
离线应用场景
概览
离线数据分析适用于数据规模大、处理实时性要求不高的场景,例如用户行为分析、用户留存分析、报表统计等等。基于百度智能云大数据平台,用户可以便捷地实现离线数据分析,包括数据的采集、数据清洗、数据仓库以及商业智能展现。
需求场景
大数据离线分析场景
通常是指对海量数据进分析和处理,形成结果数据,供下一步数据应用使用。离线处理对处理时间要求不高,但是所处理数据量较大,占用计算存储资源较多,通常通过MR或者Spark作业或者SQL作业实现。离线分析系统架构中以HDFS分布式存储软件为数据底座,计算引擎以基于MapReduce的Hive和基于Spark的SparkSQL为主。
方案概述
具体而言,可以通过使用BLS(百度LogService)、BOS(百度对象存储)、BMR(MapReduce)、Palo(百度OLAP引擎)这些产品实现上述场景。我们以常见的用户访问日志分析场景作为示例,离线处理架构图如下图所示:
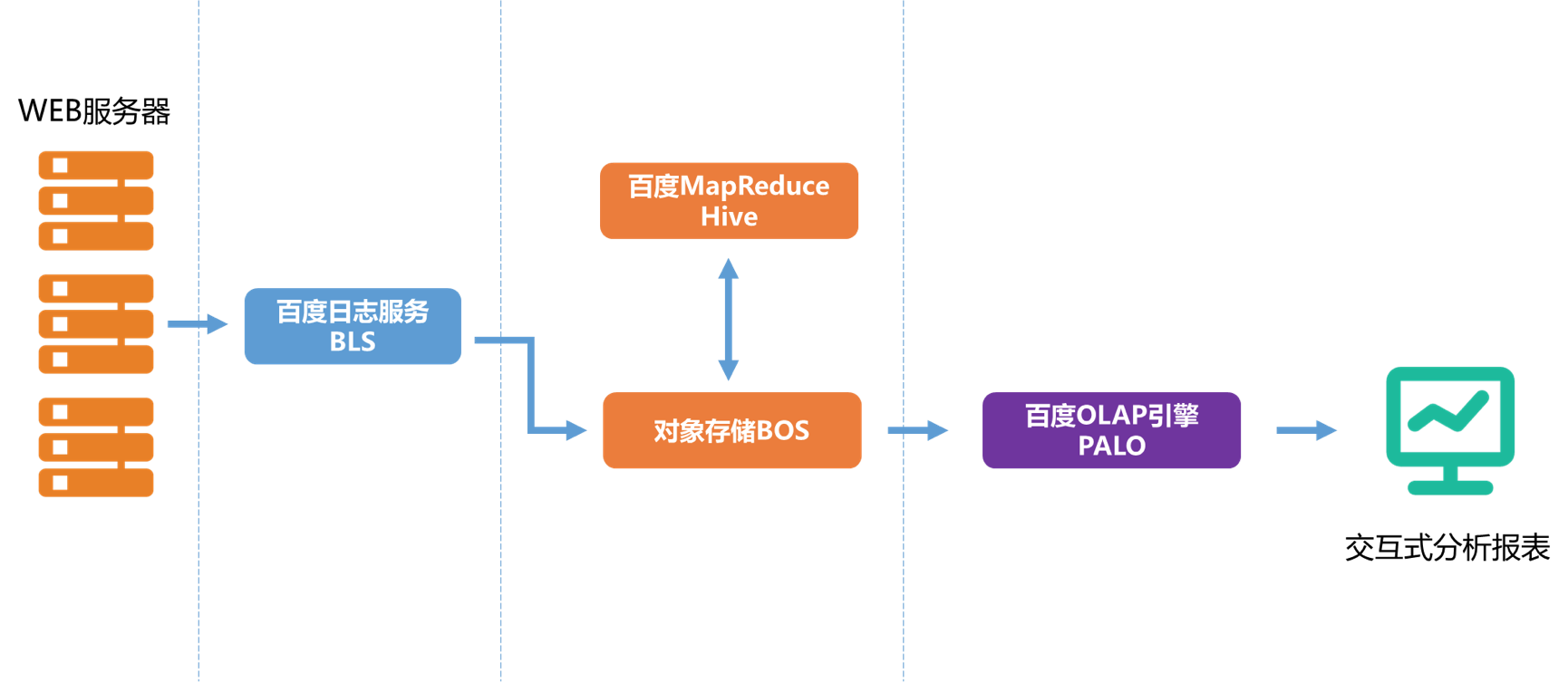
首先,用户访问日志保存在WEB服务器的文件系统,通过在BLS服务创建传输任务,把相关服务器上的日志收集到BOS进行存储;然后使用BMR集群运行Hive作业对日志数据进行清洗和处理,输出的目标数据仍保存在BOS;最后,把目标数据从BOS导入到OLAP引擎Palo中,即可进行多维分析。百度智能云Palo还支持对接兼容JDBC接口的可视化分析应用,更加直观、便捷地展示数据分析结果。
