
基于ELK构建日志分析系统
介绍
日志是一个系统不可缺少的组成部分,日志记录系统产生的各种行为,基于日志信息可以对系统进行问题排查,性能优化,安全分析等工作。 使用ELK(Elasticsearch、Logstash、Kibana) 结合Filebeat与Kafka构建日志分析系统,可以方便的对日志数据进行采集解析存储,以及近实时的查询分析。
各组件在日志系统中的职责与关系如下所示:

- Filebeat:采集原始日志数据,输出数据到Kafka;
- Kafka:作为消息队列,存储原始日志数据;
- Logstash:消费Kafka中数据,解析过滤后,将其存储到Elasticsearch中;
- Elasticsearch:存储用于分析的日志数据,并提供查询、聚合的底层能力;
- Kibana:提供日志分析的可视化界面;
操作流程:
-
包括:创建百度Elasticsearch(简称BES)集群、Kibana服务,安装Filebeat、Logstash、Kafka。
-
配置Filebeat的input为系统日志,output为Kafka,将日志数据采集到Kafka的指定topic中。
-
配置Logstash的input为Kafka,output为BES,使用Logstash消费topic中的数据并传输到BES中。
-
在消息队列Kafka中查看日志数据的消费的状态,验证日志数据是否采集成功。
-
在Kibana控制台的Discover页面,查询采集的日志数据。
环境准备
-
创建BES集群
参考集群创建中的内容,完成BES集群的创建。
