
基于Reciprocal Rank Fusion的融合查询
背景
Reciprocal Rank Fusion(RRF)是一种在信息检索和机器学习领域中使用的排名融合方法,旨在将具有不同相关性指标的多个查询的结果集融合成单个结果集。
百度智能云Elasticsearch自研支持 RRF 算法,在 RRF 算法中,不同结果集的相关性指标不必相互关联,即可相互融合获得高质量的结果。
注意:此功能当前仅支持7.10.2版本的1.7.5以上内核版本集群使用。集群版本和内核版本可在百度智能云控制台-对应集群的【集群详情】页面查看
Reciprocal Rank Fusion 的计算方法
RRF 的基本思想是在多个查询中,考虑每个查询结果集的文档排名列表,并为结果集中的每个文档分配一个得分,这个得分是文档所在的所有结果集中排名的倒数之和。
RRF 使用以下公式来确定特定文档 d 在所有查询集中结合了综合排名的最终分数:
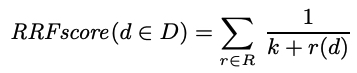
D表示不同相关性指标下的多个查询的结果集集合d为某个结果集D的一个文档k为等级常量,此值确定每个查询的单个结果集中的文档,对最终排名结果集的影响程度。k越大说明排名较低的文档对最终排名有更大的影响力。R为排名的集合,其元素为单个查询结果集的排名。r()为排名函数,表示单个结果集中d所在排名。排名从1开始,并且只有当结果集合D中存在d时,才进行累加。
Reciprocal Rank Fusion 查询方式
可以使用 rrf 参数进行倒排融合查询。需要在 rrf 中配置多个子查询,并设置混合查询的参数 rank_constant 和 window_size 。
倒排融合查询会考虑每个子查询的结果,并把所有结果集融合成一个具有综合排名的最终结果集,其中 rrf 语法包含的参数如下:
-
queries(必须包含,类型为query的列表)queries需要包含两个及以上query,每个query是一个单独的查询,需要遵循query的语法,最终通过RRF将所有query结果进行关联并合并融合成为最终查询结果集 -
rank_constant(非必须,类型为float)rank_constant对应RRF公式中的k值,确定每个查询的单个结果集中的文档,对最终排名结果集的影响程度。默认为60,需要大于或者等于1 -
window_size(非必须,类型为int)window_size确定单个查询中包含结果集的大小,如果window_size较高,会以性能为代价提高结果的相关性。默认为10,需要大于0,同时需要大于或者等于查询的size
其中 RRF 的查询语句示例如下:
1GET my_index/_search
2{
3 "rrf": {
4 "queries": [
5 {
6 "query": {
7 "match": {
8 "text": "RRF"
9 }
10 }
11 },
12 {
13 "query": {
14 "match": {
15 "title": "Reciprocal Rank Fusion"
16 }
17 }
18 },
19 {
20 "query": {
21 "knn": {
22 "vector": {
23 "vector": [ 5, 4, 3, 2, 1 ],
24 "k": 3,
25 "ef": 100
26 }
27 }
28 }
29 }
30 ],
31 "window_size": 5,
32 "rank_constant": 10
33 },
34 "size": 5
35}示例
首先为一个索引创建一个 mapping ,其中包含一个 text 字段、一个 vector 字段和一个整数字段,并为这个索引添加几个文档。
对于这个索引的向量字段,使用只有单一维度的向量,使排名更容易解释。
创建索引
使用如下 setting 和 mapping ,创建一个索引 index_rrf :
1PUT index_rrf
2{
3 "settings": {
4 "index": {
5 "knn": true,
6 "number_of_shards": 3,
7 "number_of_replicas": 1
8 }
9 },
10 "mappings": {
11 "properties": {
12 "vector": {
13 "type": "bpack_vector",
14 "dims": 1,
15 "index_type": "hnsw",
16 "space_type": "l2",
17 "parameters": {
18 "ef_construction": 200,
19 "m": 32
20 }
21 },
22 "id": {
23 "type": "integer"
24 },
25 "text": {
26 "type": "text"
27 }
28 }
29 }
30}写入数据
灌入5条一维的向量数据
1PUT index_rrf/_doc/1
2{
3 "text" : "rrf",
4 "vector" : [5],
5 "integer": 1
6}
7
8PUT index_rrf/_doc/2
9{
10 "text" : "rrf rrf",
11 "vector" : [4],
12 "integer": 2
13}
14
15PUT index_rrf/_doc/3
16{
17 "text" : "rrf rrf rrf",
18 "vector" : [3],
19 "integer": 1
20}
21
22PUT index_rrf/_doc/4
23{
24 "text" : "rrf rrf rrf rrf",
25 "integer": 2
26}
27
28PUT index_rrf/_doc/5
29{
30 "vector" : [0],
31 "integer": 1
32}执行RRF查询
执行如下查询语句
1GET index_rrf/_search
2{
3 "rrf": {
4 "queries": [
5 {
6 "query": {
7 "match": {
8 "text": "rrf"
9 }
10 }
11 },
12 {
13 "query": {
14 "knn": {
15 "vector": {
16 "vector": [
17 5
18 ],
19 "k": 3,
20 "ef": 100
21 }
22 }
23 }
24 }
25 ],
26 "window_size": 5,
27 "rank_constant": 1
28 },
29 "size": 5
30}其中查询结果为
1{
2 "took" : 4,
3 "timed_out" : false,
4 "_shards" : {
5 "total" : 3,
6 "successful" : 3,
7 "skipped" : 0,
8 "failed" : 0
9 },
10 "hits" : {
11 "total" : {
12 "value" : 5,
13 "relation" : "eq"
14 },
15 "max_score" : 1.0,
16 "hits" : [
17 {
18 "_index" : "index_rrf",
19 "_type" : "_doc",
