
基于BOS的冷热数据分离
百度智能云Elasticsearch(以下简称为ES)使用不同的存储介质来存储数据,达到冷热数据分离的目的:
- 对于读写性能要求比较高的“热数据”,使用SSD云磁盘存储,保障了高效的查询性能。
- 对于存储量需求比较大但对查询性能要求较低的“冷数据”,使用价格更低廉的百度对象存储(BOS)存储数据,大幅度降低存储成本。
注意:目前冷热数据分离架构仅支持功能发布后新创建的7.4.2、7.10.2版本的实例。无法使用冷热数据分离功能的集群请提交工单,BES团队会协助升级集群,升级方式参见ES版本升级。
实现原理
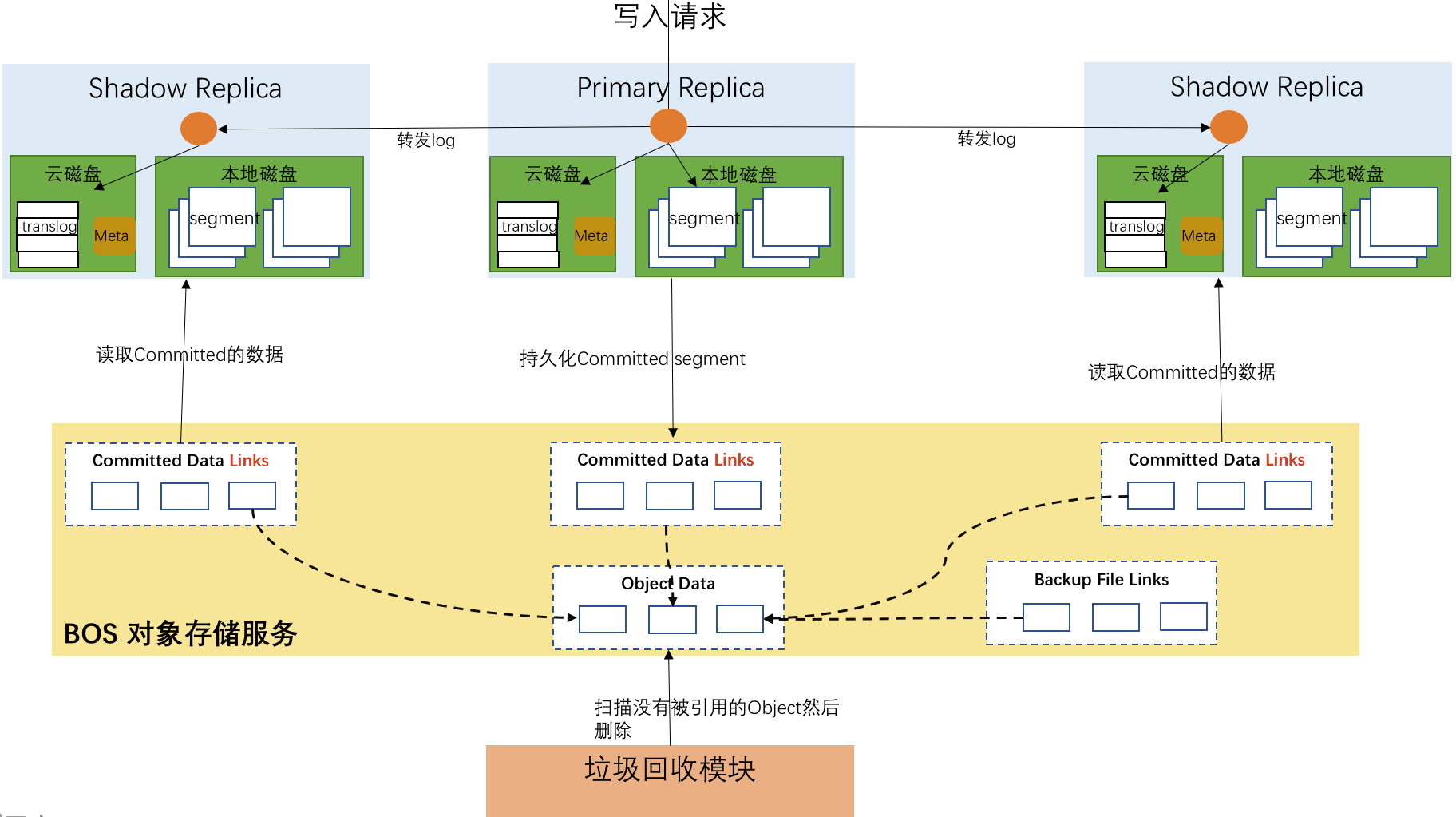
优势
- 冷热数据分离:热数据使用SSD云磁盘存储,保证性能,冷数据使用价格低廉的BOS存储,更经济的满足用户的需求。
- 高性价比:使用BOS作为存储介质,扩大了ES单节点的存储容量,用户可以使用较少的ES节点存储大量的数据,大幅度降低存储成本。
适用场景
- 历史日志分析场景:历史数据量大,查询频率相对低,使用冷热数据分离可以大幅降低存储成本。
使用方法
最开始使用基于BOS冷热分离架构时,首先创建BOS Bucket的并配置,然后将BOS相关信息配置到ES中。最后就可以在ES中创建冷热数据分离Index,在业务需要时 手动 或通过管控平台 定时调度功能 进行索引置冷,将Index迁移到BOS。
创建BOS Bucket
冷热数据分离使用BOS来做冷数据的共享存储,因此在使用冷热数据分离架构前,需要先新建BOS Bucket。
用户可以通过 Console 控制台创建BOS Bucket:
- 登录 对象存储 BOS 管理控制台
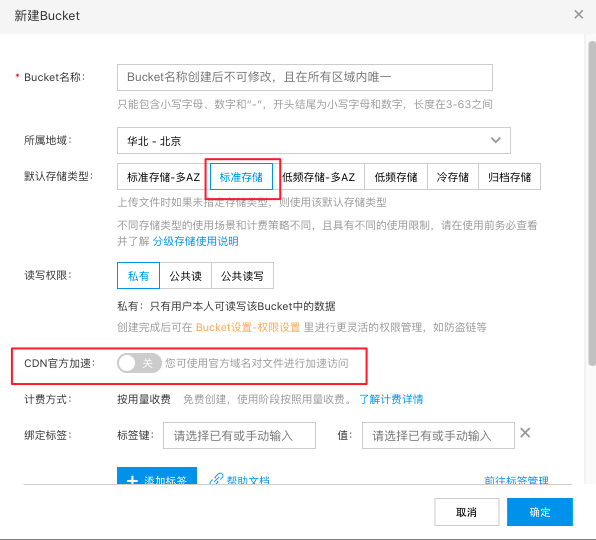
- 在控制台左侧的导航栏中找到并点击 + 按钮(“新建 Bucket”按钮),在弹出框中按照提示创建Bucket。
- 新建Bucket配置项说明:
- 默认存储类型:选择“标准存储”
- CDN官方加速:关闭
其他配置项用户可根据业务需求选择。创建Bucket详细方式参见:创建Bucket
Bucket生命周期配置
使用BOS创建Bucket后,强烈建议配置Bucket生命周期。
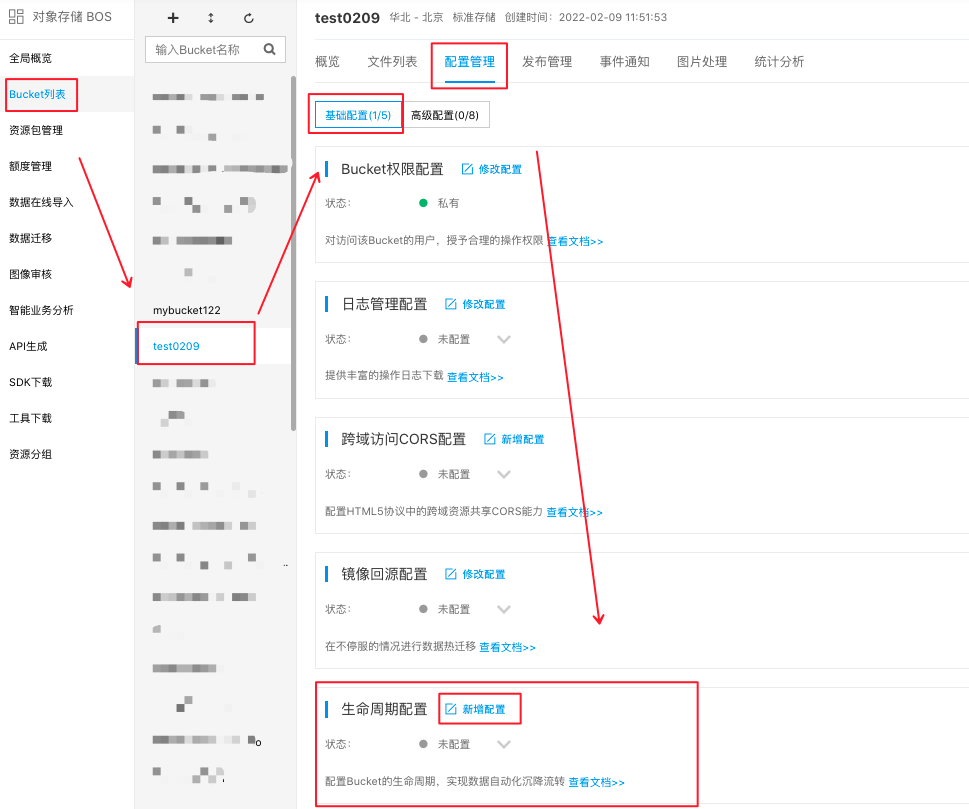
- 登录 对象存储 BOS 管理控制台。
