
边缘Kafka
更新时间:2024-11-01
概述
百度边缘Kafka产品最初是为处理海量日志而设计的,但随着其功能的不断扩展,它已成为一个分布式、基于发布/订阅模式的消息系统,广泛应用于大数据实时处理领域。在边缘计算环境中,能够高效地收集、处理、传输和存储来自物联网设备的数据,实现低延迟、高可靠性的数据处理能力。
优势
- 高吞吐量:Kafka单机每秒可以处理几十上百万的消息量,并且即使在存储TB级别的消息时,也能保持稳定的性能。
- 持久化与可靠性:Kafka将消息持久化到磁盘,并通过数据复制机制确保数据的安全性和可靠性,即使在节点故障时也能保证数据不丢失。
- 分布式架构:支持横向扩展,能够轻松增加节点以满足不断增长的业务需求。
- 实时性:支持高速数据流处理,适用于实时预测、异常检测等应用场景。
- 灵活性:解耦生产者和消费者,提高系统的灵活性和扩展性。
适用场景
-
活动跟踪
用户与前端应用程序发生交互,前端应用程序生成用户活动相关的消息,通过百度消息服务的发布/订阅模型,由后端应用程序进行读取、处理。
-
流计算处理
对于实时风控、实时监控等场景,数据实效性要求较高。百度消息服务可对接百度MapReduce提供的Spark Streaming或者Flink实现数据实时处理。
产品定价
百度边缘Kafka产品的定价会根据不同的服务规格和使用量进行计费。具体参照官网。
快速入门
1.登录百度智能云BEC控制台。
2.进入BEC控制台,在页面左侧导航栏中,选择边缘大数据=>点击边缘Kafka进入到创建页面。
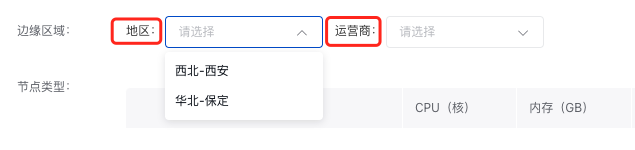
4.您可在边缘区域选择地区和运营商。
5.完成上述操作您可通过快速入门,快速创建所需的数据库实例并连接到实例。详情请查看快速入门
相关概念
-
消息
Kafka中的基本数据单位,包含键、值、时间戳等信息。
- 生产者
向Kafka发送消息的客户端。
-
消费者
从Kafka读取消息的客户端。
评价此篇文章