数据采集
通过BLS服务采集日志
参考文档
使用BLS服务首先需要在目标机器上安装收集器,收集器负责从BLS服务接收传输任务,并把日志数据从本地磁盘上传到BOS指定目录。
在本案例中,我们的Web服务器上运行了nginx进程,并且把nginx日志生成路径配置在/var/log/nginx/下,日志文件的格式为access.log.yyyyMMdd,根据日期进行轮转,每天生成一个新的日志文件,比如2017年3月20号的日志将都保存在文件access.log.20170320中。为了将这些日志文件收集到BOS保存,我们在BLS服务创建一个新的传输任务,具体配置信息如下图所示。源端类型为“目录”,将“源日志目录”配置为nginx日志所在目录:/var/log/nginx,“匹配文件规则”配置为日志文件的正则表达式:^access.log.[0-9]{8}$。
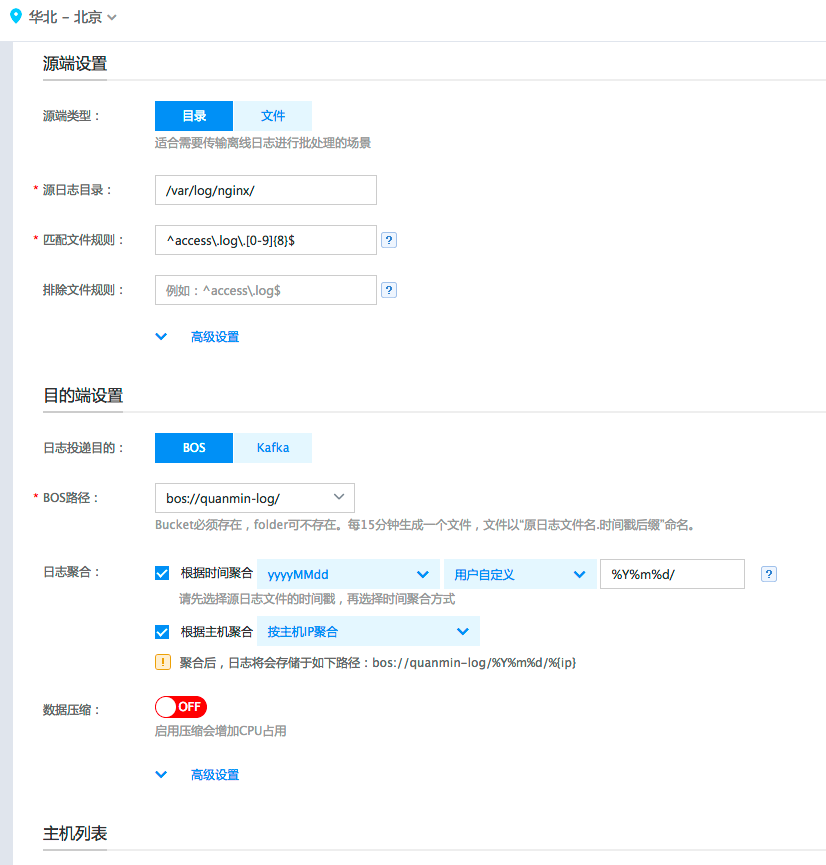
目的端设置中,选择“日志投递目的”为“BOS”,并且通过下拉选框选择BOS上目的路径为“bos://quanmin-log/"。另外,我们可以根据日志聚合的需要,在BOS端重新组织日志数据的目录结构。