
向量数据库
向量数据库由百度智能云Elasticsearch团队研发,能够快速实现向量检索、向量计算等功能需求。
背景
近年来基于Text(Document) Embedding、特征向量等的向量检索在推荐系统、图片的相似度检索中得到了广泛使用。用户可以使用Word2vec等工具将图像、音频、自然语言等复杂的数据信息映射为特征向量,再通过向量检索算法检索特征向量,从而实现了对复杂的数据信息的处理。为了处理向量数据,百度Elasticsearch向量检索插件提供了两种向量检索算法:linear算法和hnsw算法。
| 算法 | 含义 | 适用场景 | 缺点 | 支持距离算法 |
|---|---|---|---|---|
| linear | 线性计算所有向量数据 | 召回率100%。 查询时间与数据量成正比。 通常用于效果对照。 |
大数据量下效率较低 消耗cpu 全内存 |
余弦距离(cosine) 欧式距离(l2) 点积(dot_prod) L1距离(l1)(7.10.2版本新增) |
| hnsw | 基于hnsw算法对数据进行近似计算 | 单机数据量小。 对召回率要求高 对查询速度要求高。 |
数据膨胀比较大 写入数据后需要构建索引 全内存 |
余弦距离(cosine) 欧式距离(l2) L1距离(l1)(7.10.2版本新增) |
注意:目前向量检索插件支持功能发布后新创建的7.4.2、7.10.2版本的实例,您可以通过以下API查询集群是否支持knn插件,不支持向量检索插件的集群请提交工单,BES团队会协助升级集群,升级方式参见ES版本升级。
Plain Text1GET _cat/plugins?v
集群准备
| 建议 | 说明 | |
|---|---|---|
| 套餐选择 | 至少16G内存以上 | 向量检索对集群内存要求较高,如果数据量超过10G,建议选择16核64G以上的套餐,如bes.g3.c16m64、bes.c3.c32m64、bes.g3.c32m128等。 |
| 单机数据量 | 建议不超过节点总内存的三分之一 | 向量检索对集群内存要求较高,如果数据量过大,可能造成内存溢出。 |
| 写入限流 | 以16核64G的节点为例,建议单节点写入限流控制在4000tps以内 | 向量索引的构建属于CPU密集型任务,建议不要大流量写入数据。 由于在查询过程中,会把数据全部加载到系统内存,因此在查询期间,不要同时进行大流量写入。 |
使用方法
用户在写入数据前,需要根据业务的向量维度信息和性能需求配置knn参数,选择距离计算算法,创建所需的knn索引。创建索引后,即可以写入数据。在索引完成构建后,可以通过下文提供的查询方式,进行向量检索查询。
创建knn索引
我们需要预先创建knn索引,创建方式如下:
如下示例,我们创建了一个名为test-index的索引,包含了field1和field2字段。您也可以根据自身需求,自定义索引名称和字段名称。
1PUT /test-index
2{
3 "settings": {
4 "index": {
5 "codec": "bpack_knn_hnsw",
6 "bpack.knn.hnsw.space": "cosine",
7 "bpack.knn.hnsw.m": 16,
8 "bpack.knn.hnsw.ef_construction": 512
9 }
10 },
11 "mappings": {
12 "properties": {
13 "field1": {
14 "type": "bpack_vector",
15 "dims": 2
16 },
17 "field2": {
18 "type": "bpack_knn_vector",
19 "dims": 2
20 }
21 }
22 }
23}参数说明
| 参数 | 描述 |
|---|---|
| index.codec | bpack_knn_hnsw,支持hnsw算法和linear算法。否则仅支持linear算法。 |
| type | 向量检索插件提供两种新的向量字段类型,bpack_vector和bpack_knn_vector。在7.10.2版本中,两个参数含义相同。 在7.4.2版本含义如下: bpack_vector表示普通向量字段,支持linear算法;bpack_knn_vector表示向量检索字段,支持linear算法和hnsw算法。 |
| dims | 向量维度,支持2~2048维。 |
settings中的bpack.knn.hnsw参数含义见下文中索引级别参数优化。
写入与查询数据
写入数据
我们向刚才创建的索引test-index的_doc中写入数据,写入数据示例如下:
1POST /test-index/_doc/
2{
3 "field1" : [6.5, 2.5],
4 "field2" : [6.5, 2.5],
5 "price" : 10
6}其中field1、field2是我们刚刚创建的向量类型的字段,price是其他普通字段。
在索引完成构建后,我们可以查询数据如下:
linear查询
linear算法可以查询bpack_knn_vector类型的字段,也可以查询bpack_vector类型的字段。下例中,我们查询的是bpack_vector类型的字段field1。
