
预置Data Search设计
检索业务背景

在检索增强生成 的整体架构中,检索层的核心职责是在海量数据中筛选出高信噪比的信息。检索层本质上是在做信息筛选和证据寻址,它决定了系统的“召回上限”和“噪声下限”。
- 决定召回上限 如果检索层未能从海量数据中精准捕获关键事实,即便下游的大模型推理能力再强,也无法在“无米之炊”的约束下生成正确答案。检索层的遗漏,直接等同于系统知识的盲区。难以避免产生幻觉。
- 决定噪声下限 如果检索层无法有效过滤无关信息,它不仅是浪费了宝贵的上下文窗口 ,更是在主动引入噪声。它们往往包含与正确答案相似但主要参数错误的“干扰项”。这些高相似度的噪声极易误导 LLM, 诱导出更多的幻觉
因此,混合检索设计的初衷,就是通过不同算法的互补,最大程度地提升证据的信噪比。
检索能力模型
为了实现高信噪比的目标,我们需要理解并利用两种截然不同但互补的检索方式。
全文检索
全文检索(以 BM25 算法为代表)主要处理的是词法层面的匹配。它不尝试“理解”句子的意思,而是统计查询词在文档中出现的频率和稀缺程度, 并在这个基础上进行打分。
在企业级应用中,很多查询包含着硬约束。
- 专有名词与实体:当用户查询“错误码 504”或“订单号 A-123”时,任何基于语义的模糊推荐都是不可接受的。我们需要文档中精确出现这些字符。
- 罕见词与术语:对于尚未进入 Embedding 模型训练语料库的黑话或新造词,向量检索往往会失效,而全文检索依然可以通过字面匹配精准定位。
