
借助VectorDB与千帆AppBuilder构建DeepSeek手册知识库
概述
本文展示使用 AppBuilder,VectorDB,DeepSeek-R1,基于清华大学出品的《DeepSeek:从入门到精通》手册,构建你自己的DeepSeek手册知识库。
基本流程是通过控制台开通好向量数据库,AppBuilder和 ModelBuilder,获取相关的信息,然后通过接口完成创建知识库,上传文件,搭建知识库问答。这样即可完成知识库的搭建。如下图所示:
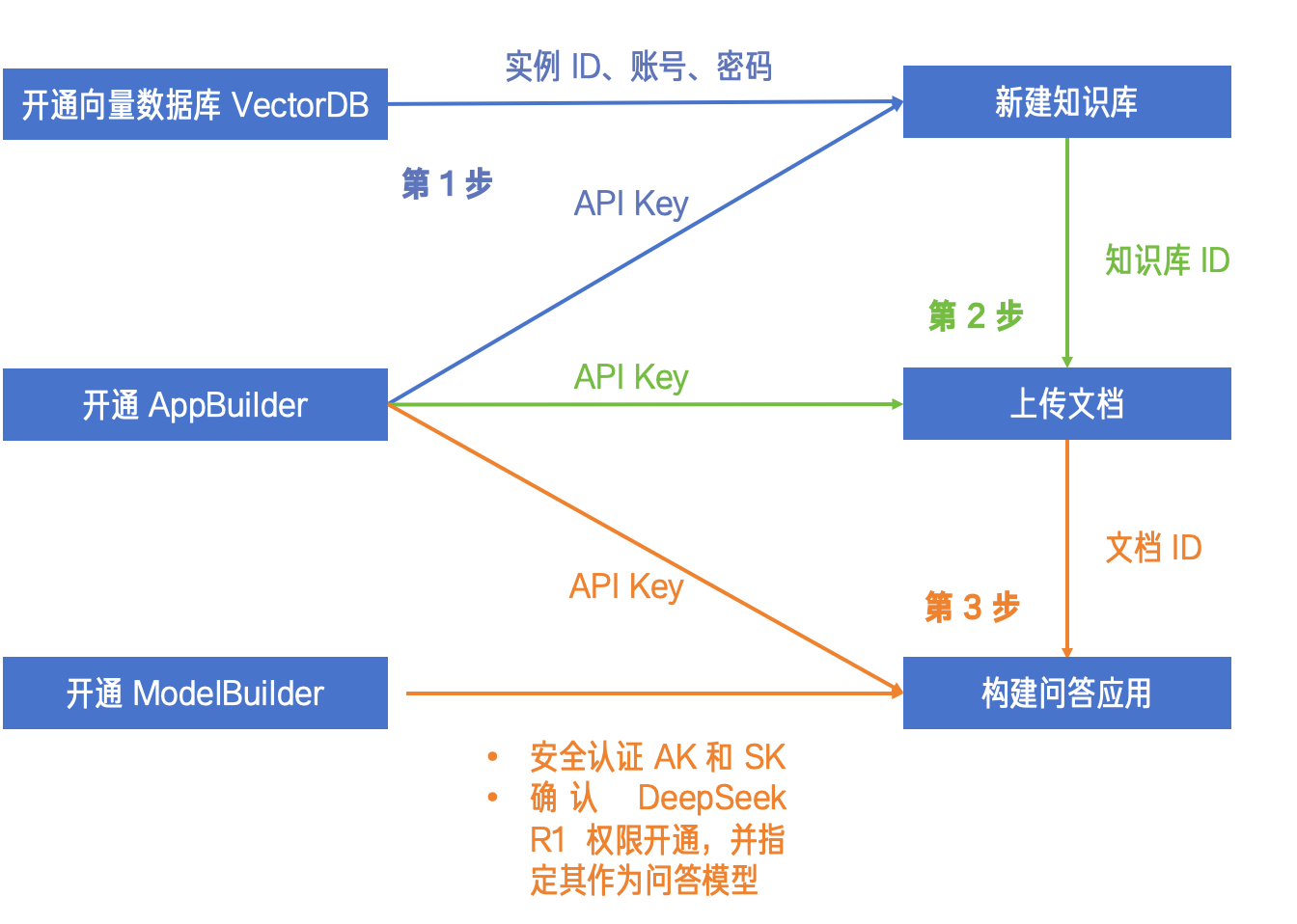
准备环境
向量数据库环境
1、创建百度向量数据库实例,当前每个新用户都有免费试用实例,抓紧申请吧。
地址:https://console.bce.baidu.com/vdb/#/vdb/instance/create
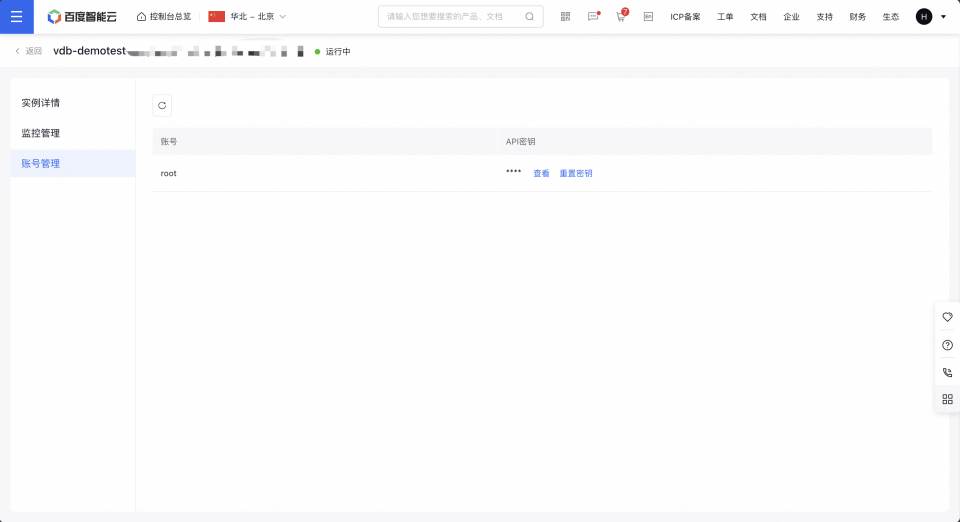
2、创建成功后,通过实例详情页查看访问的地址信息和账号信息,用于访问操作向量数据库。如例子截图,访问信息如下:
1# 访问地址格式:http://${IP}:${PORT}
2访问地址:http://192.168.20.4:5287
3账号:root
4密钥:xxxx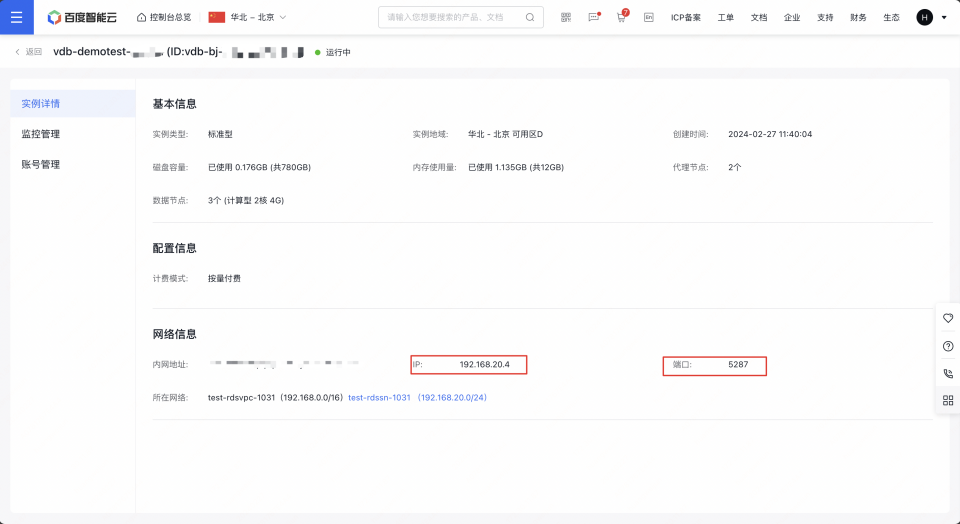
开通 AppBuilder
AppBuilder 目前不收费不会产生费用 1、登录 AppBuilder ,访问“API Key”->“创建 API Key”,获取API Key信息
开通 ModelBuilder
- 登录千帆ModelBuilder控制台,点击用户账号 >安全认证,进入Access Key管理界面。
- 获取安全认证Access Key/Secret Key,在安全认证/Access Key 页面,查看Access Key(即安全认证AK)、Secret Key(即安全认证SK)。
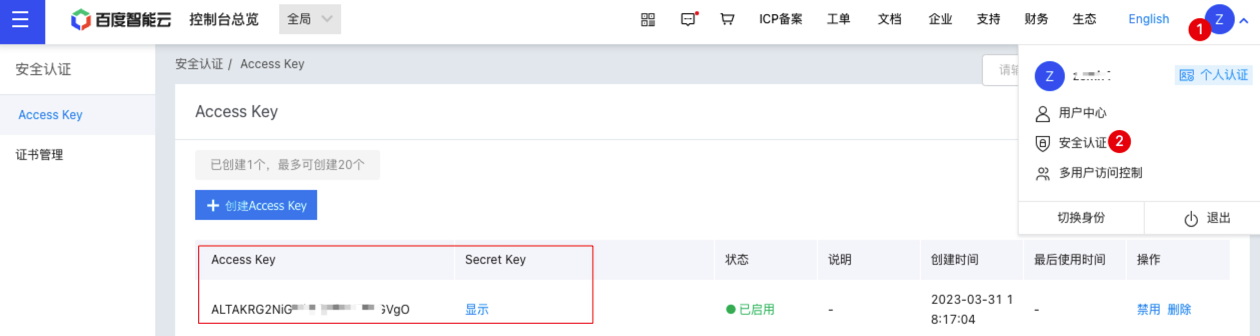
注意:安全认证Access Key/Secret Key,和应用API Key/和 Secret Key不同。安全认证Access Key/Secret Key,更多介绍请参考如何获取AK/SK。
- 保证 DeepSeek-R1 模型权限开通,https://console.bce.baidu.com/qianfan/ais/console/onlineService
安装SDK
执行如下命令,快速安装Python语言的最新版本AppBuilder-SDK,支持 Python >= 3.9版本。
1pip install --upgrade appbuilder-sdk
2pip install qianfan知识库管理
创建知识库
1import os
2import appbuilder
3os.environ["APPBUILDER_TOKEN"] = "bce-v3/ALTAK-********************************" # appbuilder_apikey
4
5knowledge = appbuilder.KnowledgeBase()
6resp = knowledge.create_knowledge_base(
7 name="vdb_knowledge",
8 description="vdb_knowledge",
