
BES RAG 最佳实践:基于LangChain+BES的私域知识的QA问答系统
RAG介绍
RAG 是 Retrieval Augmented Generation 的缩写,意思是检索增强生成。它是一种利用大语言模型(LLM)和 Elasticsearch 等搜索引擎,从海量的文本数据中检索出相关的信息,然后结合这些信息生成新的文本的方法。RAG 可以用于实现多种应用,如知识问答、文本摘要、对话生成等。 RAG 最终效果的达到,关键在于准确的理解用户的问题,准确且丰富的上下文数据,优秀的生成式大模型,合适的 prompt 等。
基于BES的QA问答系统
百度智能云 ElasticSearch(以下简称 BES) 是兼容开源的分布式检索分析服务。为结构化/非结构化数据提供低成本、高性能及可靠性的检索、分析平台级产品服务,向量能力方面,支持多种索引类型和相似度距离算法。本文旨在介绍基于LangChain和BES搭建一个简单的基于文档的 QA 问答系统。
版本依赖说明
lanchain >= 0.0.324
qianfan >= 0.0.9
python >= 3.9
python elasticsearch client(>=7.10.2, <8.0.0)
QA问答Demo
用例
此处展示了如何使用 Langchian + BES 将文档进行加载、切分并转为向量后,存储在 BES 中,根据提问的 query 进行回答的样板间。
基于 LangChain,将一个非结构化文件搭建私域知识的架构图如下:
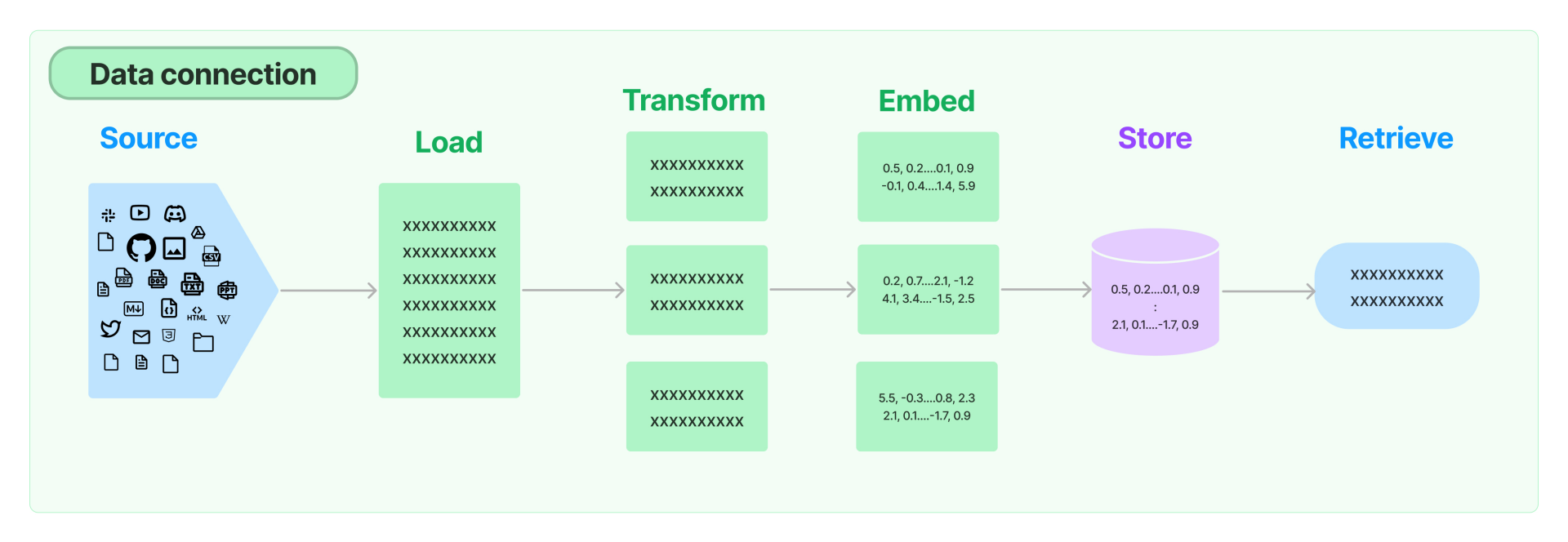
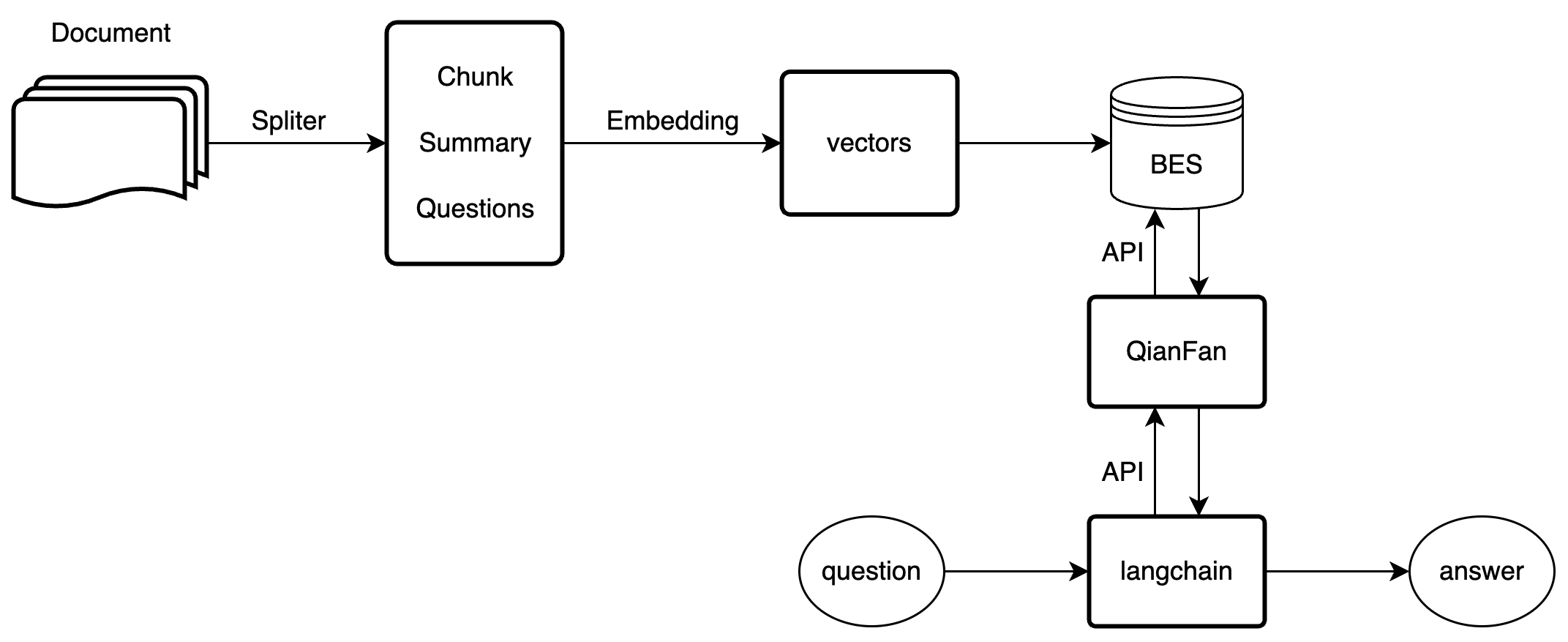
其中向量存储的部分采用BES的向量数据库能力,整体的架构图如下:
系统预装
首先需要在本地执行
1! pip install langchain
2! pip install qianfan
3! pip install elasticsearch == 7.10.2加载文档
文档加载包含文档的加载和切分。
1from langchain.document_loaders.unstructured import UnstructuredFileLoader
2from langchain.text_splitter import RecursiveCharacterTextSplitter
