
基于CCR实现多集群跨地域高可用
一、CCR功能介绍
功能概述:
CCR(Cross Cluster Replication,跨集群复制)是BES(百度Elasticsearch)高效的数据同步解决方案,旨在提高数据的可用性、降低访问延迟,并实现数据的灵活迁移。
CCR功能以数据订阅的方式工作,一个集群的数据可以被多个集群订阅,即可以被复制到多个集群上。 在CCR中有两种角色:Leader和Follower,Leader表示源数据方,Follower表示数据订阅方,其中Leader生产数据,Follower订阅Leader后同步数据,以只读的方式提供数据服务。
工作机制:
在BES中,索引数据被分割成多个分片(Shard),每个分片负责物理存储和管理索引的一部分数据。CCR就是在索引分片维度上实现的,其采用轮询的方式从Leader索引的主分片拉取数据到Follower索引主分片,单向进行数据同步,并保证一致性与及时性,其中分片中数据同步方式如下所示:
| 序号 | 数据类型 | 说明 | 同步方式 | 特点 |
|---|---|---|---|---|
| 1 | 分片存量数据 | 构建同步关系前Leader索引已经存在的数据 | 索引文件拉取 | 只涉及IO操作,同步速率快 |
| 2 | 分片增量数据 | 构建同步关系后Leader索引生成的数据 | 索引数据记录拉取 | 基于索引数据记录同步,延迟低 |
二、多地域高可用场景实践
CCR支持索引数据的单向同步,也支持多订阅模式,可以用于构建多地域的高可用场景。以三地域(包含BES集群:A、B、C)的高可用BES集群为例,三个地域的BES集群,每个集群均订阅另外两个集群中的数据,保证每个地域的BES集群都具备完整数据并都提供读写服务,如下图所示:
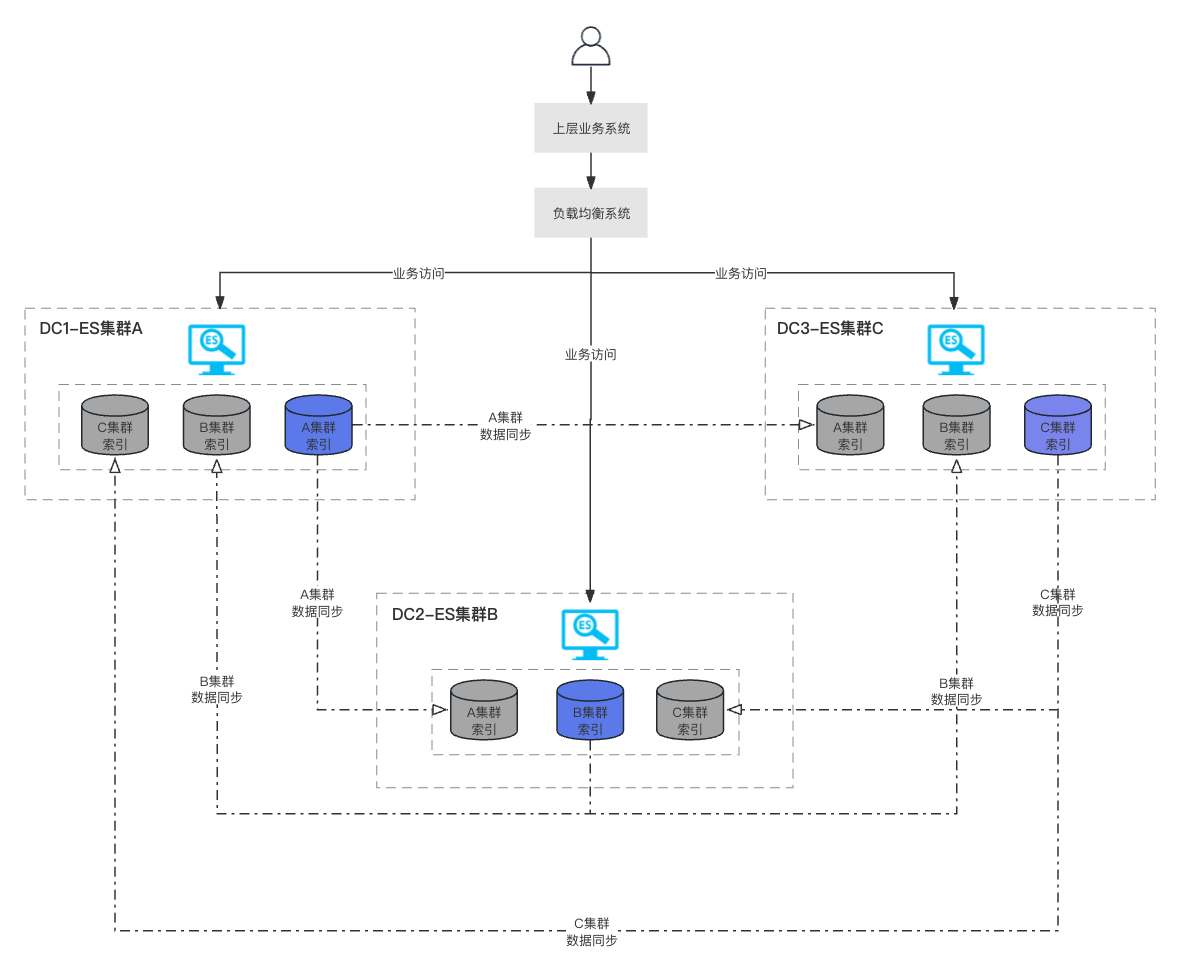
当上述任何一个地域故障时,负载均衡系统会切断故障机房流量,上层业务系统仍可以正常使用ES集群对故障无感。
2.1 集群环境准备
在三个地域准备三个7.10.2的BES集群,如下所示:
| 序号 | 集群名称 | 集群地域 | 版本 |
|---|---|---|---|
| 1 | 集群A | 北京 | 7.10.2 |
| 2 | 集群B | 保定 | 7.10.2 |
| 3 | 集群C | 广州 | 7.10.2 |
2.2 基于CCR搭建高可用环境
2.2.1 网络设置
进行高可用环境的配置,先要进行各个集群所属VPC间的网络配置,保证各个区域的BES集群网络互通。
2.2.2 同步索引配置
2.2.2.1 插件安装
在控制台的集群详情页面,【插件配置】-> 【系统插件】中找到CCR插件,点击安装即可完成插件安装(注意:安装后需要重启BES集群,插件才能生效)。
2.2.2.2 主索引配置
主索引不需要进行特殊的设置来支持CCR同步功能,但使用别名机制可以方便的进行索引切换,避免业务程序因操作索引的名称变化而进行重新部署。 以名称为leader_a_index的索引为例,加入读写别名的操作指令如下所示:
1POST /_aliases
2{
3 "actions": [
4 {
5 "add": {
6 "index": "leader_a_index",
7 "alias": "leader_a_index_read_alias"
8 }
9 },
10 {
11 "add": {
12 "index": "leader_a_index",
13 "alias": "leader_a_index_write_alias",
14 "is_write_index":true
15 }
16 }
17 ]
18}说明:上述指令可以在Kibana的Dev Tools执行,也可以通过SDK或直接调用Restful API执行,下文所有指令不再进行额外说明。
2.2.2.3 同步索引配置
在三个BES集群上,配置同步索引的操作步骤是相似的,下面以一个集群的配置操作举例说明如何进行操作配置。 在一个BES集群中,配置索引同步的步骤是:
- 从集群设置连接的主集群信息
- 从集群配置同步索引
