
使用Hive分析网站日志
概览
网站日志包含用户访问信息,通过日志分析我们可以了解网站的访问量、网页访问次数、网页访问人数、频繁访问时段等等,以便获取用户行为以优化网站的商业价值。由于网站每天会产生海量的日志,非常适合使用MapReduce(简称BMR)这样的托管Hadoop服务。同时,BMR集成了Hive和Hue,开发者可在浏览器中与Hadoop集群交互,分析处理数据,完成创建数据集、执行Hive查询等操作,大大降低了使用门槛。
需求场景
网站PV/UV日志分析
WEB服务网站每天都会有大量的用户访问,相关的用户行为,访问量,访问频次以及用户行为等数据具有很大的商业价值,可以用于用户画像的构建以及用户行为的预测等。
方案概述
示例日志
示例日志是Nginx日志,存储在对象存储服务BOS的公共可读的路径中:
- 存储在“华北-北京”区域的样例数据路径为:bos://datamart-bj/web-log-10k/,仅华北区域的BMR集群可用。
- 存储在“华南-广州”区域的样例数据路径为:bos://datamart-gz/web-log-10k/,仅华南区域的BMR集群可用。
关于百度智能云的区域说明,请参考区域选择说明。
分析过程总览
使用BMR分析Niginx日志的过程如下:
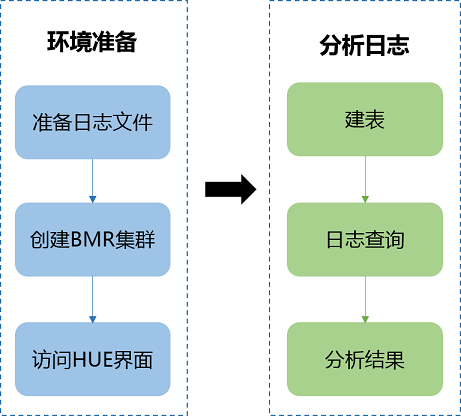
环境准备
准备日志文件
您可跳过此步直接使用百度智能云提供的示例日志。在熟悉日志分析后,可参考数据准备选择您自己的日志数据。
创建BMR集群
- 打开“产品服务>MapReduce>MapReduce-集群列表”,点击“创建集群”,进入集群配置页面。
- 选择付费方式和地区,可选择后付费或预付费,地域和区域(可用区)根据客户需求自行选择即可。
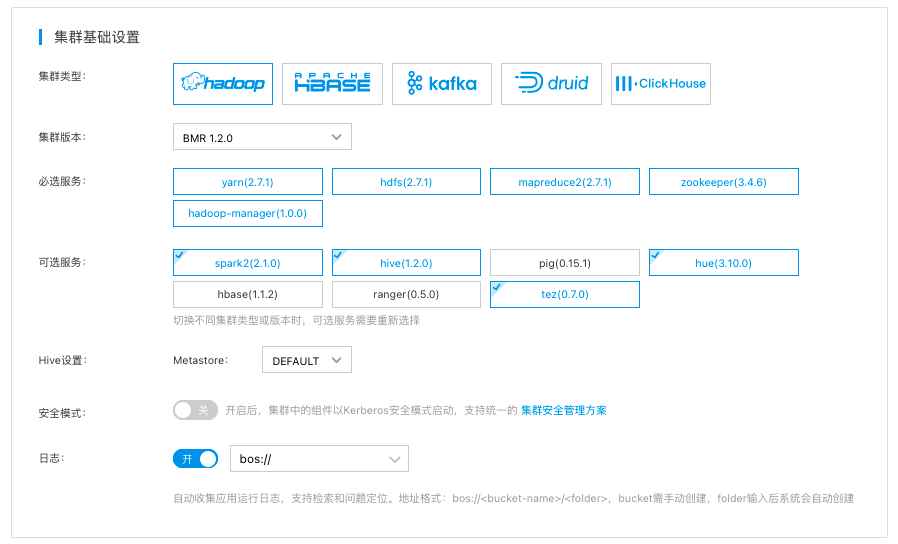
- 在“集群基础设置”区选择集群类型"hadoop",并且选择 BMR 1.2.0版本,并且勾选HUE 、Hive、Spark等需要的服务。
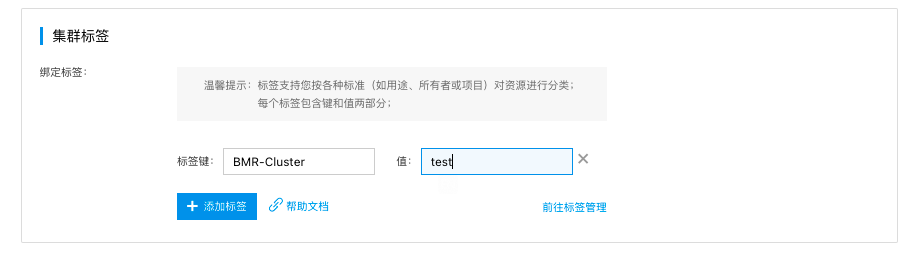
- 用户可以对BMR集群打标签,用于区分不同集群。也可默认不填写。
5.在"基础设置"中设置集群名称,密码和网络等信息,然后点击下一步。
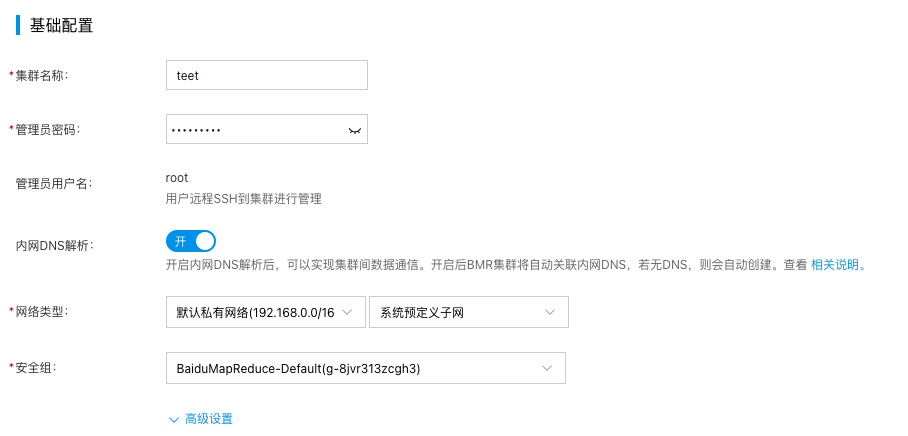