- 在左侧Bucket列表中,选择需要设置权限的 Bucket,点击 Bucket 名称进入 Bucket 管理目录。
- 在上方导航栏选择 配置管理 标签。
- 在 配置管理 页面中选择 基础配置,在 生命周期配置 区域点击 新增配置 ,对该Bucket的生命周期进行配置。默认情况下该功能不开启。
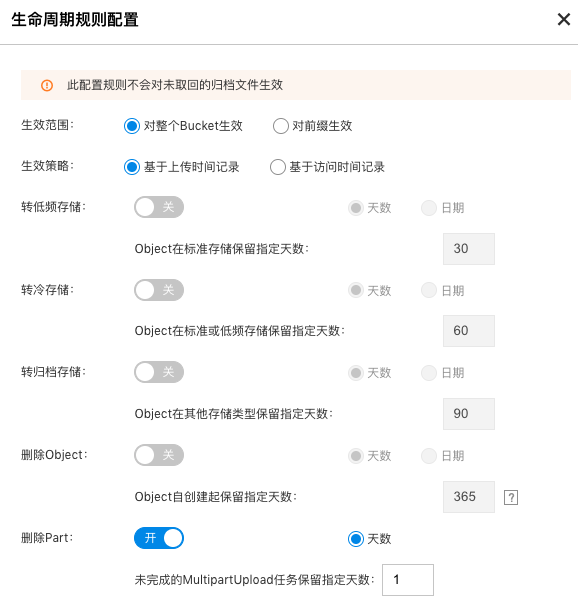
- 配置规则:
- 不可启用
删除Object规则,避免冷数据被删除 - 启用
删除Part规则,保存天数设为1天,防止未上传完整的数据块占用存储空间,造成多余存储费用
配置BOS信息到BES
通过如下API可以设置BOS存储信息:
1PUT /_cluster/settings
2{
3 "persistent": {
4 "bpack.remote_storage.bos.access_key": "xxxxxxxx",
5 "bpack.remote_storage.bos.secret_key": "xxxxxxxx",
6 "bpack.remote_storage.bos.bucket": "es_remote_bucket",
7 "bpack.remote_storage.bos.endpoint": "bj.bcebos.com",
8 "bpack.remote_storage.bos.base_path": "es_shared_data"
9 }
10}参数说明:
| 参数 | 含义 |
|---|---|
| bpack.remote_storage.bos.access_key | 访问BOS需要的access key, 可以在百度智能云的控制台上获得。 |
| bpack.remote_storage.bos.secret_key | 访问BOS需要的secret access key,可以在百度智能云的控制台上获得。 |
| bpack.remote_storage.bos.bucket | BOS上建立的bucket的名称,需要提前创建。 |
| bpack.remote_storage.bos.endpoint | BOS的访问地址,一般情况下每个地区有不同的地址,您可以参考BOS的使用文档来获得每个地域的地址。 |
| bpack.remote_storage.bos.base_path | 百度智能云Elasticsearch存放数据的目录。 |
