
通过自定义算子实现对本地模型调用
前提条件
- 已开通BOS、OOS、BLS权限。
- 已完成资源环境准备。
- 已将待测试PDF上传至元数据-数据卷下。
场景概览
本场景面向具备私有化本地模型部署需求的用户,依托百度胜算自定义算子能力,完成本地模型上传、封装、服务发布与工作流调度全流程。用户可将自有训练的图像、文本、多模态等本地模型上传至平台数据卷存储,基于 Ray 分布式算力封装自定义推理算子,无需依赖外部第三方 API 即可在平台工作流、Notebook 中完成离线批量推理、在线实时调用。支持模型版本管理、推理资源弹性分配、调用链路日志观测,实现本地模型与平台数据加工链路打通,满足企业数据不出域、模型私有化部署、定制化 AI 数据处理的安全业务诉求。
自定义算子物料包
| 物料项 | 链接 | 描述 |
|---|---|---|
| 镜像 | https://operator.bj.bcebos.com/release/base_image/0.7/base-imgae-0.7.tar?authorization=bce-auth-v1%2FALTAK9KApiyYtkuoNE78fPPW0M%2F2026-05-27T02%3A19%3A38Z%2F-1%2Fhost%2F8500e8394a5167d1409d2a91106339002bda6466bdc0bb1086e86506285297c7 | md5:7b1cd7b42b0fdf3ee712e264e420c46e 镜像中的重点软件版本如下: nvcc==12.4 python==3.10.12 torch==2.5.1 transformers==4.47.1 paddlepaddle==3.1.0 onnxruntime==1.21.1 * opencv-python==4.11.0.86 |
| 自定义算子样例包 | /root/databuilder_dev | 内置在算子镜像中,算子镜像创建的容器路径 |
| https://operator.bj.bcebos.com/release/operator/databuilder_dev-v0.3.2.tar?authorization=bce-auth-v1%2FALTAKRDyrIQOaBuxqyREAShe7e%2F2025-12-26T03%3A29%3A01Z%2F-1%2Fhost%2Fd62a50cc27701605487f9f59ea7b5192f31fc8a7151b52f0d5889c5bc52f457d | v0.3.2版本自定义算子样例包 |
操作步骤
步骤一:自定义算子准备
软件环境准备
按照以下步骤,完成自定义算子容器创建,算子开发、测试、打包都将在自定义算子容器内完成。
展开镜像
- 使用如下命令将算子镜像tar包展开为本地镜像,此命令需要在物理机上执行:
1# 1. 下载模型包
2wget -O db_operator_dev.tar "上述物料中镜像链接"
3# 2. 进入算子镜像tar包所在目录
4cd /xxx
5# 3. 展开镜像
6docker load < ./db_operator_dev.tar- 镜像展开的时间约5分钟,可以通过下面的命令检查镜像是否成功展开:
1docker image ls | grep iregistry.baidu-int.com/doris-rdw/algorithm/operator- 镜像成功展开后会有类似如下输出:

创建容器
使用如下命令创建算子开发容器:
1docker run -itd --gpus=all \
2--privileged=true \
3--shm-size=64g \