但是它极度依赖“词”的重合。如果用户搜“怎么退款”,而文档里写的是“如何申请退费”,由于没有关键词重叠,全文检索可能会完全漏掉这条核心规则。
向量检索
向量检索利用深度学习模型,将文本压缩为高维空间中的向量。在这个空间里,距离越近代表含义越相似。它处理的是语义层面的匹配。
自然语言具有高度的多义性和模糊性。
- 跨越词汇鸿沟:当用户问“那个红色的水果手机”,向量模型能理解他在找“iPhone Red”,即便这两个词在字面上毫无关系。
- 模糊意图捕捉:用户往往不知道准确的专业术语。向量检索允许用户用自然语言描述意图(如“能不能分期付?”),并将其映射到标准文档(如“信贷支付管理规范”)。
它是一个“模糊”的概率模型。有时它会过度联想,把“不可退款”和“可以退款”视为语义极其相近(因为它们讨论的话题一致),这在某些严谨场景下是致命的噪声。
小结
综上所述,全文检索和向量检索并非简单的“新旧技术”替代关系,而是互补的正交能力:
- 全文检索保证了精确性,守住了特定字符必须存在的底线。
- 向量检索提升了召回率,打破了关键词匹配的僵化限制。
混合检索的本质,就是通过算法将这两者的打分投影到同一个维度进行加权融合。我们希望检索系统既能精准核对关键术语,又能理解用户的弦外之音。下面我们会重点介绍我们混合检索的逻辑。
混合检索
在深入混合检索流程之前,我们需要先对齐索引中的数据模型。我们的设计并没有将文档看作扁平的文本块,而是构建了一个“父子依存、虚实结合”的层级结构。