冷热分离引擎会定期请求BOS,扫描并清理BOS上的过期数据,因此配置的AK、SK需要拥有该bucket的write、read、list权限。
创建冷热数据分离Index
在创建Index时,需要特别指定index.store.type为bosfs,这样百度智能云Elasticsearch才会使用冷热分离的架构来管理Index。
1PUT /{index_name}
2{
3 "settings": {
4 "index.store.type": "bosfs"
5 }
6}在以上操作结束后,用户可以和访问普通Index一样来对冷热数据分离的Index进行写入、查询数据。
对已存在的Index启用冷热数据分离架构
对于之前已经建好的索引,也可以使用基于bos的冷热分离功能。
前提条件:完成BOS Bucket创建和配置,已经将BOS信息配置到BES。
操作说明:
首先关闭索引:
1POST /{index_name}/_close然后将store.type设置为bosfs :
1put /{index_name}/_settings
2{
3 "index.store.type": "bosfs"
4}再重新打开索引:
1POST /{index_name}/_open在以上操作结束后,就将此Index设置成了冷热数据分离的Index。
冷数据迁移的触发条件
冷热数据分离的Index中的数据在满足以下2种情况之一时,会触发数据迁移到BOS。
手动触发迁移
当这个Index中的数据不再写入,并且读取频率比较低的时候,用户可以把Index设置为Cold状态,手动触发数据迁移。设置方式如下:
1POST /_bpack/migrate/{index_name}/cold注意:Cold状态的Index为只读状态,不能再写入数据。已经置为Cold状态的Index,不可以再改为普通状态。
定时调度触发迁移
用户可以使用定时调度-索引置冷来触发迁移,在定时置冷任务执行后,Index会置为Cold,并触发数据迁移,效果与上文手动触发迁移一致。
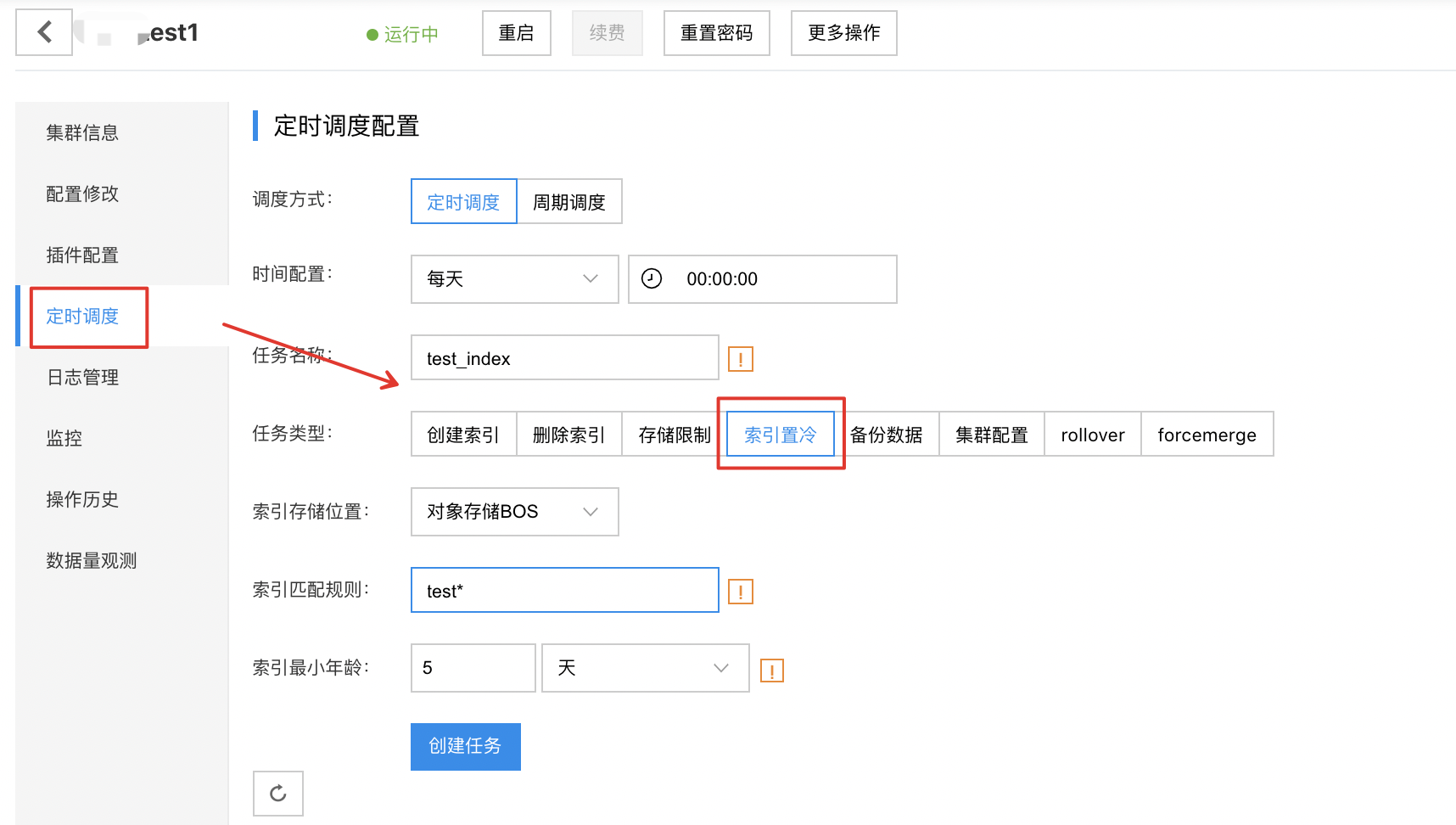
建议用户使用
手动触发迁移或定时调度触发迁移来进行索引置冷。
本地缓存淘汰策略