4--net=host \
5--name db_op_dev \
6iregistry.baidu-int.com/doris-rdw/algorithm/operator:0.7 \
7/bin/bash环境验证
- 算子开发容器创建完毕后,通过如下命令进入容器:
1docker exec -it db_op_dev /bin/bash- 进入容器,可以通过镜像预置的自定义算子测试代码验证开发环境:
1# 1. 进入阈值自定义算子测试目录
2cd /root/databuilder_dev/tests
3# 2. 运行标点替换算子测试脚本
4sh run_punctuation_replace.sh- 算子运行成功后输出如下内容:
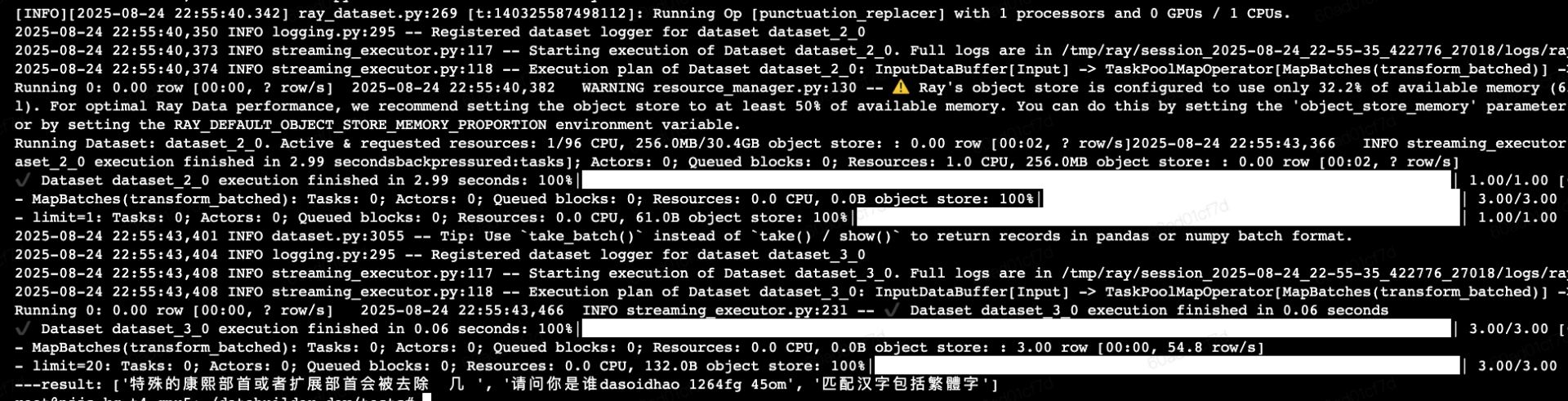
预置自定义算子介绍
- 镜像中内置了3个自定义算子(image_resizer/punctuation_filter/punctuation_replacer):

- 以下是3个算子的测试脚本:
Transformer算子介绍
类属性 - 算子元信息定义
 算子属性用于定义算子基础特征与运行环境参数,是算子框架完成算子识别、生命周期管控与资源调度的核心元数据。
算子属性用于定义算子基础特征与运行环境参数,是算子框架完成算子识别、生命周期管控与资源调度的核心元数据。
初始化方法 - 参数设置与预处理
 初始化时完成:
初始化时完成:
-
参数传递
- 通过
*args, **kwargs隐式支持父类参数(如text_key指定文本字段名)。 - 无显式参数,简化调用接口。
- 通过
-
预处理优化
- 正则预编译:在初始化时编译
r'([^\w\s])+'模式,提升运行时性能。 - 模式语义:匹配所有非字母数字(
\w)且非空白(\s)的连续字符。
- 正则预编译:在初始化时编译
-
资源准备
- 无外部资源依赖(如模型加载),轻量级初始化。
核心处理方法 - 单样本处理逻辑
 处理流程:
处理流程:
-
输入输出结构
- 输入:要求
samples为字典,且包含self.text_key指定的文本列表。 - 输出:保持原数据结构,仅更新文本内容。
- 输入:要求
-
核心逻辑
- 正则替换:使用预编译模式匹配标点符号。
- 等量空格替换:通过
lambda动态生成与匹配项等长的空格(如...→)。 - 列表推导式:高效实现批量处理。
接口调用示例
1# 1. input data
2 samples = [
3 {
4 'images': './images/cat.jpg'
5 },
6 {
7 'images': './images/cat2.jpg'
8 },
9 {
10 'images': './images/lena.jpg'
11 }
12 ]
13
14 input_dataset = RayDataset.from_list(samples)
15
16 # 2. create operator
17 dst_path = './ret'
18 os.makedirs(dst_path, exist_ok=True)
19 op = ImageResizer(width=1024, height=1024, dst_path=dst_path, need_hash_name=False)
20
21 # 3. run
22 output_dataset = input_dataset.run(op)
23
24 # 4. get & check result
25 image_path = output_dataset.get_column(column=op.image_key)