本文档中创建的BES集群选择7.4.2版本,Filebeat组件、Logstash组件使用的也是7.4.2版本。
-
创建Kibana服务
在完成BES集群创建后,除了已购买的BES节点,默认会附赠一个单节点的Kibana服务(Kibana节点支持按需自定义配置),如图所示:
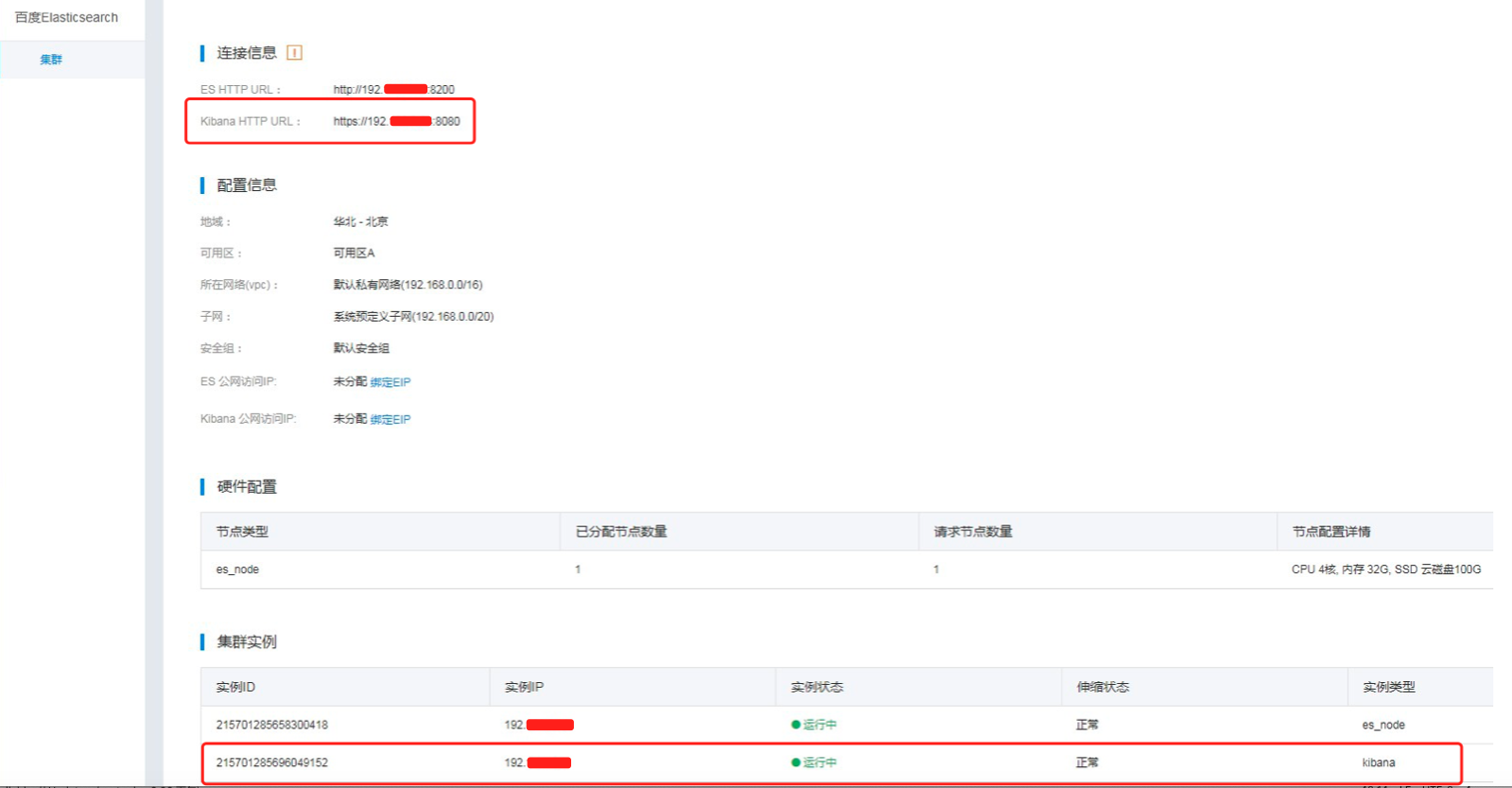
通过上图连接信息中所示的Kibana HTTP URL可以直接访问Kibana服务。
Kibana用户名密码与BES服务的用户名密码相同,详见账号使用说明
-
安装Filebeat
下载7.4.2的oss版本Filebeat;
Plain Text1wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-oss-7.4.2-linux-x86_64.tar.gz解压安装Filebeat;
Plain Text1tar -zxvf filebeat-oss-7.4.2-linux-x86_64.tar.gz -
安装Logstash
下载7.4.2的oss版本Logstash;
Plain Text1wget https://artifacts.elastic.co/downloads/logstash/logstash-oss-7.4.2.tar.gz解压安装Logstash;
Plain Text1tar -zxvf logstash-oss-7.4.2.tar.gz -
安装、配置Kafka服务
5.1 下载Zookeeper(Kafka服务依赖Zookeeper);
