
监控查看及指标说明
百度智能云Elasticsearch 对运行中的 BES 集群,提供了多项监控指标,用以监测集群的运行情况。用户可以根据这些指标实时了解集群服务的运行状况,针对可能存在的风险及时处理,保障集群的稳定运行。本文为您介绍通过 BES 控制台查看集群监控的操作。
操作步骤
1.登录百度智能云 Elasticsearch 控制台。
2.在集群列表中点击目标集群ID。
3.在集群信息页左侧的导航栏中选择监控。
BES提供两大类指标,集群监控指标和节点监控指标。默认展示集群监控指标。可以查看集群整体运行情况。上方tab可切换为节点监控指标,查看集群内各节点的运行情况和性能指标。
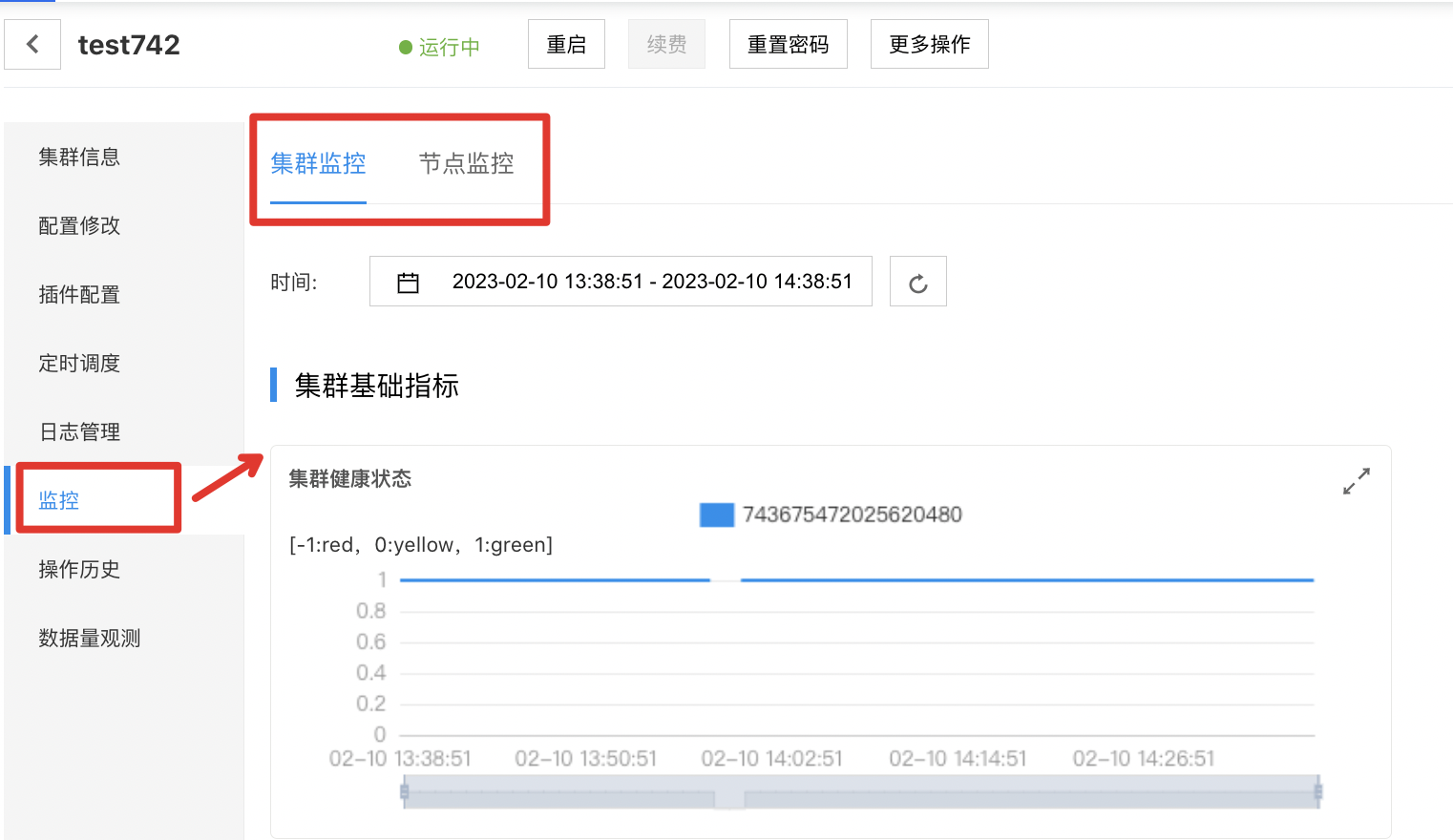
集群监控
在集群监控页,可以看到集群的监控数据信息,可通过选择不同的时间范围查看集群基础指标、集群性能指标和负载均衡指标。
集群基础指标:集群健康状态、集群总分片数、集群数据节点平均分片数、集群未分配分片数等

集群性能指标:集群写入QPS、集群查询QPS、集群写入增量、集群查询增量、集群平均写入耗时、集群平均查询耗时等。
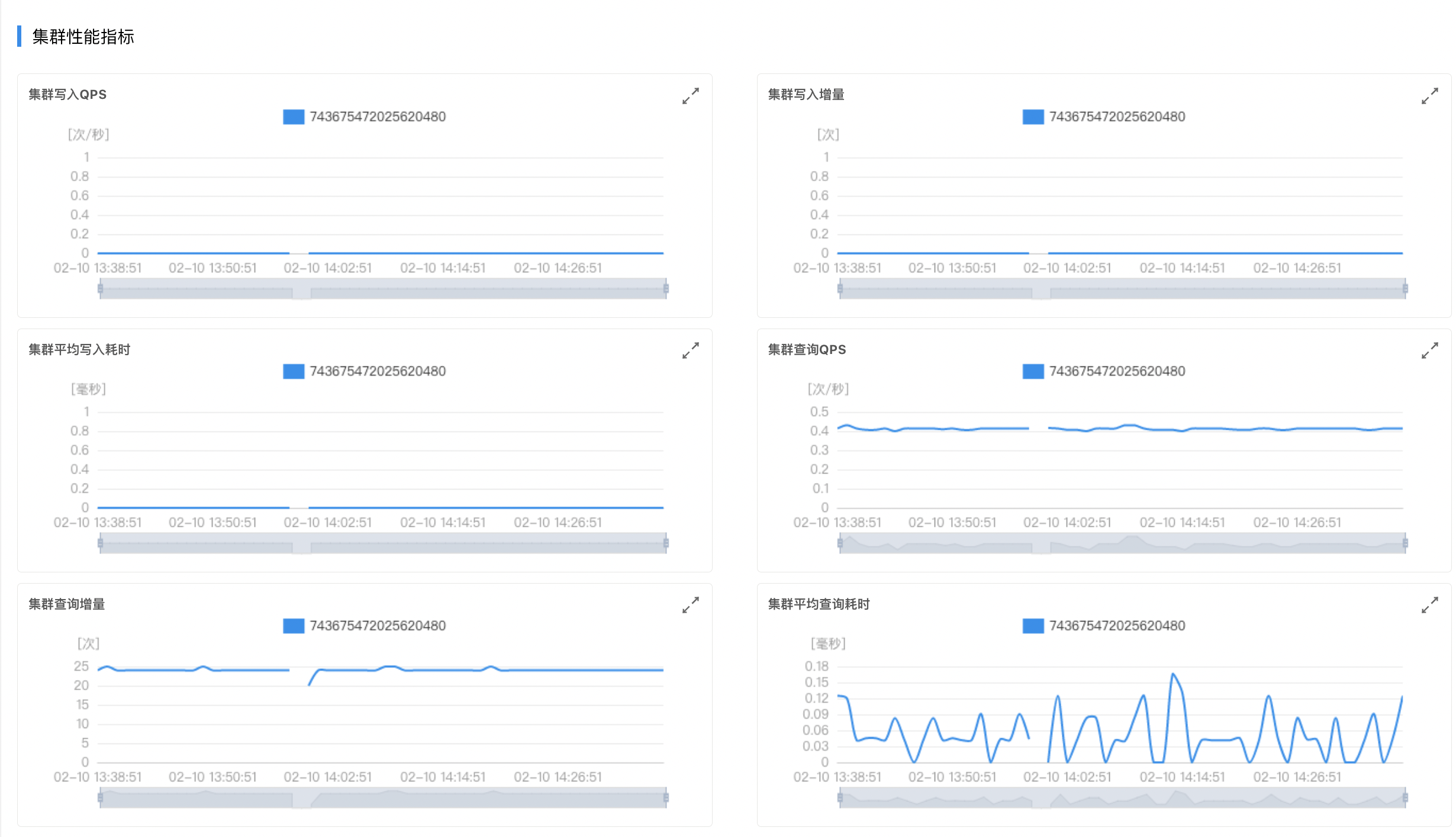
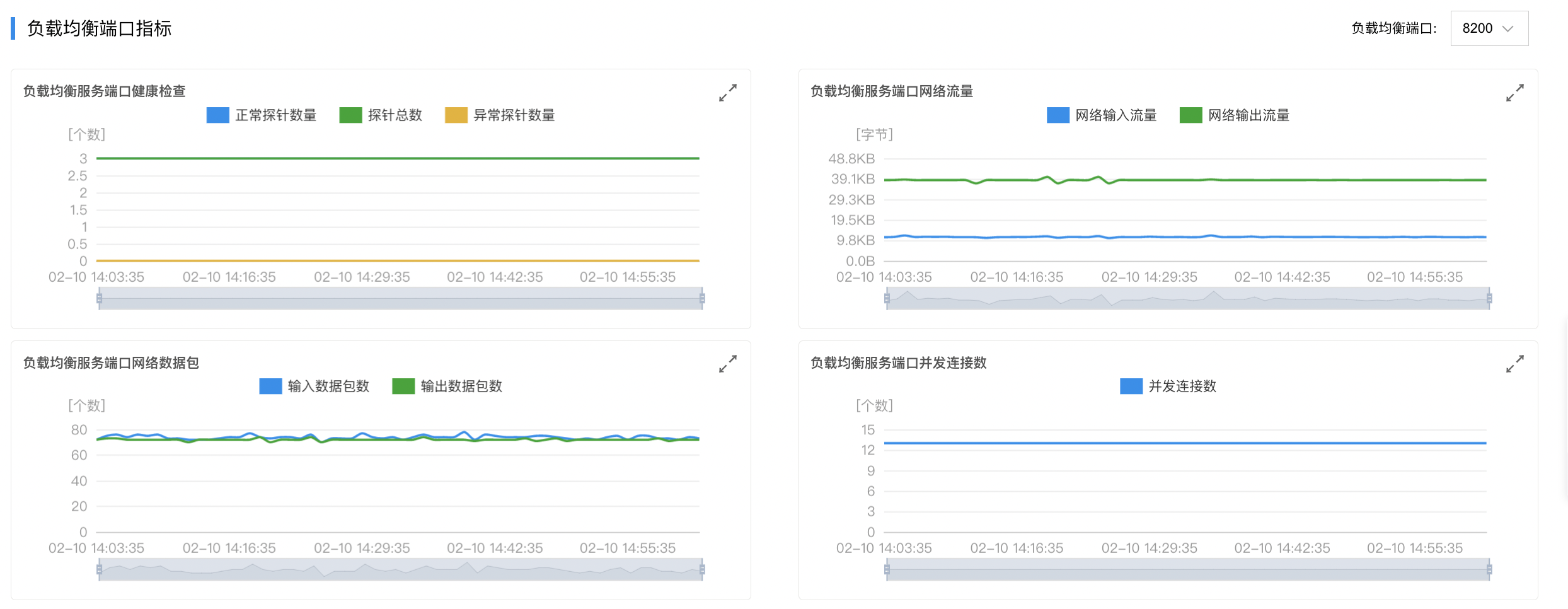
负载均衡端口指标:负载均衡服务端口健康检查、负载均衡服务端口网络流量、负载均衡服务端口网络数据包和负载均衡服务端口并发连接数。
页面右上角可跳转到BCM进行告警策略设置。
节点监控
节点列表
展示集群各个节点基本信息和部分运行指标。
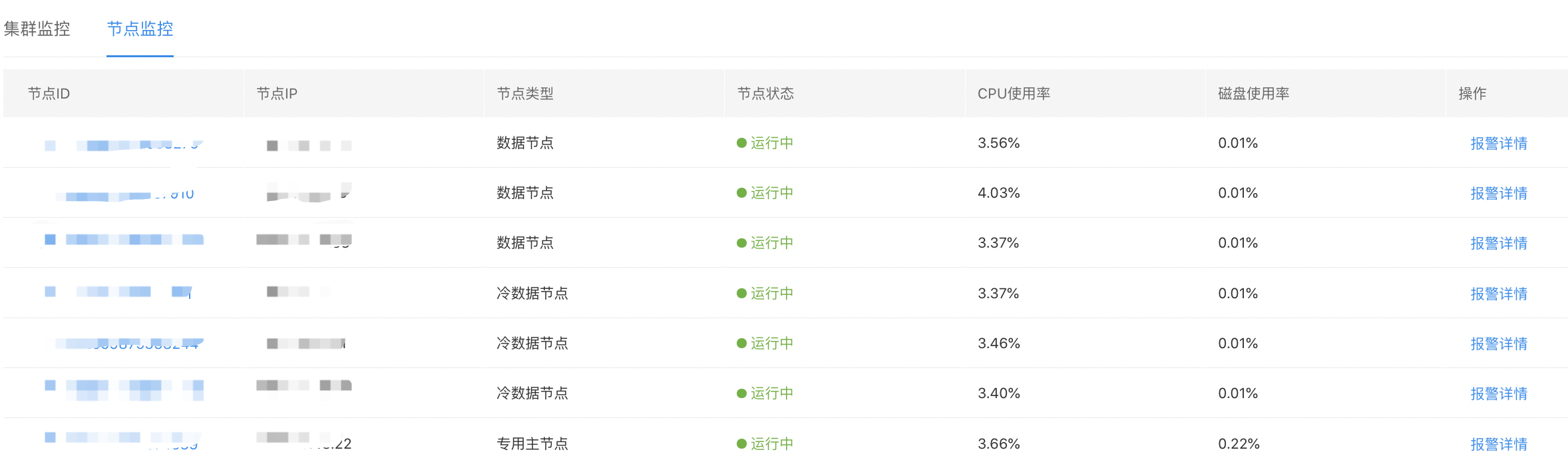
操作列【报警详情】按钮,点击跳转BCM配置对应节点的告警策略配置。
节点状态指标
