
实例资源规划
更新时间:2025-06-12
实例资源规划
1. CPU资源
根据性能白皮书,以Cohere百万768维数据为例,在Recall 99%的情况下,QPS为3784。此数据基于拥有3台4c8g 数据节点的向量数据库实例进行的测试。
单核QPS预估
Shell
1单核提供QPS能力 = 3784 / 12 ≈ 300CPU资源预估:
Shell
1预估CPU核数 = 预估QPS / 300注意:上述是经验公式,实际应用中建议通过压力测试来确定最佳CPU核数。
2. 内存资源
向量数据库内存构成
向量数据和向量索引均存储于数据节点,数据节点的内存构成包括预留缓存和向量索引存储空间。
缓存内存公式:
Shell
1缓存内存 = Min(5GB, 0.15 * 内存规格)向量索引内存管理:为处理索引重构,剩余内存应至少为当前索引所需内存的两倍。
HNSW向量索引内存预估:
公式:
Shell
1(1.1 * (4 * dims + 8 * M) * num of vectors) bytes- 其中,M是每个元素的双向链接数。建议取min(向量维度 * 1.5, 32)。
内存需求示例:
- 128维:M=16 -> 671.39MB,M=32 -> 805.67MB
- 768维:M=16 -> 3.279GB,M=32 -> 3.41GB
- 960维:M=16 -> 4.066GB,M=32 -> 4.197GB
PUCK向量索引内存预估:
公式:
Shell
1(1.2 * (4 * dims) * num of vectors) bytes内存需求示例:
- 128维:586M
- 960维:4.3G
3. 快速评估内存
单节点容纳能力预算:根据节点规格,估算单节点最大支持的向量数据量级。
示例:基于768维HNSW算法索引,M=32,单节点支持的最大向量数据量级:
| 数据节点内存规格 | 缓存 | 向量索引占用的最大内存 | 支持的最大向量数据量 |
|---|---|---|---|
| 4GB | 600MB | 3.4GB | 450,000 |
| 8GB | 1.2GB | 6.8GB | 900,000 |
| 16GB | 2.4GB | 13.6GB | 1,800,000 |
| 32GB | 4.8GB | 27.2GB | 3,600,000 |
| 64GB | 5GB | 59GB | 8,000,000 |
| 128GB | 5GB | 123GB | 16,500,000 |
| 256GB | 5GB | 251GB | 33,000,000 |
4. 节点规模试算
以1亿条768维向量,M=32,副本数为3,节点规格16核64G为例:
- 向量占用内存总量 = 341 GB
- 考虑副本,总内存需求: 341*3 = 1023 GB
- 64G节点(扣除缓存后可用于存储向量索引的内存为29.5GB),需要节点数 ≈ 35 台
5. 存储资源
存储容量计算方式:
Shell
1存储容量 = 源数据大小 * (1 + 数据膨胀 + 内部其他开销) * (1 + 预留空间)- 源数据大小 = 标量数据量 + 向量数据量
- 向量数据量 ≈ (4 dims) num of vectors * 4
- 通常数据膨胀率为120%-200%,系统需要额外的空间存储内置字段、标量索引、向量索引等,在这些额外的存储需求中,占比最大的通常是向量索引。
- 内部其他开销预留210%,用于系统合并segment,重建向量索引。
- 预留空间至少20%
- 最终需求容量 ≈ 源数据大小的6倍
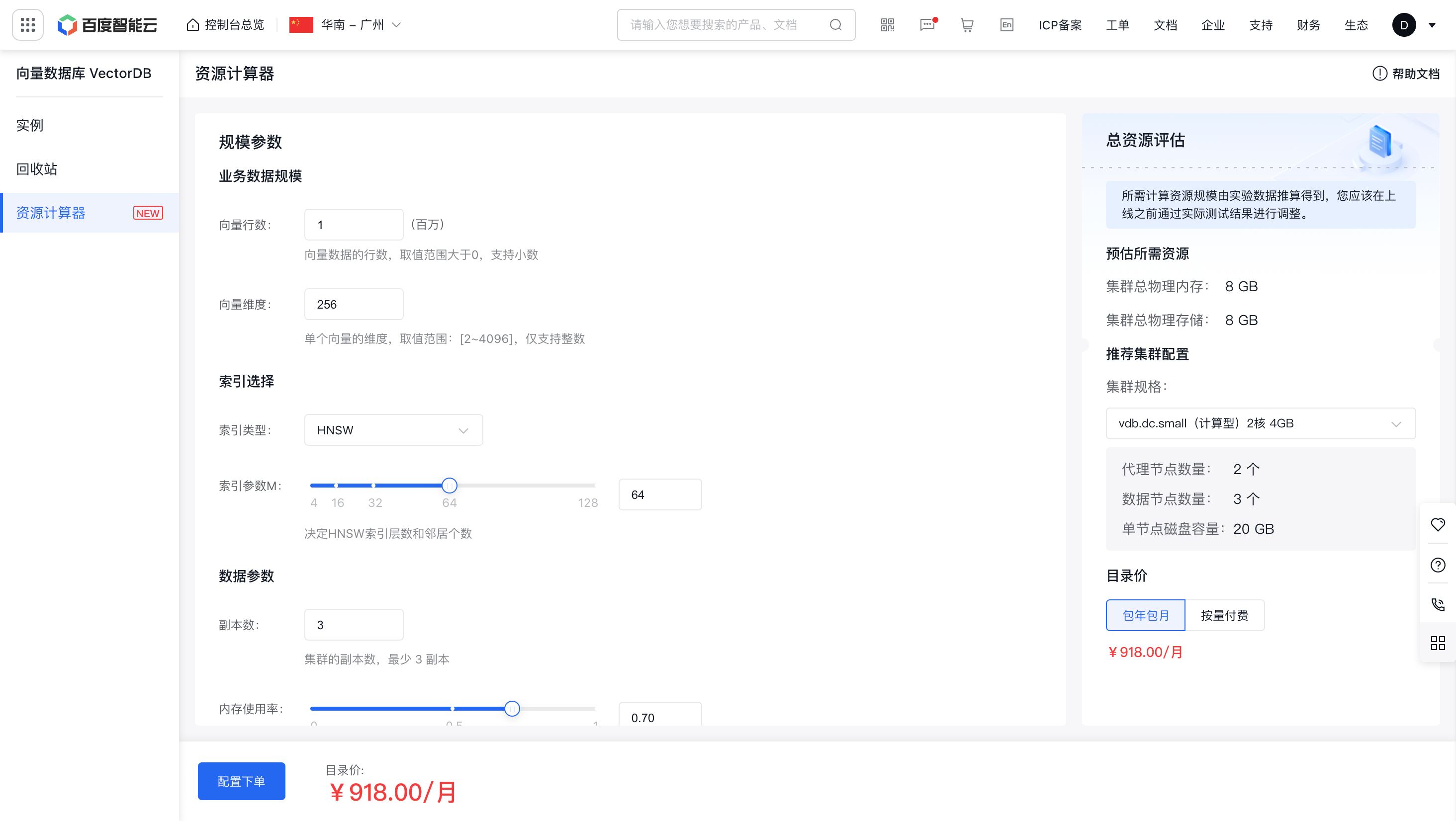
资源计算器
通过资源计算器,您可以快速根据业务的数据量评估出所需的资源,并根据总资源给出最适合的集群配置信息,方便用户购买下单。 使用地址:https://console.bce.baidu.com/vdb/#/vdb/resource/calculator
评价此篇文章