9 type="vdb",
10 clusterId='vdb-xx-xxxxxxx', # vdb实例ID,例如:vdb-bd-xxxxx
11 esUserName='root', # vdb账号
12 esPassword='**********', # vdb账号对应的password
13 location='bd'
14)
15print("新建的知识库ID: ", resp.id)
16print("新建的知识库名称: ", resp.name)
17
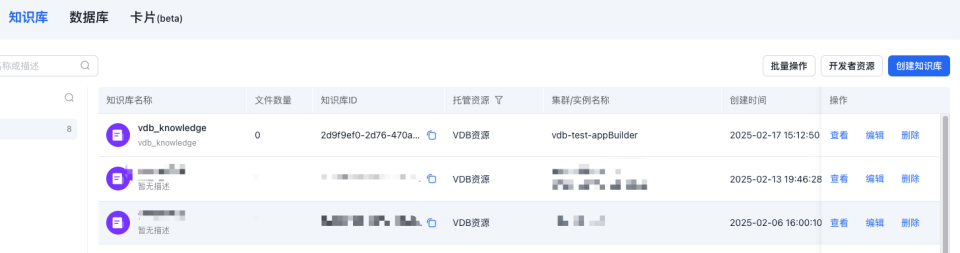
18my_knowledge_base_id = resp.id1新建的知识库ID: 2d9f9ef0-****-****-****-************
2新建的知识库名称: vdb_knowledge在控制台查看所创建的知识库
地址:https://console.bce.baidu.com/ai_apaas/personalSpace/knowledgeBase
上传文档至知识库
详细的文档解析参数见:https://cloud.baidu.com/doc/AppBuilder/s/Olz18mbpq
1import os
2import appbuilder
3from appbuilder.core.console.knowledge_base import data_class
4os.environ["APPBUILDER_TOKEN"] = "bce-v3/ALTAK-********************************" # appbuilder_apikey
5
6my_knowledge_base_id = "2d9f9ef0-****-****-****-************" # 知识库ID
7my_knowledge = appbuilder.KnowledgeBase(my_knowledge_base_id)
8print("知识库ID: ", my_knowledge.knowledge_id)
9
10upload_document_resp = my_knowledge.upload_documents(
11 content_format="rawText", # rawText:文本文档数据
12 file_path="./DeepSeek从入门到精通.pdf",
13 processOption=data_class.DocumentProcessOption(
14 template='custom',
15 parser=appbuilder.DocumentChoices(
16 choices=['layoutAnalysis']
17 ),
18 chunker=appbuilder.DocumentChunker(
19 choices=["separator"],
20 separator=appbuilder.DocumentSeparator(
21 separators=["。", ",", "!", "?"],
22 targetLength=300,
23 overlapRate=0.25,
24 ),
25 prependInfo=["title", "filename"],
26 ),
27 knowledgeAugmentation=appbuilder.DocumentChoices(