节点列表页,点击节点ID,进入监控指标页,查看节点各项指标的详细运行情况。包括服务器性能指标和节点性能指标。
支持选择不同的相对和绝对时间范围、节点ID和节点类型查看指标。
服务器性能指标:CPU使用率、内存使用量、磁盘空间使用量、磁盘使用率、磁盘写iops、磁盘读iops、磁盘写流量、磁盘读流量、load_1m、IO Util(平均值和最大值)等。
节点性能指标:JVM年轻代使用率、JVM老年代使用率、FullGC次数、Field Data内存使用、search线程池队排队任务数、write线程池队排队任务数、request cache、query cache、HeapMemory使用率、段内存等。
部分指标含义及说明
对部分集群指标和节点指标进行说明。具体指标含义说明以及告警阈值建议如下
注意,为便于用户配置合理的监控指标项告警,在此分为3档提供推荐配置阈值:
★★★为强烈推荐用户去配置此监控项的告警
★★和★推荐程度逐次递减
没有★的指标项,用户可视具体业务情况而定
集群指标说明
指标的统计周期均为60秒,即每60秒对集群的指标采集1次。具体各指标含义说明如下:
| 指标名称 | 指标说明 | 推荐配置告警 | 建议告警阈值-低风险 | 建议告警阈值-高风险 |
|---|---|---|---|---|
| 集群健康状态 | BES集群的健康状态。 "1" 表示 green ,表示所有的主分片和副本分片都可用,集群处于最健康状态。 "0" 表示 yellow , 表示所有的主分片均可用,但部分副本分片未分配(unassigned)。此时搜索结果仍然是完整的。但集群的高可用性在一定程度上受到影响。在集群健康状态变为 yellow 后,建议及时调查和定位问题并修复,防止数据丢失。 "-1" 表示 red ,集群异常状态,表示该集群中某个或某几个索引的主分片未分配(unassigned)。在集群健康状态变为 red 后,应及时定位异常分片,并进行修复。 "-2" 表示 gray ,表示未知状态。 |
