
通过自定义算子实现第三方模型服务调用
前提条件
- 已开通BOS、OOS、BLS权限。
- 已完成资源环境准备。
- 已将待测试PDF上传至元数据-数据卷下。
场景概览
本场景面向需要在数据处理流程中接入第三方模型服务能力的用户,通过自定义算子对外部 AI 服务进行标准化封装,实现模型能力在工作流中的统一调用。
用户可基于自定义算子框架,将第三方服务(如 PDF 解析、OCR、文本生成、多模态理解等)封装为标准 Transformer 算子,并在数据处理流水线中直接调用,无需关心底层请求构造、任务调度与结果轮询等实现细节。通过该方式,可以将外部模型能力无缝接入平台工作流与数据处理链路,实现实现外部模型能力的标准化复用与工程化封装。
自定义算子物料包
| 物料项 | 链接 | 描述 |
|---|---|---|
| 镜像 | https://operator.bj.bcebos.com/release/base_image/0.7/base-imgae-0.7.tar?authorization=bce-auth-v1%2FALTAK9KApiyYtkuoNE78fPPW0M%2F2026-05-27T02%3A19%3A38Z%2F-1%2Fhost%2F8500e8394a5167d1409d2a91106339002bda6466bdc0bb1086e86506285297c7 | md5:7b1cd7b42b0fdf3ee712e264e420c46e 镜像中的重点软件版本如下: nvcc==12.4 python==3.10.12 torch==2.5.1 transformers==4.47.1 paddlepaddle==3.1.0 onnxruntime==1.21.1 * opencv-python==4.11.0.86 |
| 自定义算子样例包 | /root/databuilder_dev | 内置在算子镜像中,算子镜像创建的容器路径 |
| https://operator.bj.bcebos.com/release/operator/databuilder_dev-v0.3.2.tar?authorization=bce-auth-v1%2FALTAKRDyrIQOaBuxqyREAShe7e%2F2025-12-26T03%3A29%3A01Z%2F-1%2Fhost%2Fd62a50cc27701605487f9f59ea7b5192f31fc8a7151b52f0d5889c5bc52f457d | v0.3.2版本自定义算子样例包 |
操作步骤
步骤一:自定义算子准备工作
软件环境准备
