百度智能云VectorDB产品基于自研的“莫愁”向量数据库内核构建,充分利用了百度内部在分布式存储&数据库领域的成熟经验,实现了高性能、低成本、高可靠、高可用、强扩展和大规模的能力。
VectorDB产品是经典的托管型产品架构,除了前端和控制台(Console),后端由两大层次构成:管控层和内核层,分别简介如下:
管控层 :与控制台协作,完成产品实例的购买/释放/计费/扩缩容等各类操作,并将产品信息通过控制台暴露给客户;在内部,管控层负责创建虚拟机资源并在虚拟机中完成数据库内核系统的部署以及后续的运维和监控等。 内核层 :数据库内核系统,提供数据库核心能力,负责完成客户的一些列数据相关的操作,例如建库建表,增删查改等。因此,我们可以看到,VectorDB产品的接口被划分为OpenAPI和SDK两大部分。其中OpenAPI对应的是管控层,负责完成一些控制台和管控层面的操作,SDK(包括相应的HTTP API)负责与莫愁内核交互,完成各类数据库访问和操作。
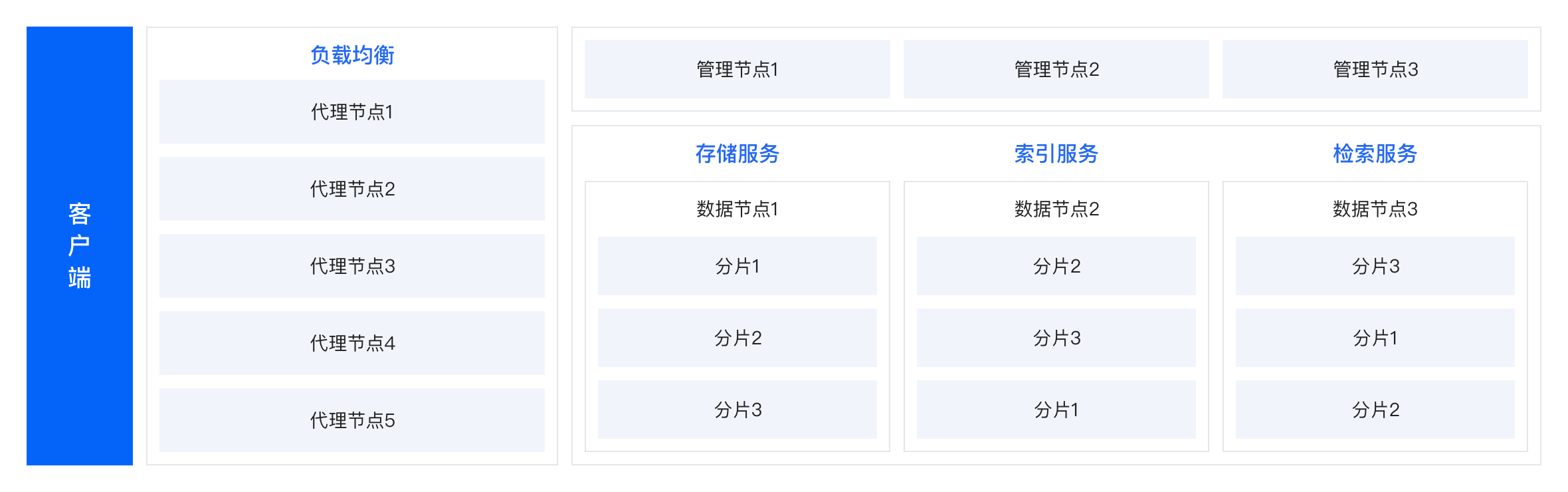
在物理架构层面,莫愁内核由代理节点、数据节点和管理节点等角色构成,分别简介如下:
代理节点(Proxy) :一组无状态,采用对等部署模式的节点,负责接入、转换并执行用户的请求,支持负载均衡。管理节点(Master) :集群的中控角色,管理集群的物理拓扑、逻辑拓扑、数据库元数据、各类资源等,基于Raft协议构建,支持高可用。数据节点(DataNode) :集群的数据服务角色,内置朱雀引擎 ,提供标量/向量数据的存储、索引和检索等服务,负责数据的增删改查和检索等,是数据流的核心。通过Raft协议管理表/集合数据的分片及其副本,支持自动Failover和弹性伸缩等。