配置告警推荐程度:★★★ 直接反映了集群可用性,需要高度关注 |
1分钟最大值<=0 | 1分钟最大值<=-1 |
| 集群总分片数 | BES集群已分配shard总数。 | |||
| 集群数据节点平均分片数 | BES集群已分配shard总数/数据节点总数。阈值由用户自行设定,建议不超过1000,超过阈值后请及时清理数据。 | 配置告警推荐程度:★★ 达到限制后无法创建新索引,ES官方推荐数据节点的分片数不超过1000个,如果调整过设置,需要根据设置调整告警阈值 |
1分钟最大值>=800 | 1分钟最大值>=1000 |
| 集群未分配分片数 | BES集群未分配的分片总数。 | |||
| 集群写入QPS | BES集群在统计周期内(60秒)每秒写入文档的数量的平均值。 如果在1秒内,客户端向BES集群发送1个文档的写入请求,对应写入QPS为1。 |
|||
| 集群查询QPS | BES集群在统计周期内(60秒)每秒query的数量的平均值。查询QPS数量与待查询索引的分片个数有关,客户端的1个查询可能涉及多个分片。 如果在1秒内,客户端向BES集群发送1个查询请求,被查询的分片有3个,对应查询query的QPS为3。 |
|||
| 集群平均写入耗时 | BES集群在统计周期内(60秒)所有节点单次 index 请求耗时的平均值 | |||
| 集群平均查询耗时 | BES集群在统计周期内(60秒)所有节点单次查询请求耗时的平均值。 | |||
| 集群写入增量 | BES集群在统计周期内(60秒)写入文档的增加的数量。集群写入增量和副本数相关。 如果用户设置1个副本,在60秒内,客户端共向BES集群发送1个文档的写入请求,对应写入增量为2. |