- 根据用户实际计算和存储需求,选择实例类型规格,点击“提交订单”。支付订单后,集群会在五至十分钟左右创建完成。
访问Hue Web界面
- 打开“产品服务>MapReduce>MapReduce-集群列表”,点击已创建的集群,进入实例详情页面。
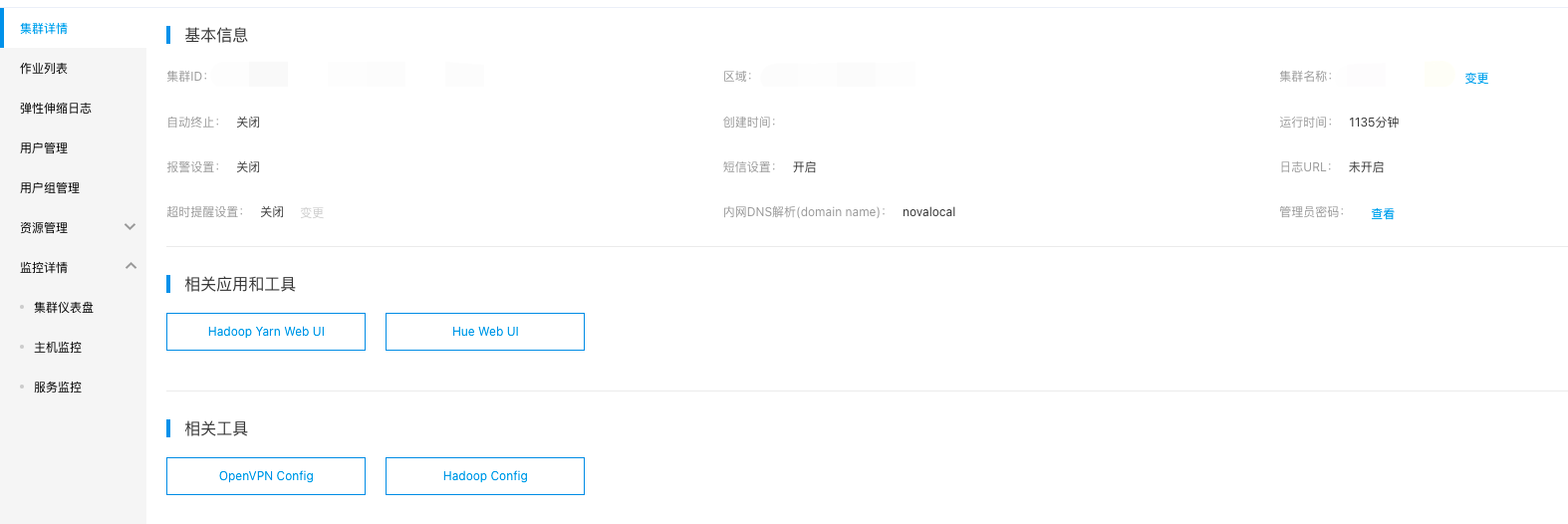
- 在“相关应用”栏中点击“Hue Web UI”。
-
在弹出的认证页面中输入创建集群时设置的用户名和密码,用户名默认为root,密码为创建集群时的密码,并点击“登录”。
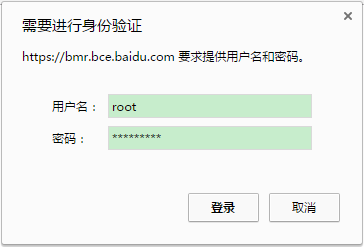
-
首次登录HUE WEB UI,需要创建您登录Hue服务的用户名和密码,输入后点击“Create Account”后进入Hue Web界面。
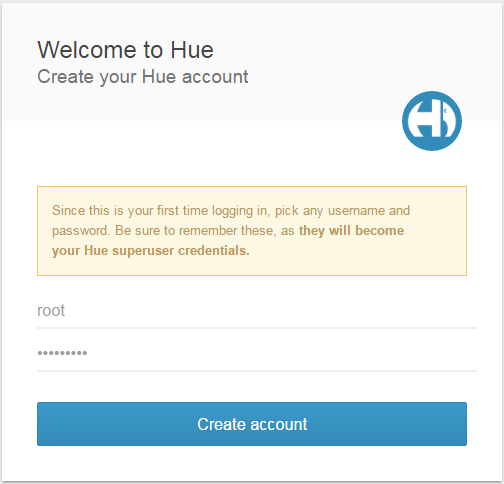
分析网站日志
建表
-
在分析之前,首先需要根据网站日志建立一张Hive表。在Hue菜单栏中选择“查询编辑器”>“Hive”,并输入以下SQL语句:
SQL1DROP TABLE IF EXISTS access_logs; 2CREATE EXTERNAL TABLE access_logs( 3 remote_addr STRING comment 'client IP', 4 time_local STRING comment 'access time', 5 request STRING comment 'request URL', 6 status STRING comment 'HTTP status', 7 body_bytes_sent STRING comment 'size of response body', 8 http_referer STRING comment 'referer', 9 http_cookie STRING comment 'cookies', 10 remote_user STRING comment 'client name', 11 http_user_agent STRING comment 'client browser info', 12 request_time STRING comment 'consumed time of handling request', 13 host STRING comment 