- 按照下面的步骤,完成自定义算子容器创建,后面的算子开发、测试、打包都在自定义算子容器内完成
展开镜像
使用如下命令将算子镜像tar包展开为本地镜像,此命令需要在物理机上执行
1# 1. 下载模型包
2wget -O db_operator_dev.tar "上述物料中镜像链接"
3# 2. 进入算子镜像tar包所在目录
4cd /xxx
5# 3. 展开镜像
6docker load < ./db_operator_dev.tar- 镜像展开的时间约5分钟,可以通过下面的命令检查镜像是否成功展开
1docker image ls | grep iregistry.baidu-int.com/doris-rdw/algorithm/operator- 镜像成功展开后会有类似如下输出

创建容器
使用如下命令创建算子开发容器
1docker run -itd --gpus=all \
2--privileged=true \
3--shm-size=64g \
4--net=host \
5--name db_op_dev \
6iregistry.baidu-int.com/doris-rdw/algorithm/operator:0.7 \
7/bin/bash环境验证
算子开发容器创建完毕后,通过如下命令进入容器
1docker exec -it db_op_dev /bin/bash- 进入容器,可以通过镜像预置的自定义算子测试代码验证开发环境
1# 1. 进入阈值自定义算子测试目录
2cd /root/databuilder_dev/tests
3# 2. 运行标点替换算子测试脚本
4sh run_punctuation_replace.sh- 算子运行成功后输出如下内容

预置自定义算子介绍
- 镜像中内置了3个自定义算子(image_resizer/punctuation_filter/punctuation_replacer)

- 3个算子的测试脚本
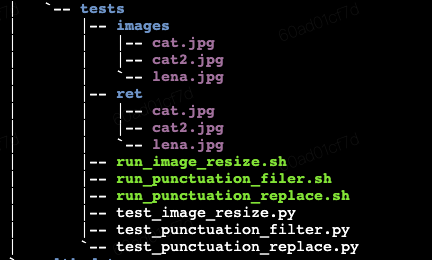
Transformer算子介绍
类属性 - 算子元信息定义
 这些属性定义了算子的基本特性和执行环境配置,是算子框架识别和管理该算子的关键元数据。
这些属性定义了算子的基本特性和执行环境配置,是算子框架识别和管理该算子的关键元数据。
初始化方法 - 参数设置与预处理
 初始化时完成:
初始化时完成:
-
参数传递
- 通过
*args, **kwargs隐式支持父类参数(如text_key指定文本字段名) - 无显式参数,简化调用接口
- 通过
-
预处理优化
- 正则预编译:在初始化时编译