26
27 for name in image_path:
28 image = Image.open(name)
29 print(f'---result image {name} shape: {image.size}')步骤二:自定义算子开发
准备模型
- 登录百度胜算控制台,进入已经创建好的工作空间。在侧边导航栏选择元数据。
- 单击新建按钮,选择创建数据目录,配置数据目录名称为demo_test。
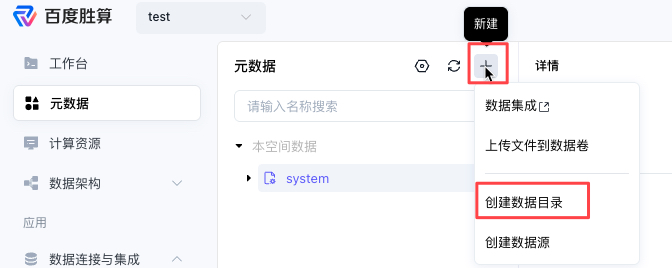
- 选择已创建好的数据目录demo_test,依次单击default>立即创建>创建模型。

- 在创建好的模型目录页面,单击右上角的创建按钮,在弹窗中输入模型名称并点击确定,即可创建出不同版本的模型目录。

-
单击创建好的模型版本,进入页面后,单击右侧上传文件,选择自定义算子准备中打包好的模型进行上传。

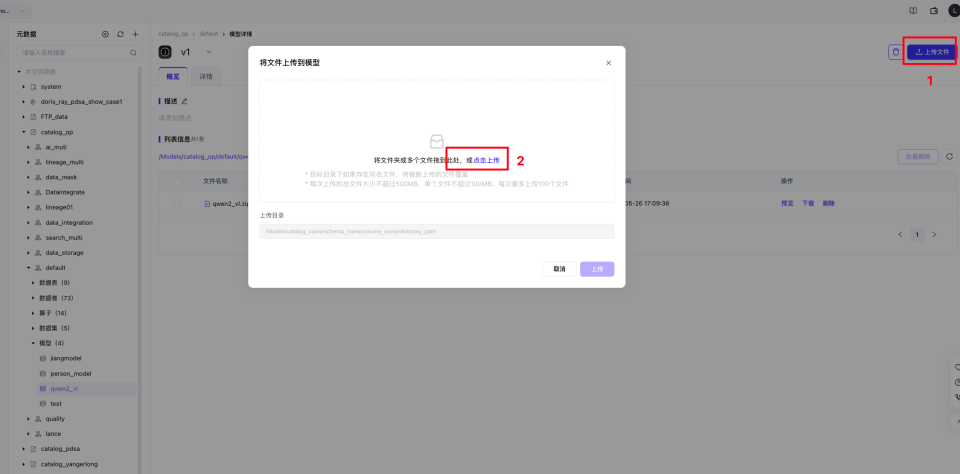
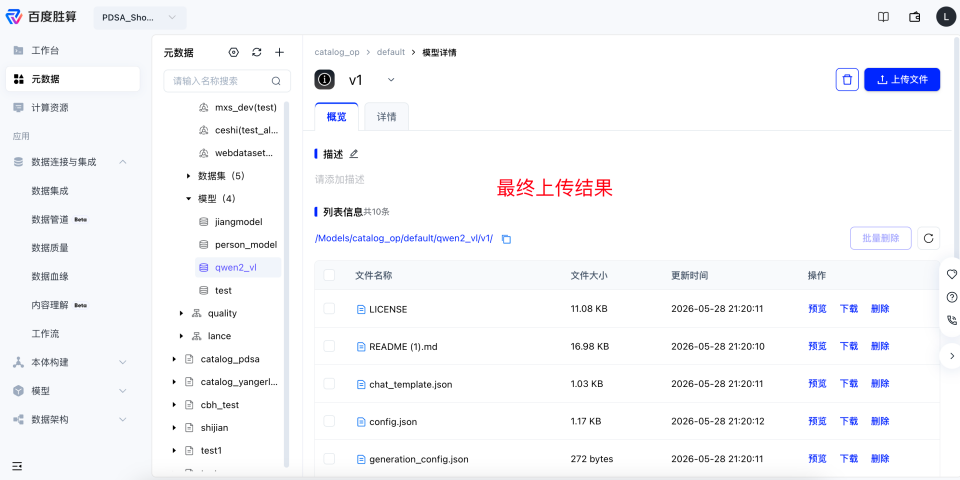
注意:如果提示超出上传文件限制大小,请联系对接人员!
代码撰写
实现对第三方模型服务的调用,以加载本地qwen-vl为例,在catalog_op目录下新建文件夹load_localmodel_vllm,代码撰写要求如下:
- 加载模型一定要放在 if preload: 之后。
- _processor = 'cuda' ,要保证有GPU的服务器资源。
- 可以设置 model_path, model_name 两个参数,这样方便后续我们更换模型后,也不需要更改代码。
- model_path : 为上面创建的模型目录地址,/Models/catalog_op/default/qwen2_vl/v1/。
- self.smart_file.volume_2_local(image_path, self.download_path) 这是用来从远程volume下载到本地的命令。
- 想输出的字段都可以通过samples["xx"] = xx 来输出,保存到volume的文件中。
1#!/usr/bin/env python
2# -*- coding: UTF-8 -*-
3# Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
4#
5# Licensed under the Apache License, Version 2.0 (the "License");
6# you may not use this file except in compliance with the License.
7# You may obtain a copy of the License at
8#
9# http://www.apache.org/licenses/LICENSE-2.0
10#
11# Unless required by applicable law or agreed to in writing, software
12# distributed under the License is distributed on an "AS IS" BASIS,
13# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14# See the License for the specific language governing permissions and
15# limitations under the License.