在本案例中,我们勾选“根据时间聚合”,注意选择源日志文件的时间戳为yyyyMMdd,这是跟我们服务器上日志文件名中的时间戳正则匹配的,BLS收集器将根据这个正则去匹配日志文件名,从而得到改日志文件对应的时间数据。然后,我们选择“用户自定义”,这里是配置具体的聚合路径,我们填入配置“%Y%m%d”,也就是把BOS目的端路径配置为bos://nginx-logs/%Y%m%d/。由于Web服务器有多台,我们需要把日志来源的服务器也在日志保存路径中体现出来,因此勾选“根据主机聚合”,并选择按主机ip聚合。最终,在BOS上保存的日志数据的路径将符合bos://quanmin-log/%Y%m%d/%{ip}的格式。
数据清洗
创建BMR集群,运行定时任务
配置好BLS传输任务后,预期每天的日志都将传输到指定的BOS目录。nginx日志包含字段较多,我们需要进行选择并转换字段来得到符合需求的数据。这一步我们可以使用BMR定时任务功能,每天定期运行Hive作业,对导入BOS的日志数据进行用户活跃留存统计。
在本案例中,具体操作步骤如下:
-
创建集群模板,操作入口是BMR产品控制台左侧导航栏“集群模板”-页面中部主体“创建模板”按钮:
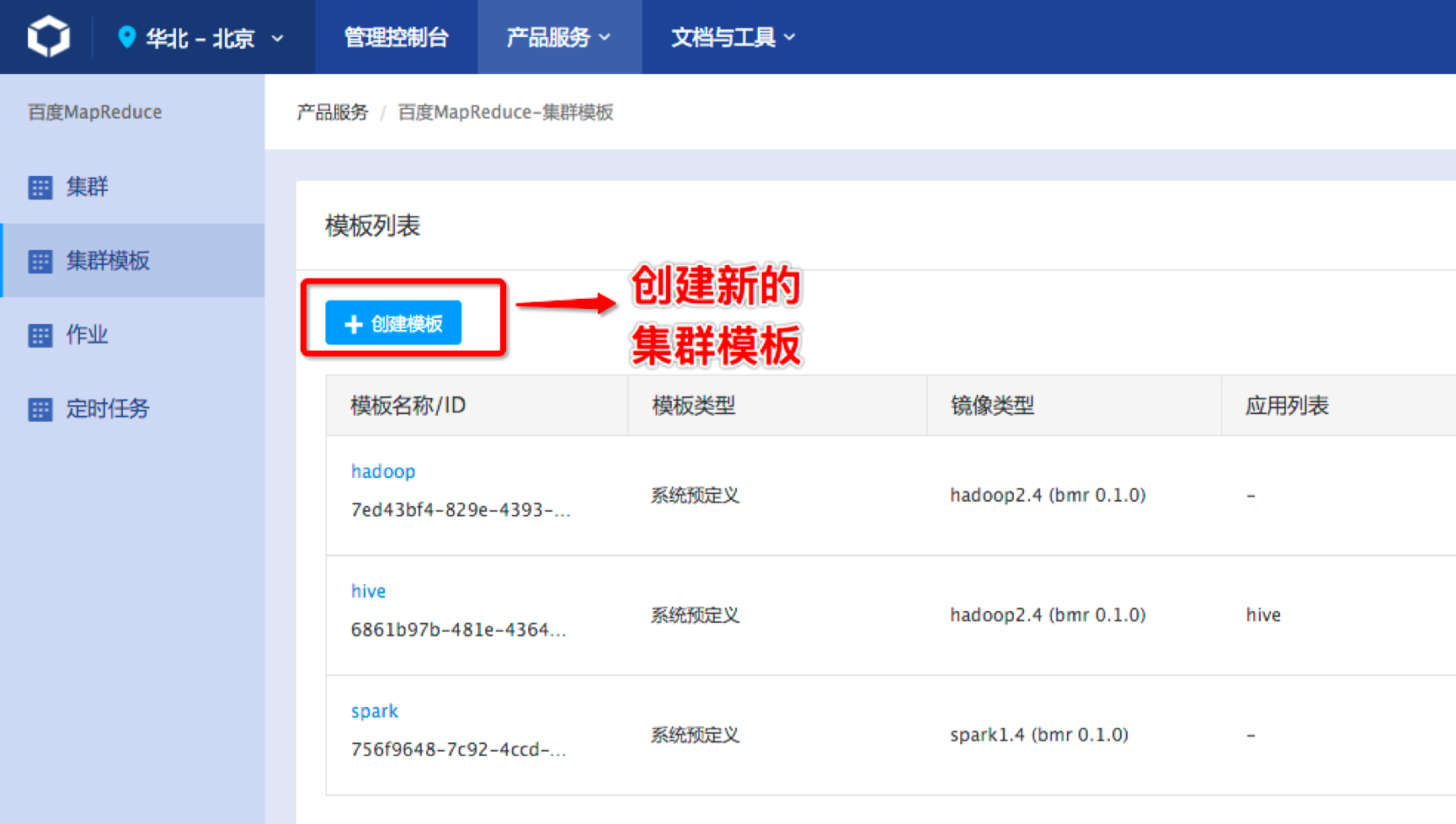
创建模块的参数填写需要注意两点:
- 启动“自动终止”,该选项说明在定时任务完成后自动释放集群,停止计费。如果不启动,则定时任务执行过程创建出的集群将一直保持活跃状态,计入产品费用:
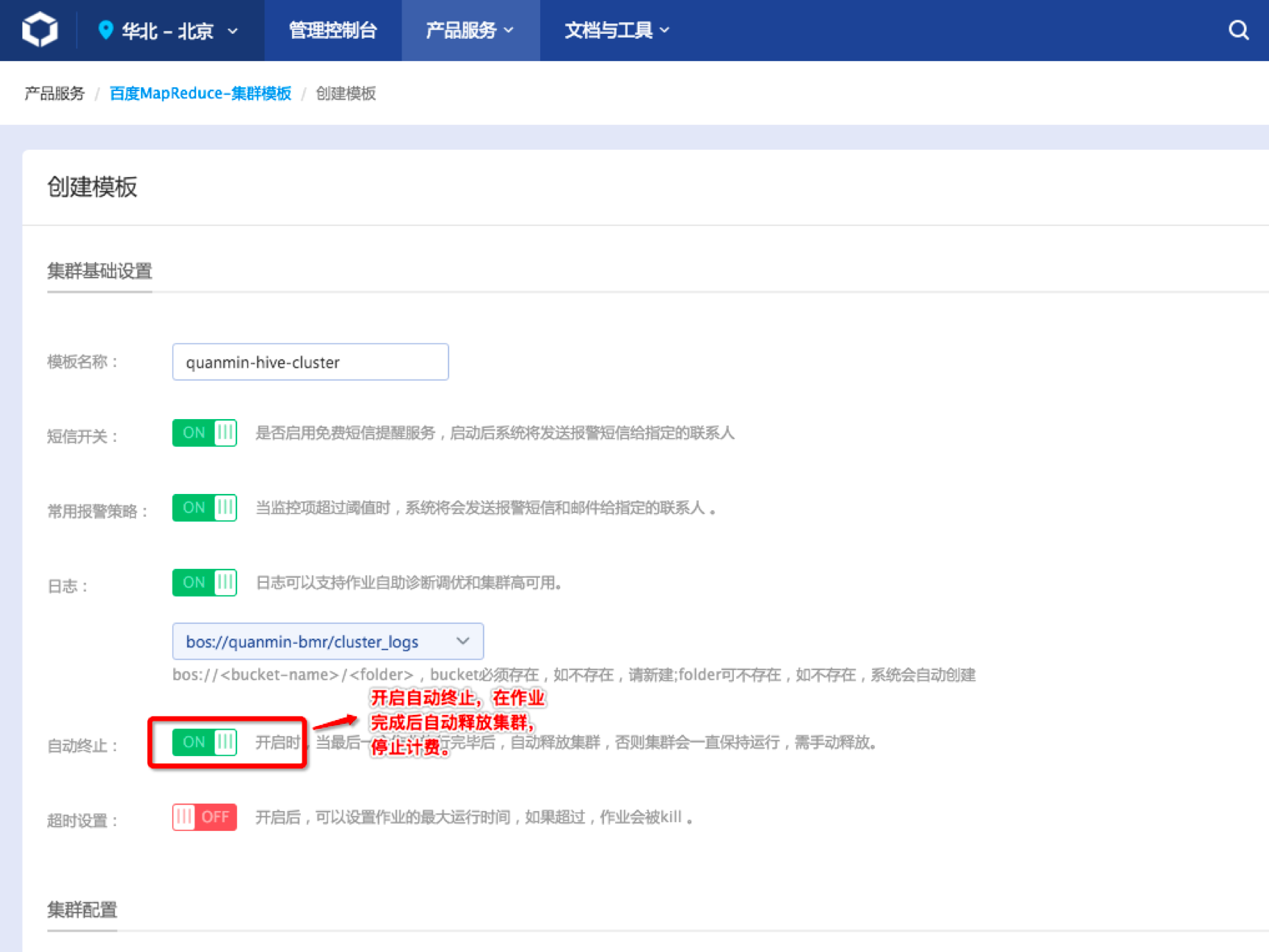
- 注意添加hive应用,否则集群将不能运行hive作业:
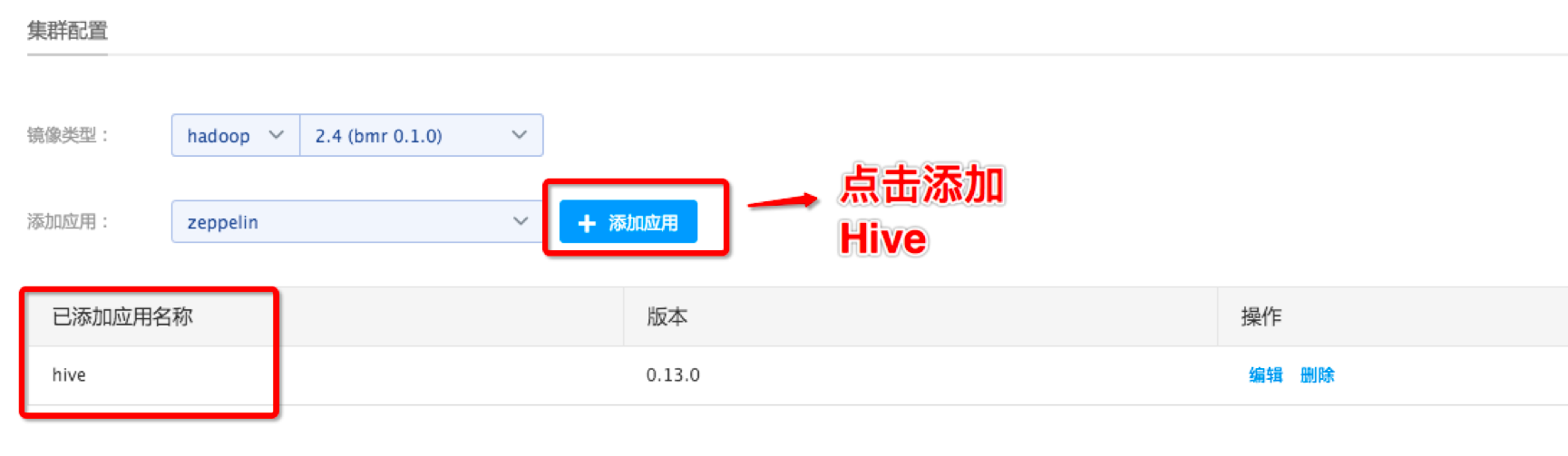
集群节点配置是根据具体作业任务的规模来配置的,如果不了解实际规模可以先保持默认节点配置,后续根据作业运行耗时情况来重新配置。
-
创建定时任务,操作入口是BMR产品控制台左侧导航栏“定时任务”-页面中部主体“创建任务”按钮:
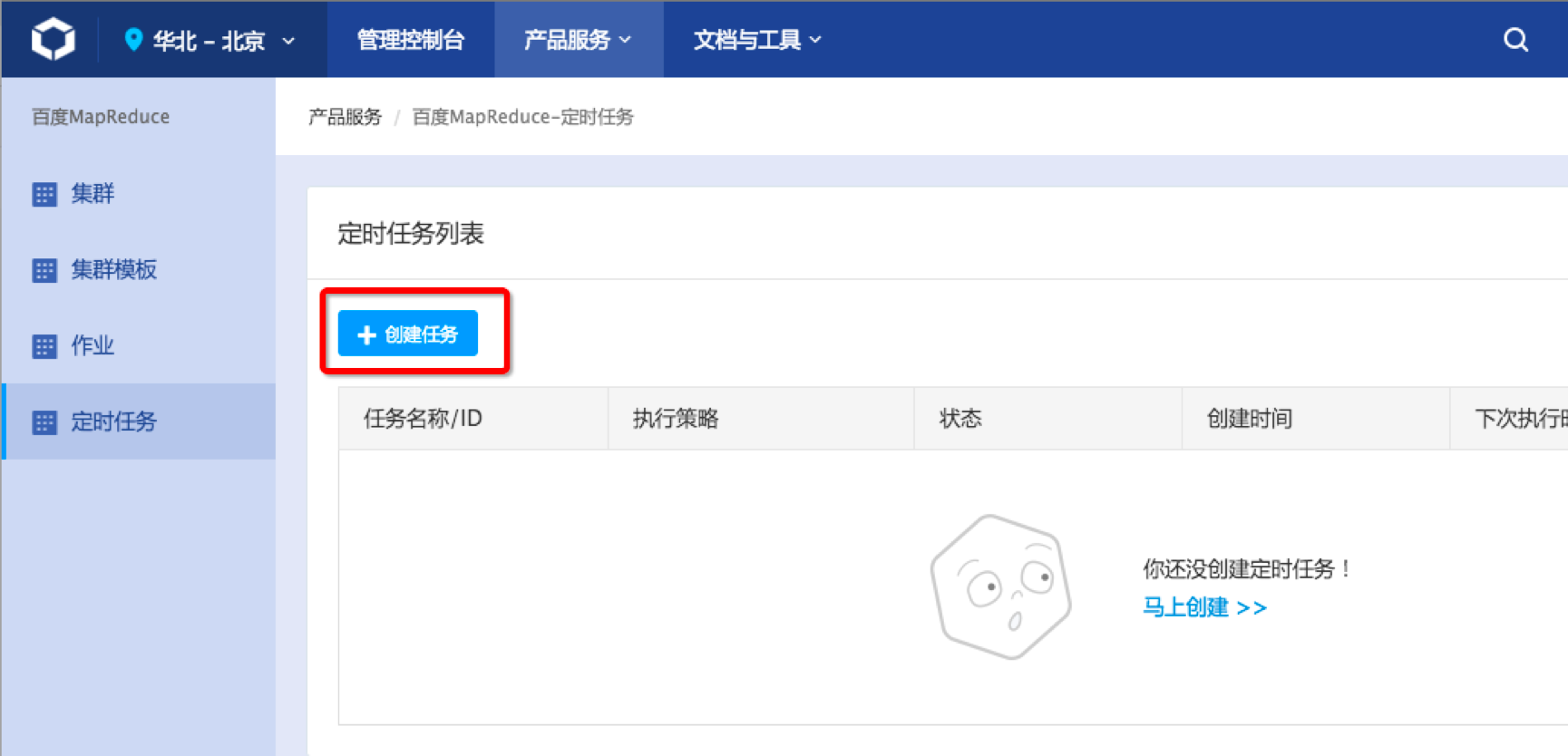
配置定时任务主要是选择集群模板、执行策略以及作业。集群模板需要选择刚才创建的集群模板。执行策略可以根据实际业务需要进行选择。这里以每天运行数据分析举例,配置执行频率是每1天。任务开始时间为立即开始(如果需要第二天一早看到数据结果,可以把开始时间定为凌晨某个时间点)。

-
添加Hive作业到定时任务中。我们编写的Hive作业将对原始日志数据进行如下处理:
1)对空值附以对业务无意义的数值。
由于Palo不支持空值字段,需要对日志中的空值字段做一定处理,目前均处理为0。
2)将IP信息转化为地址位置信息。
通过IP-GEO库与UDF把IP信息转化为地理位置信息,精确到市一级,同时提供经纬度信息便于在可视化工具中做地图报表。
