
引擎增强
Spark Native Engine
截止目前,Spark是一个运行在JVM上的大数据计算引擎,其计算性能依然有很大的提升空间。我们通过引入ClickHouse计算引擎实现了Spark性能的巨大提升,同时还能保证和现有Spark的兼容性。
基本原理
我们先以一段简单的聚合SQL为例,看下Spark是如何执行的
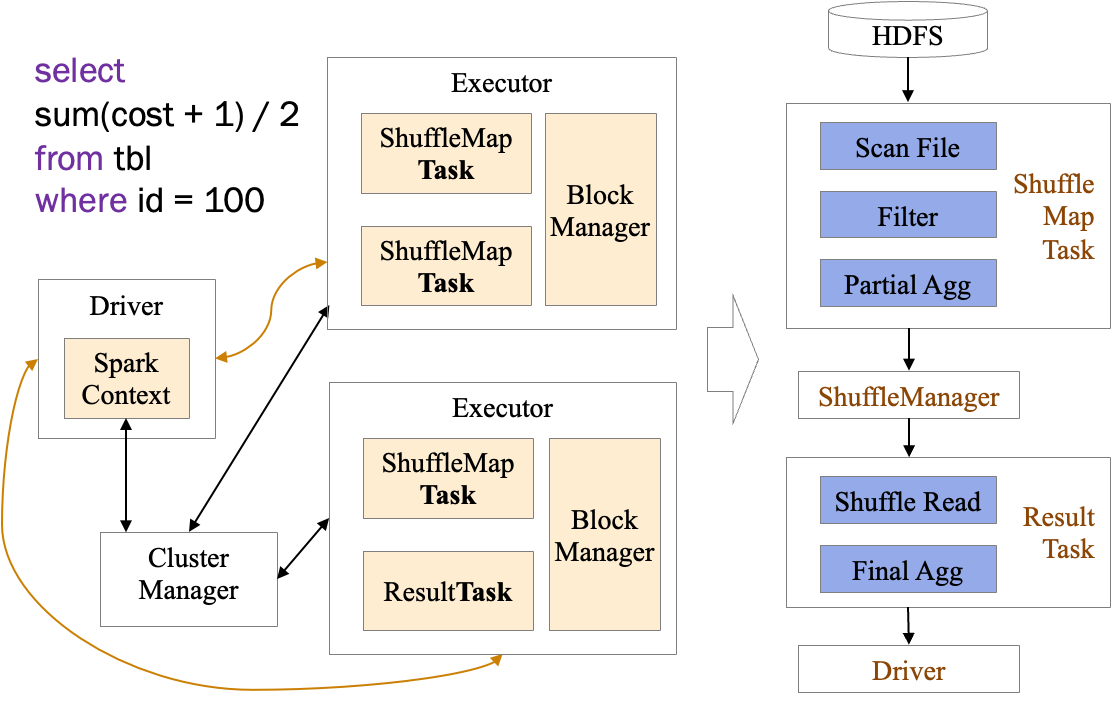
我们的SQL代码经过解析先在Driver中生成了执行计划,执行计划优化后最终转化为一个个的RDD,每个RDD和其要处理的分片信息最终会发往对应的Executor,以Task为执行单元来执行对应的计算逻辑。这里可以将一个Task当做Executor中的一个线程,这个线程里完成了主要的计算逻辑。在Task中实际执行的Scan、Filter、Agg等计算逻辑就是由对应的RDD生成的。
实际上ClickHouse中也有对应于Scan、Filter、Agg这样的计算逻辑,所以我们可以将每个Task中的实际计算逻辑交给ClickHouse来执行,凭借ClickHouse强大的计算性能实现Spark性能的提升。我们这里称使用ClickHouse加速以后的Spark引擎为SNE(Spark Native Engine)。
下面是这段SQL使用SNE执行时的执行计划以及每个Task中Java和ClickHouse的调用关系。
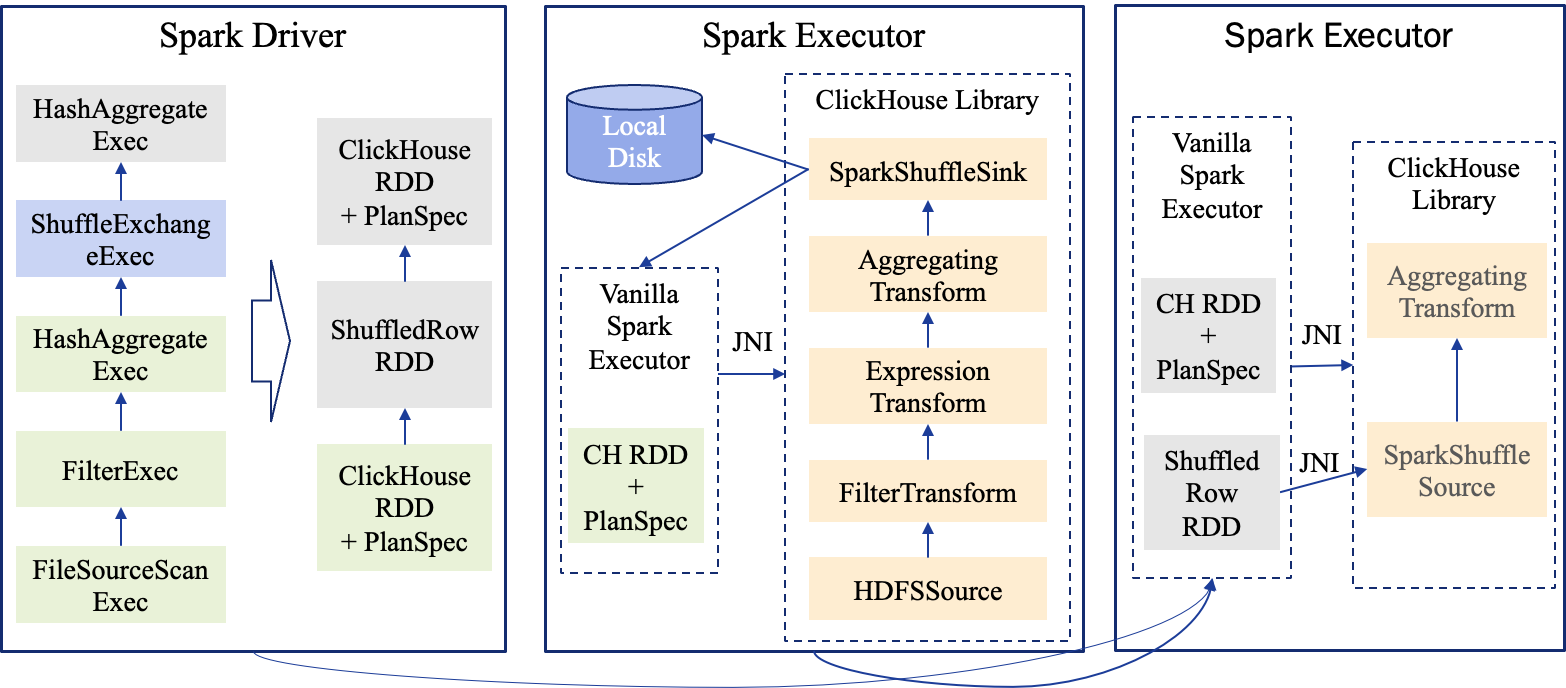
可以看到我们使用JNI将执行计划信息发给了ClickHouse,在整体分布式框架上,依然保持了Spark现有的架构。
使用方法
使用SNE的方法非常简单,只需要增加如下配置即可:
1spark.sql.execution.clickhouse true由于我们目前还没有支持所有Spark特性,对于不支持的情况,我们会自动回退到原生Spark来执行用户的请求。另外我们支持了如下配置可以强制使用SNE执行而不回滚
1spark.sql.clickhouse.fallback false这个配置的默认值是true,就是会自动回滚。
进展
在数据类型方面,我们目前已经支持了常见的基础类型:BooleanType, ByteType, IntegerType, LongType, FloatType, DoubleType, DecimalType, TimestampType, DateType, StringType。
在算子级别的覆盖度见下表:
| Operator | 支持度 |
|---|---|
| FileSourceScanExec | 支持 |
| FilterExec | 支持 |
| ProjectExec | 支持 |
