
Row 操作
插入记录
功能介绍
将一条或者一批记录插入到指定的表中。插入语义为Insert,若记录的主键已存在,则插入失败并报错。当插入一批时,该接口暂不支持批次的原子性。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import Row
5
6account = 'root'
7api_key = '$您的账户API密钥'
8endpoint = '$您的实例访问端点' # 例如:'http://127.0.0.1:5287'
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15
16table = db.table("book_vector")
17rows = [
18 Row(id='0001',
19 vector=[0.2123, 0.21, 0.213],
20 bookName='西游记'),
21]
22table.insert(rows)
23
24client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| rows | List<Row> | 是 | 插入的记录列表。 |
插入或更新记录
功能介绍
将一条或者一批记录插入到指定的表中。插入语义为Upsert(Insert or else Update),即,当记录的主键不存在时,则正常插入,若发现主键已存在,则用新的记录覆盖旧的记录。当插入一批时,该接口暂不支持批次的原子性。该接口可用于批量迁移/灌库等场景。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import Row
5
6account = 'root'
7api_key = '$您的账户API密钥'
8endpoint = '$您的实例访问端点' # 例如:'http://127.0.0.1:5287'
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15
16table = db.table("book_vector")
17rows = [
18 Row(id='0001',
19 vector=[0.2123, 0.21, 0.213],
20 bookName='西游记'),
21]
22table.upsert(rows)
23
24client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| rows | List<Row> | 是 | 待插入记录列表。 |
更新记录
功能介绍
更新表中指定记录的一个或多个标量字段的值
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4account = 'root'
5api_key = '$您的账户API密钥'
6endpoint = '$您的实例访问端点' # 例如:'http://127.0.0.1:5287'
7config = Configuration(credentials=BceCredentials(account, api_key),
8 endpoint=endpoint)
9client = pymochow.MochowClient(config)
10db = client.database("db_test")
11table = db.table("book_vector")
12primary_key = {'id': '0001'}
13update_fields = {'bookName': '红楼梦'}
14table.update(primary_key=primary_key, update_fields=update_fields)
15client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| primary_key | Json | 是 | 指定记录的主键值。 |
| partition_key | Json | 否 | 指定记录的分区键值。 如果该表的分区键和主键是同一个键,则不需要填写分区键值。只有在有主键值的情况下,分区键值才会生效。 |
| update_fields | Json | 是 | 待更新的字段列表及其新值。 不允许更新主键、分区键和向量字段。 |
删除记录
功能介绍
删除表中的指定记录。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4
5account = 'root'
6api_key = '$您的账户API密钥'
7endpoint = '$您的实例访问端点' # 例如:'http://127.0.0.1:5287'
8
9config = Configuration(credentials=BceCredentials(account, api_key),
10 endpoint=endpoint)
11client = pymochow.MochowClient(config)
12
13db = client.database("db_test")
14
15table = db.table("book_vector")
16primary_key = {'id': '0001'}
17table.delete(primary_key) # 基于主键的查询删除
18table.delete(filter="id=='0001'") # 基于标量字段的过滤删除
19
20client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| primary_key | Json | 否 | 指定记录的主键值。 |
| partition_key | Json | 否 | 指定记录的分区键值。 如果该表的分区键和主键是同一个键,则不需要填写分区键值。只有在有主键值的情况下,分区键值才会生效。 |
| filter | String | 否 | 删除的标量过滤条件。 当要删除全部记录,可设置为"*";Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。必须填写主键值或过滤条件,二者有且仅能选其一。 |
标量查询
功能介绍
基于主键值进行点查。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4
5account = 'root'
6api_key = '$您的账户API密钥'
7endpoint = '$您的实例访问端点' # 例如:'http://127.0.0.1:5287'
8
9config = Configuration(credentials=BceCredentials(account, api_key),
10 endpoint=endpoint)
11client = pymochow.MochowClient(config)
12
