
基础使用
简介
Apache Flink 是一个开源的框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。它能够处理实时数据流和批处理数据,具有高吞吐量、低延迟和容错性强的特点。Flink 能在所有常见的集群环境中运行,并能以内存速度和任意规模进行计算。
常见应用场景:
- 事件驱动型应用:
- 反欺诈:实时检测异常交易行为。
- 异常检测:监控系统状态,实时发现异常。
- 数据分析应用:
- 流数据分析:实时分析数据流,提取有价值的信息。
- 实时报表分析:实时生成报表,展示关键指标的变化。
- 数据管道与ETL:
- 实时ETL:Flink 提供丰富的Connector,支持多种数据源和数据Sink,能够实时处理数据管道。
- 实时数仓:支持分钟级或秒级的数据更新,便于实时查询和分析。
作业提交
- 登录百度智能云控制台,选择“产品>MapReduce BMR”,单击“创建集群”,进入集群创建页,可选服务中勾选 Flink 服务。
注意:BMR2.1.1及以上版本支持 Flink。不同BMR版本对应支持的Flink组件版本也不同,具体支持版本以选择BMR版本后可选服务中组件版本为准。
- SSH登录集群 ,参考SSH连接到集群。
- 执行以下命令,上传文件至HDFS,本示例以 Flink 作业示例 WordCount 为例:
1hdfs dfs -put /etc/hadoop/conf/core-site.xml /tmp- 执行以下命令,提交作业:
1flink run --jobmanager yarn-cluster \
2-yn 1 \
3-ytm 1024 \
4-yjm 1024 \
5/opt/bmr/flink/examples/batch/WordCount.jar \
6--input hdfs://$ACTIVE_NAMENODE_HOSTNAME:$PORT/tmp/core-site.xml \
7--output hdfs://$ACTIVE_NAMENODE_HOSTNAME:$PORT/tmp/out- 结果查看
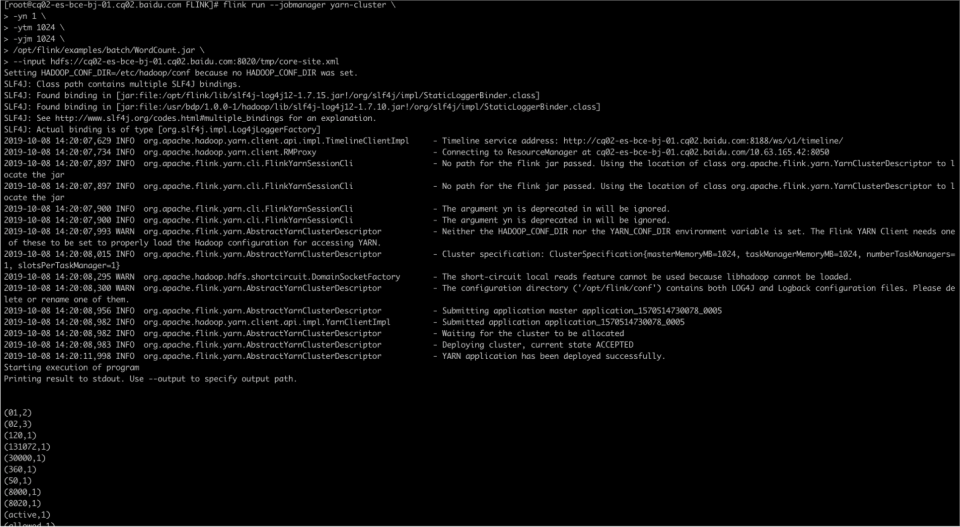
查看作业状态
- 登录百度云控制台,进入 BMR 集群列表,单击集群名称/ID>>集群详情>>相关应用和工具>>Hadoop Yarn Web UI,进入 Web UI。
- 单击 Flink 任务的 Application ID。
- 进入详情页面后,单击 Tracking URL 的链接。
- 进入 Apache Flink Dashboard 页面,即可查看作业的状态。
使用示例
通过BMR的Flink消费百度消息服务BMS。本文以使用Scala为例,Flink版本1.8.2,线上Kafka版本2.1。具体步骤如下:
第一步 创建Topic并下载百度消息服务的证书
(本步骤详情请参考文档 Spark流式应用场景)
下载证书:
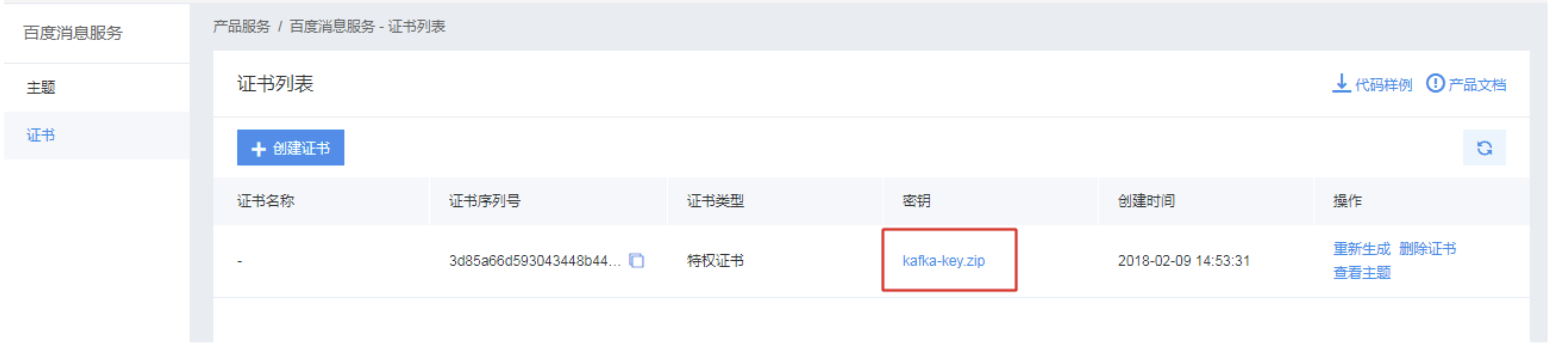
第二步 编写业务代码
1package com.baidu.inf.flink
2
3import java.util.Properties
4
5import org.apache.flink.api.common.serialization.SimpleStringSchema
6import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
7import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
8import org.apache.kafka.common.serialization.StringDeserializer
9import org.slf4j.LoggerFactory
10
11object CloudFlinkConsumeKafkaDemo {
12 private val logger = LoggerFactory.getLogger(this.getClass)
13
14 def main(args: Array[String]): Unit = {
15 logger.info("************ Flink Consume Kafka Demo start **************")
16 if (args.length < 7) {
17 logger.error(" Parameters Are Missing , " +
18 "Needs : <topic> " +
19 "<groupId> " +
20 "<brokerHosts> " +
21 "<truststore_location> " +
22 "<truststore_pass> " +
23 "<keystore_location> " +
24 "<keystore_pass>")
25 System.exit(-1)
26 }
27 val Array(topic, groupId, brokerHosts,
28 truststore_location, truststore_pass,
29 keystore_location, keystore_pass, _*) = args
30
31 val env = StreamExecutionEnvironment.getExecutionEnvironment
32 env.setParallelism(2)
33 env.getConfig.disableSysoutLogging
34
35 val kafkaProperties = new Properties()
36 kafkaProperties.setProperty("bootstrap.servers", brokerHosts)
37 kafkaProperties.setProperty("key.deserializer", classOf[StringDeserializer].getName)
38 kafkaProperties.setProperty("value.deserializer", classOf[StringDeserializer].getName)
39 kafkaProperties.setProperty("group.id", groupId)
40 kafkaProperties.setProperty("auto.offset.reset", "latest")
41 kafkaProperties.setProperty("serializer.class", "kafka.serializer.StringEncoder")
42 kafkaProperties.setProperty("security.protocol", "SSL")
43 kafkaProperties.setProperty("ssl.truststore.location", truststore_location)
44 kafkaProperties.setProperty("ssl.truststore.password", truststore_pass)
45 kafkaProperties.setProperty("ssl.keystore.location", keystore_location)
46 kafkaProperties.setProperty("ssl.keystore.password", keystore_pass)
47 kafkaProperties.setProperty("enable.auto.commit", "true")
48
49 val ds = env.addSource(
50 new FlinkKafkaConsumer[String](topic,
51 new SimpleStringSchema(),
52 kafkaProperties))
53
54 ds.print()
55 env.execute()
56 }
57}第三步 编译代码,打成可执行Jar文件,上传到服务器上
(注:要保证第一步下载的证书文件在集群每个节点上相同的路径下都存在)
运行作业示例:
flink run --jobmanager yarn-cluster -yn 1 -ytm 1024 -yjm 1024 /root/flink-streaming-1.0-SNAPSHOT-jar-with-dependencies.jar "676c4bb9b72c49c7bd3b089c181af9ec__demo02" "group1" "kafka.fsh.baidubce.com:9091" "/tmp/client.truststore.jks" "kafka" "/tmp/client.keystore.jks" "0yw0ckrt"
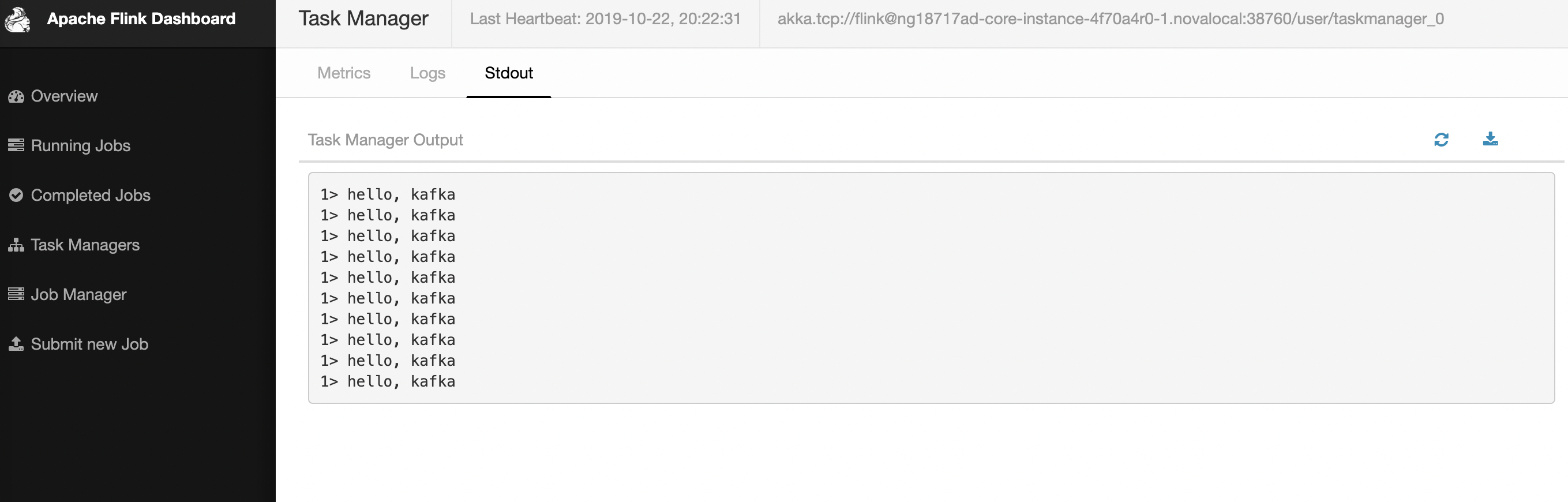
第四步 消息队列中生产一些消息,在Flink作业监控页面上查看对应输出
通过Tunnel登录到集群的Yarn页面上(通过SSH-Tunnel访问集群)
在yarn console找到对应作业的application的单击application名称,进入作业详情页面:
(在Flink的原生页面上,点击TaskManagers > Stdout,查看作业运行情况)
评价此篇文章