1POST /test-index/_search
2{
3 "query": {
4 "script_score": {
5 "query": {
6 "match_all": {}
7 },
8 "script": {
9 "source": "bpack_knn_script",
10 "lang": "knn",
11 "params": {
12 "space": "cosine",
13 "field": "field1",
14 "vector": [3.5, 2.5]
15 }
16 }
17 }
18 },
19 "size": 100
20}
21或
22POST /test-index/_search
23{
24 "query": {
25 "function_score": {
26 "boost_mode": "replace",
27 "script_score": {
28 "script": {
29 "source": "bpack_knn_script",
30 "lang": "knn",
31 "params": {
32 "space": "cosine",
33 "field": "field1",
34 "vector": [3.5, 2.5]
35 }
36 }
37 }
38 }
39 },
40 "size": 100
41}其中查询参数含义为:
| 参数 | 描述 | 默认值 |
|---|---|---|
| source | 选择计算方法,这里置为bpack_knn_script。 |
必填参数 |
| space | 距离算法参数。7.10.2版本linear算法支持四种距离算法:余弦距离(cosine)、点积(dot_prod)、欧式距离(l2)、L1距离(l1)。7.4.2版本linear算法支持三种距离算法:余弦距离(cosine)、点积(dot_prod)、欧式距离(l2)。 | cosine |
| field | 向量字段名。 | 必填参数 |
| vector | 格式为float数组,数组长度必须与创建索引时该字段mapping指定的dims保持一致。 | 必填参数 |
hnsw查询
使用hnsw的方式查询,该索引必须指定index.codec为bpack_knn_hnsw,且要查询的向量字段mapping指定的type必须是bpack_knn_vector。下例中,我们查询的是bpack_knn_vector类型的字段field2。
1POST /test-index/_search
2{
3 "size" : 10,
4 "query": {
5 "hnsw": {
6 "field2": {
7 "vector": [3, 4],
8 "k": 2,
9 "ef": 512
10 }
11 }
12 }
13}2022-01-18后创建的集群使用字段"hnsw"进行查询,之前的集群使用"knn"进行查询,如下:
Plain Text1POST /test-index/_search 2{ 3 "size" : 10, 4 "query": { 5 "knn": { 6 "field2": { 7 "vector": [3, 4], 8 "k": 2, 9 "ef": 512 10 } 11 } 12 } 13}
其中查询参数含义为:
| 参数 | 描述 | 默认值 |
|---|---|---|
| vector | 格式为float数组,数组长度必须与创建索引时该字段mapping指定的dims保持一致,否则可能造成结果有误差。 | 必填参数 |
| k | 在hnsw算法中查询的最近邻的数量,取值为正整数。 | 必填参数 |
| ef | 此参数表示在搜索期间,最近邻居的动态扫描区域的大小。该值越大,查询准确率越好,查询速度越慢,取值范围为[2,1024]。(7.10.2版本废弃此参数,填写无实际意义,『ef』改为索引级别参数,详见下文:bpack.knn.hnsw.ef_search) |
512 |
Elasticsearch Score详解
向量检索引擎支持余弦距离(cosine)、欧式距离(l2)、L1距离(l1)、点积(dot_prod)、海明码(hammingbit),其中L1距离、海明码为7.10.2版本新增。
海明码仅支持支持long型字段,且仅支持linear算法;其他仅支持向量字段。
linear
| 距离算法 | 距离公式 | Elasticsearch Score |
|---|---|---|
| l2 | 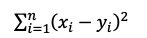 |
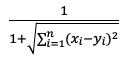 |
| l1 | 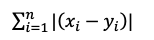 |
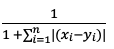 |
| cosine | 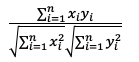 |
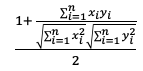 |
| dot_prod | 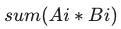 |