13db = client.database("db_test")
14
15table = db.table("book_vector")
16primary_key = {'id': '0001'}
17projections = ["id", "bookName"]
18res = table.query(primary_key=primary_key, projections=projections)
19
20client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| primary_key | Json | 是 | 指定记录的主键值。 |
| partition_key | Json | 否 | 指定记录的分区键值。 如果该表的分区键和主键是同一个键,则不需要填写分区键值。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时查询结果默认返回所有标量字段。 |
| retrieve_vector | Boolean | 否 | 是否返回结果记录中的向量字段值,默认为False。 |
| read_consistency | ReadConsistency | 否 | 查询请求的一致性级别,取值为: |
批量标量查询
功能介绍
基于主键值的批量点查操作。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import BatchQueryKey
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16keys = [BatchQueryKey({'id':'0001'}),
17 BatchQueryKey({'id':'0002'})]
18projections = ["id", "bookName"]
19res = table.batch_query(keys=keys, projections=projections)
20client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| keys | List<BatchQueryKey> | 是 | 目标记录的主键及分区键 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时查询结果默认返回所有标量字段。 |
| retrieve_vector | Boolean | 否 | 是否返回结果记录中的向量字段值,默认为False。 |
| read_consistency | ReadConsistency | 否 | 查询请求的一致性级别,取值为: |
BatchQueryKey 参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| primary_key | Json | 是 | 目标记录的主键 |
| partition_key | Json | 否 | 目标记录的分区键值。 如该表的分区键和主键是同一个键,则不需要填写分区键值。 |
标量过滤查询
功能介绍
基于标量属性过滤查询记录。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.enum import ReadConsistency
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16
17projections = ["id", "bookName"]
18marker = {'id': 50}
19filter = 'id < 100'
20table.select(filter=filter, marker=marker, projections=projections, read_consistency=ReadConsistency.EVENTUAL, limit=10)
21
22client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
| marker | Json | 否 | 查询的分页起始点,用于控制分页查询返回结果的起始位置,方便用户对数据进行分页展示和浏览,用户不填时,默认从第一条符合条件的记录开始返回。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时查询结果默认返回所有标量字段。 |
| read_consistency | String | 否 | 查询请求的一致性级别,取值为: |
| limit | Int | 否 | 查询返回的记录条数,在进行分页查询时,即每页的记录条数。 默认为10,取值范围[1, 1000]。 |
向量TopK检索
功能介绍
基于向量字段值的KNN或ANN TopK检索操作,支持通过标量字段值进行过滤。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import VectorTopkSearchRequest, FloatVector, VectorSearchConfig
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16request = VectorTopkSearchRequest(vector_field="vector", vector=FloatVector([0.3123, 0.43, 0.213]),
17 limit=10, filter="bookName='三国演义'", config=VectorSearchConfig(ef=200))
18res = table.vector_search(request=request)
19client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| request | VectorTopkSearchRequest | 是 | 检索请求参数描述信息。 |
| partition_key | Json | 否 | 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。 需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 |
| read_consistency | ReadConsistency | 否 | 检索请求的一致性级别,取值为: |
VectorTopkSearchRequest参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| vector_field | String | 是 | 检索的指定向量字段名称。 |
| vector | FloatVector | 是 | 检索的目标向量字段值。 |
| limit | Int | 否 | 返回最接近目标向量的向量记录数量,相当于TopK的K值,默认为50。 |