下图展示了这些节点之间的关系:
从资源层面来看,VectorDB的一张表,支持横向划分为多个分区,每个分区称为一个Partition。支持设定分区的副本数(Replication),系统自动将每个分区的不同副本尽量分布到不同的数据节点上,尽可能降低数据节点故障对各副本的影响,尽可能的实现更高的可用性和可靠性。副本之间,采用Raft一致性协议进行管理,多个副本之间自动选主并由主副本来接受更新类操作。当存在数据节点宕机导致某些副本缺失之后,Master会检测到该异常,然后找到一个合适的数据节点,触发对该分片建立新的副本,这就是自动Failover机制。此外,Master还会频繁检测各个数据节点之间的副本数(或主副本数)或者数据量是不是处于均衡的状态,如果出现了严重的不均衡,则会触发一系列的再均衡机制,具体而言,就是计算出哪些副本放到哪些节点会更合适,并建立副本迁移任务,推进副本迁移,最终实现平衡。通过上述的各类机制,可以轻松实现自动化地应对数据节点的上下线,从而支撑弹性伸缩。
Raft协议基于多数派原理,因此,在一个Raft复制组中,只要大多数副本正常,那么就不会影响整个复制组的更新操作,从而可以容忍少数副本异常,实现更高的可用性。在成熟的分布式实践中,如果对可用性没有极为苛刻的要求,推荐采用3副本即可,3的大多数是2,因此在一组3副本的复制组中,可以容忍1个副本异常,一般可以实现99.9%~99.99%的可用性(可用性还受其它因素影响)。若副本数只有2,由于2的大多数仍然是2,故无法容忍任何副本异常。另一方面,若业务对可用性有着极高的要求,那么可以考虑采用更高的副本数,例如采用5副本,那么可以容忍2个副本异常。当然,较高的副本数也会带来较高的资源重复代价,在设定这些分布式层面的参数时,建议客户根据业务的实际需求来权衡可用性、可靠性以及资源成本来综合考量。