3)将时间字段打散为多个字段。
为方便下载查询,将日志中的时间字段打散为年、月、日、时、分等五个字段。同时为了在Palo中声明为date类型从而加快查询速度,且不丢失字段本身的含义,年、月字段需满足yyyy-mm-dd格式的合法值,故年字段统一为当年第一天,月字段统一为当月第一天,例如2016年表示为2016-01-01,2016年7月表示为2016-07-01。
4)统计用户次日留存情况。
次日留存定义为当天的所有访问IP中在前一天也访问过的IP子集,也就是一个客户端IP在某天及其前一天都出现在nginx访问日志中,则可认为该IP是一个次日留存客户。
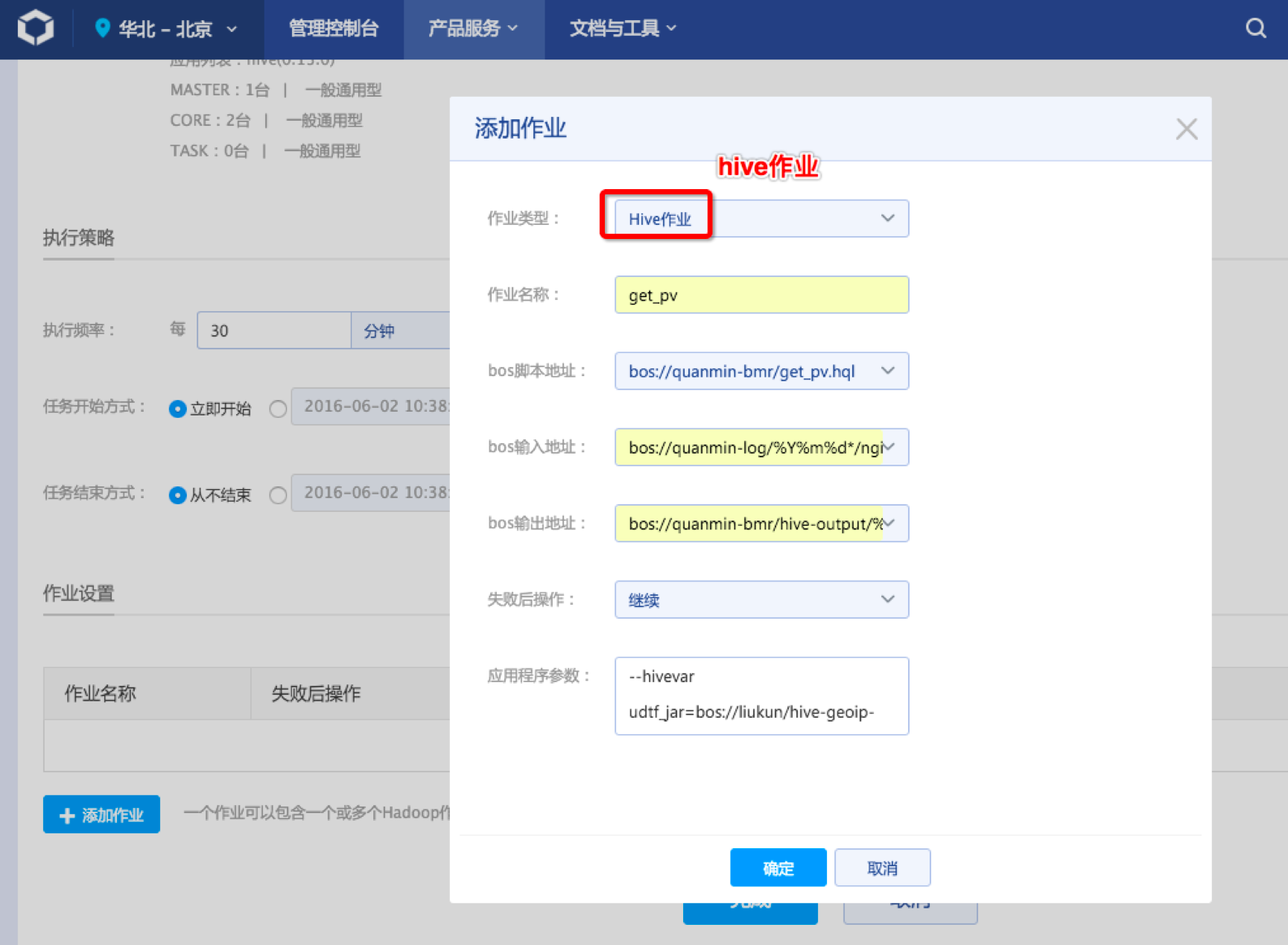
点击“确定”。样例定时任务就只有一个Hive作业,因此可以点击“完成”提交定时任务。
标准创建定时任务的步骤请参考文档;
标准的Hive作业样例请参考文档。
报表展现
Palo建表与数据导入
BMR运行hive作业处理过后的数据保存在BOS上,本案例中,上面定时任务运行hive作业,配置的BOS输出地址是bos://quanmin-bmr/hive-output/%Y%m%d/access_pv/,其中“%Y%m%d”将根据任务实际执行日期替换为数字,比如20160601。为了把BMR清洗好的数据导入Palo,我们首先需要在Palo预先建立好数据库表。首先,在Palo服务创建一个新集群。