r'([^\w\s])+'模式,提升运行时性能 - 模式语义:匹配所有非字母数字(
\w)且非空白(\s)的连续字符
- 正则预编译:在初始化时编译
-
资源准备
- 无外部资源依赖(如模型加载),轻量级初始化
核心处理方法 - 单样本处理逻辑
 处理流程:
处理流程:
-
输入输出结构
- 输入:要求
samples为字典,且包含self.text_key指定的文本列表 - 输出:保持原数据结构,仅更新文本内容
- 输入:要求
-
核心逻辑
- 正则替换:使用预编译模式匹配标点符号
- 等量空格替换:通过
lambda动态生成与匹配项等长的空格(如...→) - 列表推导式:高效实现批量处理
接口调用示例
1# 1. input data
2 samples = [
3 {
4 'images': './images/cat.jpg'
5 },
6 {
7 'images': './images/cat2.jpg'
8 },
9 {
10 'images': './images/lena.jpg'
11 }
12 ]
13
14 input_dataset = RayDataset.from_list(samples)
15
16 # 2. create operator
17 dst_path = './ret'
18 os.makedirs(dst_path, exist_ok=True)
19 op = ImageResizer(width=1024, height=1024, dst_path=dst_path, need_hash_name=False)
20
21 # 3. run
22 output_dataset = input_dataset.run(op)
23
24 # 4. get & check result
25 image_path = output_dataset.get_column(column=op.image_key)
26
27 for name in image_path:
28 image = Image.open(name)
29 print(f'---result image {name} shape: {image.size}')步骤二:自定义算子开发
实现对第三方模型服务的调用,以调用pdf解析服务为例,在catalog_op目录下新建文件夹pdf_parser,代码结构如下:
1|-- catalog_op
2| `-- default
3| |-- image_resizer
4| | `-- v1
5| | |-- __init__.py