当本地磁盘使用率超过了缓存最大磁盘限制,本地数据会被删除。缓存最大磁盘限制默认为75%,用户可以通过修改设置项bpack.bosfs.cache.disk.limit来修改缓存最大磁盘限制,修改方式如下:
1PUT /_cluster/settings
2{
3 "persistent": {
4 "bpack.bosfs.cache.disk.limit" : "50%"
5 }
6}
7or
8PUT /_cluster/settings
9{
10 "persistent": {
11 "bpack.bosfs.cache.disk.limit" : "0.5"
12 }
13}本地缓存配置
数据置冷后,为了提升ES的查询性能,冷热分离架构将会缓存部分数据,减少对BOS的访问请求。在检索时,第一次获取数据会直接访问BOS,之后将获取到的数据缓存在本地,后续访问会先检查是否有缓存。
缓存的配置
仅在7.10.2版本支持
| 配置 | 说明 | 默认值 | 类型 |
|---|---|---|---|
| bpack.migrate.max_bytes_per_sec | 置冷数据时数据上传bos速率限制值 | 40m | 字符串 |
| bpack.bosfs.cache.custom_cache_names | 缓存系统支持多级缓存,分别用来缓存不同访问粒度的数据。此配置列出所有缓存的名字,即使不配置,系统也会默认有2个缓存,名字为default和dic。如果自定义配置,可以配置除default和dic外的其他缓存类型。 | ["default","dic"] | 字符串数组 |
| bpack.bosfs.cache.{cache_name}.expiry_time | 缓存中的文件在最后一次读或者写入后开始计时,在指定的时间后过期。使用TimeUnit格式表示,例如『10s』、『10m』、『3h』等,不可设置为小数值,如『1.5h』。 | 60m | 字符串 |
| bpack.bosfs.cache.{cache_name}.disk_limit | 缓存的最大容量。当缓存尝试加载数据时超过了缓存的最大容量限制,它将触发驱逐操作。该值可以设置为一个带有存储容量单位的值,例如『10kb』、『10mb』、『3g』等,不建议设置为小数值,如『1.5g』。 | disk的10% | 字符串 |
| bpack.bosfs.cache.{cache_name}.file.types | 文件缓存的文件后缀名。 | - | 字符串数组 |
