
新手操作指引
本文主要介绍如何快速开通文字识别服务,完成接口调用。
一、注册及实名认证
使用百度智能云文字识别服务前,您需要一个百度智能云账号并完成实名认证。具体操作如下:
- 注册并登录百度智能云平台,请参考注册和登录。个人用户可以直接使用自己的百度账号进行登录,企业用户建议注册账号,避免后续人员变动带来的账号归属问题。
- 完成实名认证,操作细节请参考实名认证。只有完成了实名认证才能购买并使用文字识别服务。
二、领取免费测试资源
登录并进入文字识别控制台。如果您的账号已完成实名认证,系统会自动为您的账号发放免费测试资源。测试资源会在您进入控制台后约10分钟内发放。
领取到的免费资源可以在资源列表里查看。
三、创建应用
应用是调用服务的主体,您可以划定该应用有权限调用的接口范围,以此实现权限管理。后续也可以查看每个应用上产生的接口调用量。
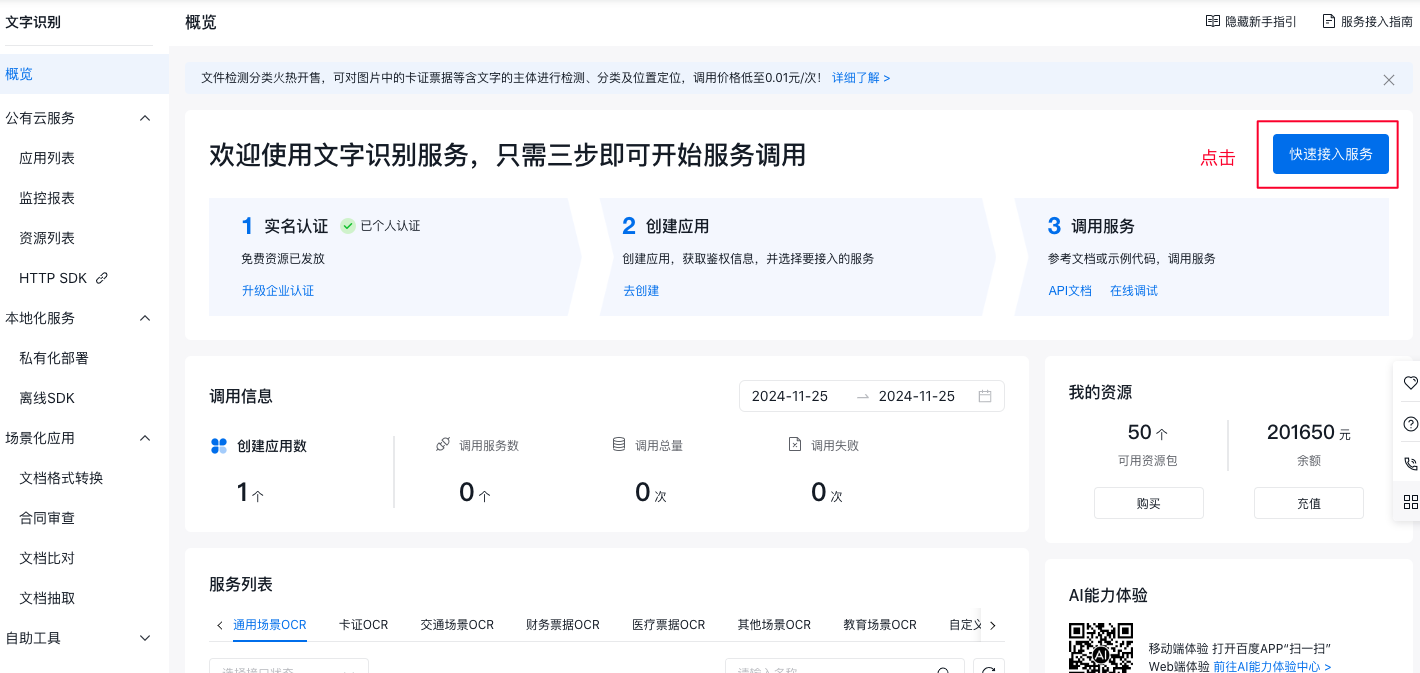
方式一:在概览页上快速创建应用
进入文字识别控制台,点击使用指引模块的快速接入服务按钮。
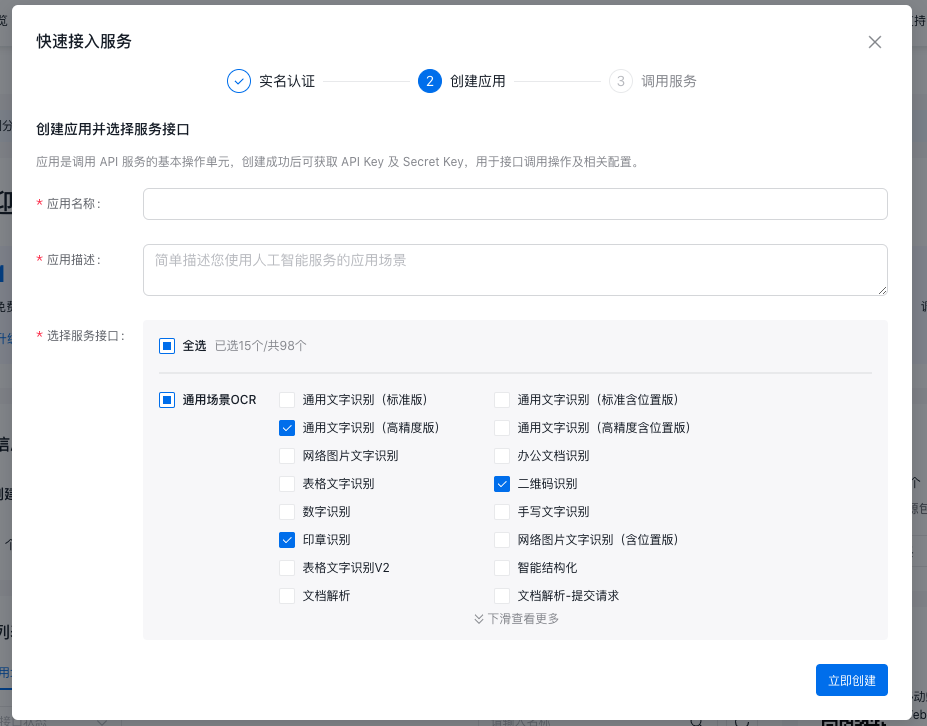
应用名称和应用描述应当尽量反应应用的实际用途,方便您后续管理应用。在服务接口列表勾选您希望该应用能够调用的接口,勾选完毕后点击"立即创建"。