16
17"""File load_localmodel_vllm.py"""
18
19import base64
20import json
21import os
22import re
23import time
24
25from palette.ops.base import Transformer
26from databuilder.model.util import get_model_path
27from palette.util.file_utils import SmartFile
28
29os.environ["TRANSFORMERS_OFFLINE"] = "1"
30os.environ["HF_DATASETS_OFFLINE"] = "1"
31
32def _parse_llm_json(llm_output):
33 """从模型输出中提取并解析 JSON,失败时返回 None"""
34 try:
35 match = re.search(r"```(?:json)?\s*(.*?)```", llm_output, re.DOTALL)
36 if match:
37 json_str = match.group(1)
38 else:
39 first_curly = llm_output.find('{')
40 first_square = llm_output.find('[')
41 if first_curly == -1 and first_square == -1:
42 raise ValueError("未找到 JSON 开始符号")
43 if first_curly != -1 and (first_square == -1 or first_curly < first_square):
44 json_str = llm_output[first_curly: llm_output.rfind('}') + 1]
45 else:
46 json_str = llm_output[first_square: llm_output.rfind(']') + 1]
47 return json.loads(json_str)
48 except Exception as e:
49 print(f"[LoadLocalModelVLLM] JSON 解析失败: {e}")
50 return None
51
52
53class LoadLocalModelVLLM(Transformer):
54 """
55 本地 vLLM 模型推理算子
56 功能:
57 1. 从 volume 路径下载图片到本地
58 2. 使用本地 vLLM 模型对图片进行推理标注
59 3. 解析模型输出的 JSON,写入 annotations 字段
60 """
61 _op_type = "transform"
62 _batched_op = True
63 _processor = 'cuda'
64 _name = "load_localmodel_vllm"
65 _ray_execute_mode = "PIPELINE_ACTOR"