|||
| 集群查询增量 | BES集群在统计周期内(60秒)查询query的数量。集群查询增量与待查询索引的分片个数有关,客户端的1个查询可能涉及多个分片。 如果在60秒内,客户端共向BES集群发送1个查询请求,被查询的分片有3个,对应查询query增量为3。 |
|||
| 集群写入拒绝率 | BES集群在统计周期内(60秒),被拒绝的写入请求数/总写入请求数。具体计算规则:根据 GET /_bpack/metrics/nodes 接口,统计总写入请求数和被拒绝的写入请求数。总写入请求数是es的action层接收到的总体写入请求数,返回状态码为429的作为拒绝数。取相邻两次记录的差值,然后汇聚计算每个统计周期内的绝对值。 说明:2024年8月20日之后新创建的集群默认支持统计该指标,存量集群需要安装对应插件(baidu-metrics),从而支持该指标统计。插件安装详见文档。 |
配置告警推荐程度:★ 有数据写入拒绝代表写入压力大 |
1分钟最大值>0% | 1分钟最大值>10% |
| 集群查询拒绝率 | BES集群群在统计周期内(60秒),被拒绝的查询请求数/总查询请求数。具体计算规则:根据 GET /_bpack/metrics/nodes 接口,统计总查询请求数和被拒绝的查询请求数。总查询请求数是es的action层接收到的总体查询请求数,返回状态码为429的作为拒绝数。取相邻两次记录的差值,然后汇聚计算每个统计周期内的绝对值。 说明:2024年8月20日之后新创建的集群默认支持统计该指标,存量集群需要安装对应插件(baidu-metrics),从而支持该指标统计。插件安装详见文档。 |
配置告警推荐程度:★ 有数据查询拒绝代表查询压力大 |
1分钟最大值>0% | 1分钟最大值>10% |