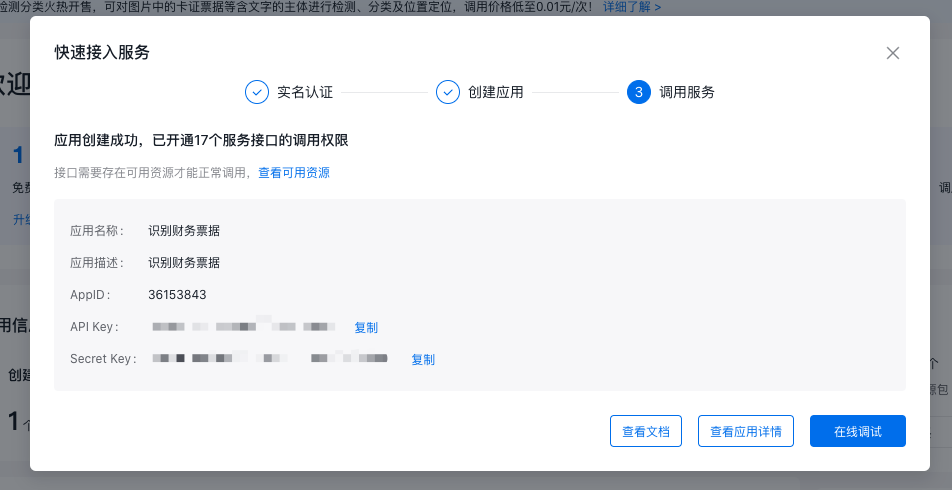
创建成功!API Key和Secret Key是您调用该应用内接口的凭证,如果泄露会导致资源被盗刷,请妥善保管,避免外泄。
本方式创建的应用只能选择当前产品方向的服务接口。如果您希望创建跨产品方向的应用,请参考下面的方式二。
方式二:在应用管理页创建应用
进入文字识别控制台,选择左侧导航的"应用列表",点击"创建应用"。
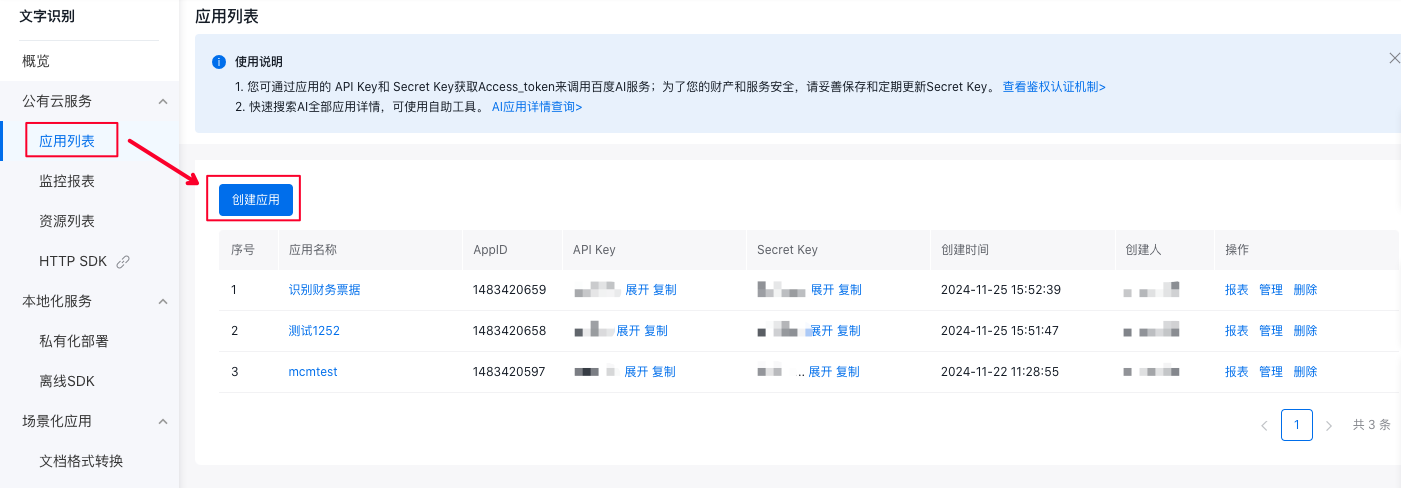
应用名称和应用描述应当尽量反应应用的实际用途,方便您后续管理应用。在服务接口列表勾选您希望该应用能够调用的接口,勾选完毕后点击"立即创建"。
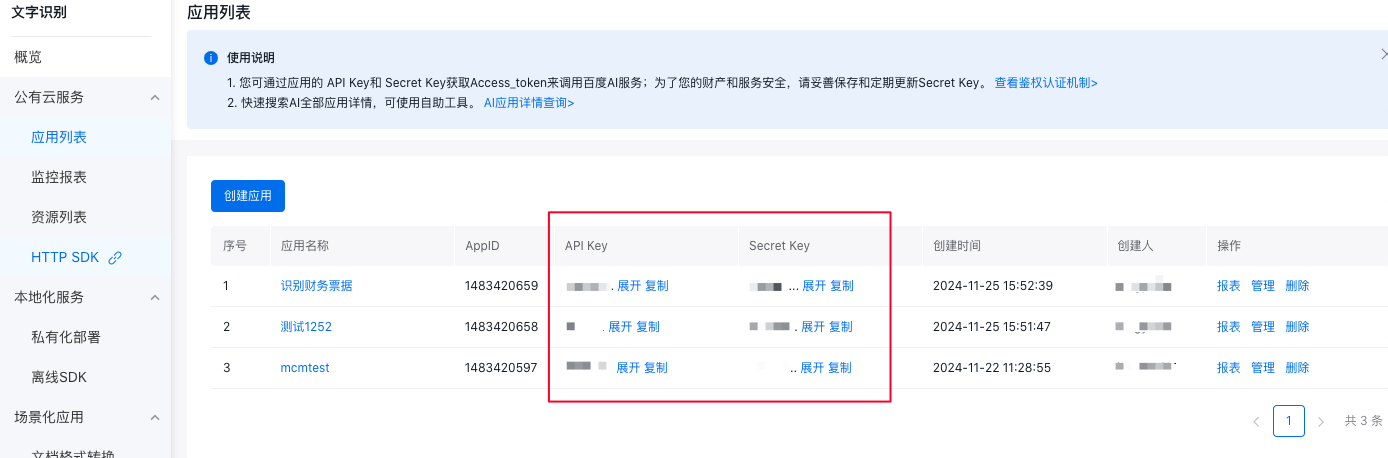
创建成功后,您可以在应用列表页里查看应用的API Key和Secret Key。API Key和Secret Key是您调用该应用内接口的凭证,如果泄露会导致资源被盗刷,请妥善保管,避免外泄。
四、调用接口服务
您可以根据以下介绍选择合适的使用方式:
- 通过 百度智能云 - 示例代码中心 在线调用文字识别服务 API