Plain Text1wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz5.2 解压安装Zookeeper;
Plain Text1tar -zxvf apache-zookeeper-3.6.4-bin.tar.gz5.3 配置Zookeeper;
Plain Text1vi conf/zoo.cfgzoo.cfg内容如下所示:
Plain Text1tickTime=2000 2dataDir=/your_path/apache-zookeeper-3.6.4-bin/data 3clientPort=2181 4initLimit=5 5syncLimit=2 6admin.serverPort=8888配置参数说明,如下所示:
参数名称 参数说明 tickTime 服务器之间或客户端与服务器之间维持心跳的时间间隔 dataDir 数据文件目录 clientPort 客户端连接端口 initLimit Leader-Follower初始通信时限 syncLimit Leader-Follower同步通信时限 admin.serverPort 内置Jetty绑定的port 5.4 启动Zookeeper;
Plain Text1bin/zkServer.sh start5.5 下载Kafka;
Plain Text1wget https://archive.apache.org/dist/kafka/2.0.1/kafka_2.12-2.0.1.tgz5.6 解压安装Kafka;
Plain Text1tar -zxvf kafka_2.12-2.0.1.tgz5.7 配置Kafka;
Plain Text1cd kafka_2.12-2.0.1 2vi config/server.propertiesserver.properties内容如下所示:
Plain Text1broker.id=0 2zookeeper.connect=localhost:2181配置参数说明,如下所示:
参数名称 参数说明 broker.id Kafka集群实例的唯一标识 zookeeper.connect Zookeeper的连接地址 5.8 启动Kafka;
Plain Text1bin/kafka-server-start.sh config/server.properties5.9 创建名称为
logdata的 topic,用于接收采集数据,命令示例如下所示:Plain Text1bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 2 --partitions 20 --topic logdata命令参数说明,如下所示:
参数名称 参数说明 zookeeper Zookeeper的连接地址 topic topic的名称 replication-factor topic的副本数 partitions topic的分区数量
配置Filebeat
1.创建Filebeat采集配置文件;
1 cd filebeat-oss-7.4.2-linux-x86_64
2 vi filebeat.kafka.ymlfilebeat.kafka.yml内容如下:
1 filebeat.inputs:
2 - type: log
3 enabled: true
4 paths:
5 - /your_path/*.log
6
7 output.kafka:
8 hosts: ["**.**.**.**:9092"]
9 topic: logdata
10 version: 2.0.1配置参数说明,如下所示:
| 参数名称 | 参数说明 |
|---|---|
| type | 输入类型,设置为log,表示输入源为日志 |
| enabled | input处理器的开关 |
| paths | 需要监控的日志文件的路径 |
| hosts | 消息队列Kafka的地址 |
| topic | 日志输出到消息队列Kafka的topic |
| version | Kafka的版本 |
2.启动Filebeat;
1./filebeat -e -c filebeat.kafka.yml 配置Logstash
1.创建配置文件logstash.conf;
1cd logstash-oss-7.4.2
2vi logstash.conflogstash.conf内容如下:
1input {
2 kafka {
3 bootstrap_servers => "127.0.0.1:9092"
4 group_id => "log-data"
5 topics => ["logdata"]
6 codec => json
7 }
8}
9filter {
10}
11output {
12 elasticsearch {
13 hosts => "http://es_ip:es_http_port"
14 user =>"your username"
15 password =>"your password"
16 index => "kafka‐%{+YYYY.MM.dd}"
17 }
18}配置参数说明,如下所示:
| 参数名称 | 参数说明 |
|---|---|
| bootstrap_servers | Kafka的地址 |
| group_id | Kafka消费者组id |
| topics | Kafka的topic名称 |
| codec | 数据格式 |
| hosts | BES服务地址 |
| user | BES账号 |
| password | BES账号的密码 |
| index | 数据写入的索引 |
2.启动Logstash;
1bin/logstash -f logstash.conf 更多Logstash的使用说明,详见Logstash使用指南。
查看日志消费状态
使用如下命令查看消费状态;
1bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group log-data --describe命令参数说明,如下所示:
| 参数名称 | 参数说明 |
|---|---|
| bootstrap_servers | Kafka的地址 |
| group | Kafka消费者组 |
执行结果如下所示:
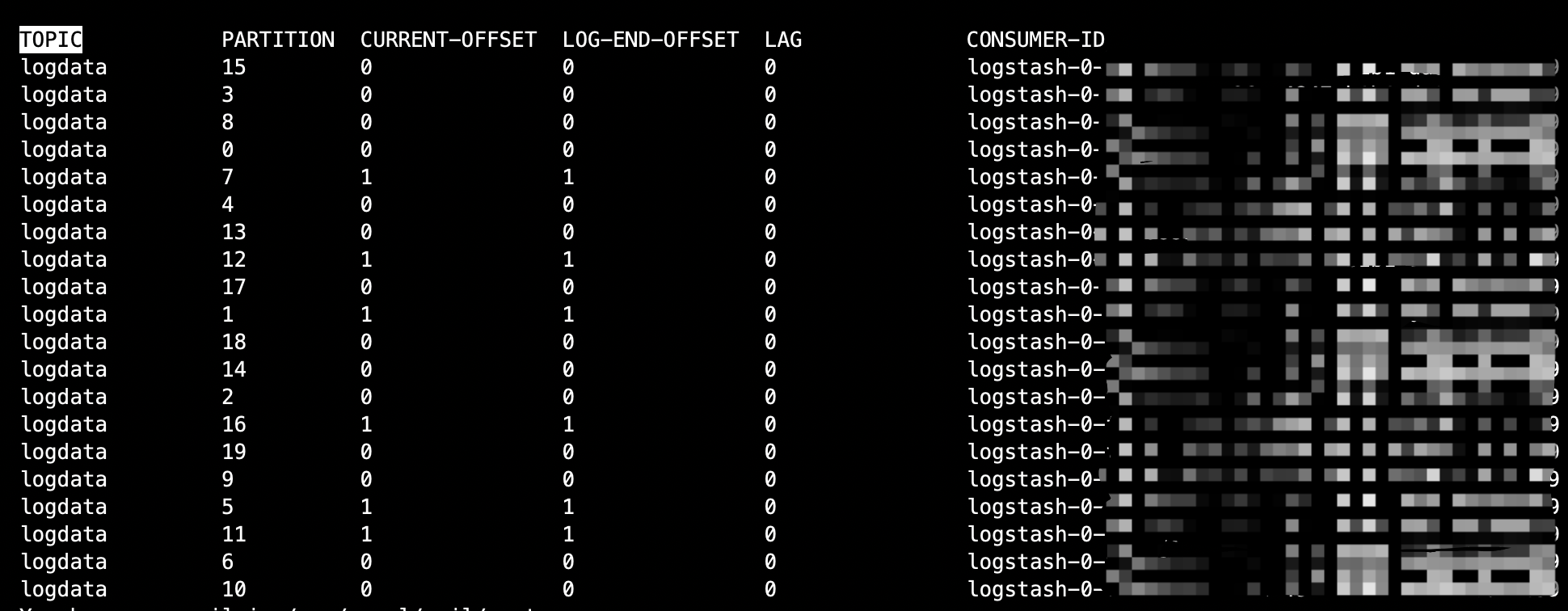
结果属性说明,如下所示:
| 参数名称 | 参数说明 |
|---|---|