| 集群写入失败率 | BES集群群在统计周期内(60秒),失败的写入请求数量/总写入请求数。具体计算规则:根据 GET /_bpack/metrics/nodes 接口,统计总写入请求数和失败的写入请求数。总写入请求数是es的action层接收到的总体写入请求数,所有返回状态码非2XX的作为失败数。取相邻两次记录的差值,然后汇聚计算每个统计周期内的绝对值。 说明:2024年8月20日之后新创建的集群默认支持统计该指标,存量集群需要安装对应插件(baidu-metrics),从而支持该指标统计。插件安装详见文档。 |
★★ 数据写入有失败情况 |
1分钟最大值>0% | 1分钟最大值>10% |
| 集群查询失败率 | BES集群群在统计周期内(60秒),失败的查询请求数量/总查询请求数。具体计算规则:根据 GET /_bpack/metrics/nodes 接口,统计总查询请求数和失败的查询请求数。总查询请求数是es的action层接收到的总体查询请求数,所有返回状态码非2XX的作为失败数。取相邻两次记录的差值,然后汇聚计算每个统计周期内的绝对值。 说明:2024年8月20日之后新创建的集群默认支持统计该指标,存量集群需要安装对应插件(baidu-metrics),从而支持该指标统计。插件安装详见文档。 |
★★ 数据查询有失败情况 |
1分钟最大值>0% | 1分钟最大值>10% |
| 负载均衡服务端口健康检查 | 包含3个指标,该集群的负载均衡(BLB)实例总数、正常实例数和异常实例数量。 | ★★ 存在异常探针数量代表不能通过BLB正常访问的BES节点数量 |
5分钟异常探针数量平均值>0 | 5分钟异常探针数量平均值>1 |
| 负载均衡服务端口网络流量 | 包含2个指标,负载均衡端口的网络输入流量和网络输出流量。可参考业务实际流量对指标进行观测。 | |||