6| | `-- image_resizer.py
7| |-- pdf_parser
8| | `-- v1
9| | |-- __init__.py
10| | `-- pdf_parser.py
11| |-- punctuation_filter
12| | `-- v1
13| | |-- __init__.py
14| | `-- punctuation_filter.py
15| |-- punctuation_replacer
16| | `-- v1
17| | |-- __init__.py
18| | `-- punctuation_replacer.py
19| |-- video_frame_extractor
20| | `-- v1
21| | |-- __init__.py
22| | `-- video_frame_extractor.py
23| `-- video_frame_split
24| `-- v1
25| |-- __init__.py
26| `-- video_frame_split.pypdf_parser.py 如下所示
- 根据第三方服务调用方式,撰写核心代码
- SmartFile 是用来下载远程Volume数据的类,使用方式可以参考样例算子
- transform_batched 是核心函数,需要在该函数实现核心功能。
-
算子输入的数据如下所示,分别对应着不同类型的数据
- text_key: text
- image_key: images
- video_key: videos
- audio_key: audios
- document_key: documents
1from palette.ops.base import Transformer
2from palette.util.file_utils import SmartFile
3import os
4import base64
5import time
6import requests
7
8
9class PdfParser(Transformer):
10 """
11 PDF 解析算子
12 功能:
13 1. 读取 PDF 文件(支持 volume 路径)
14 2. 提交到本地 PDF 解析服务(异步任务模式)
15 3. 轮询查询直到任务完成
16 4. 将解析结果(markdown 文本)写入 text 字段
17 """
18 _op_type = "transform"
19 _batched_op = True
20 _processor = 'cpu'
