
HuggingFace数据集自定义脚本处理
更新时间:2026-06-26
前提条件
- 已开通BOS、OOS、BLS权限。
- 已完成资源环境准备。
- 准备好任务脚本。
本次使用工作流来执行PySpark任务,需要创建通用资源队列并加入资源组。
场景概览
在百度胜算 AI 数据智能工作流链路中,针对本地 / 离线原始业务数据,通过自定义 Python 脚本调用 Hugging Face Datasets 库,完成数据加载、清洗、字段转换、标签归一、样本过滤、数据集拆分、标准化持久化,产出兼容 Transformer 模型训练、向量检索、微调任务的标准 HF Dataset 格式数据集,打通原始业务数据→AI 建模的中间处理环节。
操作步骤
步骤一:创建项目并配置计算资源权限
- 在左侧导航栏单击工作台,单击立即创建按钮,创建项目。
- 输入项目名称test,然后单击确定。
- 在左侧导航栏单击计算资源,单击列表操作列的权限管理按钮,确认当前创建的项目具备计算资源的使用权限,确保后续工作流可正常调度算力。
步骤二:导入任务脚本
- 在步骤一创建的项目中单击右上角创建>导入文件。

- 选择提前准备好的任务脚本导入。
步骤三:创建并运行工作流
- 在步骤一创建的项目中单击右上角创建>工作流,输入名称HF-test,然后单击确定。
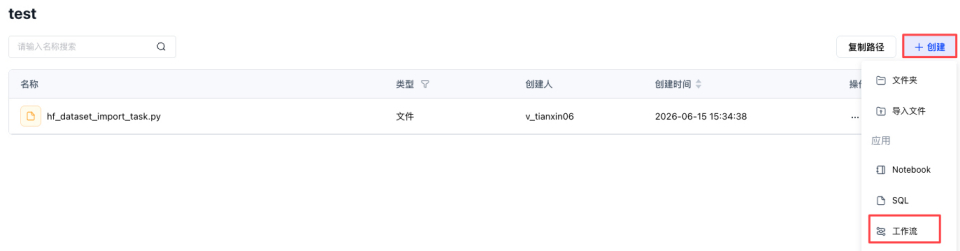
- 单击创建空白工作流卡片,然后选择PySpark任务,单击任务节点,在右侧进行配置。
-
单击程序文件右侧的浏览按钮,选择步骤二导入的文件。
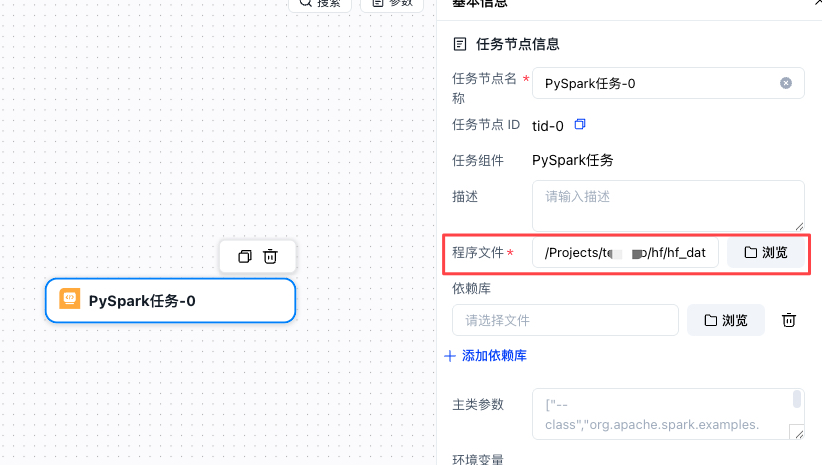
当前采用 Python 代码开发,无需配置主类相关参数。
- 然后单击右侧执行资源按钮,按下图所示配置实例类型、Spark配置。

- 最后单击保存>立即运行。
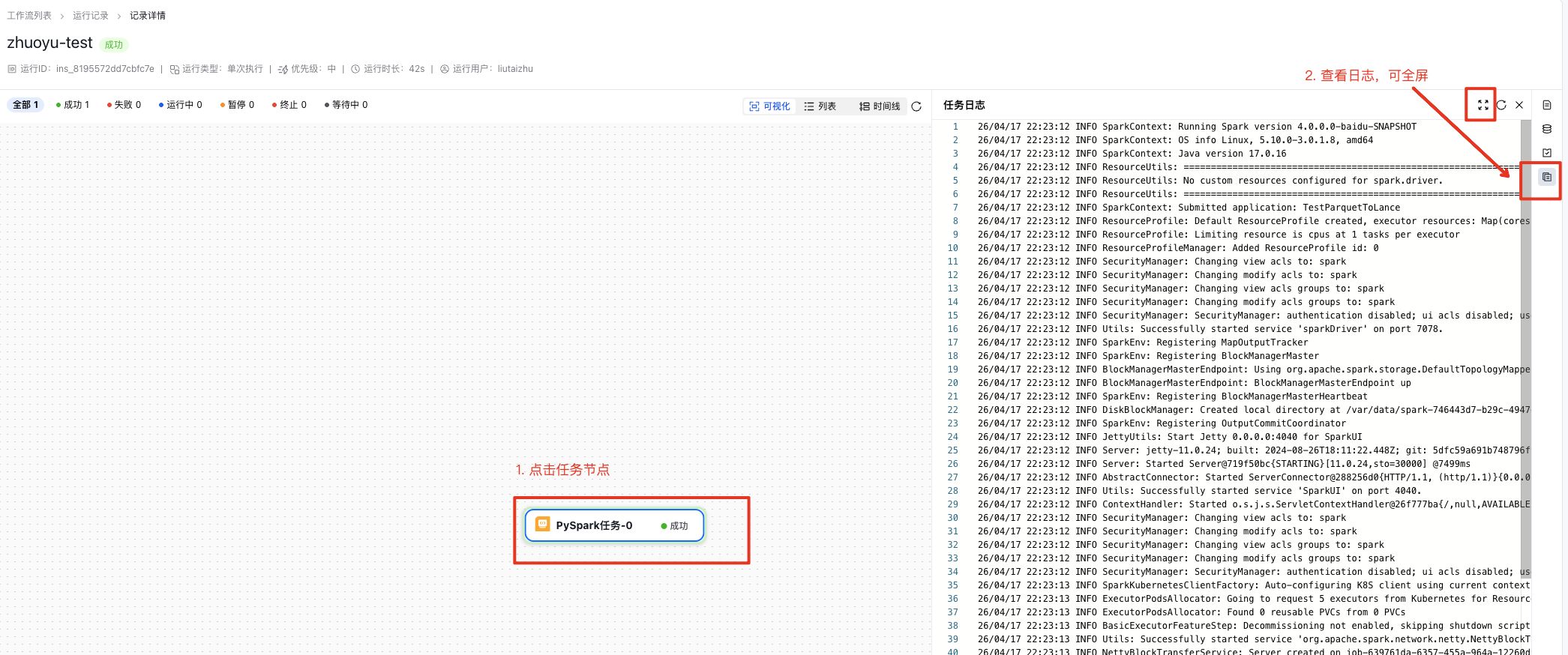
步骤四:查看任务运行状态与处理结果
- 查看工作流运行状态
评价此篇文章