在VectorDB产品的管控层面,当发现有虚拟机节点宕机时,会自动创建出新的虚拟机来代替故障的虚拟机,然后通过莫愁内核的管控接口(不对客户暴露)执行内核系统的节点上下线机制,当内核系统收到新的节点上下线时,通过上述的机制自动化地完成副本再均衡。这一切操作对客户都是透明的,轻度异常情况下,基本不会影响客户的正常使用。
VectorDB产品的管控,会对每个数据库实例自动创建一个VIP,并将该集群所有的代理节点都绑定到该VIP。当用户通过该VIP访问数据库时,会自动通过负载均衡机制将用户的HTTP请求均匀分发给每一个代理节点。只要不是所有的代理节点都异常了,客户的访问一般不会受到影响。
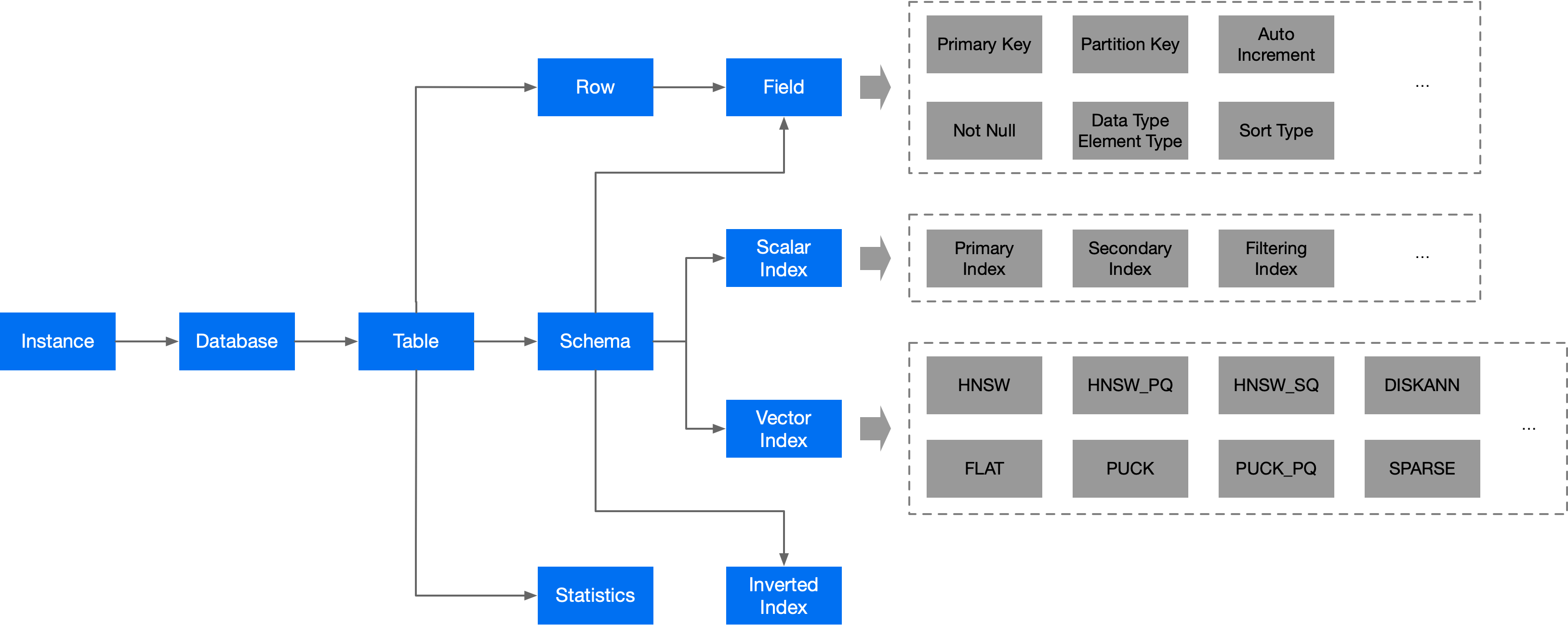
从逻辑层面来看,数据库的概念包括库、表、字段,除此之外还包含索引以及字段的各类属性等概念,我们先通过一张图来了解一下这些逻辑概念之间的关系:
下面对上述概念进行详细描述:
Instance(实例) Database(库) Table(表) Statisitics(统计) Schema(模式) Field(字段) Scalar Index(标量索引) Vector Index(向量索引) Inverted Index(倒排索引)
VectorDB当前已经支持的字段属性说明如下:
Primary Key(主键) Partition Key(分区键) Auto Increment(自增) Not Null(非空) Data Type(数据类型) 数据类型 。