具体的操作指令与说明详见下述内容。
2.2.2.3.1 从集群设置连接的主集群信息
该步骤是使用需要配置的第一个步骤,用于从集群(Follower集群)中配置需要连接的主集群(Leader集群)地址信息。一个从集群可以配置 多个主集群(Leader集群),以A集群配置B、C集群的同步索引为例,指令与说明详见下述内容。 操作指令说明:
1PUT /_cluster/settings
2{
3 "persistent": {
4 "cluster": {
5 "remote": {
6 "{主集群B-自定义名称}": {
7 "seeds": [
8 "{集群B节点ip:tcp端口}","{主集群B节点ip:tcp端口}","{主集群B节点ip:tcp端口}"
9 ]
10 },
11 "{主集群C-自定义名称}": {
12 "seeds": [
13 "{主集群C节点ip:tcp端口}","{主集群C节点ip:tcp端口}","{主集群C节点ip:tcp端口}"
14 ]
15 }
16 }
17 }
18 }
19}说明:上述节点ip为主集群节点的 vpc ip ,tcp端口为 9200
2.2.2.3.2 从集群配置同步索引
完成上述步骤操作后,既可以在从集群(Follower集群)进行同步索引的配置操作,开启数据同步过程。 操作指令说明:
1PUT /_ccr/_replication/{从集群索引名}/_start
2{
3 "leader_alias": "{主集群-自定义名称}",
4 "leader_index": "{主集群索引名}"
5}使用示例:
1PUT /_ccr/_replication/follower_index/_start
2{
3 "leader_alias": "leader-cluster-a",
4 "leader_index": "leader_a_index"
5}2.2.2.3.3 同步索引别名操作
同步索引没有索引别名操作的限制,当需要将查询从leader_a_index同步索引,切换为leader_a_index_new同步索引时,更换别名的操作指令如下所示:
1POST /_aliases
2{
3 "actions": [
4 {
5 "remove": {
6 "index": "leader_a_index",
7 "alias": "leader_a_index_read_alias"
8 }
9 },
10 {
11 "add": {
12 "index": "leader_a_index_new",
13 "alias": "leader_a_index_read_alias"
14 }
15 }
16 ]
17}三、方案优势
与传统的基于消息中间件多订阅模式的高可用模式相比,基于CCR插件的高可用方案具有如下优势:
| 方案 | 系统复杂度 | 数据实时性 | 运维复杂度 |
|---|---|---|---|
| CCR方案 | 低 | 高 | 低 |
| 消息中间件方案 | 高 | 普通 | 高 |
3.1 系统复杂度
基于消息中间件多订阅模式的高可用方案需要Kafka(或者其他消息队列)以及多个消费者程序,依赖的外服服务多;CCR方案以ES插件的方式提供服务,无第三方服务的依赖,因此基于CCR的方案复杂度更低。
3.2 数据实时性
对于存量数据的同步:
基于消息中间件的方案需要使用数据索引的方式进行同步,操作复杂度高(需要reindex或者将全部数据读取到消息队列,使用索引程序读取构 建)耗时久,而CCR方案使用的是索引文件读取方式进行同步,速率更快。
对于增量数据:
基于消息中间件的方案同步数据时,还需要经过消息中间件传导数据,而CCR方案是分片到分片的直接同步,速率也更有优势。
3.3 运维复杂度
基于消息中间件的方案的运维成本更高,因为增加了第三方的服务依赖,需要更多运维工作来保障消息中间件及生产消费程序的可用性;在进行故障恢复时,需要的操作也更多。
综上,基于CCR的BES高可用方案,系统复杂度低、数据同步实时性高、系统维护成本也更低,是更好的方案选择。
评价此篇文章