| topic | Kafka的topic名称 |
| partition | topic的分区id |
| current-offset | consumer消费的具体位移 |
| log-end-offset | partition的最高位移 |
| lag | 堆积量 |
| consumer-id | 消费者id |
通过Kibana查看日志数据
完成以下的配置后,即可通过Kibana查看日志数据。
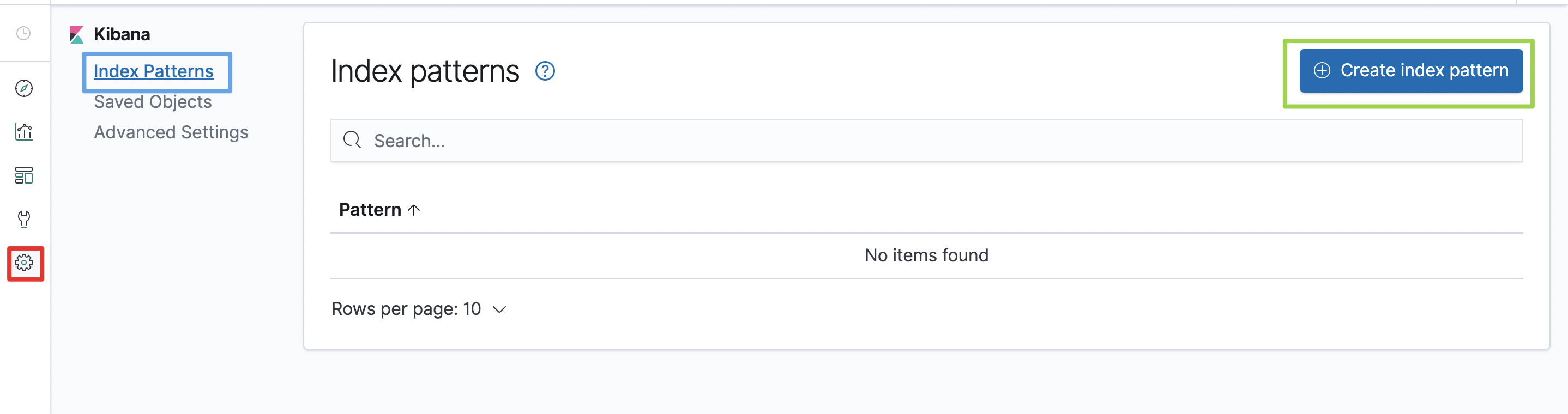
1.创建索引模式
在左侧导航栏,点击Management(下图中红框位置)后,在Kibana区域点击Index Patterns(下图中蓝框位置),然后再点击Create index pattern按钮(下图绿框位置)
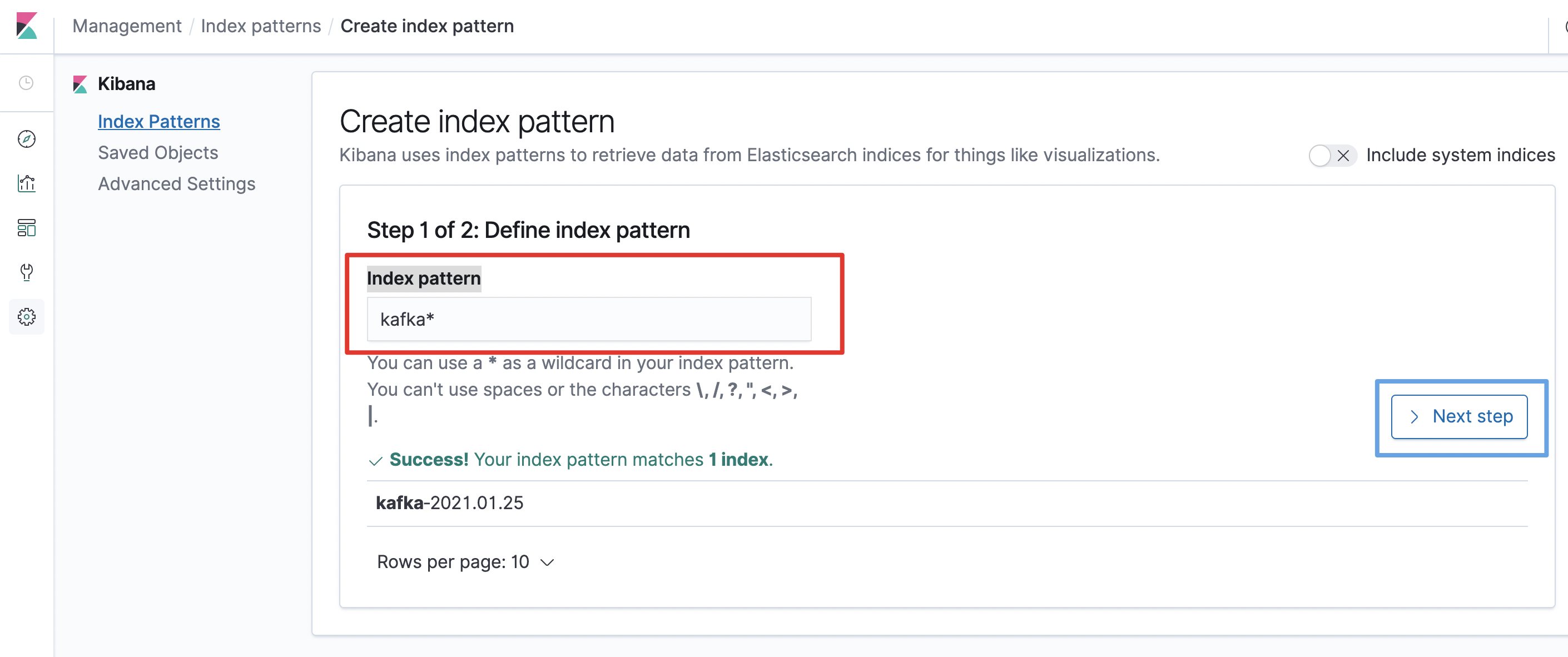
在Index pattern处(下图红框位置)填入kafka*,然后点击点击Next Step按钮(下图中蓝框位置)
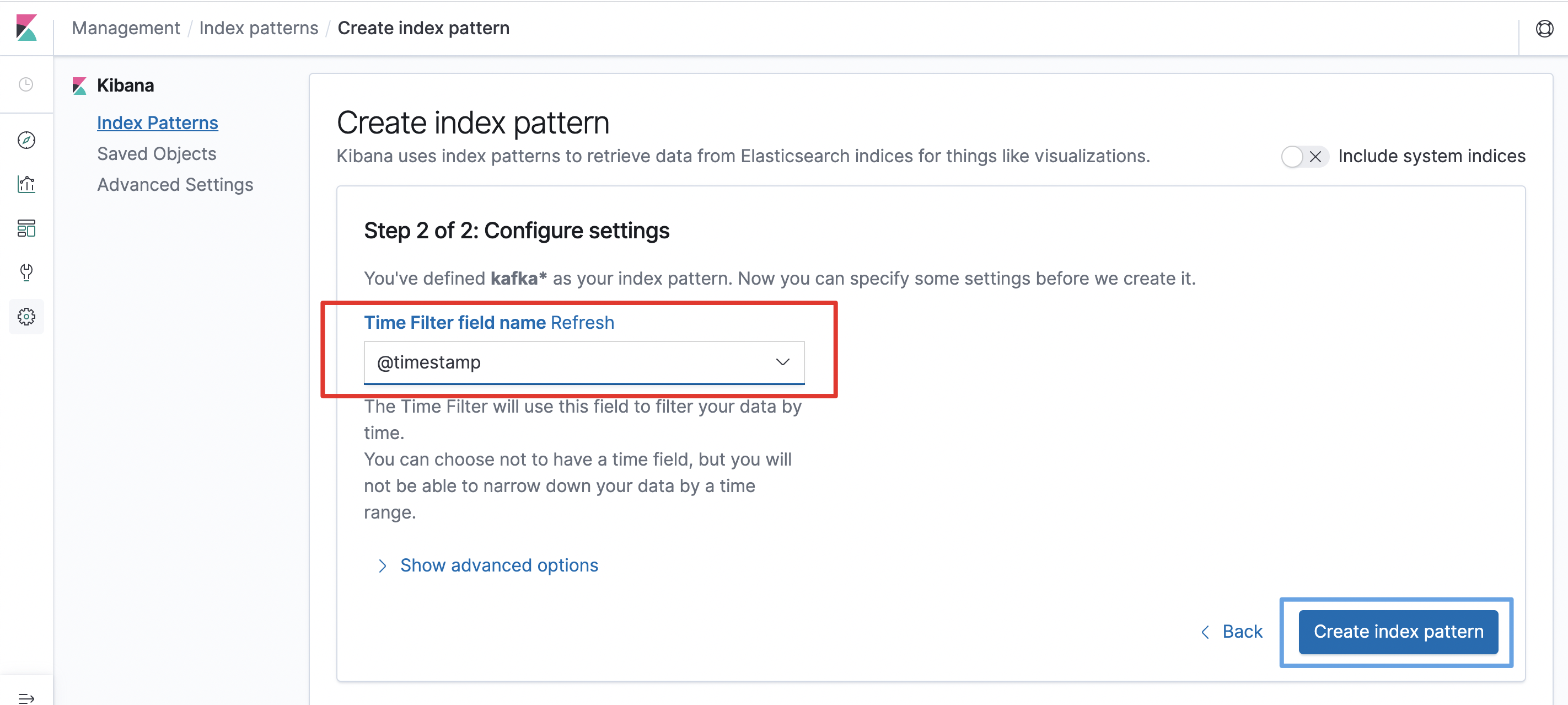
为Time Filter field name选择@timestamp字段(下图中红框位置),然后点击Create index pattern按钮(下图中蓝框位置)
2.查看日志数据
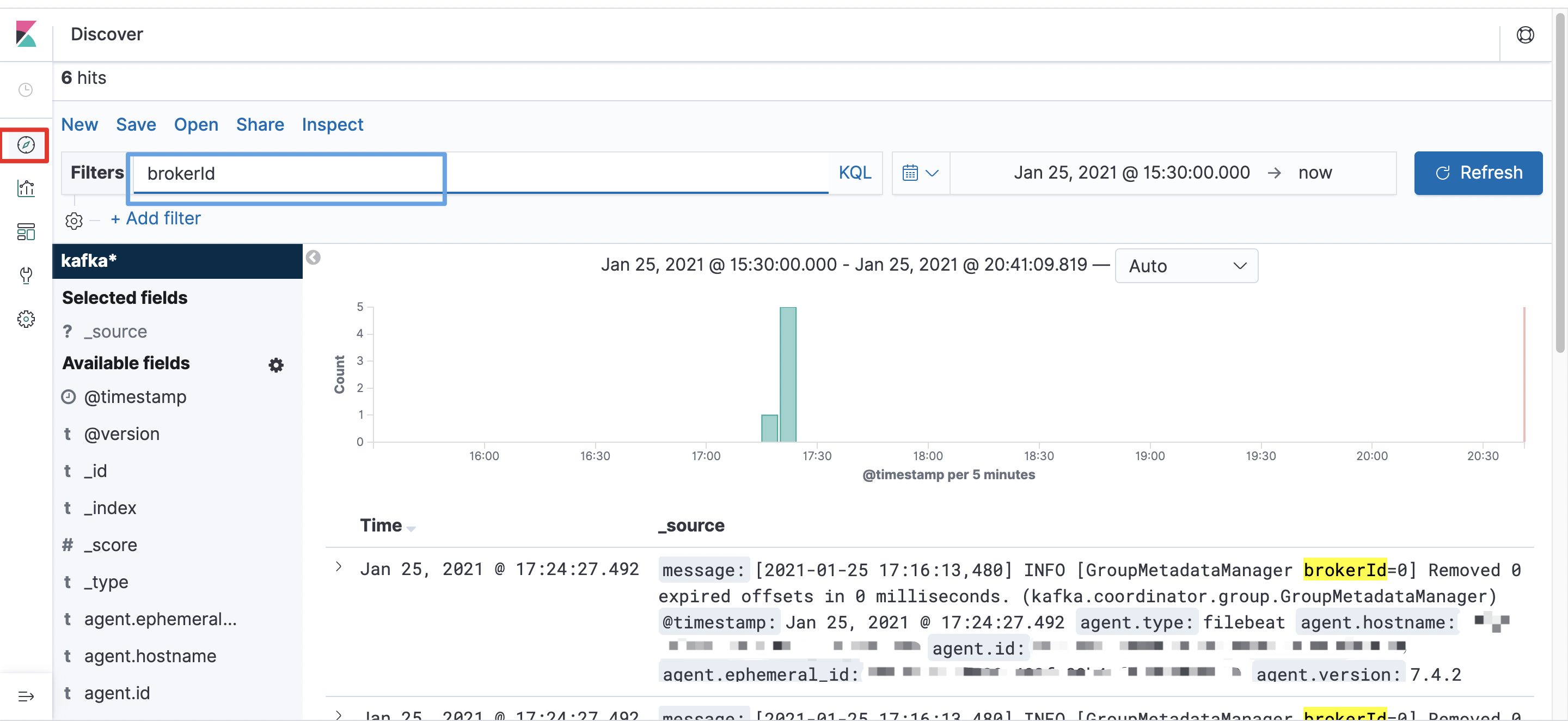
在左侧导航栏,点击Discover(下图中红框位置)后,即可以查询日志数据
更多Kibana的使用说明,详见Kibana使用指南中的内容。
评价此篇文章