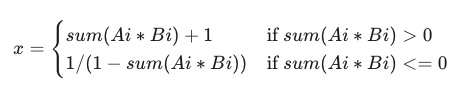 |
| hammingbit(仅支持long型字段) | countSetBits(X ⊕ Y) | 1 / (1 + countSetBits(X ⊕ Y)) |
hnsw
| 距离算法 | 距离公式 | Elasticsearch Score |
|---|---|---|
| l2 | |
|
| l1 | |
|
| cosine | |
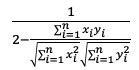 |
参数优化
索引级别的参数
创建索引时必须提供索引settings参数。如果用户不进行配置,将使用默认值。注意,以下参数只能在创建索引时配置,索引创建后不可修改。具体参数解析如下:
| 参数 | 描述 | 默认值 |
|---|---|---|
| bpack.knn.hnsw.m | 此参数表示构造期间为每个新元素创建的双向链接数。m的合理范围为2-100。主要影响内存、存储消耗、准确率,m值越高,意味着更高消耗的内存和存储,更慢的索引构建时间,以及更好的准确率。建议根据min(向量维度 * 1.5, 32)取值,以保证性能,12-48可以满足大多数场景的需求。 |
16 |
| bpack.knn.hnsw.space | 向量检索计算的距离算法。距离算法参数。7.10.2版本hnsw支持三种距离算法:余弦距离(cosine)、欧式距离(l2)、L1距离(l1)。7.4.2版本hnsw支持两种距离算法:余弦距离(cosine)、欧式距离(l2)。 | cosine |
| bpack.knn.hnsw.ef_construction | 此参数表示在索引构建过程中,最近邻居的动态扫描区域大小。该值越大,查询准确率更高,但是索引构建越慢,取值范围为[2,+∞]。 | 512 |
| bpack.knn.hnsw.ef_search | 此参数表示在搜索期间,最近邻居的动态扫描区域的大小。该值越大,查询准确率越好,查询速度越慢,取值范围为[2,+∞]。(7.10.2版本新增) | 512 |
集群级别的参数
通用参数
| 参数 | 描述 | 默认值 |
|---|---|---|
| bpack.knn.hnsw.index_thread_qty | 此参数表示hnsw构建图形允许使用的线程数。(默认情况下,nmslib将此值设置为内核数n。但是,由于Elasticsearch可以创建n个用于生成索引的线程,并且如果每个索引线程都调用nmslib来构建图形,也就是说每个线程都会生成n个线程,这可能导致同时n^2个线程运行,可能导致100%的CPU利用率。所以默认将此值设为1),取值范围为[1,32]。 | 1 |
缓存设置
linear算法缓存参数设置(7.10.2版本废弃)
| 参数 | 描述 | 默认值 |
|---|---|---|
| bpack.knn.memory.cache.limit | 此参数表示指示缓存的最大容量。当缓存尝试加载数据时超过了缓存的最大容量限制,将触发驱逐操作。该值可以设置为百分数,代表jvm内存的百分比,也可以设置为一个带有存储容量单位的值,例如『10kb』、『10mb』、『3g』等,不建议设置为小数值,如『1.5g』。 | 10% |
| bpack.knn.memory.cache.expiry.time | 此参数表示当数据持续这个时间不被访问时,将从缓存中清除。使用TimeUnit格式表示,例如『10s』、『10m』、『3h』等,不可设置为小数值,如『1.5h』。建议设置超过30分钟,使缓存结果能够被接下来的查询有效命中;如果设置过小,则会很快被清除。 | 30m |
hnsw算法缓存参数设置
| 参数 | 描述 | 默认值 |
|---|---|---|
| bpack.knn.cache.item.expiry.time | 此参数表示当数据持续这个时间不被访问时,将从缓存中清除。使用TimeUnit格式表示,例如『10s』、『10m』、『3h』等,不可设置为小数值,如『1.5h』。建议设置超过30分钟,使缓存结果能够被接下来的查询有效命中;如果设置过小,则会很快被清除。 | 180m |
Circuit Breaker(断路器)设置
hnsw算法会消耗大量堆外内存,而如果消耗的内存过多,Elasticsearch/Lucene可以使用的pagecache就会不足,集群性能将会下降。为了避免这种情况,我们可以配置Circuit Breaker来限制堆外内存的过量消耗。目前,当内存达到我们配置的断路器限制,则会触发驱逐机制,驱逐不常用的缓存项。
| 参数 | 描述 | 默认值 |
|---|---|---|
| bpack.knn.memory.circuit_breaker.limit | 此参数表示指示缓存的最大容量。当此时hnsw的缓存超过了缓存的最大容量限制,将触发驱逐操作,并将circuit_breaker_triggered状态设置为true(可以通过查询统计信息api查询)。该值可以设置为百分数,代表除去Elasticsearch的jvm外,服务器剩余内存的百分比,也可以设置为一个带有存储容量单位的值,例如『10kb』、『10mb』、『3g』等,不建议设置为小数值,如『1.5g』。例如,一台机器拥有100GB内存,Elasticsearch的jvm使用了32GB。那么bpack.knn.memory.circuit_breaker.limit的默认值为(60% * (100 -32) = 40.8GB)。 | 60% |