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
| config | VectorSearchConfig | 否 | 向量检索算法的运行参数 |
VectorSearchConfig参数
| 参数 | 参数类型 | 是否必选 | 适用算法 | 参数含义 |
|---|---|---|---|---|
| ef | Int | 否 | HNSW、HNSWPQ | 检索过程的动态候选列表的大小。 |
| pruning | Boolean | 否 | HNSW、HNSWPQ | 检索过程中是否开启剪枝优化。 |
| search_coarse_count | Int | 否 | PUCK | 粗聚类中心候选集大小。 |
| nprobe | Int | 否 | IVF、IVFSQ | 聚类中心候选集大小。 |
| w | Int | 否 | DISKANN | 检索过程的候选节点宽度。 |
| search_l | Int | 否 | DISKANN | 检索过程中搜索堆的最大候选集合大小。 |
向量范围检索
功能介绍
基于向量字段值的KNN或ANN范围检索操作,支持通过标量字段值进行过滤。向量范围检索当前支持 HNSW、HNSWPQ,不支持 PUCK。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import VectorRangeSearchRequest, FloatVector, VectorSearchConfig
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16request = VectorRangeSearchRequest(vector_field="vector", vector=FloatVector([0.3123, 0.43, 0.213]),
17 distance_range=(0, 20), limit=10, filter="bookName='三国演义'", config=VectorSearchConfig(ef=200))
18res = table.vector_search(request=request)
19client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| request | VectorRangeSearchRequest | 是 | 检索请求参数描述信息。 |
| partition_key | Json | 否 | 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。 需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 |
| read_consistency | ReadConsistency | 否 | 检索请求的一致性级别,取值为: |
VectorRangeSearchRequest参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| vector_field | String | 是 | 检索的指定向量字段名称。 |
| vector | FloatVector | 是 | 检索的目标向量字段值。 |
| distance_range | Tuple[Float, Float] | 是 | 范围检索场景中的最近距离与最远距离,最近距离在前,取值约束如下: |
| limit | int | 否 | 返回最接近目标向量的向量记录数量,相当于TopK的K值,默认为50。 |
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
| config | VectorSearchConfig | 否 | 向量检索算法的运行参数 |
VectorSearchConfig参数
| 参数 | 参数类型 | 是否必选 | 适用算法 | 参数含义 |
|---|---|---|---|---|
| ef | Int | 否 | HNSW、HNSWPQ | 检索过程的动态候选列表的大小。 |
| pruning | Boolean | 否 | HNSW、HNSWPQ | 检索过程中是否开启剪枝优化。 |
| search_coarse_count | Int | 否 | PUCK | 粗聚类中心候选集大小。 |
| nprobe | Int | 否 | IVF、IVFSQ | 聚类中心候选集大小。 |
| w | Int | 否 | DISKANN | 检索过程的候选节点宽度。 |
| search_l | Int | 否 | DISKANN | 检索过程中搜索堆的最大候选集合大小。 |
批量向量检索
功能介绍
基于多个向量字段值的KNN或ANN检索操作,支持通过标量字段值进行过滤。仅适用于多节点标准版,不支持单节点免费测试版。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import VectorBatchSearchRequest, FloatVector, VectorSearchConfig
5
6account ='root'
7api_key ='$您的账户API密钥'
8endpoint ='$您的实例访问端点'# 例如:'http://127.0.0.1:5287'
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16request = VectorBatchSearchRequest(vector_field="vector",
17 vectors=[FloatVector([1, 0.21, 0.213, 0]),
18 FloatVector([1, 0.32, 0.513, 0])],
19 limit=10, filter="bookName='三国演义'",
20 config=VectorSearchConfig(ef=200))
21res = table.vector_search(request=request)
22
23client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| request | VectorBatchSearchRequest | 是 | 检索请求参数描述信息。 |
| partition_key | Json | 否 | 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。 需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 |
| read_consistency | ReadConsistency | 否 | 检索请求的一致性级别,取值为: |
VectorBatchSearchRequest参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| vector_field | String | 是 | 检索的指定向量字段名称。 |