集群创建好以后, Palo提供兼容MySQL的接口,可以直接使用MySQL的相关库或者工具进行连接Palo集群(目前Palo只支持MySQL 5.0以上的客户端,在连接之前请确认您的客户端版本)。以MySQL Workbench为例:
-
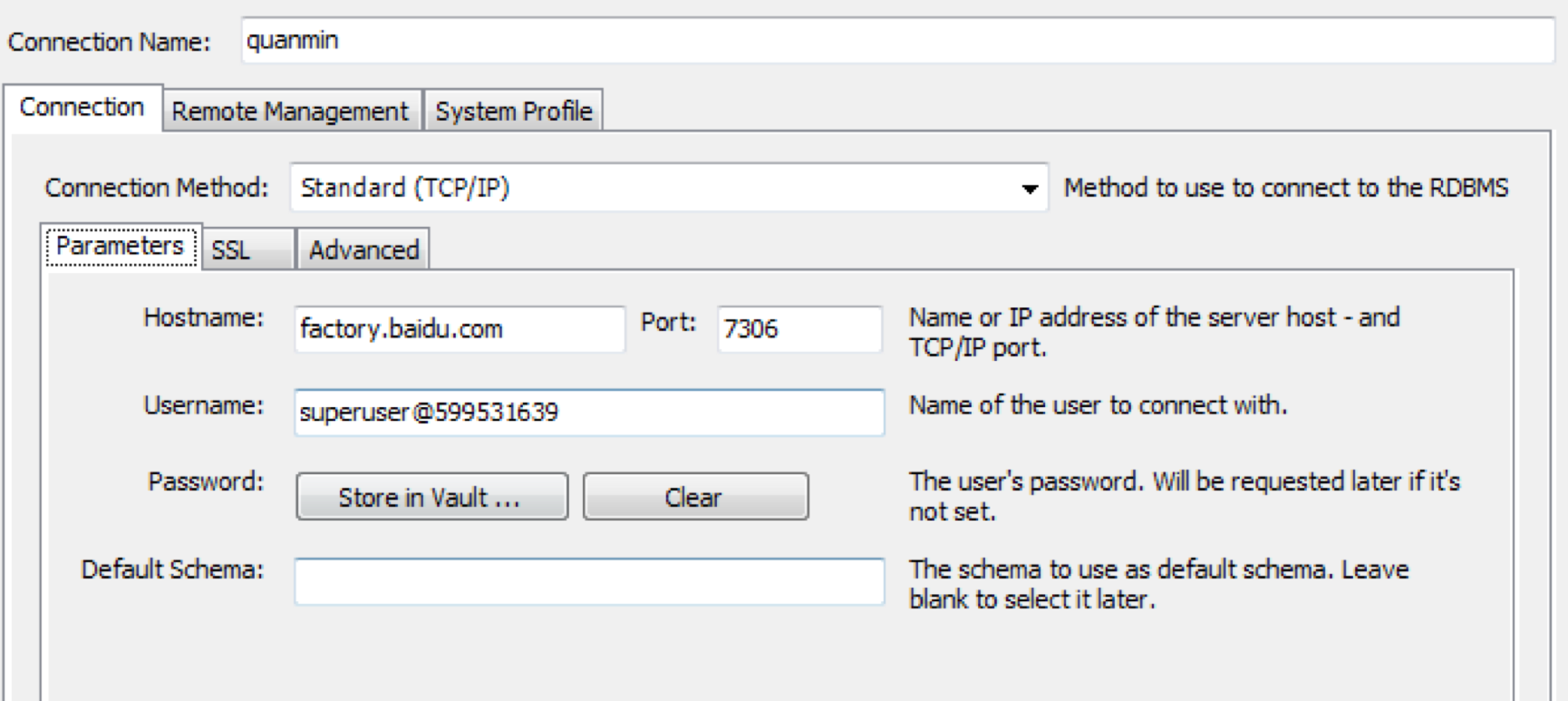
连接Palo集群。使用的配置信息均可以在Palo集群的详情页面查看到:
- hostname:factory.baidu.com
- port:7036
- username:superuser@cluster_id,实例中cluster_id为599531639
-
建立数据库。
Plain Text1CREATE DATABASE QUANMIN; -
建立数据表。目前需要建两张表,一张是包含所有数据和字段的明细表(detail table),一张是次日留存表(retain_day table,当前页包含了所有字段)。这里我们给出datail表的建表语句:
Plain Text1CREATE TABLE detail 2( 3platform int, 4action varchar(100), 5v1 varchar(100), 6v2 varchar(100), 7year