21 _name = "pdf_parser"
22 _ray_execute_mode = "PIPELINE_TASK"
23 _ray_batch_format = "numpy"
24
25 def __init__(self,
26 server_url: str = 'http://xxx:8000',
27 poll_interval: float = 2.0,
28 timeout: int = 300,
29 *args, **kwargs):
30 """
31 :param server_url: PDF 解析服务地址,如 http://xxxx:8000
32 :param poll_interval: 轮询间隔(秒)
33 :param timeout: 单个任务最大等待时间(秒)
34 """
35 super().__init__(*args, **kwargs)
36 self.server_url = server_url.rstrip('/')
37 self.push_url = f'{self.server_url}/v2/models/parser_pdf'
38 self.query_url = f'{self.server_url}/v2/models/parser_pdf/query'
39 self.poll_interval = poll_interval
40 self.document_key = 'documents'
41 self.timeout = timeout
42 self.smart_file = SmartFile()
43 self.download_path = os.path.join(
44 os.getcwd(),
45 os.path.splitext(os.path.basename(__file__))[0]
46 )
47
48 def _submit_task(self, session, local_path):
49 """提交 PDF 文件到解析服务,返回 task_id"""
50 file_name = os.path.basename(local_path)
51 with open(local_path, 'rb') as f:
52 file_data = base64.b64encode(f.read()).decode('utf-8')
53
54 response = session.post(self.push_url, json={
55 'file_name': file_name,
56 'file_data': file_data,