| vectors | List<FloatVector> | 是 | 检索的目标向量字段值。 |
| limit | Int | 否 | 返回最接近目标向量的向量记录数量,相当于TopK的K值,默认为50。 |
| distance_range | Tuple[Float, Float] | 否 | 范围检索场景中的最近距离与最远距离,最近距离在前,取值约束如下: |
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
| config | VectorSearchConfig | 否 | 向量检索算法的运行参数 |
VectorSearchConfig参数
| 参数 | 参数类型 | 是否必选 | 适用算法 | 参数含义 |
|---|---|---|---|---|
| ef | Int | 否 | HNSW、HNSWPQ | 检索过程的动态候选列表的大小。 |
| pruning | Boolean | 否 | HNSW、HNSWPQ | 检索过程中是否开启剪枝优化。 |
| search_coarse_count | Int | 否 | PUCK | 粗聚类中心候选集大小。 |
| nprobe | Int | 否 | IVF、IVFSQ | 聚类中心候选集大小。 |
| w | Int | 否 | DISKANN | 检索过程的候选节点宽度。 |
| search_l | Int | 否 | DISKANN | 检索过程中搜索堆的最大候选集合大小。 |
多向量检索
功能介绍
对多个向量列分别进行相似性检索,对多路结果进行融合排序后返回最终结果。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.schema import RRFRank
5from pymochow.model.table import VectorTopkSearchRequest, MultiVectorSearchRequest, FloatVector, VectorSearchConfig
6
7account ='root'
8api_key ='$您的账户API密钥'
9endpoint ='$您的实例访问端点'# 例如:'http://127.0.0.1:5287'
10
11config = Configuration(credentials=BceCredentials(account, api_key),
12 endpoint=endpoint)
13client = pymochow.MochowClient(config)
14
15db = client.database("db_test")
16table = db.table("book_vector")
17
18requests = [
19 VectorTopkSearchRequest(vector_field="vector1",
20 vector=FloatVector([1, 0.21, 0.213, 0]),
21 limit=100,
22 config=VectorSearchConfig(ef=200)),
23 VectorTopkSearchRequest(vector_field="vector2",
24 vector=FloatVector([1, 0.32, 0.513, 0]),
25 limit=100,
26 config=VectorSearchConfig(ef=200))
27]
28
29request = MultiVectorSearchRequest(requests=requests,
30 ranking=RRFRank(60),
31 filter="bookName='三国演义'",
32 limit=100)
33
34res = table.vector_search(request=request)
35
36client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| request | MultiVectorSearchRequest | 是 | 检索请求参数描述信息。 |
| partition_key | Json | 否 | 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。 需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 |
| read_consistency | ReadConsistency | 否 | 检索请求的一致性级别,取值为: |
MultiVectorSearchRequest
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| requests | List<Union[VectorTopkSearchRequest,VectorRangeSearchRequest]> | 是 | 多向量检索每路的检索向量及其检索参数。 |
| ranking | Union[RRFRank, WeightedRank] | 是 | 融合排序算法参数 |
| limit | Int | 否 | 请求返回的向量记录数量。该参数表示对每路检索的结果进行融合排序之后,将分值最高的 limit 条向量返回。注意该 limit 参数可以与 requests 中每路检索的 limit 参数不同。 |
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
RRFRank
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| k | Int | 是 | RRF 融合排序算法的参数。score 计算公式: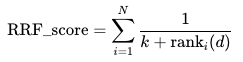 |
WeightedRank
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| weights | List |
是 | WeightedRank 融合排序算法的参数。score 计算公式: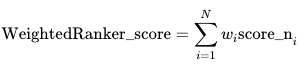 |
全文检索
功能介绍
基于关键字的全文检索,支持通过标量字段值进行过滤。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import BM25SearchRequest
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16request = BM25SearchRequest(index_name="book_segment_inverted_idx",
17 search_text="吕布",
18 limit=10,