| bpack.knn.circuit_breaker.unset.percentage | 此参数表示Circuit Breaker的解除百分比,当缓存容量大小低于bpack.knn.circuit_breaker.unset.percentage时,Circuit Breaker将解除触发,将circuit_breaker_triggered状态设置为false(可以通过查询状态api查询)。 | 75 |
示例
1PUT /_cluster/settings
2{
3 "persistent" : {
4 "bpack.knn.hnsw.index_thread_qty" : 1,
5 "bpack.knn.cache.item.expiry.time": "15m",
6 "bpack.knn.memory.circuit_breaker.limit" : "55%",
7 "bpack.knn.circuit_breaker.unset.percentage": 23
8 }
9}查看hnsw算法的相关统计信息
查询状态的方式如下:
1GET /_bpack/_knn/stats
2GET /_bpack/_knn/nodeId1,nodeId2/stats/statName1,statName2结果示例如下:
1{
2 "_nodes": {
3 "total": 1,
4 "successful": 1,
5 "failed": 0
6 },
7 "cluster_name": "my-application",
8 "circuit_breaker_triggered": false,
9 "nodes": {
10 "HYMrXXsBSamUkcAjhjeN0w: {
11 "eviction_count" : 0,
12 "miss_count" : 1,
13 "graph_memory_usage_kb" : 1,
14 "cache_capacity_reached" : false,
15 "load_exception_count" : 0,
16 "hit_count" : 0,
17 "load_success_count" : 1,
18 "total_load_time_nanos" : 2878745
19 }
20 }
21}集群状态参数:
| 参数 | 描述 |
|---|---|
| circuit_breaker_triggered | 指示是否触发断路器。如果集群中的任何节点由于已达到缓存的容量,而从缓存中删除条目时,则会触发断路器。而当缓存中条目数的大小低于bpack.knn.circuit_breaker.unset.percentage时,断路器将取消触发。 |
节点状态参数:
| 参数 | 描述 |
|---|---|
| eviction_count | 表示guava cache中,缓存淘汰的次数。(由于索引删除等情况产生的不计算在内) |
| hit_count | 节点上发生的缓存命中数。 |
| miss_count | 节点上发生的缓存未命中数。 |
| graph_memory_usage_kb | 缓存在本机内存中的总大小,以kb为单位。 |
| cache_capacity_reached | 是否达到此节点的缓存容量。 |
| load_exception_count | 加载到缓存时发生的异常数量。 |
| load_success_count | 加载到缓存时发生的成功数量。 |
| total_load_time_nanos | 加载到缓存的总耗时,单位:纳秒。 |
性能对比
- 内存配置:30G
- cpu配置:逻辑核数56,2个物理cpu,每个cpu cores : 14
- Elasticsearch 节点:单节点
性能对比结果如下:
| 数据量 | 索引参数 | 集群参数 | Top30召回率 | hnsw平均耗时 | linear平均耗时 |
|---|---|---|---|---|---|
| 100万32维向量 1shards |
"bpack.knn.hnsw.space": "cosine", "bpack.knn.hnsw.m": 16, "bpack.knn.hnsw.ef_construction": 300 |
"bpack.knn.cache.item.expiry.time": "1h", "bpack.knn.memory.cache.limit": "15g", "bpack.knn.memory.cache.expiry.time":"1h", "bpack.knn.memory.circuit_breaker.limit" : "70%" |
99.97% | 12.96ms | 134.96ms |
| 1000万32维向量 1shards |
"bpack.knn.hnsw.space": "cosine", "bpack.knn.hnsw.m": 16, "bpack.knn.hnsw.ef_construction": 600 |