| bpack.bosfs.cache.default.expiry_time | 默认文件缓存的过期时间 | 60m | 字符串 |
| bpack.bosfs.cache.default.disk_limit | 默认文件缓存的最大容量 | disk的30% | 字符串 |
| bpack.bosfs.cache.default.file.types | 默认文件缓存的文件后缀名。会缓存除其他缓存外的所有文件。 | - | 字符串数组 |
| bpack.bosfs.cache.dic.expiry_time | 默认文件缓存的过期时间 | 120m | 字符串 |
| bpack.bosfs.cache.dic.disk_limit | 默认文件缓存的最大容量 | disk的10% | 字符串 |
| bpack.bosfs.cache.dic.file.types | 默认文件缓存的文件后缀名。会缓存除其他缓存外的所有文件。 | ["tvx", "si", "tip", "tim", "tvb", "fdx", "doc", "dim"] | 字符串数组 |
数据观测
提供数据观测接口,方便使用者观察数据分布情况。
1、索引级观测接口
接口命令:
1GET /_bpack/migration/stats?v响应结果说明:
| 属性 | 说明 |
|---|---|
| index | 索引名称 |
| uuid | 索引uuid |
| status | bosfs类型索引的冷热状态 |
| active.shard | 索引活跃分片数 |
| finished.shard | 完成bos数据上传的分片数 |
| waiting.shard | 等待bos数据上传的分片数 |
| running.shard | 进行bos数据上传的分片数 |
| hot.data | 本地索引数据大小 |
| cold.data | bos上索引数据大小 |
| cache.data | 本地索引缓存数据大小 |
响应示例:

2、节点级观测接口
仅在7.10.2版本支持
接口命令:
1GET /_bpack/node/migration/stats?v响应结果说明:
| 属性 | 说明 |
|---|---|
| id | es节点id |