date, 8month date, 9day date, 10hour datetime, 11minute datetime, 12time datetime, 13user_id int, 14device varchar(50), 15ip varchar(20), 16server_ip varchar(20), 17province_name varchar(50), 18city_name varchar(50), 19longitude varchar(20), 20latitude varchar(20), 21pv int sum 22) 23engine = olap 24partition by range(time) ( 25PARTITION p1 VALUES LESS THAN ("2016-08-01 00:00:00"), 26PARTITION p2 VALUES LESS THAN ("2016-10-01 00:00:00") 27) 28distributed by hash(platform) -
最后进行BOS数据导入,在MySQL Workbench继续执行语句:
Plain Text1load label detail1 ( 2data infile("bos://quanmin-bmr/hive-output/2016-07-30/*") into table 3`detail` columns terminated by "," (platform, action, v1, v2, user_id, device, time, year, month, day, hour,minute, ip, server_ip, province_name, city_name,longitude, latitude, pv) 4) 5PROPERTIES( 6"bos_accesskey" ="your_ak", 7"bos_secret_accesskey" = "your_sk", 8"bos_endpoint"= "http://bj.bcebos.com" 9); - 使用主流的BI/可视化工具进行数据分析与展现。Palo支持JDBC接口连接访问,因此对于兼容JDBC接口的BI/可视化工具都能连接Palo集群,对我们导入的数据进行可视化分析。
注意:
- 每次成功导入后,下次需要使用不同的导入label,导入语句中的your_ak、your_sk需要替换为实际的ak、sk。百度智能云使用ak、sk验证用户身份,请妥善保管。
- 导入过程中,可以通过 “SHOW LOAD;” 命令查看load过程。
- 导入成功后,即可通过MySQL客户端和BI/可视化工具进行查询分析。
相关产品
评价此篇文章