66 _ray_batch_format = "numpy"
67
68 def __init__(self,
69 model_path: str = '',
70 system_prompt: str = '',
71 user_prompt: str = '',
72 max_tokens: int = 4096,
73 max_model_len: int = 8192,
74 temperature: float = 0.7,
75 top_p: float = 0.9,
76 preload: bool = False,
77 *args, **kwargs):
78 """
79 :param model_path: 模型路径,由平台注册的完整路径
80 :param system_prompt: 系统提示词,为空时使用内置默认值
81 :param user_prompt: 用户提示词,为空时使用内置默认值
82 :param max_tokens: 最大输出 token 数
83 :param max_model_len: 模型最大上下文长度
84 :param temperature: 生成随机性
85 :param top_p: 核采样阈值
86 :param preload: 为 True 时在构造阶段完成模型加载
87 """
88 super().__init__(*args, **kwargs)
89 self.model_path = model_path
90 self.system_prompt = system_prompt or (
91 '你是一个专业的图像分析专家。'
92 '请仔细分析图片内容,以 JSON 格式返回结果。'
93 )
94 self.user_prompt = user_prompt or (
95 '请分析这张图片,提取能描述图片内容的标签列表。'
96 '标签应涵盖主体、场景、风格、颜色等维度。'
97 '以 JSON 格式返回,格式为:{"tags": ["标签1", "标签2", ...]}'
98 )
99 self.max_tokens = max_tokens
100 self.max_model_len = max_model_len
101 self.temperature = temperature
102 self.top_p = top_p
103 self.model = None
104 self.sampling_params = None
105 self.smart_file = SmartFile()
106 self.download_path = os.path.join(
107 os.getcwd(),
108 os.path.splitext(os.path.basename(__file__))[0]
109 )
110 print(f"[LoadLocalModelVLLM] init, model_path={model_path}, preload={preload}")
111 if preload:
112 from vllm import LLM, SamplingParams
