
iOCR自定义平台部署
一、资源规划
资源规划文档旨在系统资源使用层对真实交付场景做产品层面的通用指导
本文档涵盖了构建百度iOCR算子服务所需要的服务器主机、 CPU、内存、 GPU、网络等内容方面的规划。 本文档所列出的所有数量数字方面的值均需针对实际场景需求和限制做针对性调整。
名词定义
| 名称 | 含义 |
|---|---|
| 鉴权服务 | 鉴权服务包含百度发布的服务授权证书,如果没有安装鉴权服务,后续的应用服务也将无法启动,目前支持加密狗和提取机器指纹两种鉴权方式 |
| 应用服务 | 包含Docker等基础环境以及相关技术方向的算法模型,是私有化产品的的核心。部署应用服务的前提是部署鉴权服务,应用服务在运行时会实时请求鉴权服务,需要保障两个服务之间能够顺利通信 |
| 单机一键部署 | 适用于鉴权服务、应用服务部署在一台服务器上的场景。即执行一条命令将鉴权服务、应用服务安装完成。 |
| 多机一键部署 | 适用于鉴权服务、应用服务部署在多台服务器上的场景。即执行一条命令将鉴权服务、应用服务安装完成。 |
| 测试环境 | 客户方提供的进行产品、场景测试的环境,一般与生产环境隔离,开发、测试能够方便接触到的环境,对部署的可用性要求较低 |
| 生产环境 | 客户的生产环境,一般的业务系统真实提供服务的环境,具备较高的可用性要求,包括异地多活的灾备要求。一般只有运维人员有该环境的超管权限 |
物理架构拓扑图
文字识别私有化部署产品包含鉴权服务和应用服务,其中
- 鉴权服务通过客户网关系统连接到应用服务器为应用服务提供鉴权认证
- 应用服务部分直接或通过生产级网关被客户业务场景直接使用
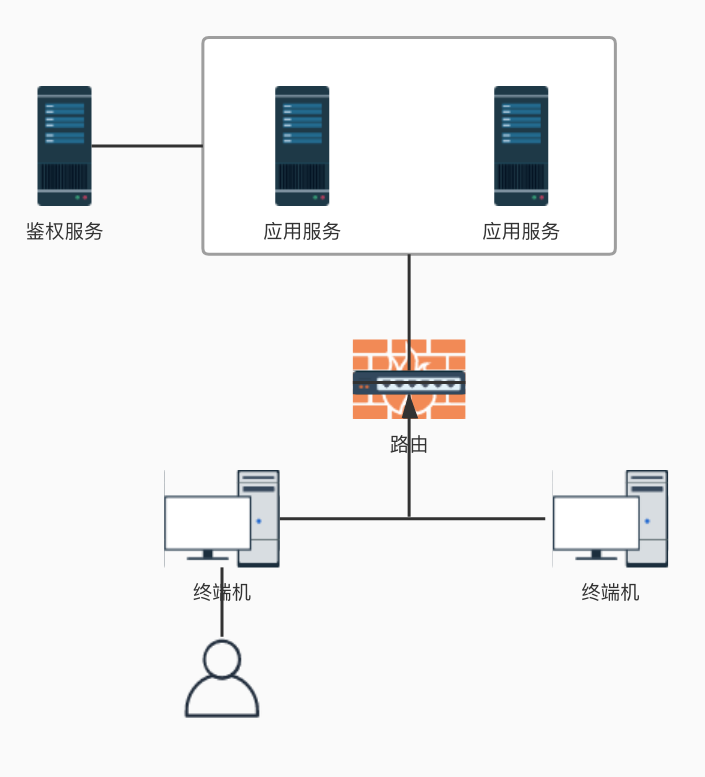
鉴权应用
规划原则
鉴权服务是是您运行文字识别应用服务的基础,如果鉴权异常,将直接导致模型的API接口不可用。鉴权服务健康节点数需满足大于等于N/2 + 1个 (N表示鉴权服务节点总数,并向下取整),如N=2,需保证2个节点鉴权服务都正常才能保证整体鉴权服务可用;如N=3,需保证存在2个节点鉴权服务正常才能保证整体鉴权服务可用,否则直接影响模型应用可用性。
规划流程
一般建议鉴权节点数量为1或3个。
模型算子应用
规划原则
- 单模型应用实例承担流量,根据业务逻辑复杂度(请求报文)、机器节点硬件条件(CPU、内存、网络、显存)强相关
- 单模型应用实例的内存分配依赖模型的大小
- 单模型应用实例的CPU资源与请求报文相关
- 单模型应用实例占用网路IO与请求报文和返回结果相关
- 单模型应用实例占用磁盘空间大小与请求报文、日志输出量等特性相关
- 场景需要的模型应用服务资源与整体业务QPS、单模型实例性能、高可用方案相关
规划流程
根据实际场景进行性能测试,得出单模型实例性能指标(QPS、响应延时、内存占用、显存占用),结合场景高峰流量预估和高可用要求,以及服务器实际显卡数量等计算需要模型应用实例数,根据机器节点硬件资源指标,最终确定硬件节点数。
应用服务资源规划示例
| 资源需求 | 部署模块 | 节点数 | 单节点CPU | 单节点内存 | 单节点存储 | 单节点网络 |
|---|---|---|---|---|---|---|
| 测试环境 | Mysql Redis iocr-api iocr-task iocr-train general-ocr-* Docker |
1 | 4核 | 8G | 50G | >1000Mbps |
| 生产环境 | Mysql Redis iocr-api iocr-task iocr-train general-ocr-* Docker |
N | 8核 | 16G | 500G | >1000Mbps |
以上资源数值为推荐参考值,可根据实际情况做测试和调整。
二、场景与名词
场景说明
- (无环境)全新部署:服务器环境为第一次部署,该服务器之前没有部署过任何百度iOCR自定义模板识别产品。
名词解释
| 名词 | 说明 | 示例 |
|---|---|---|
| package_dir | 存放部署包的路径、包体积较大,尽量不要放在/下 | 如 /mnt/disk0/baidu_ocr_install_20111009,以日期命名 |
