
IK中文分词插件与动态更新词典
更新时间:2024-07-12
IK中文分词插件(英文名为analysis-ik)是百度智能云Elasticsearch默认安装的中文分词插件。
本文介绍了IK 中文分词插件的使用方法和动态更新IK词典的方法。
注意:目前IK中文分词插件支持所有版本的Elasticsearch实例。
使用方法
分词粒度
analysis-ik主要提供两种粒度的Analyzer:
- ik_max_word:会将文本做最细粒度的拆分;尽可能多的拆分出词语
- ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
同名提供两种Tokenizer:
- ik_max_word
- ik_smart
切词效果
ik_max_word的切词效果如下:
Text
1POST /_analyze
2{
3 "analyzer": "ik_max_word",
4 "text": "百度校园夏令营"
5}
Plain Text
1{
2 "tokens": [
3 {
4 "token": "百度",
5 "start_offset": 0,
6 "end_offset": 2,
7 "type": "CN_WORD",
8 "position": 0
9 },
10 {
11 "token": "百",
12 "start_offset": 0,
13 "end_offset": 1,
14 "type": "TYPE_CNUM",
15 "position": 1
16 },
17 {
18 "token": "度",
19 "start_offset": 1,
20 "end_offset": 2,
21 "type": "COUNT",
22 "position": 2
23 },
24 {
25 "token": "校园",
26 "start_offset": 2,
27 "end_offset": 4,
28 "type": "CN_WORD",
29 "position": 3
30 },
31 {
32 "token": "夏令营",
33 "start_offset": 4,
34 "end_offset": 7,
35 "type": "CN_WORD",
36 "position": 4
37 },
38 {
39 "token": "夏令",
40 "start_offset": 4,
41 "end_offset": 6,
42 "type": "CN_WORD",
43 "position": 5
44 },
45 {
46 "token": "夏",
47 "start_offset": 4,
48 "end_offset": 5,
49 "type": "CN_WORD",
50 "position": 6
51 },
52 {
53 "token": "令",
54 "start_offset": 5,
55 "end_offset": 6,
56 "type": "CN_CHAR",
57 "position": 7
58 },
59 {
60 "token": "营",
61 "start_offset": 6,
62 "end_offset": 7,
63 "type": "CN_CHAR",
64 "position": 8
65 }
66 ]
67}ik_smart的切词效果如下:
Text
1POST /_analyze
2{
3 "analyzer": "ik_smart",
4 "text": "百度校园夏令营"
5}
Plain Text
1{
2 "tokens": [
3 {
4 "token": "百度",
5 "start_offset": 0,
6 "end_offset": 2,
7 "type": "CN_WORD",
8 "position": 0
9 },
10 {
11 "token": "校园",
12 "start_offset": 2,
13 "end_offset": 4,
14 "type": "CN_WORD",
15 "position": 1
16 },
17 {
18 "token": "夏令营",
19 "start_offset": 4,
20 "end_offset": 7,
21 "type": "CN_WORD",
22 "position": 2
23 }
24 ]
25}动态更新词典
配置词典
当IK自身带的词库不满足需求时,用户可以自定义词典。步骤如下:
- 把编辑好的词典放到一个http服务器上,可以选择以下两种方案。
- 用户可以把词典文件上传到BOS,并获取链接地址。需要注意的是,务必保证Elasticsearch所在地区与BOS Bucket的地区相同,否则无法访问词典。
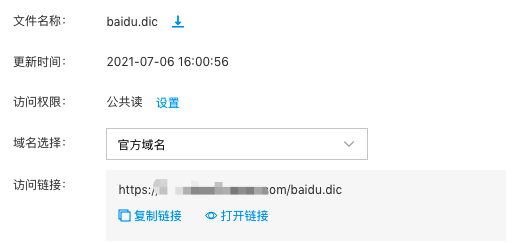
1.建议将词典文件的访问权限设置为
公共读,确保链接地址永久有效,且不会发生变化。
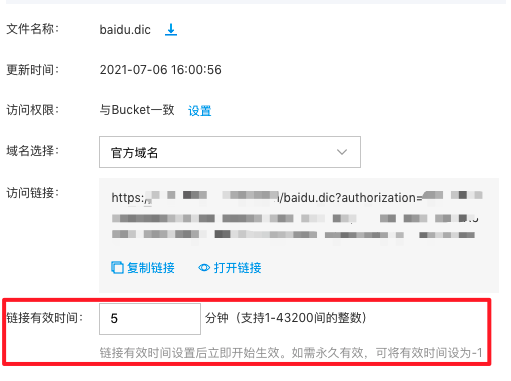
2.若不设置为公共读,则需要按业务需求修改BOS链接的有效时间,如需永久有效,可将有效时间设为-1。注意,链接有效期过后或词典文件如果发生修改(删除后重新上传),链接地址会发生变化,此时需要重新在ES中配置链接地址。
- 用户也可以自行部署http服务器,将词库放在服务器上。需要注意的是,务必保证Elasticsearch所在节点能够访问该http服务,否则无法下载安装。
- 在Elasticsearch里配置ik词库的http地址,比如自定义词库的配置文件是baidu.dict,停用词的配置文件是baidu_stop.dic时,向Elasticsearch发送的命令如下:
Text
1PUT /_cluster/settings
2{
3 "persistent": {
4 "bpack.ik_analyzer.remote_ext_dict":"http://ip:port/baidu.dic",
5 "bpack.ik_analyzer.remote_ext_stopwords":"http://ip:port/baidu_stop.dic"
6 }
7}- Elasticsearch会每隔60s检测一下setting中http url指向的词库文件是否发生变化,如果变化了,那么es就会自动下载这个文件,然后加载到ik中。
验证词库是否生效
当配置好后,用户可以通过POST /_analyze 来检测词库是否生效,比如:
- 在没有配置词库之前,分词效果为:
Plain Text
1POST /_analyze
2{
3 "analyzer" : "ik_smart",
4 "text" : ["赵小明明真帅"]
5}Elasticsearch的返回结果是:
Plain Text
1 {
2 "tokens": [
3 {
4 "token": "赵",
5 "start_offset": 0,
6 "end_offset": 1,
7 "type": "CN_WORD",
8 "position": 0
9 },
10 {
11 "token": "小明",
12 "start_offset": 1,
13 "end_offset": 3,
14 "type": "CN_WORD",
15 "position": 1
16 },
17 {
18 "token": "明",
19 "start_offset": 3,
20 "end_offset": 4,
21 "type": "CN_WORD",
22 "position": 2
23 },
24 {
25 "token": "真帅",
26 "start_offset": 4,
27 "end_offset": 6,
28 "type": "CN_WORD",
29 "position": 3
30 }
31 ]
32 }- 然后配置自定义词典,其中正常词库里只包含 "赵小明明", 停用词词库中包含 "真帅",配置完之后,再次调用
POST /_analyze,结果如下:
Text
1{
2 "tokens": [
3 {
4 "token": "赵小明明",
5 "start_offset": 0,
6 "end_offset": 4,
7 "type": "CN_WORD",
8 "position": 0
9 }
10 ]
11}结果显示, “赵小明明” 被当做一个单独的词,而 "真帅" 由于是停用词所以没有被分词。
评价此篇文章