113 import torch
114
115 os.makedirs(self.download_path, exist_ok=True)
116 full_model_path = get_model_path(model_path)
117 print(f"[LoadLocalModelVLLM] preload=True, full_model_path={full_model_path}")
118
119 t0 = time.perf_counter()
120 device = 'cuda' if torch.cuda.is_available() else 'cpu'
121 print(f"[LoadLocalModelVLLM] 开始加载模型, device={device}")
122 self.model = LLM(
123 model=full_model_path,
124 tokenizer=full_model_path,
125 trust_remote_code=True,
126 max_model_len=self.max_model_len,
127 device=device,
128 )
129 self.sampling_params = SamplingParams(
130 max_tokens=self.max_tokens,
131 temperature=self.temperature,
132 top_p=self.top_p,
133 )
134 print(f"[LoadLocalModelVLLM] 模型加载完成,耗时 {time.perf_counter() - t0:.4f}s")
135
136 def __call__(self, samples, *args, **kwargs):
137 src_images = samples[self.image_key].tolist()
138 print(f"[LoadLocalModelVLLM] __call__ 开始,batch size={len(src_images)}")
139 tags_list = []
140
141 for i, image_path in enumerate(src_images):
142 print(f"[LoadLocalModelVLLM] 处理第 {i+1}/{len(src_images)} 张: {image_path}")
143 try:
144 local_path = self.smart_file.volume_2_local(image_path, self.download_path)
145 with open(local_path, "rb") as f:
146 image_data = base64.b64encode(f.read()).decode("utf-8")
147
148 messages = [
149 {"role": "system", "content": [{"type": "text", "text": self.system_prompt}]},
150 {"role": "user", "content": [