| work_dir | 应用程序文件存储地址,默认为/home/baidu/work | 如 /home/baidu/work |
三 、准备工作
请您在部署前务必参考此文档部署前环境检查必看进行硬件、网络、及软件环境检查,以避免在安装部署过程中出现问题。
四、全新部署:
获取部署包
1、申请正式模型部署包安装文件下载链接,下载模型部署包。具体可参考:
1# 示例如下,-O --output-document=FILE 对文件重名名,O为大写英文字母
2# 请将示例中的9C20XXXXXXXX.tar.gz替换为真实的文件名
3wget -O 9C20XXXXXXXX.tar.gz https://bj.bcebos.com/v1/private-ai-online/9C20XXXXXXX.tar.gz?authorization=bce-authXXXXXXX132187fcf81 2、将9C20XXXXXXXX.tar.gz上传到待部署的服务器中,建议以【baiduocr_install + 日期】命名,如 baidu_ocr_install_20111009,该目录我们称之为package_dir
3、进入package_dir 执行以下命令解压部署包
1cd baidu_ocr_install_20111009 && tar zxvf 9C20XXXXXXXX.tar.gz4、解压后进入original目录执行bash download.sh命令获取全部安装文件,执行脚本后会自动下载以下安装文件:数据库服务安装包、鉴权服务安装包、应用服务安装包以及docker安装包等基础依赖环境。如果已经提前下载完毕,请忽略该步骤。
1cd original && bash download.sh同时会在download.sh同级目录下生成download.log日志记录下载详情。
若您在此过程出现问题,请提交工单联系百度的工作人员
5、下载iOCR私有化部署工具包
包含初始化环境变量脚本和算子服务验证代码demo,下载地址:iOCR私有化部署工具包,将下载的zip包上传至待部署的服务器并解压
初始化环境变量
找到上一步下载的iOCR私有化部署工具包文件存储路径,进入解压后的“初始化环境变量脚本”目录
1、修改env_local.config, 压缩包里有初始化环境变量的shell脚本env_local.sh,可根据需要修改env_local.config里的配置,该config默认是本地ip和服务默认端口。
脚本配置修改说明:
a) 默认shell脚本配置为env_local.config,里面的预设的ip都是127.0.0.1,端口都是微服务默认的端口。
b) 如果需要修改ip,打开env_local.config根据实际情况修改即可。
c) 如果服务器ip可能变动,可以将ip设置为docker网桥ip,默认为172.17.0.1
ps:脚本里的各个参数说明见下文:
点击查看参数说明
| 参数名 | 说明 |
|---|---|
| OCR_SERVICE_ADDRESS | OCR高精度文字识别模型的ip:port。 多ip:port的情况下以 | 分割。 OCR高精度模型的默认端口8127。 |
| OCR_HAND_WRITE_SERVICE_ADDRESS | OCR手写文字识别模型的ip:port,没有购买手写模型的话该参数与高精度模型一致。 OCR手写模型默认端口8017. |
| REDIS_TYPE | Redis的形式,单机为proxy,集群为cluster。 |
| REDIS_NODES_ADDRESS | Redis节点ip:port,以 ; 分割。Redis默认端口6379 |
| CONTENT_OCR_S2_SERVICE_HOST | 财务票据识别模型ip:port。 财务票据识别模型默认端口8130 |
| VEHICLE_INVOICE_SERVICE_HOST | 机动车销售发票模型ip:port,机动车销售发票模型,默认端口8132. |