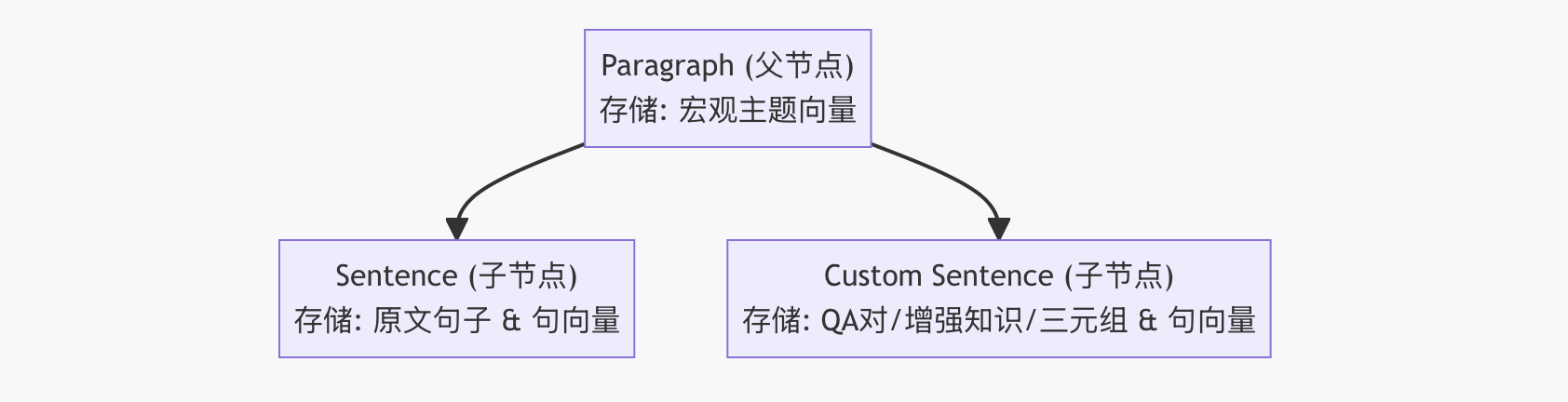
这种设计使得检索系统不仅能搜到“原文里写了什么”(通过 Sentence),还能搜到“这代表了什么含义”(通过 Custom Sentence,例如用户搜“怎么退钱”,能匹配到挂载在退款条款下的 QA 问题“如何进行退款操作”)。
| 数据单元 | 角色定位 | 来源与性质 |
|---|---|---|
| Paragraph (段落) | 父节点 / 返回单元 | 宏观上下文它是 RAG 最终需要的一个完整自然段。存储了代表段落整体主题的向量 |
| Sentence (句子) | 子节点 / 计算单元 | 原生微观证据从 Paragraph 中拆解出的自然句。它是 BM25 检索的最小原子,依附于父节点。 |
| Custom Sentence (增强句) | 子节点 / 增强单元 | 合成微观证据这是知识增强的关键接口。它可以是离线生成的 QA 问答对\缩写解释\人工标注的关键点。在索引结构中,它与 Sentence 是兄弟节点关系,享有同等的检索权重。 |
业务流程
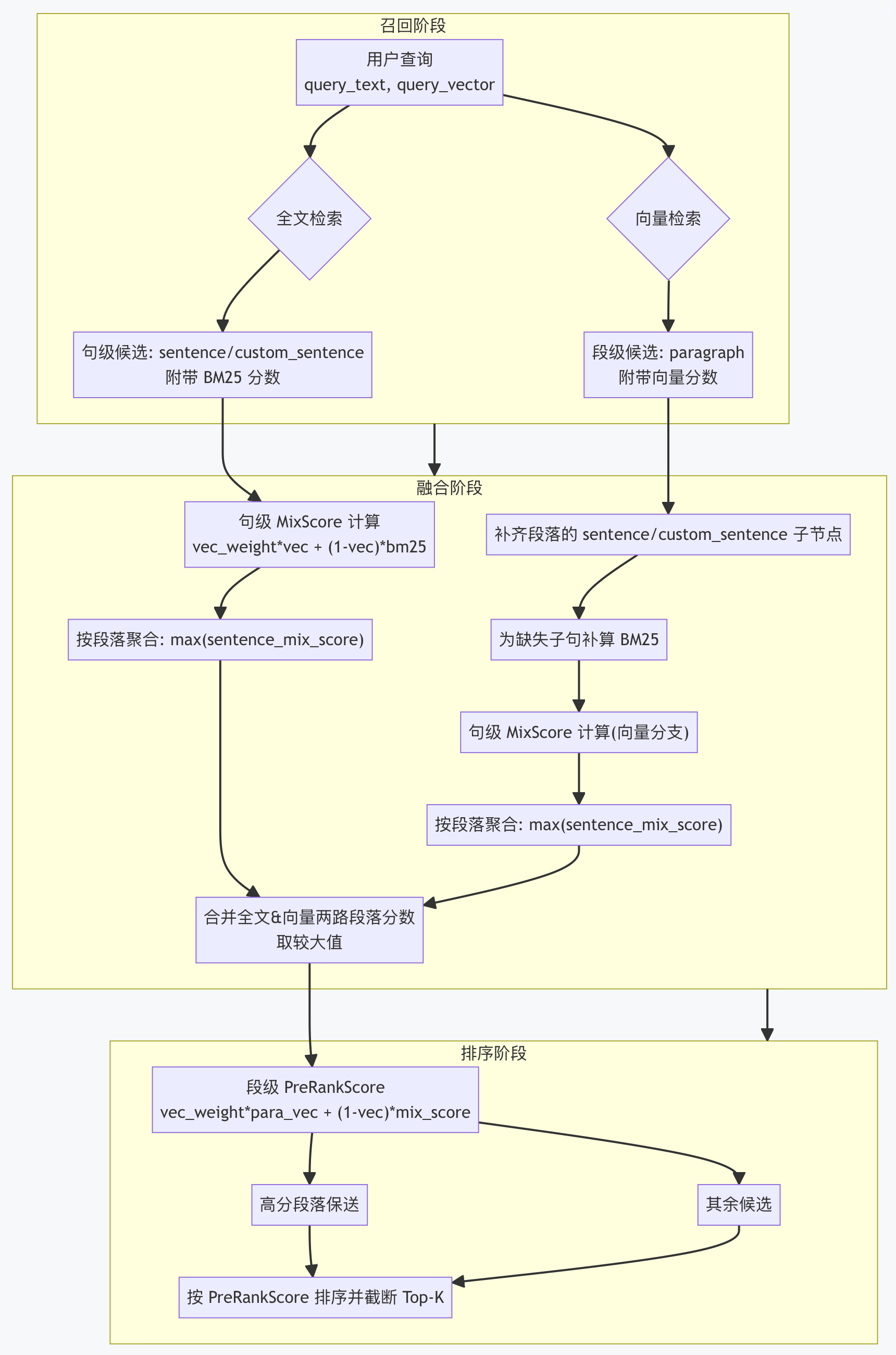
阶段一:双路召回
我们先通过下图建立一个宏观的认知。
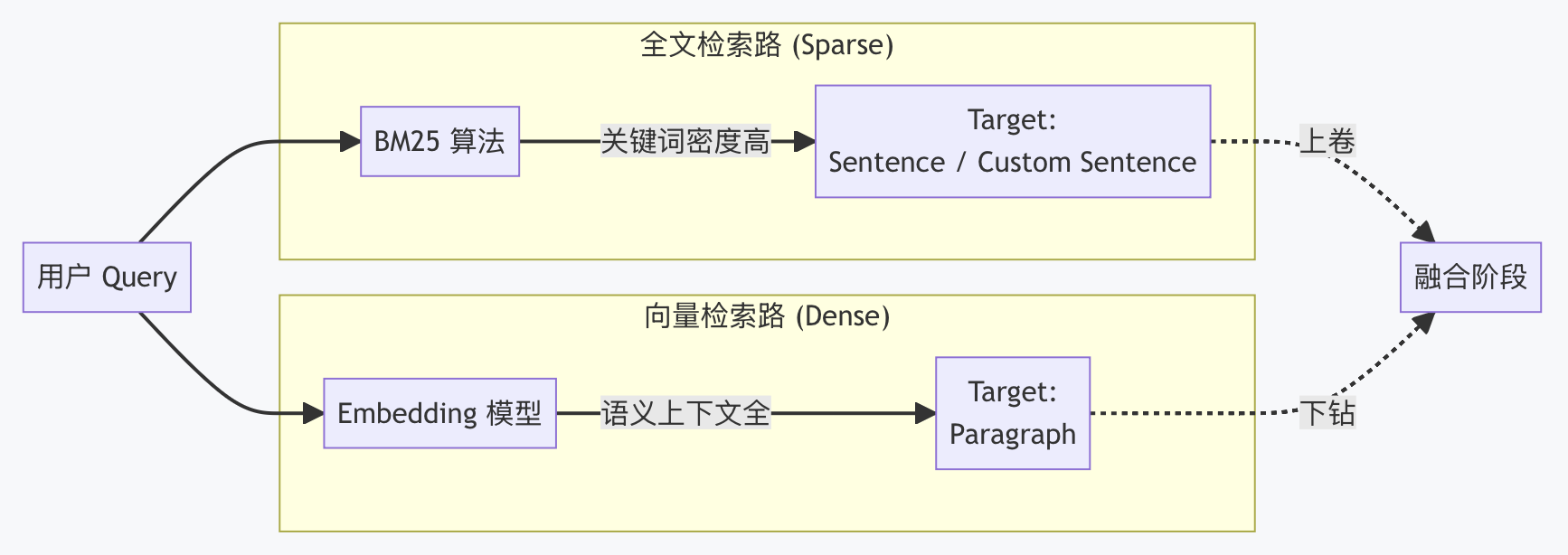
