
HBase
HBase简介
本文以分析Web日志统计每天的PV和UV为例,介绍如何在百度智能云平台使用HBase。
HBase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,能够利用HDFS的分布式处理模式和Hadoop的MapReduce程序模型。HBase融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理的能力。总的来说,HBase能够让您在大量的数据中查询记录,也可获得综合分析报告。
HBase不是一个关系型数据库,需要不同的方法定义数据模型,HBase定义了一个四维数据模型:行键、列簇、列修饰符以及版本,以便获取指定数据:
- 行键:每行都有唯一的行键,行键没有数据类型,它内部被认为是一个字节数组。
- 列簇:数据在行中被组织成列簇,每行有相同的列簇,但是在行之间,相同的列簇不需要有相同的列修饰符。在引擎中,HBase将列簇存储在自身的数据文件中,因此,列簇需要事先被定义。
- 列修饰符:列簇定义真实的列,被称之为列修饰符,可认为列修饰符就是列本身。
- 版本:每列都可以有一个可配置的版本数量,可通过列修饰符的制定版本获取数据。
程序准备
您可以直接使用样例程序。也可设计自己的程序,并上传到对象存储BOS(具体操作详见对象存储BOS入门指南)。
集群准备
- 准备数据,请参考数据准备。
- 准备百度智能云环境。
-
登录控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,并做如下配置:
- 设置集群名称
- 设置管理员密码
- 打开日志开关
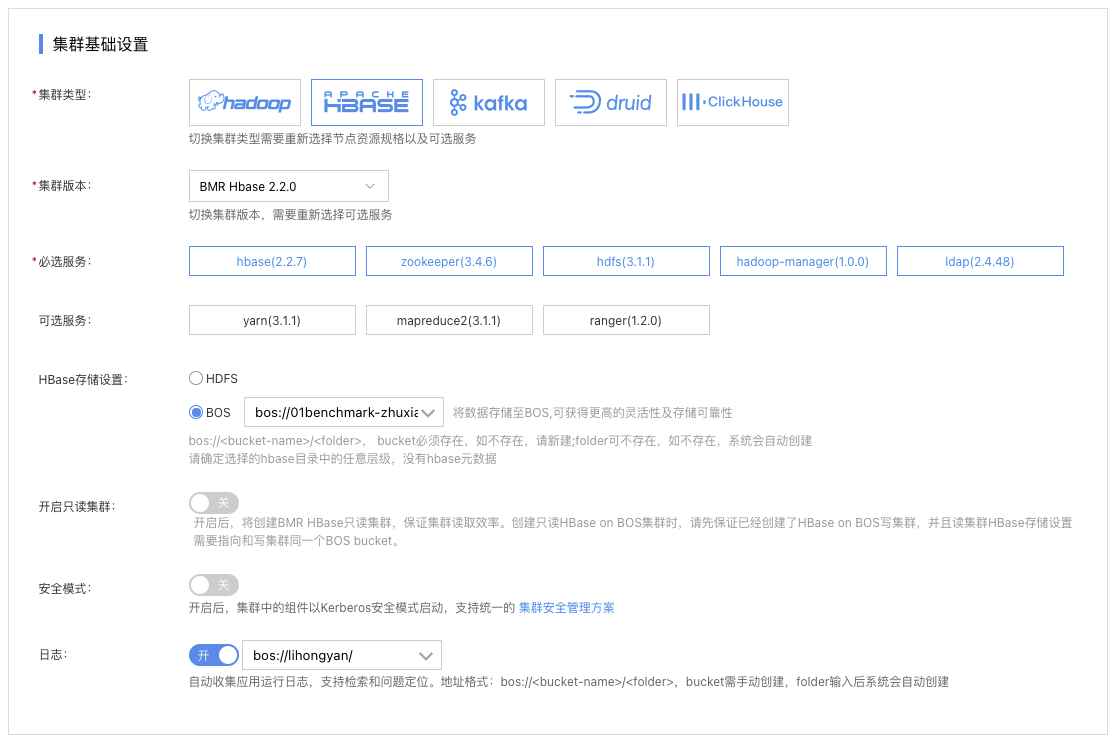
- 选择集群类型HBASE”
- 选择集群版本 BMR Hbase 2.2.0”。
- 请保持集群的其他默认配置不变,点击“完成”可在集群列表页可查看已创建的集群,当集群状态由“初始化中”变为“运行中”时,集群创建成功。
说明:Hbase集群支持在创建集群时将HBase存储设置设置为BOS,可以获得更高的数据可靠性。
bos:<bucket-name>/<folder>, bucket必须存在,如不存在,请新建;folder可不存在,如不存在,系统会自动创建;请确定选择的hbase目录中的任意层级,没有hbase元数据。集群创建后续无法修改该路径及切换为HDFS存储。请合理选择您的存储方式。具体设置方式,如下图所示。
运行Java作业
提取Web访问日志内容到HBase Table
- 在“产品服务>MapReduce>MapReduce-作业列表”页中,点击“创建作业”,进入创建作业页。
-
配置Java作业参数,具体如下:
- 作业类型:选择“Java作业”。
- 作业名称:输入作业名称,长度不可超过255个字符。
- 应用程序位置:可输入样例程序路径
bos://bmr-public-data/apps/hbase/bmr-hbase-samples-1.0-SNAPSHOT.jar。 - 失败后操作:继续。
- MainClass:输入
com.baidubce.bmr.hbase.samples.logextract.AccessLogExtract。 - 应用程序参数:输入
-D mapreduce.job.maps=6 -D mapreduce.job.reduces=2 bos://bmr-public-data/logs/accesslog-1k.log AccessTable。(最后一个参数"AccessTable",是HBase Table的名称。)
- 在“集群适配”区,选择适配的集群。
- 点击“完成”,则作业创建完成。运行中的作业状态会由“等待中”更新为“运行中”,当作业运行完毕后状态会更新为“已完成”。
统计每天的PV
- 在“产品服务>MapReduce>MapReduce-作业列表”页中,点击“创建作业”,进入创建作业页。
-
配置Java作业参数,具体如下:
- 作业类型:选择“Java作业”。
- 作业名称:输入作业名称,长度不可超过255个字符。
- 应用程序位置:可输入样例程序路径
bos://bmr-public-data/apps/hbase/bmr-hbase-samples-1.0-SNAPSHOT.jar。 - 失败后操作:继续。
- MainClass:输入
com.baidubce.bmr.hbase.samples.pv.PageView。 - 应用程序参数:输入
-D mapreduce.job.maps=6 -D mapreduce.job.reduces=2 AccessTable bos://${USER_BUCKET}/pv。bos://${USER_BUCKET}/pv必须具有写权限且该路径中所指定的目录不能在bos上存在,例如,输出路径为bos://test/sqooptest,则sqooptest目录在bos上必须不存在。
- 在“集群适配”区,选择适配的集群。
- 点击“完成”,则作业创建完成。当作业状态会由“等待中”更新为“运行中”状态,作业运行完毕后状态更新为“已完成”。
统计每天的UV
- 在“产品服务>MapReduce>MapReduce-作业列表”页中,点击“创建作业”,进入创建作业页。
-
请在创建作业页选择已创建的集群、选择“Java作业”并配置对应的参数。
- 作业名称:输入作业名称,长度不可超过255个字符。
- 应用程序位置:可输入样例程序路径
bos://bmr-public-data/apps/hbase/bmr-hbase-samples-1.0-SNAPSHOT.jar。 - 失败后操作:继续。
- MainClass:输入
com.baidubce.bmr.hbase.samples.uv.UniqueVisitor。 - 应用程序参数:输入
-D mapreduce.job.maps=6 -D mapreduce.job.reduces=2 AccessTable bos://${USER_BUCKET}/uv。bos://${USER_BUCKET}/uv必须具有写权限且该路径中所指定的目录不能在bos上存在,例如,输出路径为bos://test/sqooptest,则sqooptest目录在bos上必须不存在。
- 配置好作业参数后,点击“完成”,则作业创建完成。运行中的作业状态会由“等待中”更新为“运行中”,当作业运行完毕后状态会更新为“已完成”。
查看结果
bos://${USER_BUCKET}/pv/下的最终reduce结果示例:
103/Oct/2015 139
205/Oct/2015 372
304/Oct/2015 375
406/Oct/2015 114bos://${USER_BUCKET}/uv/下的最终reduce结果示例:
103/Oct/2015 111
205/Oct/2015 212
304/Oct/2015 247
406/Oct/2015 97BMR HBase读写分离集群构建
1、背景
当前hbase on bos 将存储与计算解耦,数据存储在bos 上体现了了众多运营优势。
- 优势1、HBase 根目录存储在 bos 中(HBase hfile存储文件和元信息)此数据在集群外部持续存在且可跨可用区访问。
- 优势2、较之前使用hdfs 3副本的冗余空间占用,大大节省了的存储空间。
- 优势3、避免集群资源的浪费,您可以针对计算要求而非数据规模要求调整 bmr 集群的大小,避免存储空间大但是计算需求小的情况存在资源浪费的情况。
如果您的主集群在批量加载、写入和压缩期间处于高负载状态,但是您同时又有一些历史数据分析查询的业务急需要处理。怎么办? 传统的方法你可能需要集群的扩容并配置group来保证集群业务之间的隔离。这样您可能为了满足自己一些读取的需求预留出一定的资源从而增加集群资源的成本,同时增加了运维的成本。如果您有这些烦恼,那么您可以replica cluster 功能创建辅助集群,以实现负载分担,将读取负载与写入负载分离开来,从而确保您满足读取服务要求,同时围绕成本和性能进行优化。
2、优点
使用read replica cluster 模式有如下几点的优点:
1、读写分离。写负载和读负载分布在不同的集群中,避免了业务在同一个集群的情况下相互的性能影响。提升读写性能,减少运维成本。
2、减少集群资源的使用成本,primary 集群可以只关注当前需要写的table,对一些不需要写入的table 可以直接disable掉,减少集群的压力。replica cluster可以只针对当前需要读取的表进行分析,避免无关的table占用过多的资源,减少使用成本。
3、即读即建,读完可删。如果不需要继续使用的话可以直接释放掉,减少使用成本。
当前功能replica cluster 与 primary cluster 的数据存在一定时间的gap(小时级),所以replica cluster 推荐读取更改不频繁的历史数据表。
创建集群
读写分离实现需要分别创建写集群和读集群,从而实现读写集群分离的构建。
创建写集群
-
登录控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,并做如下配置:
- 设置集群名称
- 设置管理员密码
- 打开日志开关
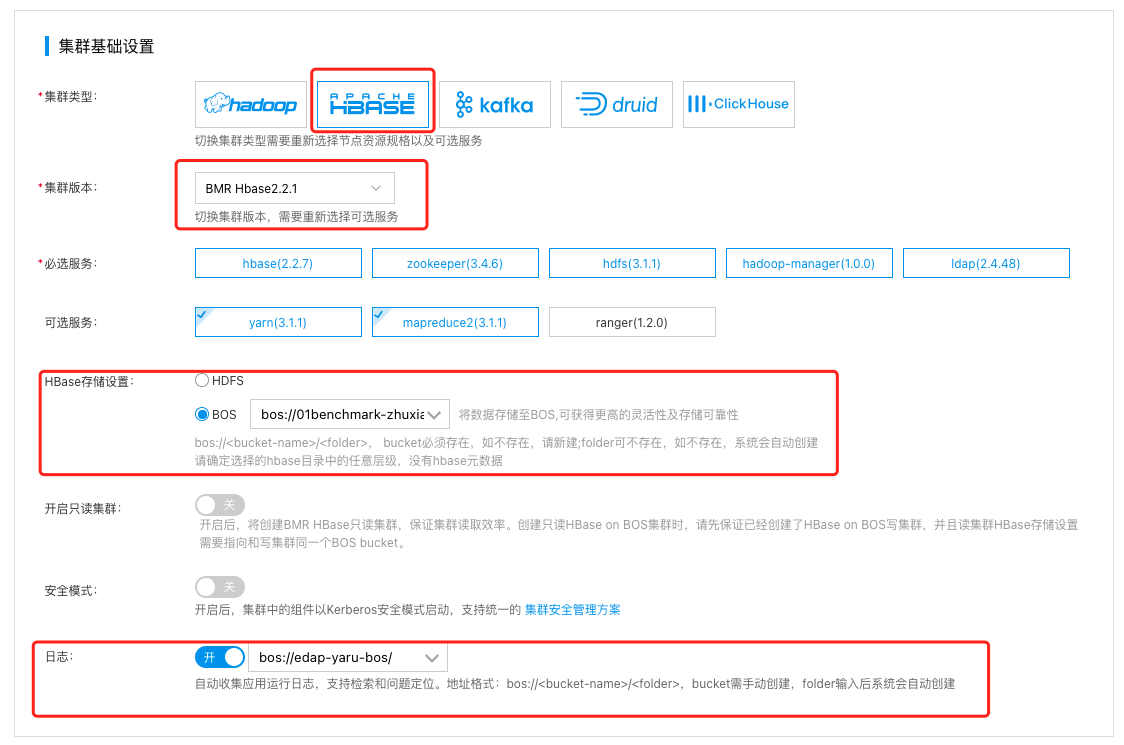
- 选择集群类型HBASE”
- 选择集群版本 BMR Hbase 2.2.1”。
- 请保持集群的其他默认配置不变,点击“完成”可在集群列表页可查看已创建的集群,当集群状态由“初始化中”变为“运行中”时,集群创建成功。
说明:Hbase集群支持在创建集群时将HBase存储设置设置为BOS,可以获得更高的数据可靠性。
bos:<bucket-name>/<folder>, bucket必须存在,如不存在,请新建;folder可不存在,如不存在,系统会自动创建;请确定选择的hbase目录中的任意层级,没有hbase元数据。集群创建后续无法修改该路径及切换为HDFS存储。请合理选择您的存储方式。具体设置方式,如下图所示。
创建只读集群
-
登录控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,并做如下配置:
- 设置集群名称
- 设置管理员密码
- 打开日志开关
- 选择集群类型HBASE”
- 选择集群版本 BMR Hbase 2.2.1”。
- 将HBase存储设置指向写集群统一BOS bucket
- 打开只读集群开关
- 指定要读取的表的名称,不填写默认可以读取写集群中所有的表。
开启后,将创建BMR HBase只读集群,保证集群读取效率。创建只读HBase on BOS集群时,请先保证已经创建了HBase on BOS写集群, 并且读集群HBase存储设置需要指向和写集群同一个BOS bucket。
- 请保持集群的其他默认配置不变,点击“完成”可在集群列表页可查看已创建的集群,当集群状态由“初始化中”变为“运行中”时,集群创建成功。
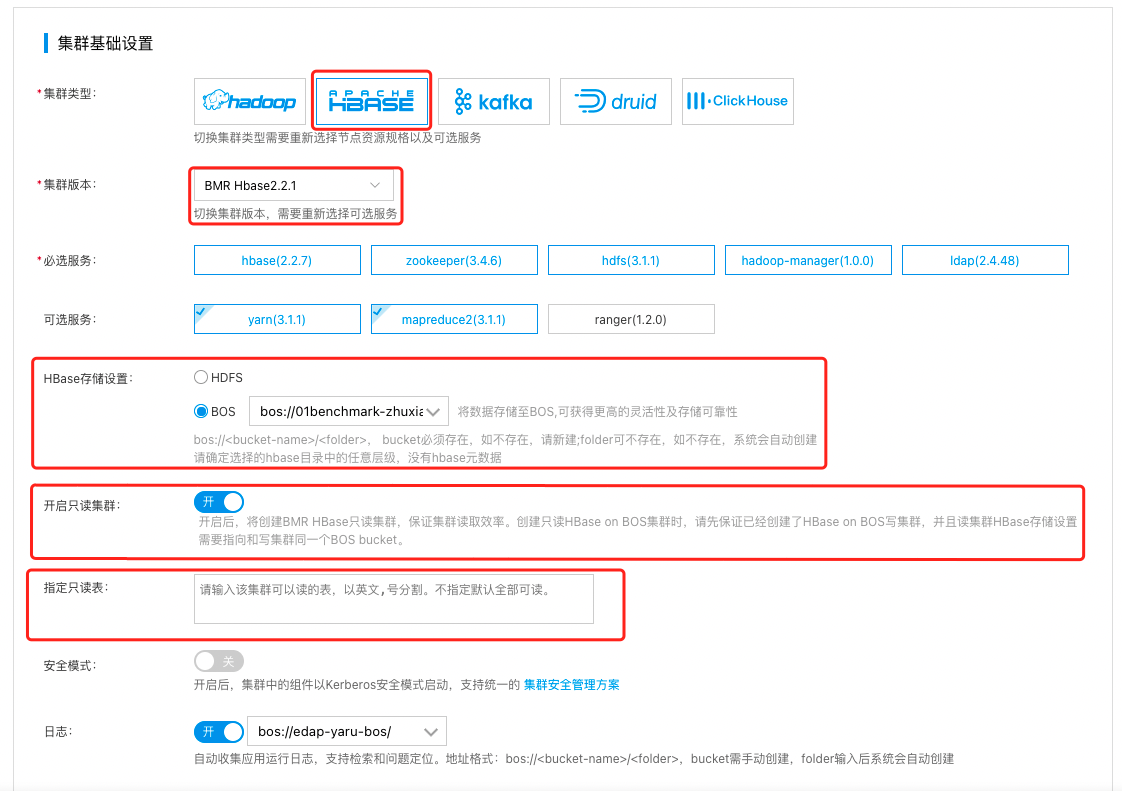
只读集群可以get和scan指定的表,但是禁止namespace、table、写入操作。
在写集群中创建HBASE表并插入数据
1、登录到写集群的master节点上,可以通过内网IP或者绑定EIP的方式访问集群主机或者点击主机名称,直接跳转到BCC console用VNC控制台登录。本实例采用VNC控制台登录。输入创建集群时的密码即可,用户名默认为:root。
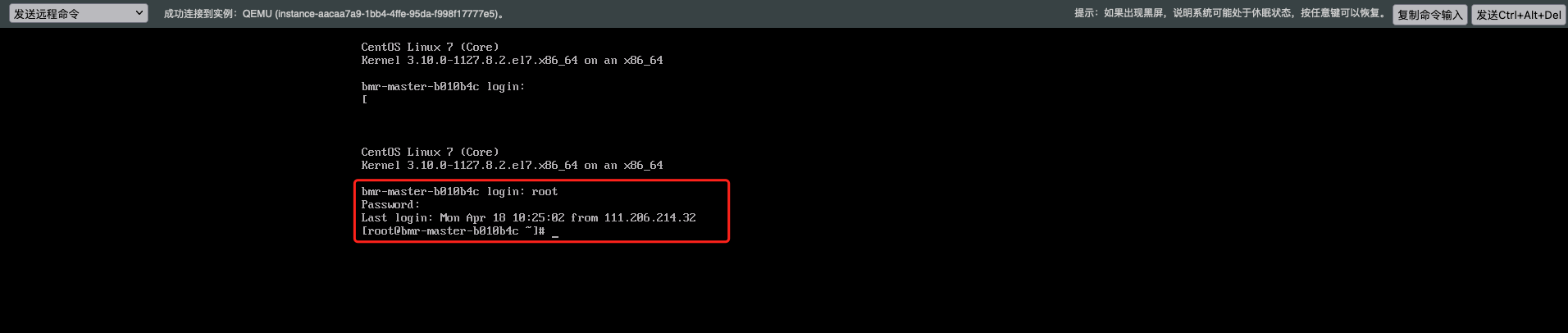
2、输入命令:hbase shell,进入hbase命令行模式。
3、创建表,执行命令:create 'Student','StuInfo','Grades'

4、插入数据
1put 'Student', '0001', 'StuInfo:Name', 'test'
2put 'Student', '0001', 'Grades:Name', '1'
3put 'Student', '0001', 'StuInfo:Sex', 'man'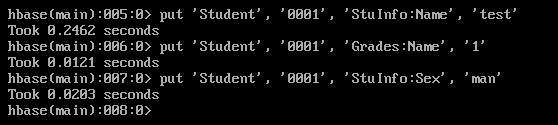
5、查看插入的数据。
scan 'Student'

在只读集群中查询数据
只读集群读取写集群中的历史数据时可以及时读取,但是读取写集群新创建的表或者插入的新数据有大约4小时左右的延迟,如需读取新创建的表或者是新插入表中的数据,请在写集群中刷新元数据或对应表,参考命令如下:flush 'meta' 或者 flush '表名'。
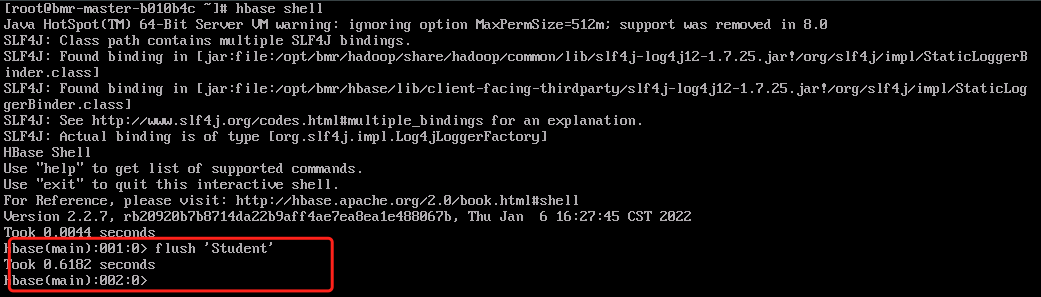
1、登录到只读集群的master节点上,可以通过内网IP或者绑定EIP的方式访问集群主机或者点击主机名称,直接跳转到BCC console用VNC控制台登录。本实例采用VNC控制台登录。输入创建集群时的密码即可,用户名默认为:root。
2、输入命令:hbase shell,进入hbase命令行模式。
3、查询数据。
scan 'Student'

评价此篇文章