| ip | es节点ip |
| shards | 节点上bosfs索引的分片的总量 |
| hot.data | 本地索引数据大小 |
| cold.data | bos上索引数据大小 |
| cache.data | 本地索引缓存数据大小 |
响应示例:

3、集群级观测接口
仅在7.10.2版本支持
接口命令:
1GET /_bpack/cluster/migration/stats?v响应结果说明:
| 属性 | 说明 |
|---|---|
| shards | 节点上bosfs索引的分片的总量 |
| hot.data | 本地索引数据大小 |
| cold.data | bos上索引数据大小 |
| cache.data | 本地索引缓存数据大小 |
响应示例:

常用API
仅在7.10.2版本支持
1、冷索引预热
在初次收到搜索请求时,由于冷数据均保存在BOS,初次请求会存在较高延迟。为了避免这种情况,用户可以使用冷索引预热APi对目标索引进行预热,下载对应文件进入缓存,加快检索效率。
1POST /_bpack/bosfs/{index}/_pre_hot2、清理缓存
用户可以使用清理缓存APi手动清理缓存文件。
1POST /_bpack/bosfs/_clear_cache
2POST /_bpack/bosfs/{index}/_clear_cache性能测试
- 测试工具:Elasticsearch 官方的esrally工具
- 数据集:pmc
-
数据量:
- 总文档数:14,354,975
- 存储总量:约500GB
-
集群规格:
- 节点数:3
- shard数:12
- 副本数:0
针对不同的查询种类,分别设置一定的吞吐量进行压测,测试结果如下:
| 高性能云盘集群 | 冷热架构集群 | |||
|---|---|---|---|---|
| 节点配置 | cpu:8 内存:32G |
cpu:8 内存:32G |
||
| term查询 | 吞吐量(ops/s) | 397.25 | 396.06 | |
| 延迟(ms) | 90%分位值 | 32.04 | 16.11 | |
| 平均值 | 14.61 | 12.05 | ||
| 查询耗时(ms) | 90%分位值 | 12.05 | 13.70 | |
| 平均值 | 11.16 | 11.02 | ||