28 choices=["faq"]
29 )
30 )
31)
32
33document_id = upload_document_resp.documentId
34print("文档ID: ", document_id)1文档ID: dd1a5b81-****-****-****-************检查文档是否可以使用
在控制台查看上传的文档
地址:https://console.bce.baidu.com/ai_apaas/personalSpace/knowledgeBase/detail/{my_knowledge_base_id}
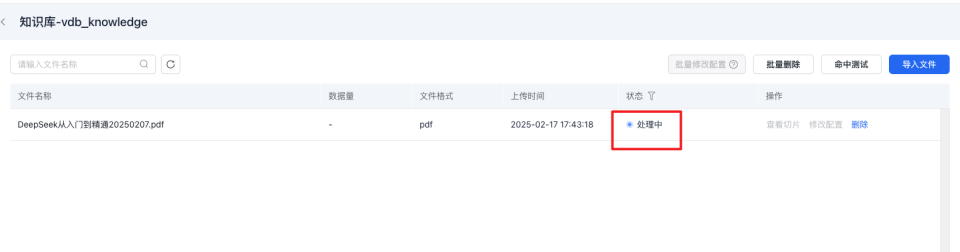
当文档的状态为可用时,便可以对该文档发起知识库检索
使用sdk检查文档状态
详细的参数见:获取知识库的文档列表
1import os
2import appbuilder
3os.environ["APPBUILDER_TOKEN"] = "bce-v3/ALTAK-********************************" # appbuilder_apikey
4
5knowledge_base_ID = "2d9f9ef0-****-****-****-************" # 知识库ID
6document_ID = "dc75bbd3-****-****-****-************" # 文档ID
7my_knowledge = appbuilder.KnowledgeBase(my_knowledge_base_id)
8
9doc_is_ready = False
10doc_list = my_knowledge.get_all_documents(my_knowledge_base_id)
11for doc in doc_list:
12 if doc.id == document_id:
13 doc_is_ready = (doc.word_count != 0 and doc.enabled)
14 break
15doc_status = "可用" if doc_is_ready else "处理中"
16print(f'文档可用状态:{doc_status}')1文档可用状态:处理中构建本地问答知识库
详细的查询参数见:https://cloud.baidu.com/doc/AppBuilder/s/ym4wo8a0p
1import os
2import appbuilder
3from appbuilder.core.console.knowledge_base import data_class
4from qianfan import Qianfan
5
6os.environ["QIANFAN_ACCESS_KEY"] = "****************************" # modelbuilder_ak
7os.environ["QIANFAN_SECRET_KEY"] = "****************************" # modelbuilder_sk
8
9os.environ["APPBUILDER_TOKEN"] = "bce-v3/ALTAK-********************************" # appbuilder_apikey
10
11PROMPT_TEMPLATE = """