您可能会注意到,两条检索链路锁定的目标粒度是不一致的(一个查句子,一个查段落)。这是有意为之的, 其原因如下:
-
全文检索 -> 对齐子节点 (Sentence / Custom Sentence)
- BM25 对精确关键词敏感。无论是原文中的特定条款(Sentence),还是我们预埋的 QA 问题(Custom Sentence),只要包含关键词,就能被精准捕获。防止因段落过长而稀释关键词密度。
-
向量检索 -> 对齐父节点 (Paragraph)
- 向量检索擅长捕捉宏观语义。一个完整的段落通常包含更完整的主题信息,因此我们用段落向量来召回那些“语义相关但用词不重叠”的内容。
通过这种“各取所长”的不对称设计,我们在源头上就在争取进入融合阶段的候选集具备最高的质量。
阶段二:融合
在上面的流程图里, 真正决定候选段落排序的, 是两轮加权融合得到的分数:
- 句级混合分数 MixScore:在
sentence/custom_sentence粒度上, 把“语义相似度”和“BM25 相关性”融合成一个值。 - 段级预排序分数 PreRankScore:在
paragraph粒度上, 再把“段落整体语义”和“句级证据”二次融合。
从业务角度看, 可以理解为:
- 第一次融合是在问:“这句话既在讲这件事, 又用到了正确的词吗?”
- 第二次融合是在问:“这一整段整体是不是在讲这个话题, 并且里面是否存在非常关键的一句?”