| 负载均衡服务端口网络数据包 | 包含2个指标,负载均衡端口的输入数据包数和输出数据包数。可参考业务收发数据包数量对指标进行观测。 | |||
| 负载均衡服务端口并发连接数 | BES负载均衡端口的并发连接数。 |
节点指标说明
指标的统计周期均为60秒,即每60秒对集群的指标采集1次。具体各指标含义说明以及告警阈值建议如下
注意,为便于用户配置合理的监控指标项告警,在此分为3档提供推荐配置阈值:
★★★为强烈推荐用户去配置此监控项的告警
★★和★推荐程度逐次递减
没有★的指标项,用户可视具体业务情况而定
| 指标名称 | 指标说明 | 推荐配置告警 | 建议告警阈值-低风险 | 建议告警阈值-高风险 |
|---|---|---|---|---|
| 节点状态 | 统计周期内(60秒),节点的运行状态。监控指标中的节点状态和集群信息-集群架构图中的节点状态一致。 "1" 对应颜色为 green 绿色 ,表示节点正常运行中。 "0" 对应颜色为 blue 蓝色,表示节点正在生效中,生效中的节点不可进行暂停和启动等操作。节点启停功能详见节点启停文档。 "-1" 对应颜色为 gray 灰色,表示节点已经停止,已经停止的节点不可进行暂停的操作,可以进行节点启动操作。 "-2" 对应颜色为 orange 橙色,表示节点未知状态,未知状态的节点不可以进行暂停和启动等操作。 |
★★★ | 10分钟最大值<=0 | 10分钟最大值<=-1 |
| CPU使用率 | 统计周期内(60秒),节点的CPU使用率百分比。 | ★★ | 5分钟平均值>80% | 5分钟平均值>90% |
| 内存使用量 | 统计周期内(60秒),节点的内存(mem)使用量。 | |||
| 磁盘空间使用量 | 统计周期内(60秒),节点的磁盘使用量。 | |||