12参考以下信息回答我的问题:
13{context}
14---
15我的问题或指令:
16{question}
17---
18请根据上述参考信息回答我的问题或回复我的指令。前面的参考信息可能有用,也可能没用,你需要从我给出的参考信息中选出与我的问题最相关的那些,来为你的回答提供依据。回答一定要忠于原文,简洁但不丢信息,不要胡乱编造。我的问题或指令是什么语种,你就用什么语种回复,
19你的回复:
20"""
21
22knowledge_base_ID = "2d9f9ef0-****-****-****-************" # 知识库ID
23document_ID = "dc75bbd3-****-****-****-************" # 文档ID
24
25knowledge = appbuilder.KnowledgeBase()
26
27def answer(question):
28 res = knowledge.query_knowledge_base(
29 query=question,
30 type=data_class.QueryType.HYBRID,
31 knowledgebase_ids=[knowledge_base_ID],
32 top=2,
33 skip=0,
34 metadata_filters=data_class.MetadataFilters(
35 filters=[
36 ],
37 condition="or"
38 ),
39 pipeline_config=data_class.QueryPipelineConfig(
40 pipeline=[
41 data_class.VectorDBRetrieveConfig(
42 name="step1",
43 pre_ranking=data_class.PreRankingConfig(
44 bm25_b=0.75,
45 bm25_weight=0.25,
46 vec_weight=0.75,
47 bm25_k1=1.5,
48 bm25_max_score=50,
49 )
50 ),
51 data_class.RankingConfig(
52 name="step2",
53 type="ranking",
54 inputs=["step1"],
55 model_name="ranker-v1",
56 top=20,
57 ),
58 data_class.SmallToBigConfig(
59 name="step3",
60 type="small_to_big"
61 )
62 ],
63 ),
64 )
65
66 context = ""
67 for id, chunk in enumerate(res.chunks):
68 context = context + f'{chunk.content}' + "\n"
69
70 # 使用deepseek-r1模型来总结从知识库检索中的结果
71 client = Qianfan()
72
73 completion = client.chat.completions.create(
74 model="deepseek-r1", # 指定deepseek-r1模型
75 messages=[