151 {"type": "text", "text": self.user_prompt},
152 {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}},
153 ]},
154 ]
155 outputs = self.model.chat([messages], self.sampling_params)
156 raw_output = outputs[0].outputs[0].text
157 print(f"[LoadLocalModelVLLM] 推理完成,raw_output length={len(raw_output)}")
158 parsed = _parse_llm_json(raw_output)
159 tags = parsed.get('tags', parsed) if isinstance(parsed, dict) else parsed
160 except Exception as e:
161 print(f"[LoadLocalModelVLLM] 推理失败 {image_path}: {e}")
162 tags = None
163
164 tags_list.append(tags)
165
166 print(f"[LoadLocalModelVLLM] __call__ 完成,processed={len(tags_list)}")
167 samples['tags'] = tags_list
168 return samples步骤三:自定义算子打包
打包命令
核心代码撰写完毕后,开始打whl包:
1cd /root/databuilder_dev
2sh ./build.sh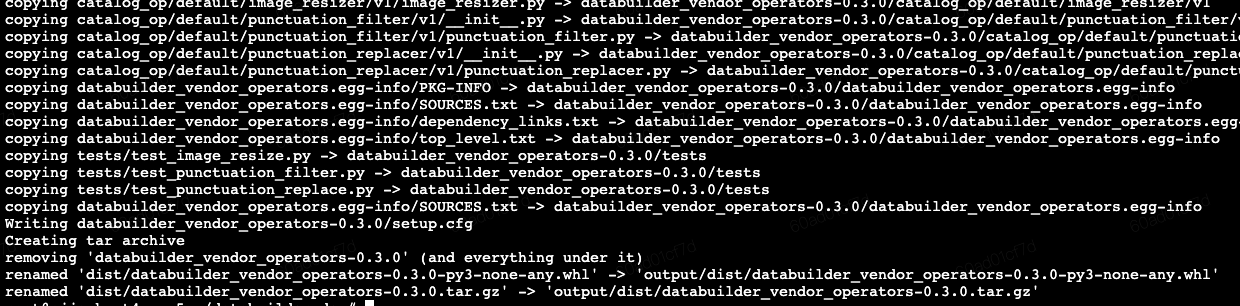 生成的自定义算子包whl文件存储在 /root/databuilder_dev/output/dist 路径下:
生成的自定义算子包whl文件存储在 /root/databuilder_dev/output/dist 路径下:

安装whl包
使用如下命令在自定义算子开发容器内按照whl包:
1cd /root/databuilder_dev/output/dist
2pip install databuilder_vendor_operators-0.3.0-py3-none-any.whl- 安装完毕后,可以运行 /root/databuilder_dev/tests 路径下的 run_xxx.sh 脚本在本地测试算子
- 算子在本地测试通过后,可以上线到DataBuilder平台
步骤四:自定义算子上线
以load_localmodel_vllm算子为例,下面介绍一下算子创建流程。
创建算子
如果要自己新建自定义算子,选择default,单击立即创建-创建算子。
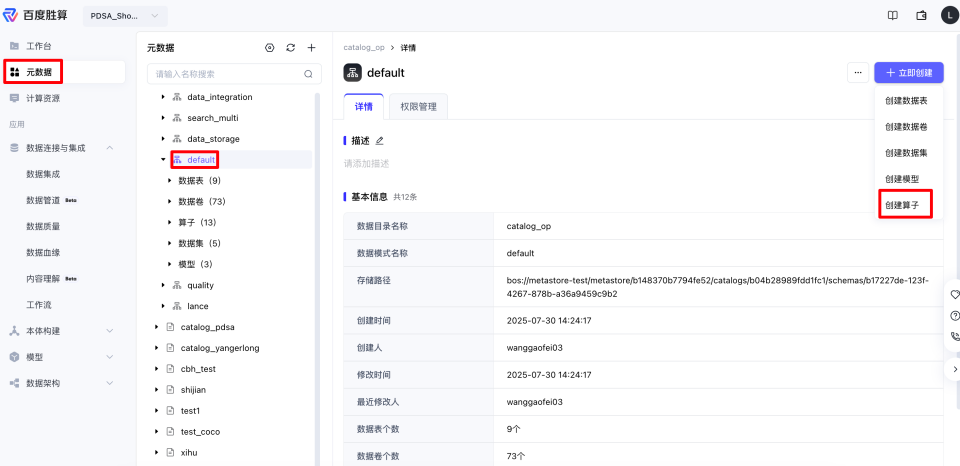
填写信息
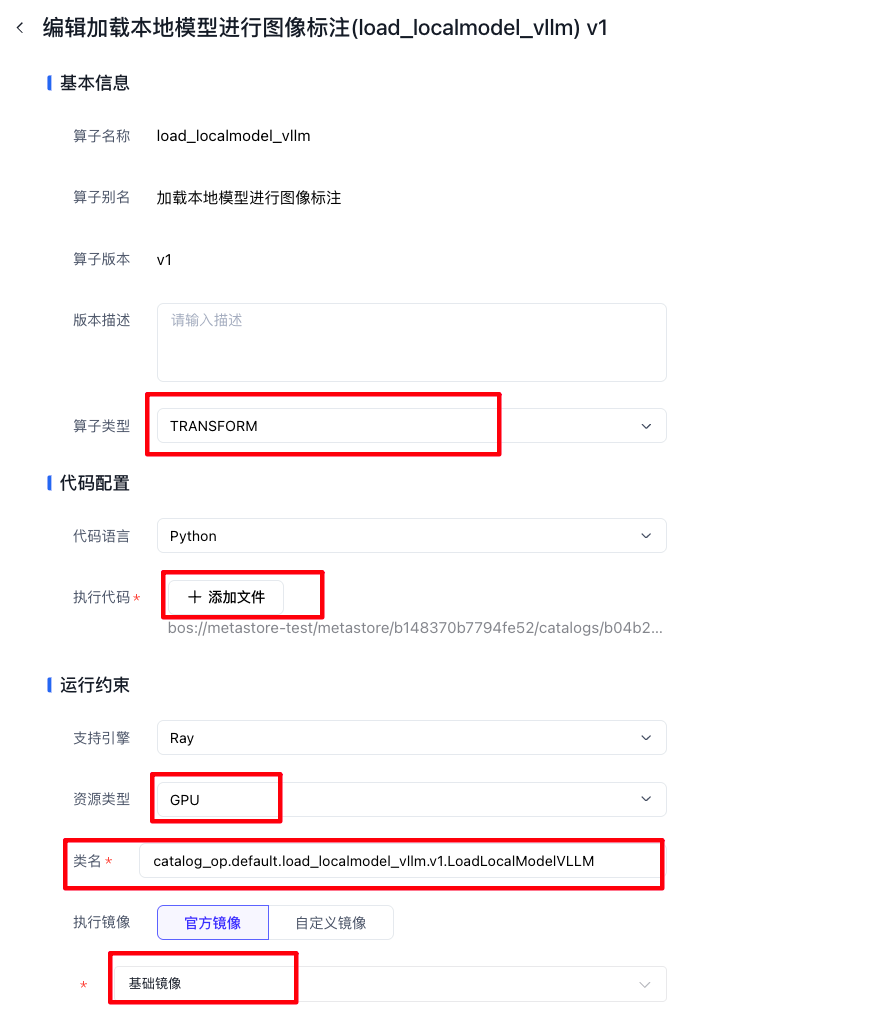
填入算子名称和算子别名,并选择提交并创建算子版本。