| PRESET_TEMPLATE | 对应模型能力的预置模板,具体参数值见下方。 |
PRESET_TEMPLATE 具体值参见:
| 模板名 | 对应值 |
|---|---|
| 增值税模型 | vat_invoice |
| 机动车销售发票模型 | vehicle_invoice |
| 火车票模型 | train_ticket |
| 行程单 | air_ticket |
多个模板以|分割,例如:vat_invoice|train_ticket|air_ticket
2、执行shell脚本导入环境变量。
1source env_local.sh 3、查看环境变量是否成功导入
1sh print_env.sh 主要确认ip端口是否输入错误
正式安装
找到模型部署包的存储路径 package_dir,然后按照如下步骤操作:
1、进入package_dir开始进行鉴权服务和iOCR服务的一键部署。首先进入以下文件路径;
1# 进入上一步以日期命名的部署包目录
2cd baidu_ocr_install_20111009 && cd original/package/Install使用root权限启动一键部署脚本进行安装:
如果您只有一台服务器,可以使用inall参数来部署,inall 表示install all,安装所有的产品以及鉴权服务和基础服务,适用于在单台服务器上安装所有模块的场景,容易和 install混淆,在使用时请注意。
1# inall: 安装所有的产品以及鉴权服务和基础服务,适用于在单台物理机上安装所有模块的场景
2python install.py inall安装过程中可能会遇到以下情况:
a)
此处尝试输入continue,如果continue以后部署失败,请联系支持人员排查问题。
b) 选择是否初始化数据库:
initialize database for iocr-web ? [y/n]
如果是第一次安装部署,选择是,输入:y,如果不是第一次安装部署,选择否,输入n。
c) 选择模型占用的gpu显卡。
输入显卡号即可。(注意如果需要多个模型记得一个模型需要独占一张卡)

2、确认本次安装模块是否完整:
执行docker ps -a 查看正在运行的docker容器否包含以下且状态均正常:
| 容器名 | 说明 |
|---|---|
| iocr-web | 页面服务 |
| iocr-api | 接口服务 |
| iocr-task | 任务服务 |
| iocr-train | 训练服务 |
| mysql | 数据库 |
| redis | redis服务 |
| general-ocr-* | ocr模型服务 |
| content-ocr-s2 | 财税模型服务,需要使用预置财务模板时会有该服务,否则不需要该服务 |
如果您想单独卸载并重新安装某个模块,可以先输入se参数
1# se :表示search,根据模块名称查询安装包里是否包括某个模块,不区分大小写,如果没有指定名称则输出安装包里所有模块信息
2python install.py se 来检索当前模型部署包内包含哪些模块,如:
1……
2模块名: openresty, 内置版本 7, 依赖模块 []
3模块名: docker, 版本号:1.0, 内置版本 5, 依赖模块 []
4……如卸载openresty,可以执行如下命令(此处仅为示例,实际操作中根据需要执行)
1# rm :remove, 根据模块名称删除某个已经安装的模块;如果有其他模块依赖这个模块,则不允许删除
2python install.py rm openresty重新安装openresty,则可以执行(此处仅为示例,实际操作中根据需要执行)
1# in :install, 安装某个模块,名称不区分大小写
2python install.py in openresty五、web页面验证
验证步骤:
1、页面地址:http://ip:8084/iocr
2、默认的登录用户名和密码请联系技术支持同学
3、上传一张合法模板图(base64以后小于4M并且最长边不大于4096)(IOCR辅助脚本压缩包里附了一张模板图),
上传成功后,框选合适的参照字段。
参照字段如何框选?