Element Type(元素类型) Sort Type(排序类型)
VectorDB当前已经支持的标量索引类型说明如下:
Primary Index(主键索引) Secondary Index(二级索引) Filtering Index(过滤索引)
VectorDB当前已经支持和即将支持的向量索引类型说明如下:
FLAT HNSW HNSW_PQ HNSW_SQ Puck Puck_PQ DISKANN SPARSE
百度智能云针对VectorDB自研了高性能数据库引擎——朱雀,具备如下强大的能力:
⽀持常⻅标量类型数据、文本类型数据、稠密浮点向量、稀疏浮点向量和二进制向量。
⽀持Schema,⽀持多主键、⾃增主键、分区键、多向量字段,支持列族。
⽀持标量数据的⼆级索引,支持文本数据的倒排索引,⽀持各类丰富的稠密向量索引和稀疏向量索引,支持过滤索引。
⽀持标量数据的点查、扫描和带条件查询,⽀持稠密向量检索、稀疏向量检索和二进制向量检索,⽀持带任意标量过滤条件的向量检索。
⽀持关键词和全⽂检索,集成百度NLP中英文混合分词器。
⽀持基于上述各类检索模式的多路混合检索以及结果的融合排序。
⽀持标量数据和向量数据的增、删、改,⽀持批量处理。
基于LSM模型,支持行存、列存、行列混存。
支持压缩和透明加密。
支持快照及恢复。
支持引擎内再分片,支持自动化及细粒度向量索引构建调度。
支持SIMD指令集优化、CPU硬件优化和其它硬件优化等。
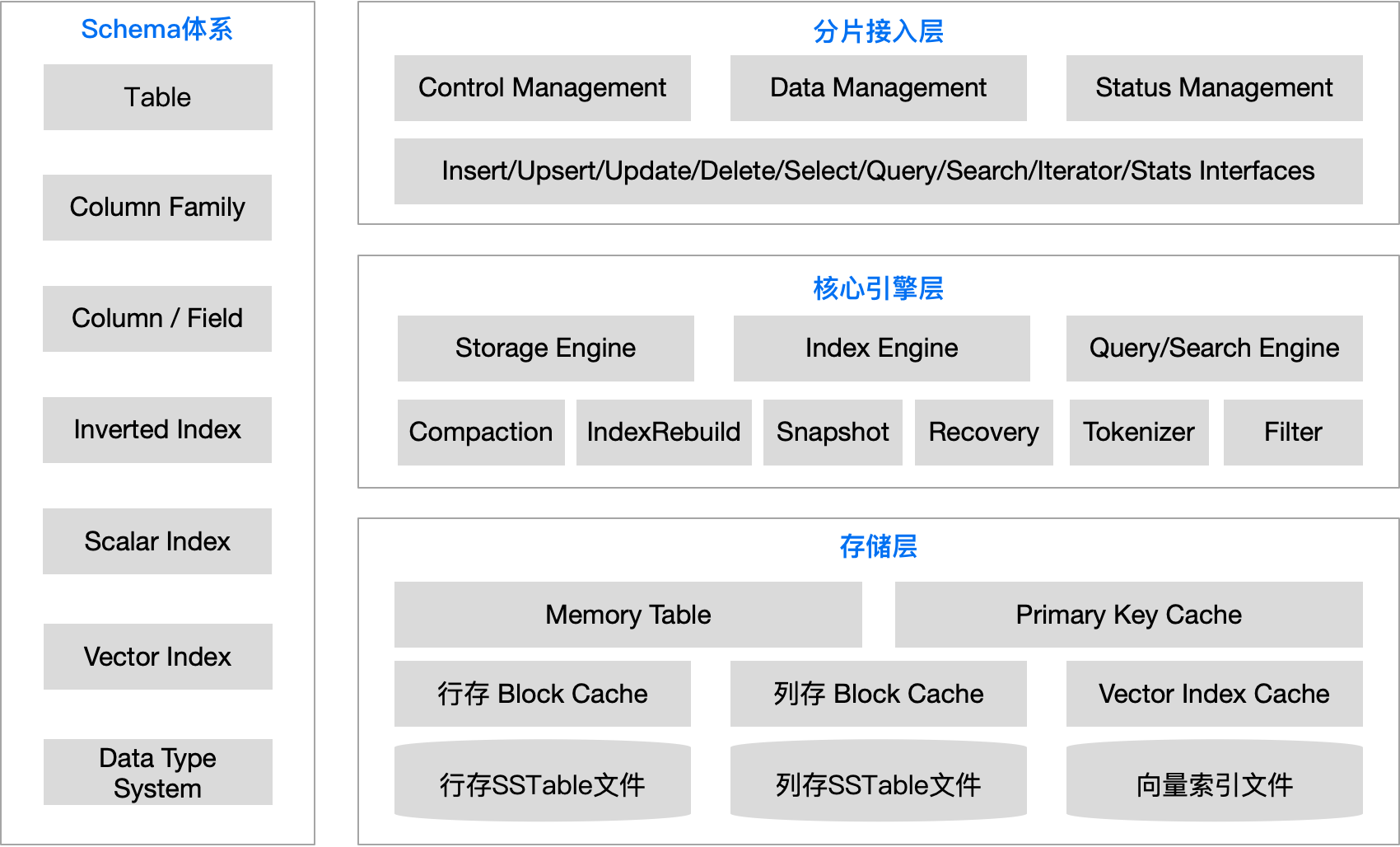
数据库引擎的逻辑架构如下图所示: