
从Kafka同步数据
从Kafka到ClickHouse
首先,我们关注最常见的用例:使用Kafka表引擎将数据从Kafka插入ClickHouse。
Kafka表引擎允许ClickHouse直接从Kafka主题读取数据。虽然该引擎对于查看主题消息很有用,但其设计仅允许一次性检索,即当向表发出查询时,它会从队列中使用数据并增加消费者偏移量,然后再将结果返回给调用者。实际上,如果不重置这些偏移量,就无法重新读取数据。
为了从表引擎读取中持久保存这些数据,我们需要一种捕获数据并将其插入另一个表的方法。基于触发器的物化视图本身就提供了此功能。物化视图启动对表引擎的读取,接收批量文档。TO子句确定数据的目标 - 通常是Merge Tree系列的表。此过程如下所示:
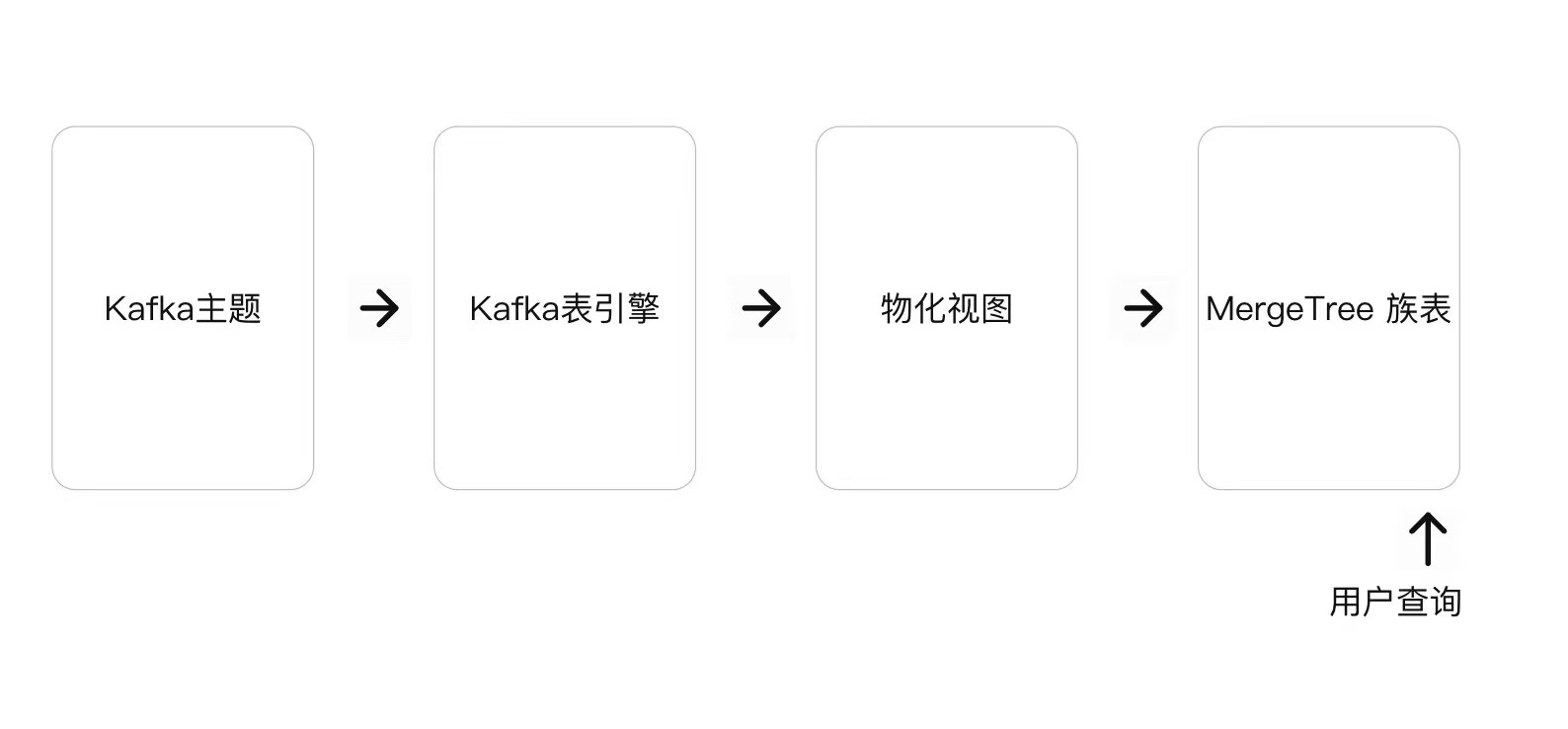
准备
如果您已填充目标主题的数据,则可以调整以下内容以用于您的数据集。或者,此处提供了一个示例 Github数据集。此数据集在下面的示例中使用,与此处提供的完整数据集相比,它使用了简化的架构和行子集(具体而言,我们限制为与ClickHouse 存储库有关的Github 事件),以简洁起见。这仍然足以使大多数随数据集发布的查询正常工作。
配置
- 如果您要连接到安全的Kafka,则此步骤是必需的。这些设置不能通过SQL DDL命令传递,必须在 ClickHouse config.xml中配置。我们假设您正在连接到SASL安全实例。这是与Confluent Cloud交互时最简单的方法。
1<clickhouse>
2 <kafka>
3 <sasl_username>username</sasl_username>
4 <sasl_password>password</sasl_password>
5 <security_protocol>sasl_ssl</security_protocol>
6 <sasl_mechanisms>PLAIN</sasl_mechanisms>
7 </kafka>
8</clickhouse>- 将上述代码片段放入 conf.d/ 目录下的新文件中,或将其合并到现有配置文件中。
- 再创建一个名为的数据库以
KafkaEngine供在本教程中使用:
1CREATE DATABASE KafkaEngine;4.创建数据库后,需要切换到该数据库:
1USE KafkaEngine;创建目标
准备目标表。在下面的示例中,为了简洁起见,我们使用简化的 GitHub 架构。
1CREATE TABLE github
2(
3 file_time DateTime,
4 event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
5 actor_login LowCardinality(String),
6 repo_name LowCardinality(String),
7 created_at DateTime,
8 updated_at DateTime,
9 action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
10 comment_id UInt64,
11 path String,
12 ref LowCardinality(String),
13 ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
14 creator_user_login LowCardinality(String),
15 number UInt32,
16 title String,
17 labels Array(LowCardinality(String)),
18 state Enum('none' = 0, 'open' = 1, 'closed' = 2),
19 assignee LowCardinality(String),
20 assignees Array(LowCardinality(String)),
21 closed_at DateTime,
22 merged_at DateTime,
23 merge_commit_sha String,
24 requested_reviewers Array(LowCardinality(String)),
25 merged_by LowCardinality(String),
26 review_comments UInt32,
27 member_login LowCardinality(String)
28) ENGINE = MergeTree ORDER BY (event_type, repo_name, created_at)创建并填充主题
以下示例创建一个具有与合并树表相同架构的表引擎。这并不是严格要求的,因为您可以在目标表中拥有别名或临时列。设置很重要;但是 - 请注意使用作为JSONEachRow从 Kafka 主题使用 JSON 的数据类型。值github和clickhouse分别代表主题名称和消费者组名称。主题实际上可以是值列表。
1CREATE TABLE github_queue
2(
3 file_time DateTime,
4 event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
5 actor_login LowCardinality(String),
6 repo_name LowCardinality(String),
7 created_at DateTime,
8 updated_at DateTime,
9 action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
10 comment_id UInt64,
11 path String,
12 ref LowCardinality(String),
13 ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
14 creator_user_login LowCardinality(String),
15 number UInt32,
16 title String,
17 labels Array(LowCardinality(String)),
18 state Enum('none' = 0, 'open' = 1, 'closed' = 2),
19 assignee LowCardinality(String),
20 assignees Array(LowCardinality(String)),
21 closed_at DateTime,
22 merged_at DateTime,
23 merge_commit_sha String,
24 requested_reviewers Array(LowCardinality(String)),
25 merged_by LowCardinality(String),
26 review_comments UInt32,
27 member_login LowCardinality(String)
28)
29 ENGINE = Kafka('kafka_host:9092', 'github', 'clickhouse',
30 'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 1;我们将在下面讨论引擎设置和性能调整。此时,对表进行简单的选择应该会读取一些行。请注意,这将使消费者偏移量向前移动,从而防止在没有重置的github_queue情况下重新读取这些行。注意限制和必需参数stream_like_engine_allow_direct_select.
创建物化视图
物化视图将连接之前创建的两个表,从 Kafka 表引擎读取数据并将其插入目标合并树表。我们可以进行许多数据转换。我们将进行简单的读取和插入。使用 * 假定列名相同(区分大小写)。
1CREATE MATERIALIZED VIEW github_mv TO github AS
2SELECT *
3FROM github_queue;在创建时,物化视图会连接到 Kafka 引擎并开始读取:将行插入目标表。此过程将无限期地继续,后续插入 Kafka 的消息将被使用。您可以随时重新运行插入脚本以将更多消息插入Kafka。
确认已插入数据
- 确认目标表中存在数据:
1SELECT count() FROM github;2.应该可以看到200,000行:
1┌─count()─┐
2│ 200000 │
3└─────────┘常见操作
停止并重新启动消息
- 要停止消息消费,可以分离 Kafka 引擎表:
1DETACH TABLE github_queue;- 这不会影响消费者组的偏移量。要重新开始消费并从之前的偏移量继续,请重新附加表。
1ATTACH TABLE github_queue;添加Kafka元数据
在将原始 Kafka 消息导入 ClickHouse 后,跟踪其中的元数据会很有用。例如,我们可能想知道我们已使用了多少特定主题或分区。为此,Kafka 表引擎公开了几个虚拟列。通过修改我们的架构和物化视图的 select 语句,这些可以作为目标表中的列保留下来。
- 首先,在向目标表添加列之前,我们执行上面描述的停止操作。
1DETACH TABLE github_queue;- 下面我们添加信息列来识别源主题和该行源自的分区。
1ALTER TABLE github
2 ADD COLUMN topic String,
3 ADD COLUMN partition UInt64;- 接下来,我们需要确保虚拟列按要求映射。虚拟列以 为前缀。虚拟列的完整列表可在此处
_找到。
要使用虚拟列更新我们的表,我们需要删除物化视图,重新连接 Kafka 引擎表,然后重新创建物化视图。
1DROP VIEW github_mv;1ATTACH TABLE github_queue;1CREATE MATERIALIZED VIEW github_mv TO github AS
2SELECT *, _topic as topic, _partition as partition
3FROM github_queue;- 新使用的行应该具有元数据。
1SELECT actor_login, event_type, created_at, topic, partition
2FROM github
3LIMIT 10;结果如下:
| actor_login | 事件类型 | 创建时间 | 主题 | 分割 |
|---|---|---|---|---|
| IgorMinar | 提交评论事件 | 2011-02-12 02:22:00 | github | 0 |
| queeup | 提交评论事件 | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | 提交评论事件 | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | 提交评论事件 | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | 提交评论事件 | 2011-02-12 02:25:20 | github | 0 |
| dapi | 提交评论事件 | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | 提交评论事件 | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | 提交评论事件 | 2011-02-12 12:21:40 | github | 0 |
| jpn | 提交评论事件 | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | 提交评论事件 | 2011-02-12 12:31:28 | github | 0修改 Kafka 引擎设置 |
修改 Kafka 引擎设置
我们建议删除 Kafka 引擎表并使用新设置重新创建它。在此过程中不需要修改物化视图 - 重新创建 Kafka 引擎表后,消息消费将恢复。
调试问题
身份验证问题等错误不会在对 Kafka 引擎 DDL 的响应中报告。为了诊断问题,我们建议使用主 ClickHouse 日志文件 clickhouse-server.err.log。可以通过配置启用底层 Kafka 客户端库librdkafka的进一步跟踪日志记录。
1<kafka>
2 <debug>all</debug>
3</kafka>处理格式错误的消息
Kafka 经常被用作数据的“垃圾场”。这会导致主题包含混合的消息格式和不一致的字段名称。避免这种情况,并利用 Kafka Streams 或 ksqlDB 等 Kafka 功能来确保消息在插入 Kafka 之前格式正确且一致。如果这些选项不可行,ClickHouse 有一些功能可以提供帮助。
- 将消息字段视为字符串。如果需要,可以在物化视图语句中使用函数来执行清理和转换。这不应代表生产解决方案,但可能有助于一次性提取。
- 如果您使用 JSONEachRow 格式从主题使用 JSON,请使用设置
input_format_skip_unknown_fields。默认情况下,在写入数据时,如果输入数据包含目标表中不存在的列,ClickHouse 会抛出异常。但是,如果启用此选项,这些多余的列将被忽略。同样,这不是生产级解决方案,可能会让其他人感到困惑。 - 考虑设置
kafka_skip_broken_messages。这要求用户指定每个块对格式错误的消息的容忍度 - 在 kafka_max_block_size 的上下文中考虑。如果超出此容忍度(以绝对消息为单位),则通常的异常行为将恢复,并且其他消息将被跳过。
传递语义和重复
Kafka 表引擎具有至少一次语义。在几种已知的罕见情况下,可能会出现重复。例如,可以从 Kafka 读取消息并成功插入 ClickHouse。在提交新的偏移量之前,与 Kafka 的连接已丢失。在这种情况下需要重试该块。可以使用分布式表或 ReplicatedMergeTree 作为目标表对块进行重复数据删除。虽然这减少了重复行的可能性,但它依赖于相同的块。诸如 Kafka 重新平衡之类的事件可能会使此假设无效,从而在极少数情况下导致重复。
基于Quorum的插入数据
在 ClickHouse 中需要更高交付保证的情况下,您可能需要基于仲裁的插入。这无法在物化视图或目标表上设置。但是,可以为用户配置文件设置它,例如:
1<profiles>
2 <default>
3 <insert_quorum>2</insert_quorum>
4 </default>
5</profiles>从ClickHouse到Kafka
尽管使用情况较少,但 ClickHouse 数据也可以保存在 Kafka 中。例如,我们将手动将行插入 Kafka 表引擎。该数据将由同一 Kafka 引擎读取,其物化视图将数据放入 Merge Tree 表中。最后,我们演示了在 Kafka 插入中应用物化视图从现有源表中读取表。体现为:
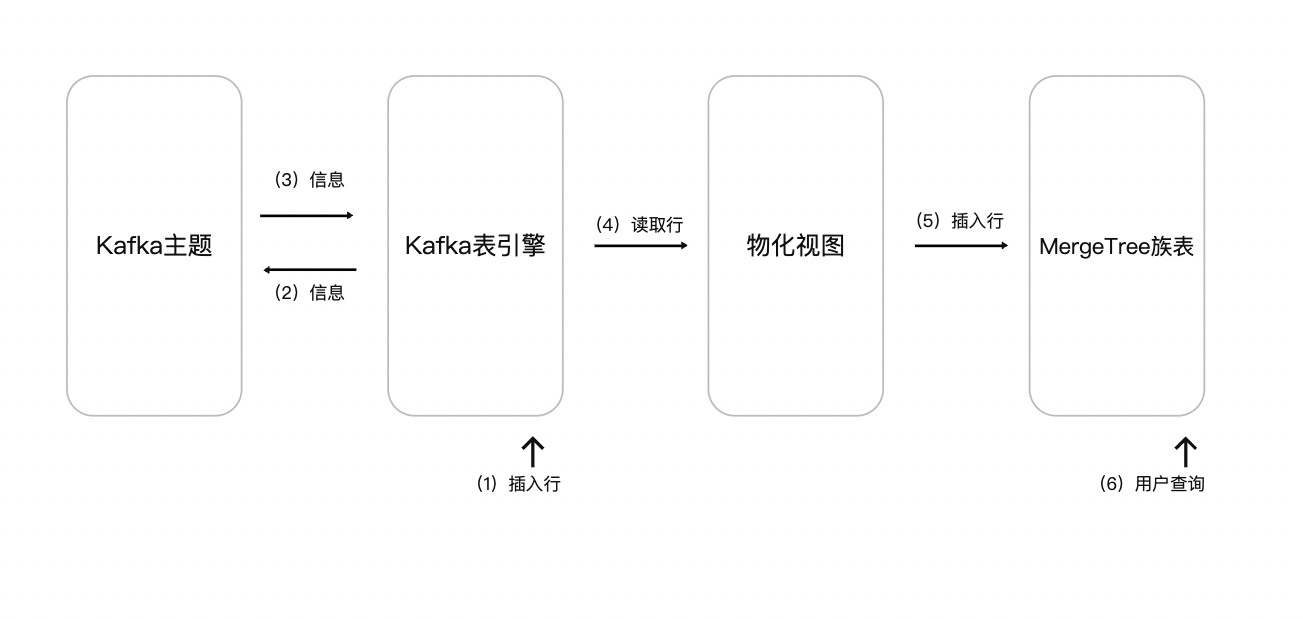
步骤
直接插入行
- 首先,确认目标表的数量。
1SELECT count() FROM github;您应该有 200,000 行:
1┌─count()─┐
2│ 200000 │
3└─────────┘- 现在将 GitHub 目标表中的行插入回 Kafka 表引擎 github_queue。请注意我们如何利用 JSONEachRow 格式并将选择限制为 100。
1INSERT INTO github_queue SELECT * FROM github LIMIT 100 FORMAT JSONEachRow3.重新计算 GitHub 中的行数以确认它已增加 100。如上图所示,行已通过 Kafka 表引擎插入 Kafka,然后由同一引擎重新读取并通过我们的物化视图插入到 GitHub 目标表中。
1SELECT count() FROM github;您应该会看到另外 100 行:
1┌─count()─┐
2│ 200100 │
3└─────────┘使用物化视图
- 当文档插入表中时,我们可以利用物化视图将消息推送到 Kafka 引擎(和主题)。当行插入 GitHub 表时,会触发物化视图,这会导致行重新插入 Kafka 引擎和新主题。再次说明这一点:
- 创建一个新的 Kafka 主题
github_out或等效主题。确保 Kafka 表引擎github_out_queue指向此主题。
1CREATE TABLE github_out_queue
2(
3 file_time DateTime,
4 event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
5 actor_login LowCardinality(String),
6 repo_name LowCardinality(String),
7 created_at DateTime,
8 updated_at DateTime,
9 action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
10 comment_id UInt64,
11 path String,
12 ref LowCardinality(String),
13 ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
14 creator_user_login LowCardinality(String),
15 number UInt32,
16 title String,
17 labels Array(LowCardinality(String)),
18 state Enum('none' = 0, 'open' = 1, 'closed' = 2),
19 assignee LowCardinality(String),
20 assignees Array(LowCardinality(String)),
21 closed_at DateTime,
22 merged_at DateTime,
23 merge_commit_sha String,
24 requested_reviewers Array(LowCardinality(String)),
25 merged_by LowCardinality(String),
26 review_comments UInt32,
27 member_login LowCardinality(String)
28)
29 ENGINE = Kafka('host:port', 'github_out', 'clickhouse_out',
30 'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 1;- 现在创建一个新的物化视图
github_out_mv以指向 GitHub 表,并在触发时将行插入上述引擎。因此,GitHub 表的添加内容将被推送到我们的新 Kafka 主题。
1CREATE MATERIALIZED VIEW github_out_mv TO github_out_queue AS
2SELECT file_time, event_type, actor_login, repo_name,
3 created_at, updated_at, action, comment_id, path,
4 ref, ref_type, creator_user_login, number, title,
5 labels, state, assignee, assignees, closed_at, merged_at,
6 merge_commit_sha, requested_reviewers, merged_by,
7 review_comments, member_login
8FROM github
9FORMAT JsonEachRow;- 如果您将原始 github 主题(作为Kafka 到 ClickHouse的一部分创建)插入,文档将神奇地出现在“github_clickhouse”主题中。使用原生 Kafka 工具确认这一点。例如,下面,我们使用kcat将 100 行插入到Confluent Cloud 托管主题的 github 主题中:
1head -n 10 github_all_columns.ndjson |
2kcat -P \
3 -b <host>:<port> \
4 -t github
5 -X security.protocol=sasl_ssl \
6 -X sasl.mechanisms=PLAIN \
7 -X sasl.username=<username> \
8 -X sasl.password=<password> 阅读该github_out主题应该可以确认消息已送达。
1kcat -C \
2 -b <host>:<port> \
3 -t github_out \
4 -X security.protocol=sasl_ssl \
5 -X sasl.mechanisms=PLAIN \
6 -X sasl.username=<username> \
7 -X sasl.password=<password> \
8 -e -q |
9wc -l注意事项
- 通过 Kafka 消费者组,多个 ClickHouse 实例可以从同一主题读取数据。每个消费者将以 1:1 的映射分配到主题分区。使用 Kafka 表引擎扩展 ClickHouse 消费时,请考虑集群中的消费者总数不能超过主题上的分区数。因此,请确保提前为主题适当配置分区。
- 可以将多个 ClickHouse 实例全部配置为使用相同的消费者组 ID(在创建 Kafka 表引擎时指定)从主题读取数据。因此,每个实例将从一个或多个分区读取数据,并将段插入到其本地目标表中。反过来,可以将目标表配置为使用 ReplicatedMergeTree 来处理数据重复。只要有足够的 Kafka 分区,这种方法就可以使用 ClickHouse 集群扩展 Kafka 读取。
- 在寻求提高 Kafka 引擎表吞吐量性能时,请考虑以下几点:
- 性能将根据消息大小、格式和目标表类型而有所不同。单个表引擎上 100k 行/秒应该被认为是可以实现的。默认情况下,消息以块的形式读取,由参数 kafka_max_block_size 控制。默认情况下,它设置为 max_insert_block_size ,默认为 1,048,576。除非消息非常大,否则几乎总是应该增加这个值。500k 到 1M 之间的值并不罕见。测试并评估对吞吐量性能的影响。
- 可以使用 kafka_num_consumers 增加表引擎的消费者数量。但是,默认情况下,除非 kafka_thread_per_consumer 从默认值 1 更改,否则插入将在单个线程中线性化。将其设置为 1 以确保并行执行刷新。请注意,创建具有 N 个消费者(并且 kafka_thread_per_consumer=1)的 Kafka 引擎表在逻辑上等同于创建 N 个 Kafka 引擎,每个引擎都有一个物化视图并且 kafka_thread_per_consumer=0。
- 增加消费者并非免费操作。每个消费者都维护自己的缓冲区和线程,这会增加服务器的开销。请意识到消费者的开销,并尽可能先在整个集群中线性扩展。
- 如果 Kafka 消息的吞吐量是可变的并且延迟是可以接受的,请考虑增加 stream_flush_interval_ms 以确保刷新更大的块。
- background_message_broker_schedule_pool_size设置执行后台任务的线程数。这些线程用于 Kafka 流式传输。此设置在 ClickHouse 服务器启动时应用,无法在用户会话中更改,默认为 16。如果您在日志中看到超时,则可能需要增加此值。
- 为了与 Kafka 通信,使用了 librdkafka 库,该库本身会创建线程。因此,大量的 Kafka 表或消费者可能会导致大量的上下文切换。要么将此负载分散到整个集群中,尽可能只复制目标表,要么考虑使用表引擎从多个主题读取 - 支持值列表。可以从单个表中读取多个物化视图,每个视图都过滤特定主题的数据。
- Kafka_max_wait_ms-重试前从Kafka读取消息的等待时间(毫秒)。设置为用户配置文件级别,默认为5000。
来自底层librdkafka的所有设置也可以放置在kafka元素内的ClickHouse配置文件中——设置名称应该是XML元素,用下划线替换句点,例如:
1<clickhouse>
2 <kafka>
3 <enable_ssl_certificate_verification>false</enable_ssl_certificate_verification>
4 </kafka>
5</clickhouse>评价此篇文章