20 "_id" : "1",
21 "_score" : 1.0,
22 "_source" : { ... }
23 },
24 {
25 "_index" : "index_rrf",
26 "_type" : "_doc",
27 "_id" : "2",
28 "_score" : 0.53333336,
29 "_source" : { ... }
30 },
31 {
32 "_index" : "index_rrf",
33 "_type" : "_doc",
34 "_id" : "3",
35 "_score" : 0.5,
36 "_source" : { ... }
37 },
38 {
39 "_index" : "index_rrf",
40 "_type" : "_doc",
41 "_id" : "4",
42 "_score" : 0.33333334,
43 "_source" : { ... }
44 },
45 {
46 "_index" : "index_rrf",
47 "_type" : "_doc",
48 "_id" : "5",
49 "_score" : 0.2,
50 "_source" : { ... }
51 }
52 ]
53 }
54}过程分析
标量查询分析
单独执行标量查询,并获取标量查询中命中的各个文档的排名
1GET index_rrf/_search?filter_path=**.hits
2{
3 "query": {
4 "term": {
5 "text": "rrf"
6 }
7 }
8}执行结果如下所示:
1{
2 "hits" : {
3 "hits" : [
4 {
5 "_index" : "index_rrf",
6 "_type" : "_doc",
7 "_id" : "1",
8 "_score" : 0.2876821,
9 "_source" : {
10 "text" : "rrf",
11 "vector" : [
12 5
13 ],
14 "integer" : 1
15 }
16 },
17 {
18 "_index" : "index_rrf",
19 "_type" : "_doc",
20 "_id" : "4",
21 "_score" : 0.21365023,
22 "_source" : {
23 "text" : "rrf rrf rrf rrf",
24 "integer" : 2
25 }
26 },
27 {
28 "_index" : "index_rrf",
29 "_type" : "_doc",
30 "_id" : "3",
31 "_score" : 0.20983505,
32 "_source" : {
33 "text" : "rrf rrf rrf",
34 "vector" : [
35 3
36 ],
37 "integer" : 1
38 }
39 },
40 {
41 "_index" : "index_rrf",
42 "_type" : "_doc",
43 "_id" : "2",
44 "_score" : 0.20259935,
45 "_source" : {
46 "text" : "rrf rrf",
47 "vector" : [
48 4
49 ],
50 "integer" : 2
51 }
52 }
53 ]
54 }
55}上述标量查询命中了4条结果( _id 为5的文档不包含 text 字段),因此标量的排名为
| _id | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| rank | 1 | 4 | 3 | 2 | none |
向量查询分析
单独执行向量查询,并获取向量查询命中的各个文档的排名
1GET index_rrf/_search?filter_path=**.hits
2{
3 "query": {
4 "knn": {
5 "vector": {
6 "vector": [
7 5
8 ],
9 "k": 3,
10 "ef": 100
11 }
12 }
13 }
14}执行结果如下所示:
1{
2 "hits" : {
3 "hits" : [
4 {
5 "_index" : "index_rrf",
6 "_type" : "_doc",
7 "_id" : "1",
8 "_score" : 1.0,
9 "_source" : {
10 "text" : "rrf",
11 "vector" : [
12 5
13 ],
14 "integer" : 1
15 }
16 },
17 {
18 "_index" : "index_rrf",
19 "_type" : "_doc",
20 "_id" : "2",
21 "_score" : 0.5,
22 "_source" : {
23 "text" : "rrf rrf",
24 "vector" : [
25 4
26 ],
27 "integer" : 2
28 }
29 },
30 {
31 "_index" : "index_rrf",
32 "_type" : "_doc",
33 "_id" : "3",
34 "_score" : 0.33333334,
35 "_source" : {
36 "text" : "rrf rrf rrf",
37 "vector" : [
38 3
39 ],
40 "integer" : 1
41 }
42 },
43 {
44 "_index" : "index_rrf",
45 "_type" : "_doc",
46 "_id" : "5",
47 "_score" : 0.16666667,
48 "_source" : {
49 "vector" : [
50 0
51 ],
52 "integer" : 1
53 }
54 }
55 ]
56 }
57}上述查询命中了4条结果( _id 为4的文档不包含 vector 字段),因此向量的排名为
| _id | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| rank | 1 | 2 | 3 | none | 4 |
结果分析
把两个查询的排名结果整理到一起
| _id | query_rank | knn_rank |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 4 | 2 |
| 3 | 3 | 3 |
| 4 | 2 | none |
| 5 | none | 4 |
然后使用上面给出的RRF公式计算最终得分,其中 rank_constant = 1
1# doc | query | knn | score
2_id: 1 = 1.0/(1+1) + 1.0/(1+1) = 1
3_id: 2 = 1.0/(1+4) + 1.0/(1+2) = 0.5333
4_id: 3 = 1.0/(1+3) + 1.0/(1+3) = 0.5
5_id: 4 = 1.0/(1+2) = 0.3333
6_id: 5 = 1.0/(1+4) = 0.2000因此可以得到最后的排名顺序为 _id 1, _id 2, _id 3, _id 4, _id 5
评价此篇文章