19 filter="bookName='三国演义'")
20res = table.bm25_search(request=request)
21logger.debug("res: {}".format(res))
22client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| request | BM25SearchRequest | 是 | 全文检索的详细参数。 |
| partition_key | Json | 否 | 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。 需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 |
| read_consistency | ReadConsistency | 否 | 检索请求的一致性级别,取值为: |
BM25SearchRequest参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| index_name | String | 是 | 倒排索引的名字。 |
| searchText | String | 是 | 全文检索的检索表达式(UTF-8编码)。几种常见用法:content:数据库:在content这列搜索"数据库"关键字content:百度VectorDB数据库:在content这列匹配"百度VectorDB数据库"中任意关键字content:"百度VectorDB数据库":搜索短语"百度VectorDB数据库"content:百度 AND content:VectorDB:在content列同时匹配"百度"、"VectorDB" 关键字 content:百度 OR content:VectorDB:在content列匹配"百度"、"VectorDB"的任意一个更多用法见全文检索表达式 |
| limit | int | 否 | 指定返回相关性最高的条目数。 |
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
全文检索表达式
| 检索类型 | 用法 | 例子 | 例子含义 | 备注 |
|---|---|---|---|---|
| 关键词检索 | field_name:keywordfield_name:(keyword_1, keyword_2) |
title:数据库title:(数据库 百度) |
在title这列搜索“数据库”关键字 在title这列搜索“数据库”、"百度"关键字,满足任意一个即可 |
|
| 关键词检索 | keywordkeyword_1 AND keyword_2 |
数据库数据库 AND 百度 |
在content 这列上搜索"数据库"关键字 在content 这列上搜索,要求同时包括"数据库"、"百度" 关键字 |
只适用于在单列上建立倒排索引的情况。对于多列倒排索引,必须使用上述 field_name:keyword 的方式指定检索词。 |
| 复合检索: AND/OR | query_1 AND query_2query_1 OR query_2(query_1 OR query_2) AND query_3 |
title:数据库 AND title:百度title:数据库 OR title:百度(title:数据库 OR title:百度) AND content:VectorDB |
在title这列搜索, 要求同时包括"数据库"、"百度" 这2个关键字 在title这列搜索, 要求包括"数据库"、"百度" 任意一个 在title这列搜索, 要求包括"数据库"、"百度" 任意一个,同时content列包含"VectorDB"关键字 |
|
| Phrase检索 | field_name:"phrase" |
title:"百度VectorDB数据库" |
在title这里搜索"百度VectorDB数据库"短语 | 短语必须使用双引号 |
| Match检索 | field_name:statement |
content:百度VectorDB的优缺点 |
在content这列搜索"百度VectorDB的优缺点"的任意词,匹配词数量越多,相关性得分越高 | |
| Prefix检索 | field_name:keyword* |
title:数据* |
在title这列检索,包含以"数据"为前缀词的文档 | |
| 更改查询权重 | field_name:keyword^boost |
title:数据库^2 OR content:百度 |
title包括"数据库"关键字,或content包含“百度”关键字,最后计算相关性得分是,title列匹配的文档权重系数为2, content 列匹配的权重系数为1 | 不设置boost的话,默认权重都是1 |
全文检索表达式会将一些特殊字符用于专用目的,如想在表达式中匹配一些特殊字符,需要用 \ 符号进行转义。当前被征用特殊字符包括:
+ - && || ! ( ) { } [ ] ^ " ~ * ? : `
以 百度自研的向量数据库:VectorDB 这个表达式为例,表达式解释器会认为在"百度自研的向量数据库" 这列上搜索 VectorDB,这就违背了使用者的初衷,为此需把表达式写成 百度自研的向量数据库\\:VectorDB。
混合检索
功能介绍
同时进行关键字全文检索和向量检索,检索结果融合排序后返回,也支持通过标量属性进行过滤。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import VectorTopkSearchRequest, BM25SearchRequest, FloatVector, VectorSearchConfig, HybridSearchRequest
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16
17bm25_request = BM25SearchRequest(index_name="book_segment_inverted_idx",
18 search_text="吕布")
19vector_request = VectorTopkSearchRequest(vector_field="vector", vector=FloatVector[0.3123, 0.43, 0.213],
20 limit=10, filter=None, config=VectorSearchConfig(ef=200))
21
22hybrid_search_request = HybridSearchRequest(vector_request=vector_request,
23 bm25_request=bm25_request,
24 vector_weight=0.5,
25 bm25_weight=0.5,
26 limit=10,
27 filter="bookName='三国演义'")