| phrase查询 | 吞吐量(ops/s) | 199.21 | 199.14 | |
| 延迟(ms) | 90%分位值 | 30.88 | 31.78 | |
| 平均值 | 25.83 | 27.25 | ||
| 查询耗时(ms) | 90%分位值 | 26.16 | 30.53 | |
| 平均值 | 24.24 | 26.27 | ||
| agg查询 | 吞吐量(ops/s) | 9.98 | 9.98 | |
| 延迟(ms) | 90%分位值 | 425.30 | 462.42 | |
| 平均值 | 388.61 | 428.12 | ||
| 查询耗时(ms) | 90%分位值 | 424.45 | 461.20 | |
| 平均值 | 387.63 | 426.92 | ||
| scroll查询 | 吞吐量(pages/s) | 37.64 | 37.65 | |
| 延迟(ms) | 90%分位值 | 396.26 | 350.29 | |
| 平均值 | 375.37 | 340.43 | ||
| 查询耗时(ms) | 90%分位值 | 394.86 | 348.52 | |
| 平均值 | 373.68 | 338.66 | ||
结论
在集群配置相同的情况下,在进行各种查询时,冷热数据架构的耗时与高性能云盘查询耗时基本持平。其中,在term查询和scroll查询时,冷热数据架构的查询性能更高。
价格方面,冷热数据架构使用BOS作为存储介质,单价比高性能云盘存储低很多,而且是按量付费,无须提前创建存储容量。
因此,冷热数据架构可以做到更好的做到降本增效。
常见问题
-
Q:已经置为
bosfs的Index还能改为其他的存储类型(如hybridfs、niofs等)吗?A:如果改为其他存储类型,由于数据存储目录不同,数据将失效。所以不可以改变为其他存储类型。
-
Q:对于已经存在的Index可以启用基于BOS的冷热分离结构吗?
A:可以,操作方式如上文
《对已存在的Index启用冷热数据分离架构》章节。 -
Q:已经置为Cold状态的Index还能改回普通状态吗?
A:不可以。且Cold状态的Index是只读状态,不能再写入数据了。
-
Q:没有设置BOS信息,或BOS信息有误,可以创建
bosfs的Index吗?A:可以创建成功,但Index不可用。更正BOS信息后,需要重新创建索引。
评价此篇文章