| HashAggregateExec | 支持 |
| SortExec | 支持 |
| BroadcastHashJoinExec | 支持 |
| ShuffledHashJoinExec | 支持 |
| SortMergeJoinExec | 支持 |
| CartesianProductExec | 支持 |
| BroadcastNestedLoopJoinExec | 支持 |
| WindowExec | 支持 |
| GlobalLimitExec | 支持 |
| LocalLimitExec | 支持 |
| CollectLimitExec | 支持 |
| TakeOrderedAndProjectExec | 支持 |
| ExpandExec | 支持 |
| UnionExec | 支持 |
| ShuffleExchangeExec | 支持 |
| BroadcastExchangeExec | 支持 |
| SubqueryBroadcastExec | 支持 |
| DataWritingCommandExec | 不支持 |
| BatchScanExec | 不支持 |
| ObjectHashAggregateExec | 不支持 |
| SortAggregateExec | 不支持 |
| CoalesceExec | 不支持 |
| GenerateExec | 不支持 |
| RangeExec | 不支持 |
| SampleExec | 不支持 |
| CustomShuffleReaderExec | 不支持 |
| InMemoryTableScanExec | 不支持 |
| AggregateInPandasExec | 不支持 |
| ArrowEvalPythonExec | 不支持 |
| FlatMapGroupsInPandasExec | 不支持 |
| MapInPandasExec | 不支持 |
| WindowInPandasExec | 不支持 |
| Velox2Row | 不支持 |
| Velox2Arrow | 不支持 |
这里我们虽然只支持了一半多一点的算子,但是在SQL场景,基本上都已经都能覆盖到了。在SQL场景,还有两类SQL需要特别说明一下:
- 我们虽然不支持DataWritingCommandExec算子,但是对于包括了该算子的SQL,比如
insert into table_x select ...,我们会将除了DataWritingCommandExec以外的算子全部执行在ClickHouse上,最后调用原生Spark的DataWritingCommandExec来完成计算。所以除了DataWritingCommandExec以外的查询算子依然可以享受到ClickHouse的性能提速。 - 还有Scan相关的算子,比如BatchScanExec、InMemoryTableScanExec,如果SQL用到了这些算子,目前会将整个SQL回退到原生Spark执行。这些算子我们接下来会尽快支持。