"bpack.knn.cache.item.expiry.time": "1h", "bpack.knn.memory.cache.limit": "15g", "bpack.knn.memory.cache.expiry.time":"1h", "bpack.knn.memory.circuit_breaker.limit" : "70%" |
99.97% | 24.69ms | 1209.13ms |
| 1000万32维向量 16shards |
"bpack.knn.hnsw.space": "cosine", "bpack.knn.hnsw.m": 48, "bpack.knn.hnsw.ef_construction": 600 |
"bpack.knn.cache.item.expiry.time": "1h", "bpack.knn.memory.cache.limit": "15g", "bpack.knn.memory.cache.expiry.time":"1h", "bpack.knn.memory.circuit_breaker.limit" : "70%" |
99.99% | 20.26ms | 609.56ms |
算法总结
-
linear算法适用场景:
- 数据量小(通常单分片在100w以下);
- 先执行正常的搜索过滤条件,然后在过滤后的结果集上进行向量检索计算;
- 召回率100%,查询性能相比hnsw较慢
-
hnsw算法适用场景:
- 数据量相对大(集群数据量在千万级);
- 向量检索计算和其他过滤同时进行,建议适当的增大hnsw的查询参数k,以保证尽可能多的满足过滤条件的数据参与计算;
- 查询性能要求高,召回率在90%以上
典型实践
- 建议写入结束后,在业务低峰期进行定期forceMerge,有助于降低查询延迟。
- 使用linear算法查询时,要根据数据量大小,定义好"bpack.knn.memory.cache.limit"参数。比如节点数据量为10G,如果使用"bpack.knn.memory.cache.limit"的默认值(计算2型默认值为30G*10%=3G),则会无法缓存。当大量查询时,有可能触发Elasticsearch的熔断操作,报错circuitBreakingException。
-
当构建较大数据量的向量索引时,可能会出现build较慢的情况,可以根据分片数和节点cpu核数,在写入数据前适当调整"bpack.knn.hnsw.index_thread_qty" 。例如,1kw数据量,1节点2分片,节点为16核cpu,我们可以把"bpack.knn.hnsw.index_thread_qty" 设置为4-6(如果设置为8,会使cpu满载,生产环境可能有风险),可以提高构建效率。
需要注意的是,"bpack.knn.hnsw.index_thread_qty" 参数设置偏大,会导致构建时启动线程过多。在负载比较高的集群,不建议调整这个参数,以免集群满载。如果写入和构建向量索引偏慢,可以通过临时减少集群负载(减少其他写入和查询),并调大"bpack.knn.hnsw.index_thread_qty"的方式来加快构建 ,等到构建结束,再将"bpack.knn.hnsw.index_thread_qty" 调整回1。
-
当写入数据量为1kw条(比如约为10G)、1节点1分片、计算2型节点(16核cpu、64G内存)时,推荐参数设置为:
Plain Text1PUT /_cluster/settings 2{ 3 "persistent" : { 4 "bpack.knn.hnsw.index_thread_qty" : 1, 5 "bpack.knn.cache.item.expiry.time": "1h", 6 "bpack.knn.memory.circuit_breaker.limit" : "70%" 7 } 8}
Plain Text1 分析: 2 3 1. `"bpack.knn.hnsw.index_thread_qty" : 1`:通常情况下,建议设置为1;当索引构建过慢,可以参考上一条建议适当调整这个参数。 4 2. `"bpack.knn.cache.item.expiry.time": "1h"`:可以根据自己需求的业务设定超时时间。 5 3. `"bpack.knn.memory.circuit_breaker.limit" : "70%"`:计算2型Elasticsearch的默认jvm内存为30G。"bpack.knn.memory.circuit_breaker.limit"为 70%*(64-30)=23.8G,可以容纳数据所占据的堆外内存。
常见问题
-
Q:召回率是怎么定义的?
A:用同样的向量查询两种查询方式,对比召回的文档,取二者相同的文档与召回文档总数的比值,即为待测向量的召回率。我们用召回率来表征查询的准确率。
-
Q:为什么写入已经成功完成,索引的文档数并没有增加或完全达到写入量,且此时可能会查询失败?
A:向量索引的构建发生在refresh或flush期间,虽然写入已经完成,但后台的向量索引构建任务可能仍然在继续。
-
Q:如何安装向量检索插件?
A:新申请的7.4.2\7.10.2集群,自带向量检索插件;如果您需要在集群安装向量检索插件,可以联系客服协助安装。
评价此篇文章