如果您是开发初学者,对HTTP请求与API调用有一定的了解,您可以通过此方式快速体验文字识别服务。该方式无需编码,只需要输入相关参数,即可在线调用API,并查看返回结果。视频教程请参见如何使用 API Explorer 调用API接口(视频版)。
- 通过可视化工具(如 Postman)调用文字识别服务 API
如果您是开发初学者,熟悉HTTP请求与API调用,您可以通过 Postman 调用、调试 API。具体请参见如何使用 Postman 调用文字识别服务。
- 通过编写代码调用文字识别服务 API
如果您是开发工程师,熟悉代码编写,您可以通过编写代码的方式调用文字识别服务。具体请参见如何使用代码快速调用文字识别服务 API。
- 通过软件开发工具包(HTTP-SDK)调用文字识别服务
如果您是开发工程师,熟悉代码编写,您可以通过已编写好的软件开发工具包(HTTP-SDK)来调用文字识别服务 API。SDK 已支持多种语言,包括 Java、 Python、PHP、C++、C#、NodeJS、Android ADK、iOS SDK 等。您可点击下载对应的 SDK。
了解更多
示例源代码
您可以在我们的官方 github 上下载示例源码。
https://github.com/Baidu-AIP/QuickStart/tree/master/OCR
更多参考
评价此篇文章