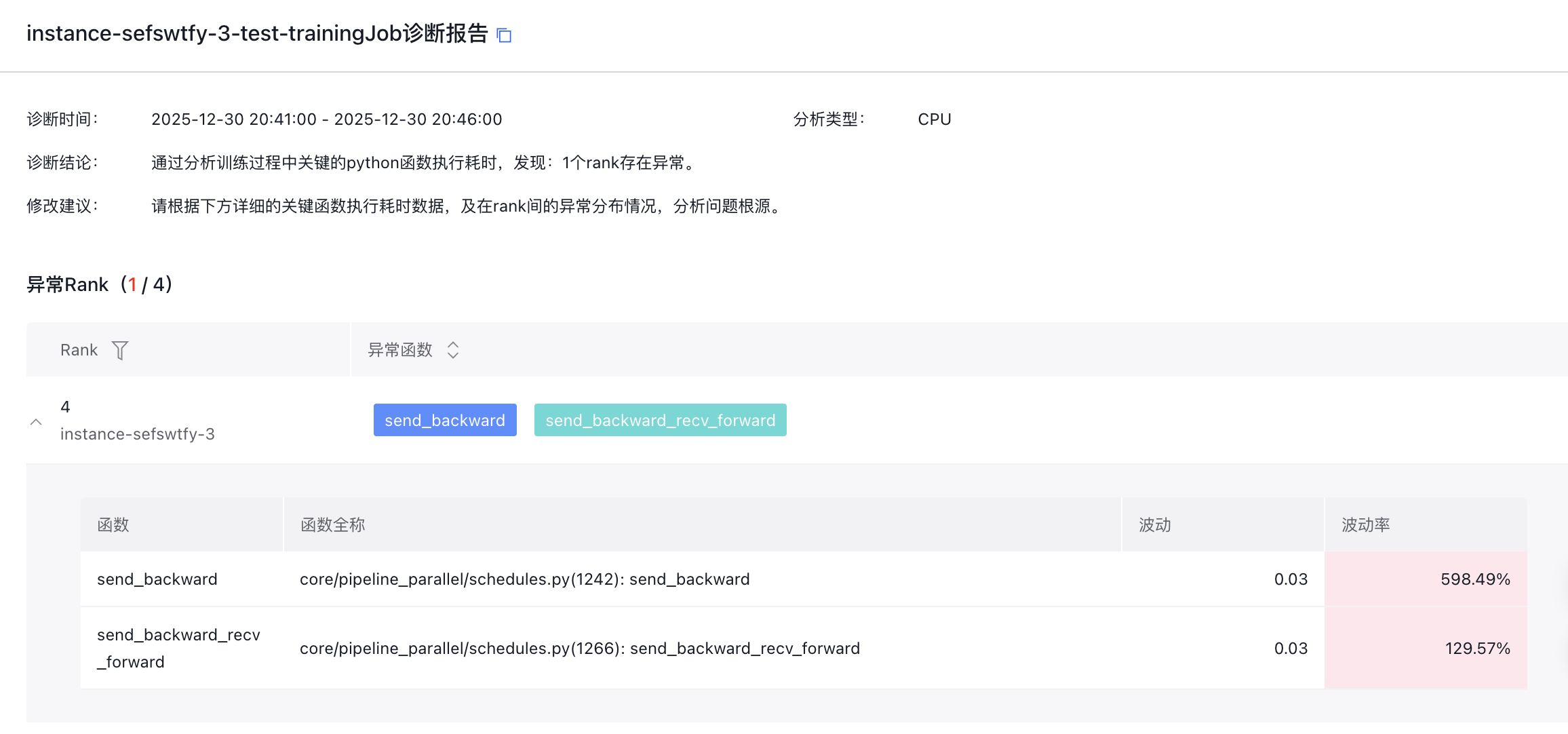
如果想进一步查看函数整体运行状况,可在函数运行时长表格中点击各个函数,并查看指定函数在所有Rank上的波动和波动率表现。
重置任务状态
用户结合报告,对有问题的任务做完故障排查及修复后,可在训练任务列表上点击该任务操作列的“重置任务状态”,该任务将变为“训练中(正常)”。

评价此篇文章