1)框选4个以上参照字段,并尽量分散在四角
2)保证框选的文字内容、位置固定不变
3)单个参照字段不可跨行
4)选取图片中不会重复出现的文字
5)仅支持中英文、数字,不可包含符号、图案
如下图示例,参照字段不会重复出现,位置固定,且较为分散,将参照字段连起来可以构成饱满的多边形

如上传失败排查步骤见下方:
上传图片失败排查步骤
a) 可能是部署前的环境变量出错,查看日志/home/baidu/work/iocr-wen/logs/server.log,搜索错误信息,出现Fail to Connect然后异常信息中的ip:port信息不正常就是环境变量出错,需要修改配置文件,请联系技术支持同学协助解决。b) 可能是ocr模型出问题,服务器上docker ps -a 查看image-name中带着general-ocr的镜像状态是否为existed,如果的确如上描述,可以联系支持人员查看是否为模型问题或鉴权问题。
4、模板是按用户隔离的,如果需要新增修改删除用户,详细操作如下:
新增、删除、修改用户操作步骤
a) (使用部署包自带的mysql的情况)服务器上进入mysql镜像, 参考命令: `docker exec -it mysql /bin/bash`b) 登录数据库,相关用户密码请联系百度技术支持同学
参考命令:
mysql -uroot -p
或
mysql -uaipe -p
c) 选择数据库,参考命令:use d_ai_check;
用户表为tb_ocr_user,新建用户直接插入记录
1INSERT INTO `d_ai_check`.`tb_ocr_user`(`user_name`, `password`) VALUES ('sjy2', 'test2');d) 修改删除操作也是直接sql操作就好
操作教程参考线上文档:
https://ai.baidu.com/docs#/iOCR-General-Step/top
六、API接口调用
请求示例:
HTTP 方法:POST
请求URL:
http://ip_address:8085/api/v1/solution/iocr/recognise
URL参数:
| 参数 | 说明 |
|---|---|
| ip_address | 机器IP地址 |
Header设置:
| 参数 | 说明 |
|---|---|
| Content-Type | application/x-www-form-urlencoded |
请求参数
| 参数 | 说明 |
|---|---|
| appid | 用户id,对应账户表里的id字段,默认账户的appid为1 |
| templateSign | 模板id,非必填 |
| classifierId | 分类器id,非必填,每次请求模板id和分类器id至少存在一个 |
| image | 图片的base64码 |
返回结构同线上,参考:https://ai.baidu.com/ai-doc/OCR/Ek3h7y961
错误码说明:
同线上,参考:https://ai.baidu.com/ai-doc/OCR/Ek3h7y961
python语言请求demo使用说明:
验证操作步骤:
- 前面页面验证时创建编辑并发布的模板的templateSign复制粘贴到脚本python2_private_demo.py里的变量template_sign。
- ip修改:默认为127.0.0.1,根据实际情况修改。
- 图片修改,如果页面服务验证时使用的是压缩包内的图片,此处可以填压缩包内另一张图片的路径。
- 运行脚本,python python2_private_demo.py
- 返回json的errorCode等于0即为成功。
更多语言的demo参考线上文档:
https://ai.baidu.com/ai-doc/OCR/yk3h7y9u3
七、运维
您可以前往「私有化部署服务」/「常见问题」查找常见问题排查思路
您可以前往 「私有化部署服务」/「运维手册」查看常用运维文档
评价此篇文章