28res = table.hybrid_serch(request=hybrid_search_request)
29logger.debug("res: {}".format(res))
30client.close()请求参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| request | HybridSearchRequest | 是 | 混合检索的详细参数。 |
| partition_key | Json | 否 | 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。 需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。 |
| projections | List<String> | 否 | 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 |
| read_consistency | ReadConsistency | 否 | 检索请求的一致性级别,取值为: |
HybridSearchRequest参数
| 参数 | 参数类型 | 是否必选 | 参数含义 |
|---|---|---|---|
| vector_request | VectorTopkSearchRequest 或 VectorRangeSearchRequest 或 VectorBatchSearchRequest | 是 | 向量检索的详细参数 |
| bm25_request | BM25SearchRequest | 是 | 全文检索的详细参数 |
| vector_weight | Float | 否 | 向量检索结果在混合检索中所占权重,默认0.5 |
| bm25_weight | Float | 否 | 全文检索结果在混合检索中所占比重,默认0.5 |
| limit | Int | 否 | 返回的最相关条目数 |
| filter | String | 否 | 检索的标量过滤条件,表示仅在符合过滤条件的候选集中进行检索,默认为空。Filter表达式语法参照SQL的WHERE子句语法进行设计,其详细描述和使用示例请参见Filter条件表达式。 |
SearchIterator
功能介绍
SearchIterator 提供了一种分页获取搜索结果的机制。在 SearchIterator 请求中,limit参数用于指定当前分页的返回结果数量。通过多次调用迭代器,可以突破单次检索的 topK 数量限制,逐步获取完整的结果集。对于 topK 值较大的搜索请求,推荐使用 SearchIterator 来实现结果的分批次获取。
请求示例
1import pymochow
2from pymochow.configuration import Configuration
3from pymochow.auth.bce_credentials import BceCredentials
4from pymochow.model.table import VectorTopkSearchRequest, FloatVector, VectorSearchConfig
5
6account = 'root'
7api_key = 'your_api_key'
8endpoint = 'you_endpoint' #example http://127.0.0.1:8511
9
10config = Configuration(credentials=BceCredentials(account, api_key),
11 endpoint=endpoint)
12client = pymochow.MochowClient(config)
13
14db = client.database("db_test")
15table = db.table("book_vector")
16
17request = VectorTopkSearchRequest(
18 vector_field="vector",
19 vector=FloatVector([1, 0.21, 0.213, 0]),
20 limit=1000,
21 config=VectorSearchConfig(ef=2000))
22
23iterator = table.search_iterator(request=request, batch_size=1000, total_size=10000) # 初始化 SearchIterator
24
25while True:
26 rows = iterator1.next() # 获取下一批检索结果
27 if not rows:
28 break
29 logger.debug("rows:{}".format(rows))
30
31iterator1.close() # 释放 iterator
32
33client.close()接口描述
Table.search_iterator
- 功能:初始化
SearchIterator对象。 -
参数:
参数名 参数类型 是否必选 参数含义 request VectorTopkSearchRequest或MultiVectorSearchRequest是 检索请求参数描述信息。 batch_size Int 是 每批次检索获取记录条数 total_size Int 是 获取记录总条数 partition_key Json 否 目标记录的分区键值,如果该表的分区键和主键是同一个键,则不需要填写分区键值。
需要注意的是,如果没有指定分区键值,那么该检索请求可能会退化为在该表所有分片上都执行的MPP检索。projections List<String> 否 投影字段列表,默认为空,为空时检索结果返回所有标量字段。 read_consistency ReadConsistency 否 检索请求的一致性级别,取值为: EVENTUAL(默认值):最终一致性,查询请求会随机发送给分片的所有副本;STRONG:强一致性,查询请求只会发送给分片主副本。 - 返回类型:
SearchIterator。
SearchIterator.next
- 功能:执行检索,并返回检索结果。当返回结果为空,说明 SearchIterator 执行结束。
- 参数:无。
- 返回类型:
List<Row>。
SearchIterator.close
- 功能:释放 SearchIterator。执行
close后,不应该再调用next。 - 参数:无。
- 返回类型:无。
限制
- 仅支持 HNSW、HNSWPQ 索引类型。
- 仅支持向量TopK检索(VectorTopkSearch)、多向量检索(MultiVectorSearch),不支持向量范围检索(VectorRangeSearch)、批量向量检索(VectorBatchSearch)、全文检索(BM25Search)、混合检索(HybridSearch)。
- 对于 MultiVectorSearch,仅支持
ws融合排序算法。
评价此篇文章