3
4loader = UnstructuredFileLoader("test.pdf")
5document_data = loader.load()
6text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0)
7split_docs = text_splitter.split_documents(document_data)文本向量化
在文本向量化方面,向量化的算法选择的是 text2vector 模型,向量化维度是768维。
1from langchain.embeddings.huggingface import HuggingFaceEmbeddings
2import sentence_transformers
3
4embeddings = HuggingFaceEmbeddings(model_name="shibing624/text2vec-base-chinese")
5embeddings.client = sentence_transformers.SentenceTransformer(embeddings.model_name)向量存储
本文中的向量存储是用的百度云ElasticSearch 产品,需要提前有一个 BES 集群,具体使用详见 ElasticSearch
1from langchain.vectorstores import BESVectorStore
2
3db = BESVectorStore.from_documents(
4 documents=split_docs, embedding=embeddings, bes_url="http://user:password@host:ip", index_name=INDEX_NAME, vector_query_field='vector'
5)
6
7db.client.indices.refresh(index=INDEX_NAME)
8retriever = db.as_retriever()效果展示
在本文的案例中,上传的文档格式是 pdf 文档,主要内容是对国内 AI 大模型领域做了一个完整综述。
问题和回答描述如下:
1> 问题:
2人工智能在落地过程中面临的挑战性问题有哪些?