76 {'role': 'user', 'content': PROMPT_TEMPLATE.format(context=context, question=question)},
77 ]
78 )
79
80 return completion.choices[0].message.content
81
82if __name__ == "__main__":
83 while True:
84 question = input("输入你的问题(输入 exit 退出对话):")
85 if question.lower() == 'exit':
86 break
87 ret = answer(question)
88 print(f'回答:{ret} \n')1输入你的问题(输入 exit 退出对话):deepseek 能做什么
2回答:
3
4根据参考信息,DeepSeek能够:
5- 处理复杂任务且支持免费商用
6- 在数学、代码、自然语言推理等任务上展现优秀性能
7- 通过强化学习技术提升模型推理能力,性能可比肩OpenAI-o1正式版
8
9其开源推理模型DeepSeek-R1主要应用于通用人工智能领域的大模型研发与应用。
10
11输入你的问题(输入 exit 退出对话):该如何使用合适的提示语
12回答:
13
14根据参考信息,使用合适提示语的步骤如下:
15
161. **个人化体验设计**
17- 要求描述具体经历细节(如[个人经历])
18- 需包含情感变化过程
19- 通过真实故事增强温度感
20
212. **情感共鸣构建**
22- 使用温暖的情感化语言
23- 采用故事化表达手法
24- 重点突出引发共鸣的关键点
25
263. **互动引导设计**
27- 在结尾添加号召性语句
28- 明确请求互动形式(点赞/评论/分享)
29- 使用"鼓励"等引导性动词增强传播性
30
314. **提示词工程应用**
32- 先设定明确生成目标(如获取信息/生成文本)
33- 给AI分配特定身份角色
34- 将复杂任务分步拆解说明
35
36需注意:所有提示语需包含具体场景上下文,情感表达要贯穿内容始终,最终需落脚到明确的互动引导诉求。
37
38输入你的问题(输入 exit 退出对话):文案写作的要注意哪些提示语
39回答:
40
41根据参考信息,文案写作需重点注意以下提示语设计要点:
42
431. **信息传递框架**
44 - 确保信息层次清晰(需明确分层指令)
45 - 表达简洁精准(限定关键词或字数)
46 - 结构逻辑严密(说明信息点间的关联)
47 - 强化受众针对性(包含受众特征描述)
48 - 突出记忆点(重复或变换表达核心信息)
49
502. **差异化设计**
51 - 塑造真实感(避免过度修饰)
52 - 体现专业性(加入数据/用户反馈)
53 - 保持种草自然度(文案与图片配合流畅)
54 - 增加互动引导(鼓励评论/点赞)
55
563. **文案结构要求**
57 - 开篇吸引力(直接点明亮点)
58 - 个人经验铺垫(增强亲和力)
59 - 方法说明与效果总结(避免空洞描述)
60 - 购买建议实际化(避免强硬推销)
61
624. **标题设计**
63 - 包含关键词、数据/方法、价值承诺
64 - 语气亲和专业(禁用过度营销词)
65 - 创新性(分析竞品结构/用词差异)
66
67(以上要点均来自表格中关于信息传递特质、差异化要求、文案结构和标题设计的核心规则)
68
69输入你的问题(输入 exit 退出对话):评价此篇文章