57 'preprocess_info': {'angle_adjust': 'false', 'gray': 'no', 'unwarp': 'no'},
58 'mode': 'professional',
59 'detect_threshold': 0,
60 'process_granularity': 'coarse',
61 'submodel_info': {'layout': 'layout_det_v2'}
62 }, timeout=(5, 120))
63 response.raise_for_status()
64 task_id = response.json().get('id')
65 return task_id
66
67 def _wait_for_result(self, session, task_id):
68 """轮询查询任务状态直到完成,返回结果 dict"""
69 deadline = time.time() + self.timeout
70 while time.time() < deadline:
71 resp = session.post(self.query_url, json={'id': task_id}, timeout=(5, 30))
72 resp.raise_for_status()
73 result = resp.json()
74 status = result.get('status')
75 if status == 'succeeded':
76 return result
77 elif status == 'failed':
78 raise RuntimeError(f'task {task_id} failed: {result}')
79 time.sleep(self.poll_interval)
80 raise TimeoutError(f'task {task_id} timed out after {self.timeout}s')
81
82 def transform_batched(self, samples, *args, **kwargs):
83 file_paths = samples[self.document_key]
84 session = requests.Session()
85
86 result_texts = []
87 for file_path in file_paths:
88 try:
89 # volume 路径下载到本地