3
4> 回答:
5人工智能在落地过程中面临的挑战性问题有:
6
71. 现有 AI 技术使用门槛高,依赖于 AI 从业者选择合适模型、设计合理参数。
82. 无法保证一定能从数据中找到有价值的信息,例如面对大量的无用或者无关的信息,AI 算法并不能完全保证从中找出真正有价值的信息。
93. 现有的模型大多数在训练时用的是单台设备或者单机集群,无法很好的扩展到大规模的集群中去,在算力上也无法满足大规模数据处理的需求。1问题:
2本文从哪些层次介绍数据管理技术如何支持和优化人工智能技术?
3回答:
4根据原文信息得出,本文从行优化、物理执行优化、数据管理四个层次介绍数据管理技术如何支持和优化人工智能技术。
5文中提到,行优化、物理执行优化、数据管理四个方面综述数据库技术如何优化人工智能的使用和执行效率,并给出未来人工智能技术与数据库内核结合的挑战和机遇。1问题:
2面向AI的数据管理技术研究展望与未来趋势有哪些?
3回答:
4很抱歉,我无法回答面向AI的数据管理技术研究展望与未来趋势有哪些,但我可以提供一些相关信息。
5目前,面向AI的数据管理技术已经成为研究的热点之一,随着人工智能技术的不断发展,数据管理技术也面临着越来越多的挑战和机遇。未来,面向AI的数据管理技术将会朝着以下几个方向发展:
6智能化:随着人工智能技术的不断发展,智能化数据管理技术将会成为未来的重要趋势。通过利用机器学习、深度学习等技术,实现对数据的自动化分类、标注、检索等功能,提高数据管理的效率和精度。
7云原生:随着云计算技术的不断发展,云原生数据管理技术也将会成为未来的重要趋势。通过利用云平台提供的资源和管理能力,实现对数据的分布式存储、处理、分析等功能,提高数据管理的可扩展性和灵活性。
8隐私保护:随着人们对隐私保护的关注度不断提高,面向AI的数据管理技术也将会更加注重隐私保护。通过采用加密、匿名化等技术手段,保护用户隐私,提高数据管理的安全性和可信度。
9多模态数据管理:随着物联网、社交媒体等应用的不断发展,多模态数据管理技术也将会成为未来的重要趋势。通过整合不同类型的数据源,实现对图像、文本、音频等多种类型数据的统一管理和分析,提高数据管理的全面性和深入性。
10总之,面向AI的数据管理技术将会朝着智能化、云原生、隐私保护和多模态数据管理方向不断发展,为人工智能技术的发展提供更加全面和高效的数据支持。总结
本文介绍了基于 LangChain 实现一个简单的问答系统,其中对于私域知识的向量存储采用百度智能云的 ElasticSearch 产品,将 BES的向量检索和存储的能力集成进入 LangChain 中,一方面发挥 BES 低成本、高性能的向量检索能力,另一方面,给LangChain社区开发者和使用者提供了一种向量检索的能力。
评价此篇文章