
Spark示例
更新时间:2025-01-23
前提条件
已完成创建 BMR 集群,并且配置了 Paimon、Spark 组件,详情请参见创建集群。
注意事项
- Paimon 的 JAR 文件已存放到 ${SPARK_HOME}/jars 目录;
- 默认使用 Hive Catalog;
- Hive 用户可以直接使用 Spark 创建的表;
- 启动 Spark 不需要添加 Paimon 相关参数。
操作示例
- SSH登录集群,参考SSH连接到集群;
- 执行以下命令查看结果:
Plain Text
1-- 用hive以外的用户时需要在ranger配置权限
2spark-sql --master local[2]
Plain Text
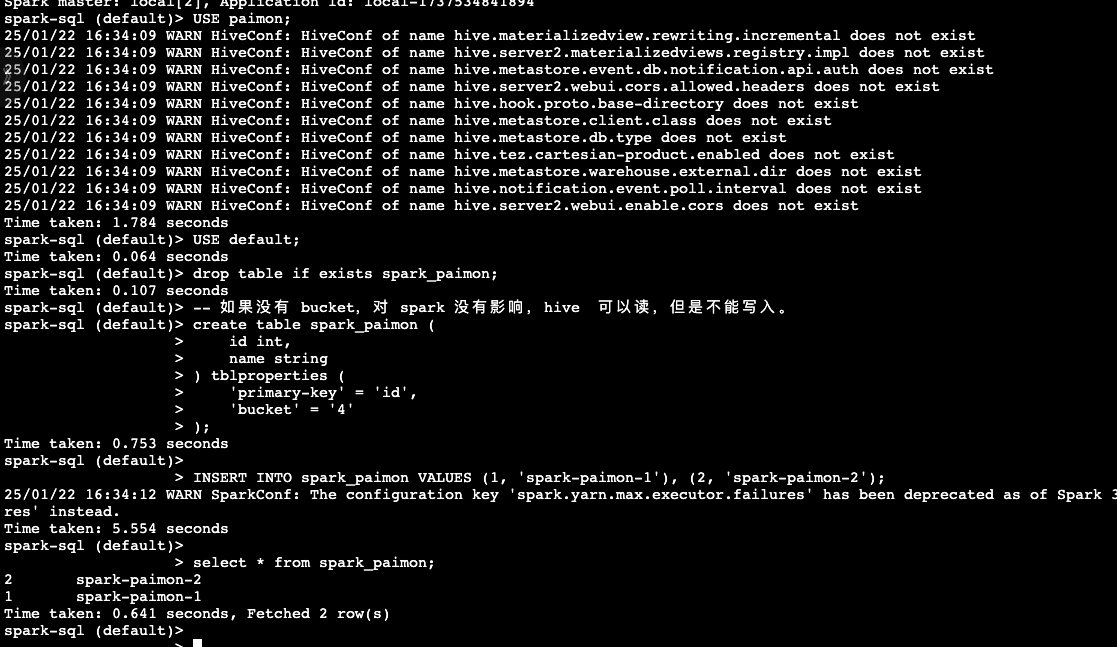
1USE paimon;
2USE default;
3drop table if exists spark_paimon;
4-- 如果没有 bucket,对 spark 没有影响,hive 可以读,但是不能写入。
5create table spark_paimon (
6 id int,
7 name string
8) tblproperties (
9 'primary-key' = 'id',
10 'bucket' = '4'
11);
12
13INSERT INTO spark_paimon VALUES (1, 'spark-paimon-1'), (2, 'spark-paimon-2');
14
15select * from spark_paimon;操作结果
评价此篇文章