| 磁盘空间使用率 | 统计周期内(60秒),节点的磁盘使用率。 | ★★★ 磁盘使用率超过es的水位线可能影响索引创建、数据写入 |
1分钟最大值>75% | 1分钟最大值>85% |
| 磁盘写iops | 统计周期内(60秒),磁盘每秒io写次数(次/秒) | |||
| 磁盘读iops | 统计周期内(60秒),磁盘每秒io读次数(次/秒) | |||
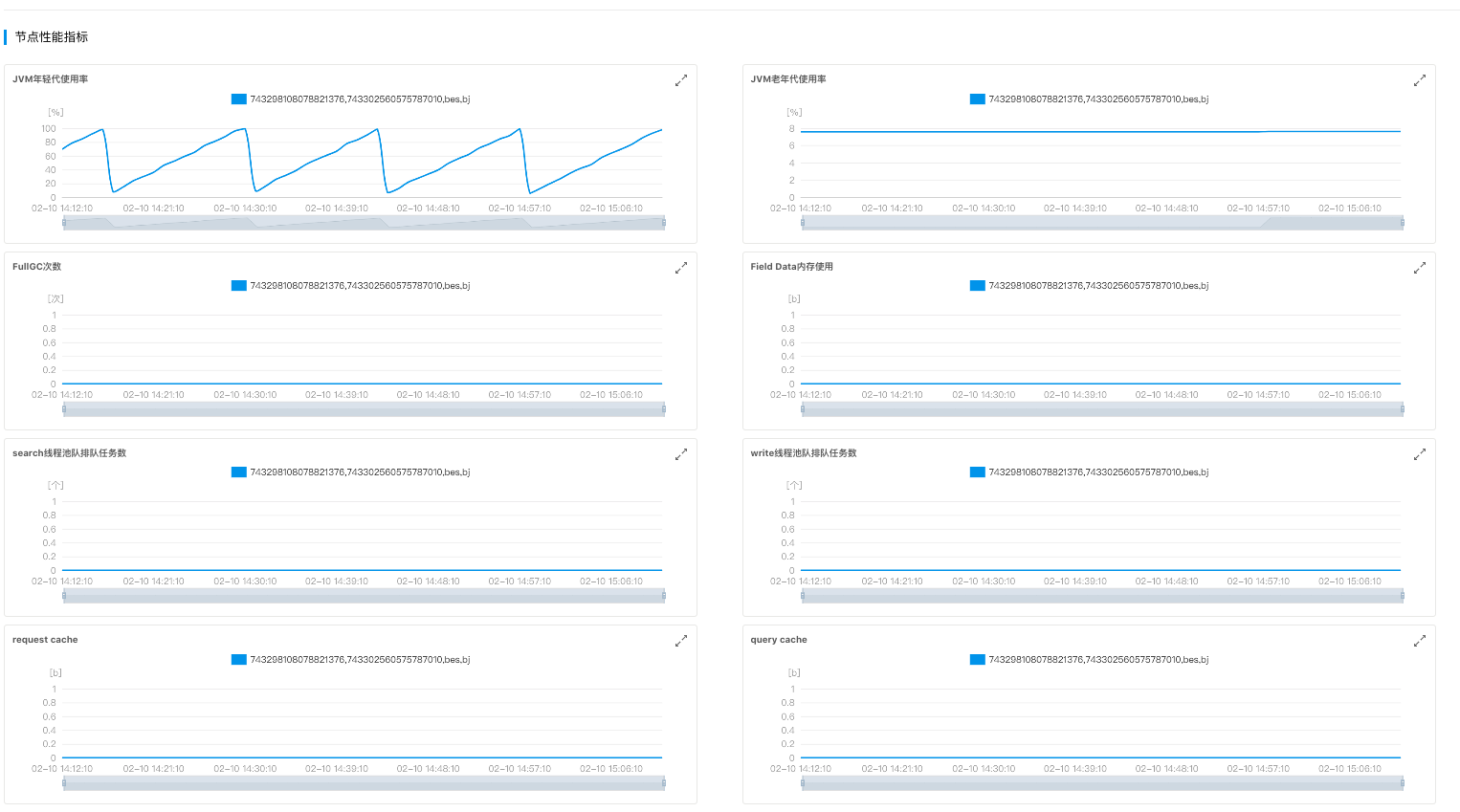
| 磁盘写流量 | 统计周期内(60秒),磁盘每秒io写速率(Kb/秒) | ★ 可视具体磁盘类型而定。各种磁盘的吞吐(见附录) |
||
| 磁盘读流量 | 统计周期内(60秒),磁盘每秒io读速率(Kb/秒) | ★ 可视具体磁盘类型而定。各种磁盘的吞吐(见附录) |
||
| load_1m | 在统计周期内(60秒),节点在1分钟内的负载情况,表示各节点的系统繁忙程度。该指标的正常数值,应该低于对应节点规格的CPU核数。load_1m 过高时,建议降低集群负载或调大集群节点规格。 | ★★ | 10分钟平均值>节点cpu核数*0.7 | 10分钟平均值>节点cpu核数*1.5 |
| IO Util | 统计周期内(60秒),节点的IO使用率。此指标提供平均值和最大值,平均值表示60秒内节点IO使用率的平均值,最大值表示60秒内节点IO使用率的最大值。默认展示平均值,可切换成最大值。建议将报警阈值设置在90%。此指标的最大值可能出现毛刺现象,建议拉长报警间隔,持续观测。 | ★ | 5分钟IOUtilAvg平均值>80% | 5分钟IOUtilAvg平均值>90% |
| JVM年轻代使用率 | 统计周期内(60秒),节点的 JVM 年轻代内存使用率。 | |||