如果用简化公式来刻画这两轮融合:
- 句级混合分数:
sentence_mix_score = vec_weight * norm_vector_score + (1 - vec_weight) * norm_bm25_score - 段级预排序分数:
pre_rank_score = vec_weight * paragraph_vector_score + (1 - vec_weight) * paragraph_mix_score -
其中:
paragraph_mix_score: 该段落下所有子句sentence_mix_score的最大值, 表示“这段里最有说服力的一句”的得分。norm_vector_score: 句级或段级的向量相似度(余弦相似度), 通过简单位移/缩放归一到 [0, 1] 区间;norm_bm25_score: 对 BM25 分数做简单压缩后的结果, 例如min(bm25, 50) / 50;
通过这样的两层融合, 排序结果既受语义相似度影响, 也不会忽视关键术语的匹配情况。下面分阶段地进行更细节的补充。
信息补全
为了公平比较,算法会执行“双向补全”操作:
- 对于 BM25 召回的句子:系统会实时计算其与 Query 的向量相似度,使其同时拥有字面分和语义分。
- 对于向量召回的段落:系统会“下钻”加载其所有子句,并补充计算这些子句的 BM25 分数。
句级混合分数
在最细的粒度(句子)上,我们首先评估其质量。对于任意一个候选句子,其混合分数计算如下:
$Score{mix}(s) = w \cdot S{vec}(s) + (1 - w) \cdot S_{bm25}^{norm}(s)$
- $S_{vec}(s)$:句子的向量余弦相似度。
- $S_{bm25}^{norm}(s)$:归一化后的 BM25 分数。
- $w$ (
vec_weight):核心平衡参数,决定了我们更信任语义还是字面匹配。
段落聚合
在 RAG 场景中,只要段落中存在一句话(即 $max$ 值)能精准、强力地回答用户问题,那么整个段落就是高价值的, 因此我们采用了 Max Pooling(最大池化) 策略: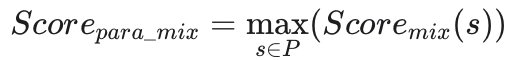
阶段三:最终排序

通过这种 “宏观主题 + 微观证据” 的确认机制,最终输出的 Top-K 列表既保证了话题的相关性,又确保了关键信息的精确匹配。
小结
完整的流程图如下所示, 混合检索的整体流程可以概括为三个阶段:召回、融合 和 排序。
关键参数与调优建议
混合检索的行为可以通过少量参数进行调节, 以适配不同的业务侧偏好:
| 参数 | 作用 | 业务含义 |
|---|---|---|
vec_weight |
控制向量分数和 BM25 分数在融合公式中的权重 | 越接近 1, 越依赖语义相似度; 越接近 0, 越依赖关键词匹配 |
| 全文召回倍数 | 决定全文检索阶段的候选数量 | 越大越不容易漏掉关键信息, 但后续计算开销更高 |
| 向量召回倍数 | 决定向量检索阶段的候选数量 | 越大对长尾语义表达更友好, 但也会引入更多噪声 |
典型的调优思路是:
- 在召回倍数上, 先保证覆盖率(不要太小), 然后结合性能预算逐步压缩;
-
在
vec_weight上, 针对不同 query 类型做分桶实验:- 结构化强、术语明确的 query 适当降低
vec_weight, 更信任 BM25; - 自然语言化、开放式的 query 提高
vec_weight, 更信任向量相似度。
- 结构化强、术语明确的 query 适当降低
通过这几个旋钮, 算法可以在“语义理解能力”和“字段匹配精度”之间灵活移动, 为上层 RAG 或搜索应用提供一个可控、可解释的混合检索基础。
鲁棒性与回退策略
真实环境中的索引数据并不总是完美的。某些 paragraph 可能因为上游切分或写入问题, 缺少期望的子句结构。为了在“保持可用性”和“暴露严重问题”之间找到平衡, 我们在混合检索中设计了几类行为:
- 正常路径: 段落既有
sentence也有custom_sentence子节点, 算法会在句级完整计算 MixScore, 再聚合到段级。 - 只有部分子句缺失: 例如只有
sentence而没有custom_sentence, 算法会在可用的那部分子句上完成计算, 同时在调试模式下打出告警, 提示索引结构存在瑕疵。 -
完全没有子句: 对于既没有
sentence也没有custom_sentence的段落, 算法会触发段级回退:- 直接使用
paragraph自身的向量分数与基于其text计算得到的 BM25 分数; - 在段级套用与上文类似的融合公式, 生成一个“降级版”的 MixScore, 让该段落仍有参与排序的机会。
- 直接使用
评价此篇文章