90 os.makedirs(self.download_path, exist_ok=True)
91 local_path = self.smart_file.volume_2_local(file_path, self.download_path)
92
93 task_id = self._submit_task(session, local_path)
94 result = self._wait_for_result(session, task_id)
95 content = result['result']['result']['content']
96 except Exception as e:
97 content = ''
98 print(f'[PdfParser] error processing {file_path}: {e}')
99
100 result_texts.append(content)
101
102 samples[self.text_key] = result_texts
103 return samples步骤三:自定义算子打包
打包命令
核心代码撰写完毕后,开始打whl包
1cd /root/databuilder_dev
2sh ./build.sh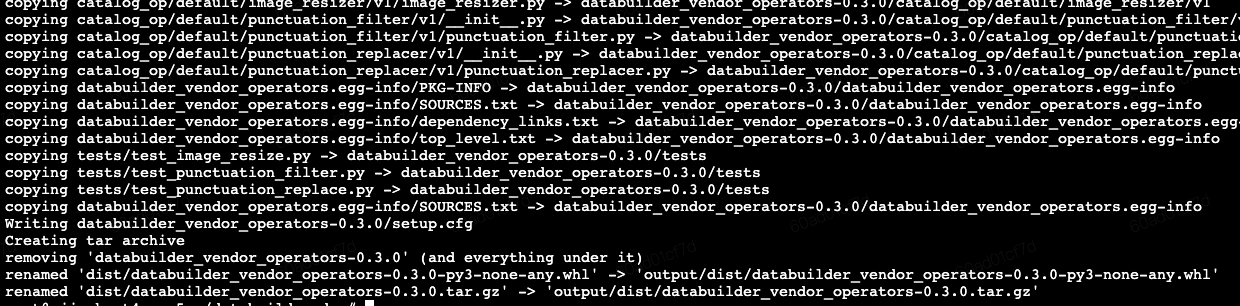
- 生成的自定义算子包whl文件存储在 /root/databuilder_dev/output/dist 路径下

安装whl包
使用如下命令在自定义算子开发容器内按照whl包
1cd /root/databuilder_dev/output/dist
2pip install databuilder_vendor_operators-0.3.0-py3-none-any.whl- 安装完毕后,可以运行 /root/databuilder_dev/tests 路径下的 run_xxx.sh 脚本在本地测试算子
- 算子在本地测试通过后,可以上线到DataBuilder平台
步骤四:自定义算子上线
以pdf_parser算子为例,下面介绍一下算子创建流程。
创建算子
如果要自己新建自定义算子,选择default,点击立即创建-创建算子。

填写信息
填入算子名称和算子别名。
 点击提交并创建算子版本进入,依次填写以下信息。算子类型要写TRANSFORM
点击提交并创建算子版本进入,依次填写以下信息。算子类型要写TRANSFORM

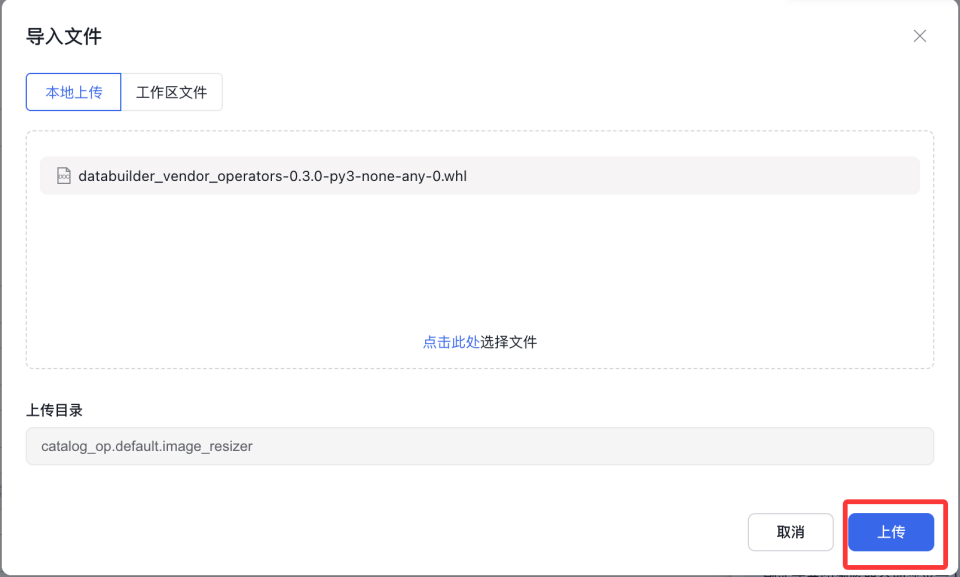
点击添加文件,将whl包导入。