| JVM老年代使用率 | 统计周期内(60秒),节点的 JVM 老年代内存使用率。 | ★ | 1分钟最大值>80% | 1分钟最大值>90% |
| FullGC次数 | 统计周期内(60秒),节点的gc总次数。 | ★★ 频繁GC会影响集群性能和稳定性 |
10分钟和值>=2 | 10分钟和值>=5 |
| Field Data内存使用 | 统计周期内(60秒),节点的fielddata内存占用情况,监控曲线越高,说明堆内存存在大量的fielddata数据缓存,过大的fielddata内存占用会触发fielddata内存熔断,影响集群稳定性。 | |||
| search线程池队排队任务数 | 统计周期内(60秒),search线程池中的队列数。 | ★ 可视具体线程池大小而定 |
||
| write线程池队排队任务数 | 统计周期内(60秒),write线程池中的队列数。 | ★ 可视具体线程池大小而定 |
||
| request cache | 统计周期内(60秒),request 缓存大小。 | |||
| query cache | 统计周期内(60秒),query 缓存大小。 | |||
| HeapMemory使用率 | 统计周期内(60秒),节点的HeapMemory使用率百分比。当HeapMemory使用率较高或存在较大的内存对象时,会影响集群服务,也会自动触发gc操作。建议报警阈值为75%。 | ★★ | 1分钟最大值>75% | 1分钟最大值>85% |
| 段内存 | 统计周期内(60秒),为了提高搜索效率而缓存在内存中的段的数据。建议报警阈值为(堆内存 * 30%)。 |
附录
磁盘容量为512GB时,各类磁盘吞吐对比,详细可参考 https://cloud.baidu.com/doc/CDS/s/hketf8fyr
评价此篇文章