相对于原生Spark的内建函数,我们目前先支持了其中较常用的部分,剩余函数会逐步支持。目前支持的函数如下:
| 函数 | 说明 |
|---|---|
| cast | |
| coalesce | |
| isNull | |
| isNotNull | |
| abs | |
| year | |
| month | |
| day/dayofmonth | |
| dayofweek | |
| weekofyear | |
| hour | |
| minute | |
| second | |
| quarter | |
| dayofyear | |
| upper/ucase | |
| !/not | |
| ~ | |
| cbrt | |
| cos | |
| floor | |
| ceil/ceiling | |
| sqrt | |
| length/char_length/character_length | 暂不支持BinaryType |
| log2 | |
| log10 | |
| + | |
| - | |
| * | |
| / | |
| %/mod | 暂不支持DecimalType |
| and | |
| or | |
| =/== | |
| < | |
| > | |
| <= | |
| >= | |
| datediff | |
| date_add | |
| date_sub | |
| add_months | |
| date_format | |
| like | |
| round | |
| shiftright | |
| shiftleft | |
| & | |
| | | |
| ^ | |
| pow/power | |
| instr | |
| substr/substring | |
| regexp_extract | |
| locate/position | |
| regexp_replace | |
| concat | |
| when | |
| in | |
| parse_url | 不支持3个参数的版本,另外第二个参数只支持常量 |
在性能方面,在5T规模的TPC-DS数据集下,相对于社区版Spark的性能对比见下图
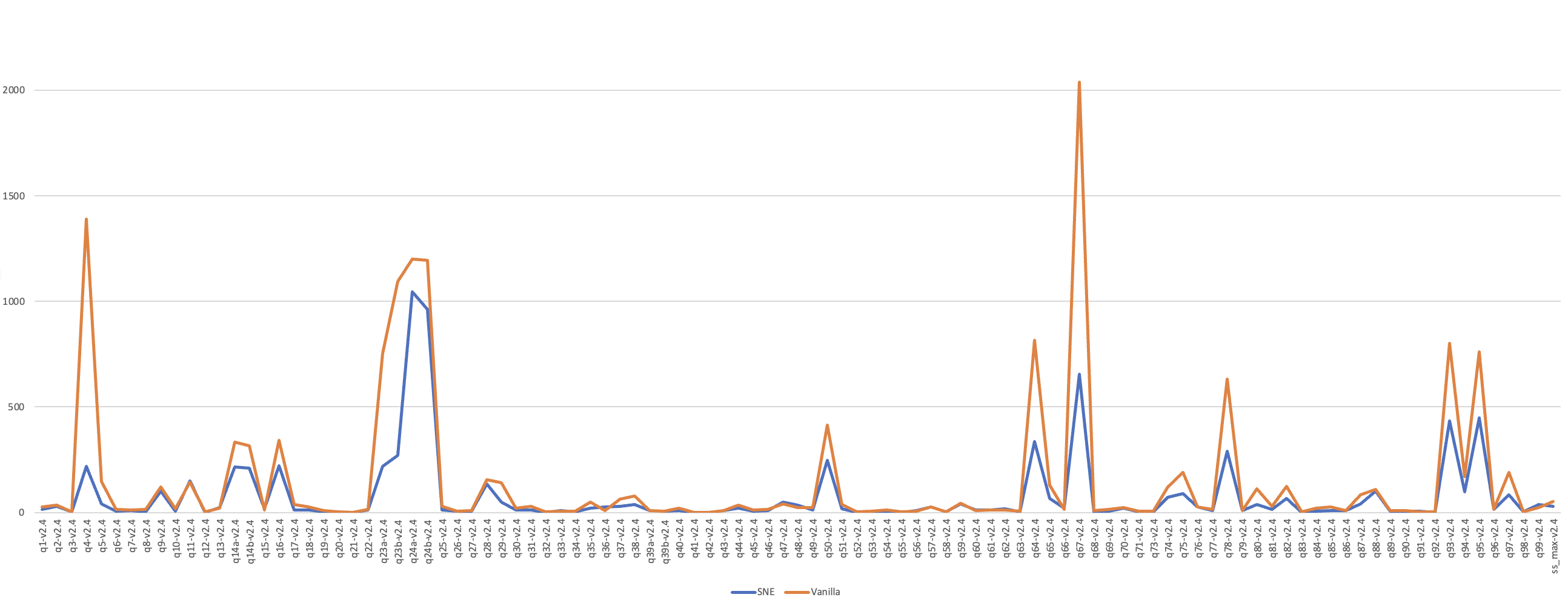
其中原生Spark总的执行时间是15257秒,SNE总的执行时间为7779秒。
评价此篇文章