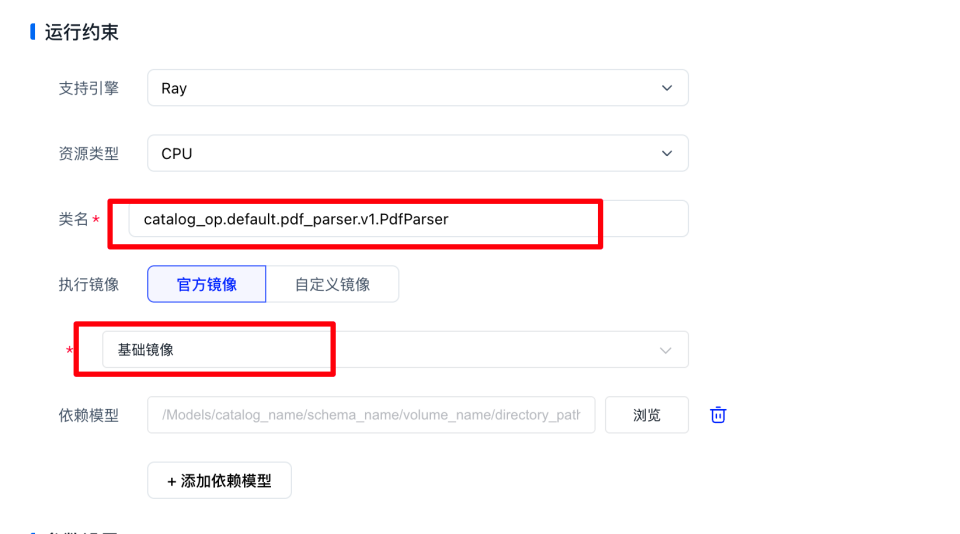
- 【注意】:类名必须是完整的自定义算子whl包+算子类名
保存算子
填写完成后点击保存。保存后的算子可以在以下目录下找到。

步骤五:自定义算子使用
创建工作流
可以点击右侧的创建工作流新建一个工作流。


导入文件元数据加载器和数据输出器
点击【算子任务】后,然后点击小三角,可以打开左侧的【算子节点】列。

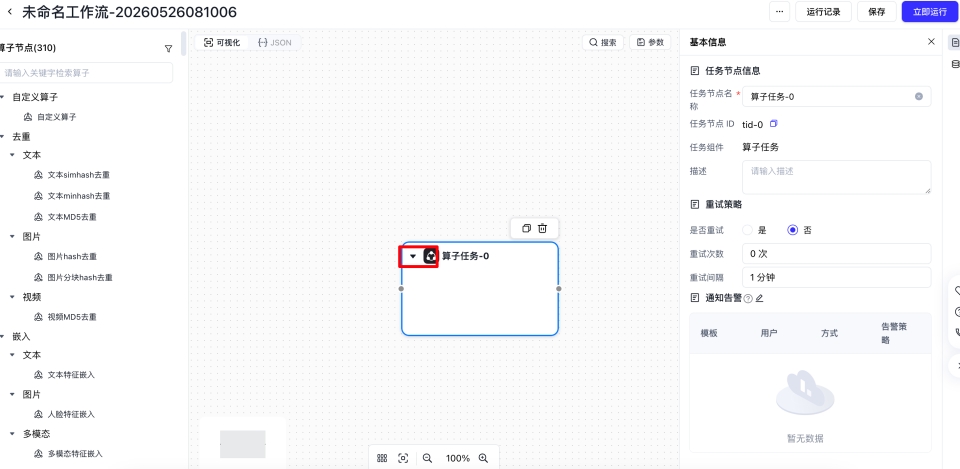
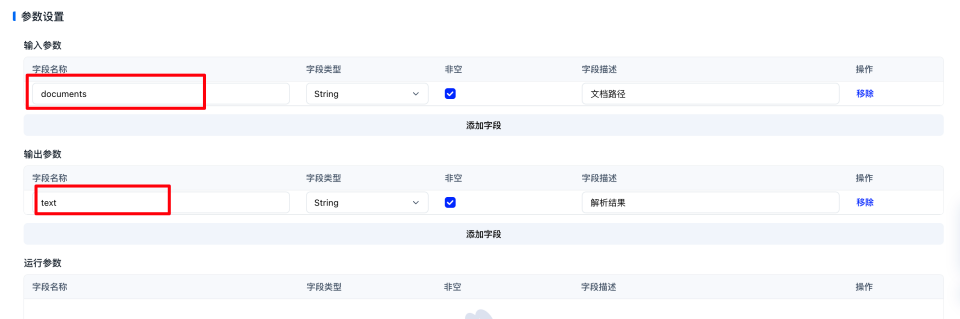
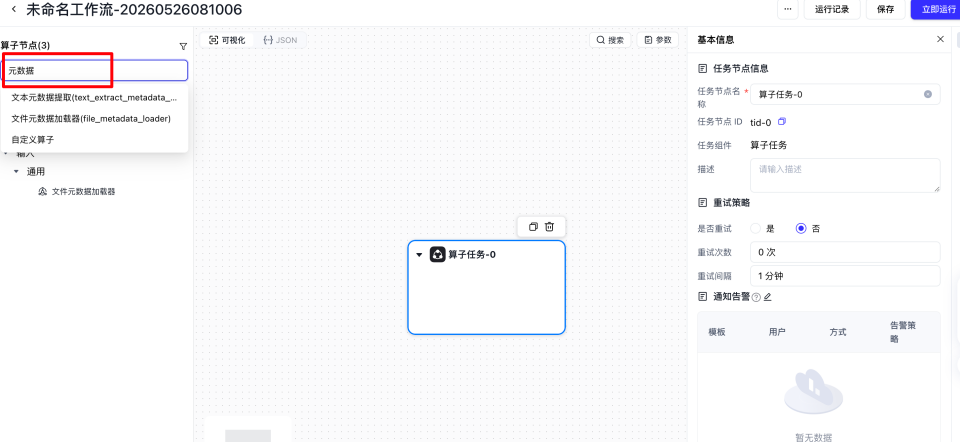
然后在搜索框输入元数据以及输出,将【文件元数据加载器】和【数据输出器】放到画布中。
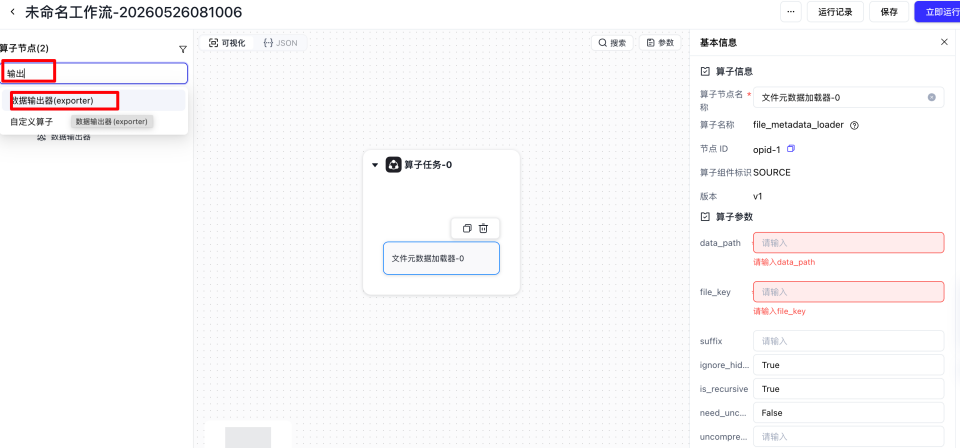
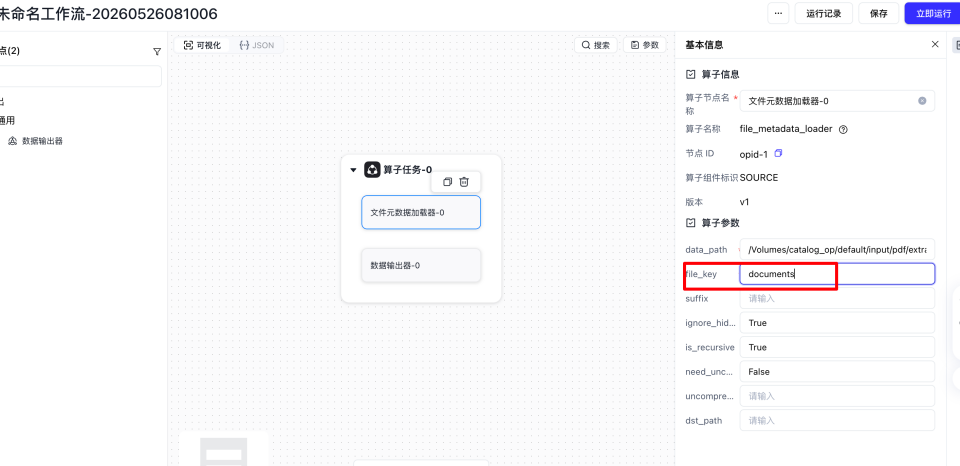
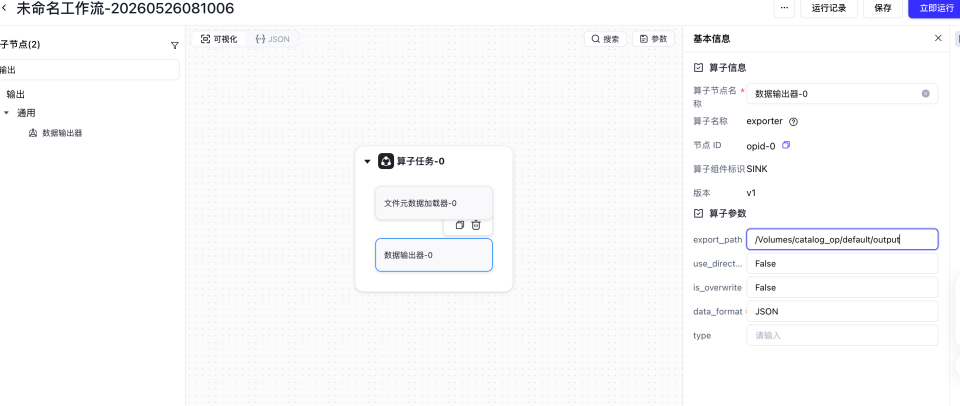
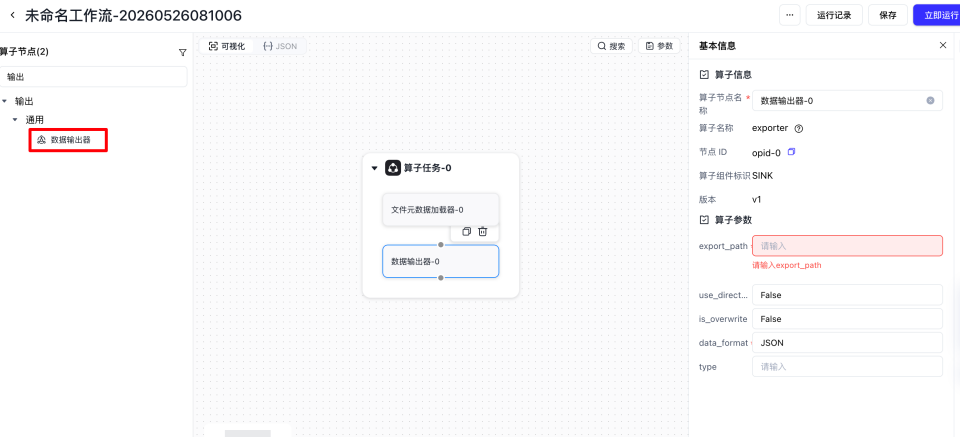 填入输入路径以及输出路径参数
填入输入路径以及输出路径参数
-
file_key要与我们自定义算子接受的xx_key对应的值保持一致,比如我们pdf_parser接受的是file_paths = samples[self.document_key],self.document_key 对应的是 documents
- text_key: text
- image_key: images
- video_key: videos
- audio_key: audios
- document_key: documents
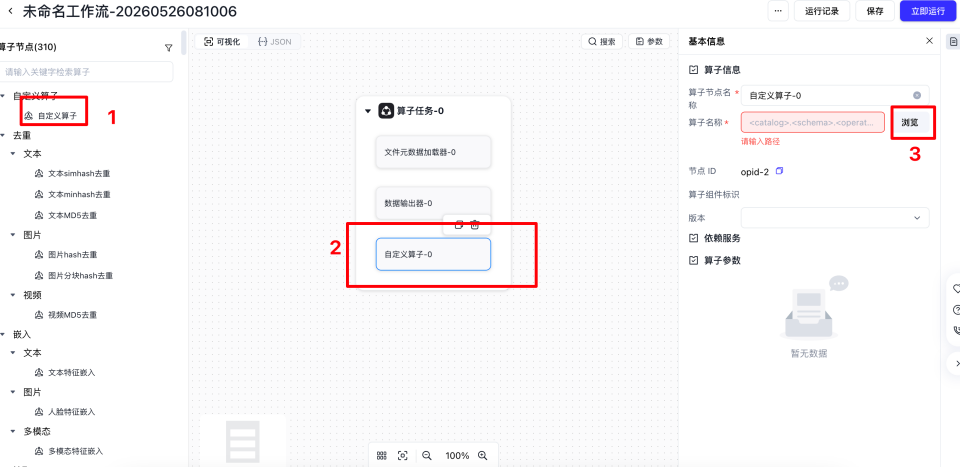
导入自定义算子
点击左侧【自定义算子】,然后点击画布中的【自定义算子】,然后点击【浏览】,选择我们刚才自定义的算子
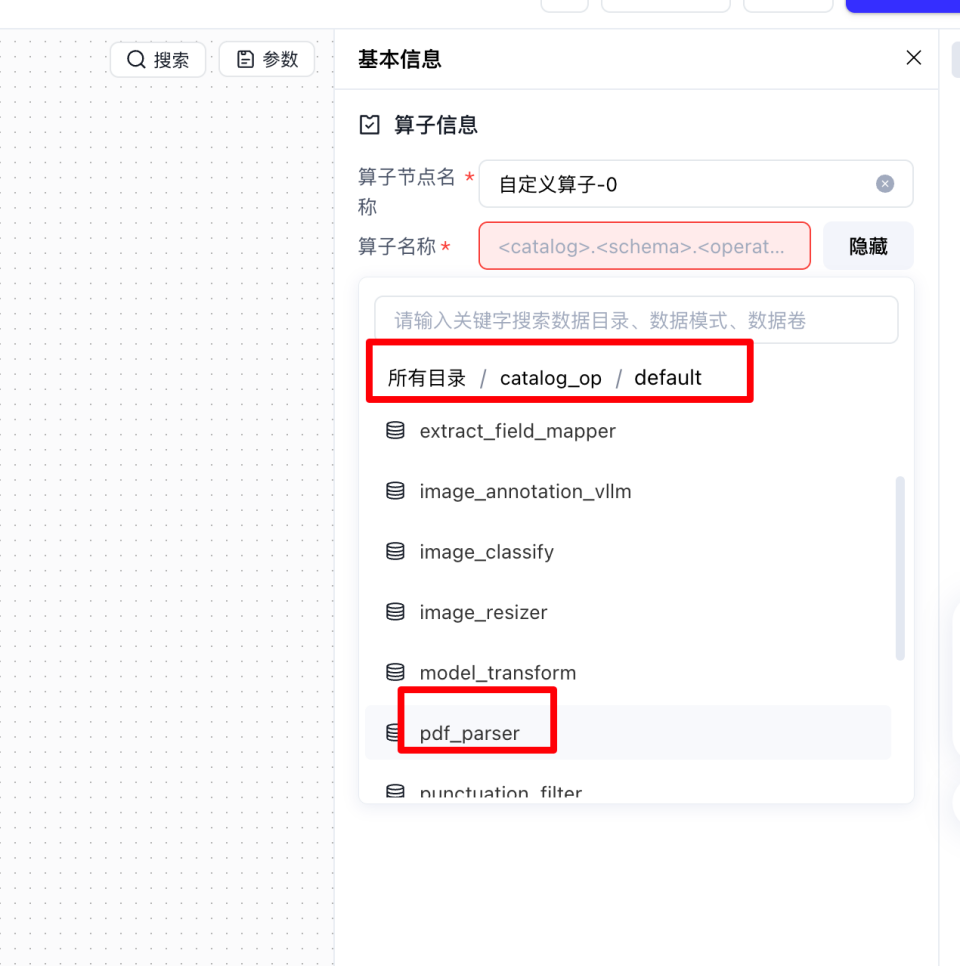 把画布里的算子顺序进行连线调整,然后点击【保存】,并点击【立即运行】,开始跑工作流
把画布里的算子顺序进行连线调整,然后点击【保存】,并点击【立即运行】,开始跑工作流

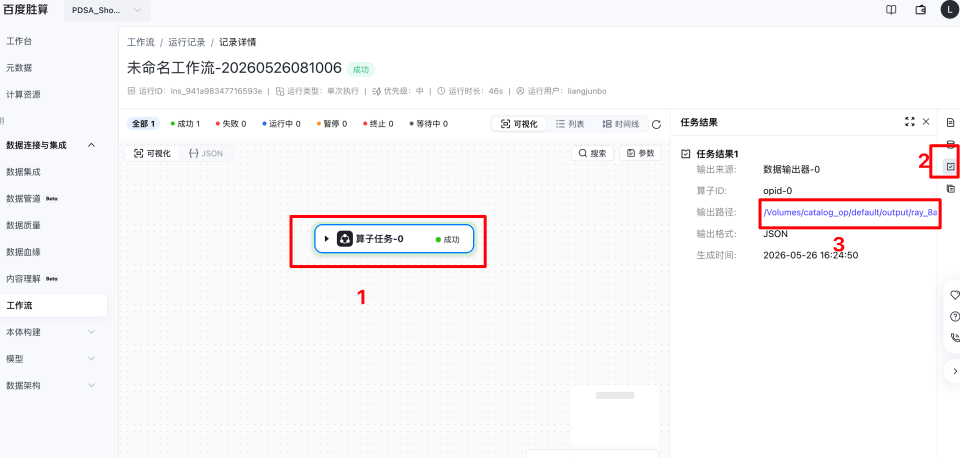
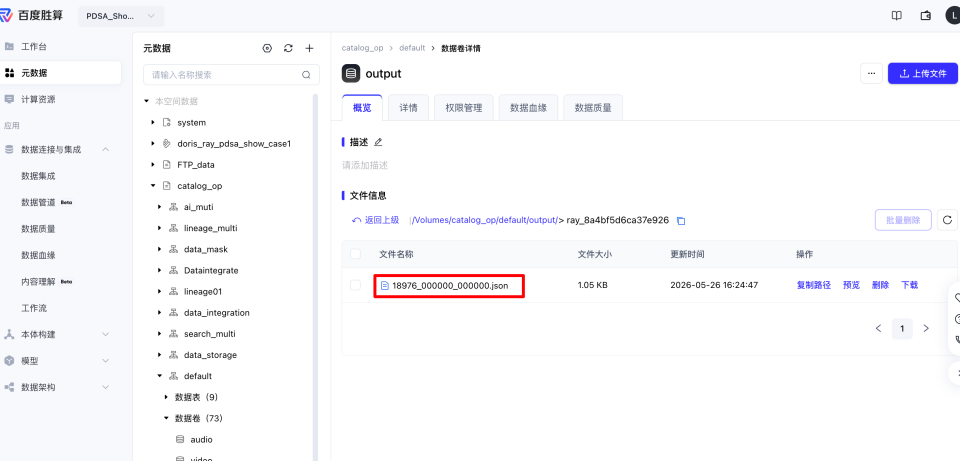
查看工作流运行结束后的输出结果
打开【运行记录】,等运行成功,可以点击查看最终运行结果


评价此篇文章