'server host', 14 msec STRING comment 'consumed time of writing logs' 15) 16COMMENT 'web access logs' 17ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' 18WITH SERDEPROPERTIES ( 19 "input.regex" = "([0-9\\.]+) - \\[([^\\]]+)\\] \"([^\"]*)\" ([\\d]+) ([\\d]*) \"([^\"]*)\" \"([^\"]*)\" ([\\S]+) \"([^\"]*)\" ([0-9\\.]+) ([\\S]+) ([0-9\\.]+)" 20 ) 21STORED AS TEXTFILE 22LOCATION "bos://datamart-bj/web-log-10k"; - 输入语句后点击左侧的三角符号执行命令,这样,Hive会重建access_logs表,然后通过正则表达式来解析日志文件。
-
成功创建access_logs表之后,点击Hive Editor左侧的刷新按钮,找到access_logs表并预览示例数据:

查询
定了表之后,便可以进行查询了。
-
若统计网页请求的结果,可使用以下语句:
Plain Text1SELECT status, count(1) 2FROM access_logs 3GROUP BY status查询结果可切换到图表页,还可以以饼图的形式可视化数据,如下图所示:

-
若想了解那个时段网页访问量最大,可使用下面的语句:
Plain Text1SELECT hour(from_unixtime(unix_timestamp(time_local, 'dd/MMMM/yyyy:HH:mm:ss Z'))) as hour, count(1) as pv 2FROM access_logs 3GROUP BY hour(from_unixtime(unix_timestamp(time_local, 'dd/MMMM/yyyy:HH:mm:ss Z')))查询结果可切换到图表页,或以柱状图来更直观的查看结果:
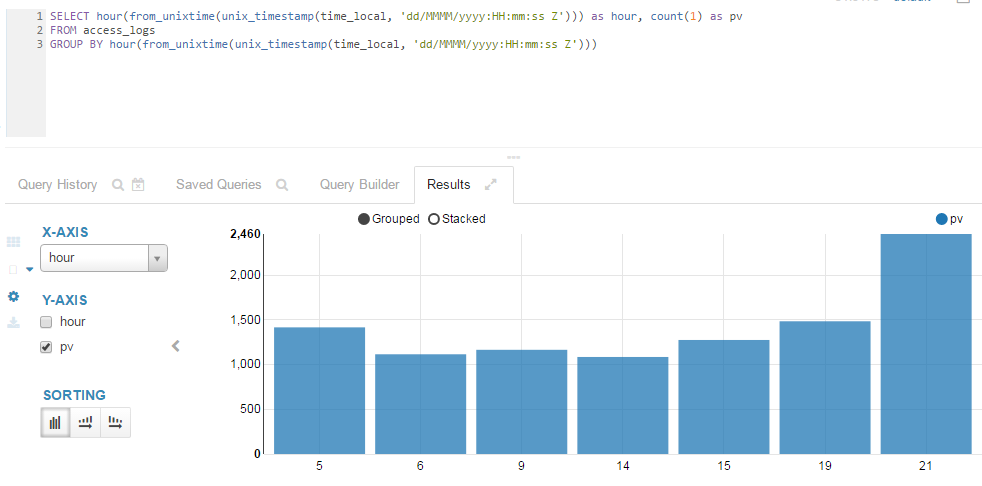
分析结果
网页访问量最大的时间点是晚上九点。
6 相关产品
评价此篇文章