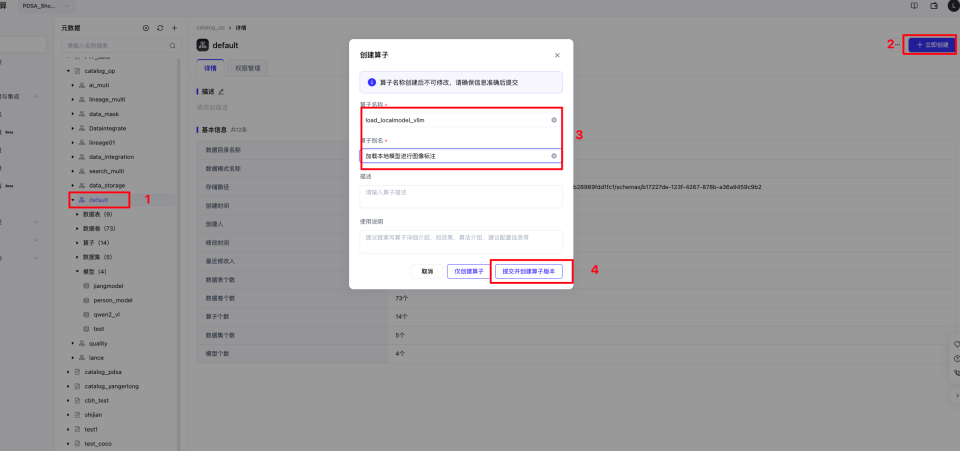 单击提交并创建算子版本进入,依次填写以下信息。算子类型要写TRANSFORM,添加文件就选择我们打好的whl包
单击提交并创建算子版本进入,依次填写以下信息。算子类型要写TRANSFORM,添加文件就选择我们打好的whl包
【注意】:类名必须是完整的自定义算子whl包+算子类名
- 依赖模型选择,需要选择我们上面上传模型zip包对应的目录
-
填写参数分为三种
-
输入参数,为算子执行的时候处理的samples所对应的key。代码是处理samples[image_key],所以我们就填写images
- text_key: text
- image_key: images
- video_key: videos
- audio_key: audios
- document_key: documents
- 输出参数,为算子最后输出的结果,代码中有 samples['file_name'] = file_names , samples['annotations'] = annotations。所以需要把file_name、annotations 都作为输出参数进行填写
- 运行参数,为算子初始化传入的参数,除了下面的model_path,model_name。 system_prompt、user_prompt等都可以作为运行参数进行设置
-
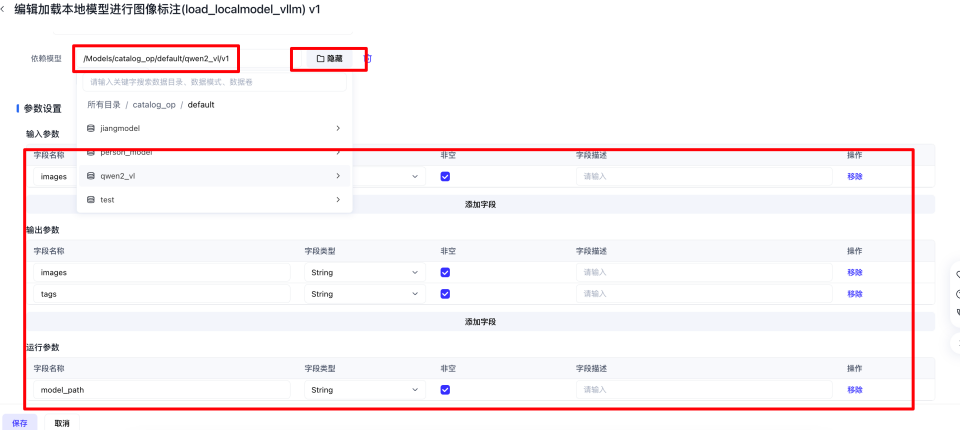
保存算子
填写完成后点击保存。保存后的算子可以在以下目录下找到。
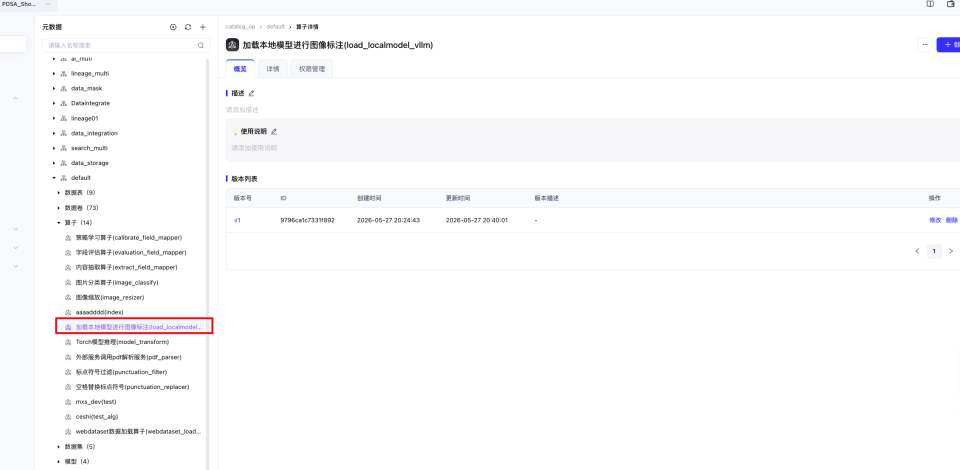
步骤五:自定义算子使用
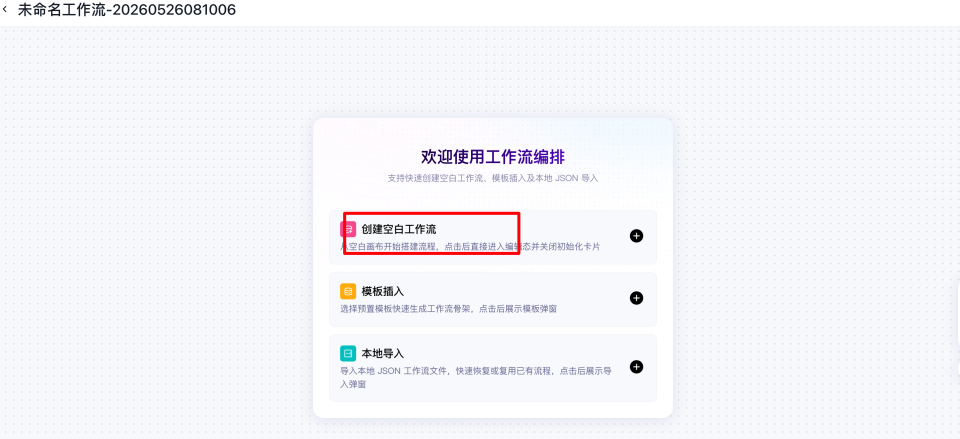
创建工作流
可以点击右侧的创建工作流新建一个工作流。

导入文件元数据加载器和数据输出器
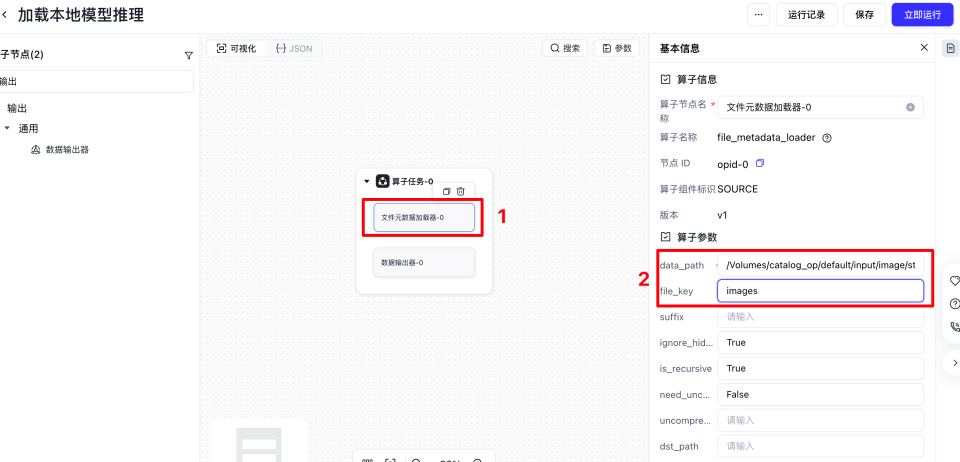
单击算子任务后,然后单击小三角,可以打开左侧的算子节点列。然后在搜索框输入元数据以及输出,将文件元数据加载器和数据输出器放到画布中。

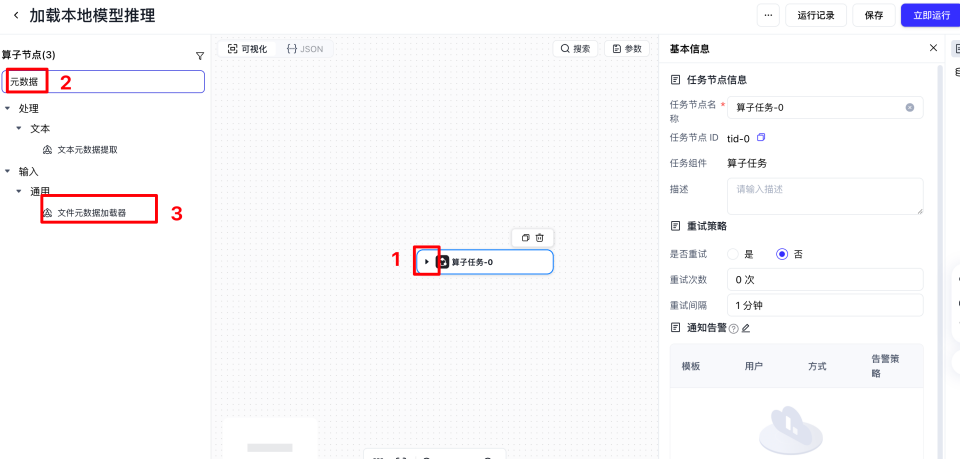
 填入输入路径以及输出路径参数,在设置参数的时候,需要点击下该算子,才会出现右侧的基本信息。
填入输入路径以及输出路径参数,在设置参数的时候,需要点击下该算子,才会出现右侧的基本信息。
-
file_key要与我们自定义算子接受的xx_key对应的值保持一致,比如我们接受的是代码是处理samples[image_key],所以我们就填写images
- text_key: text
- image_key: images
- video_key: videos
- audio_key: audios
- document_key: documents
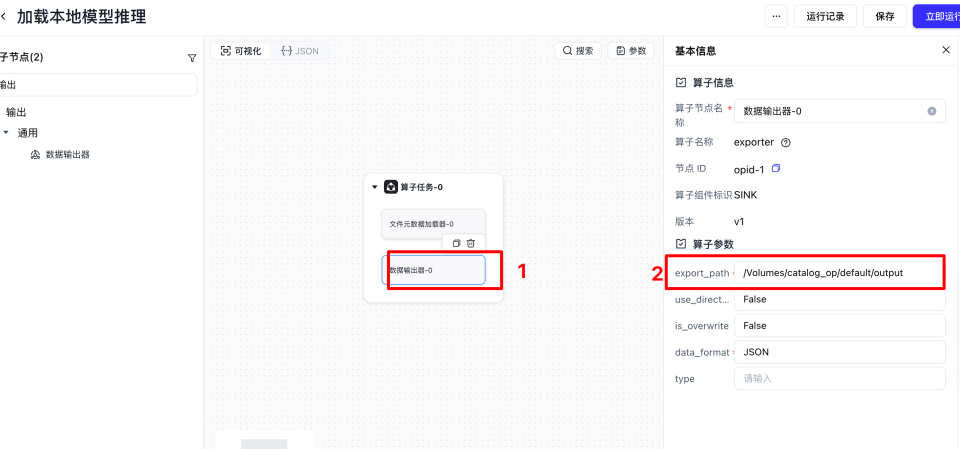
导入自定义算子
单击左侧自定义算子,然后单击画布中的自定义算子,会出现右侧的基本信息。
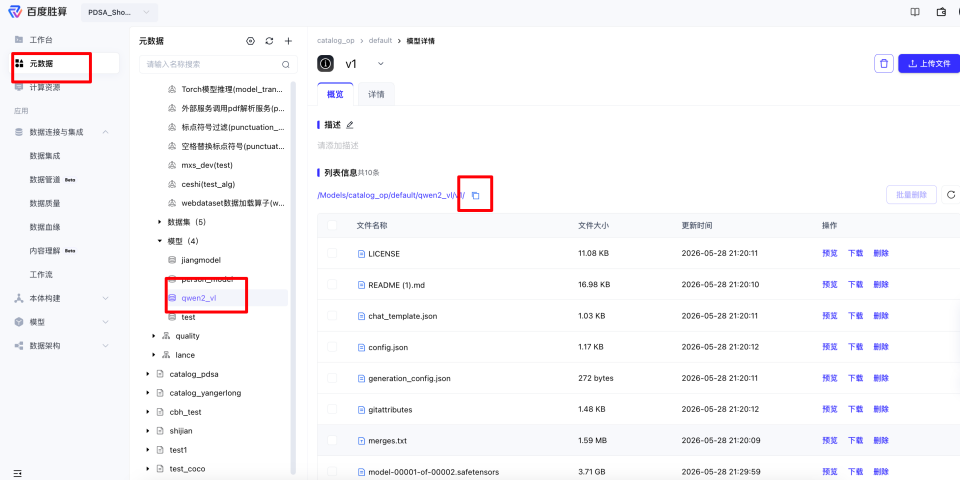
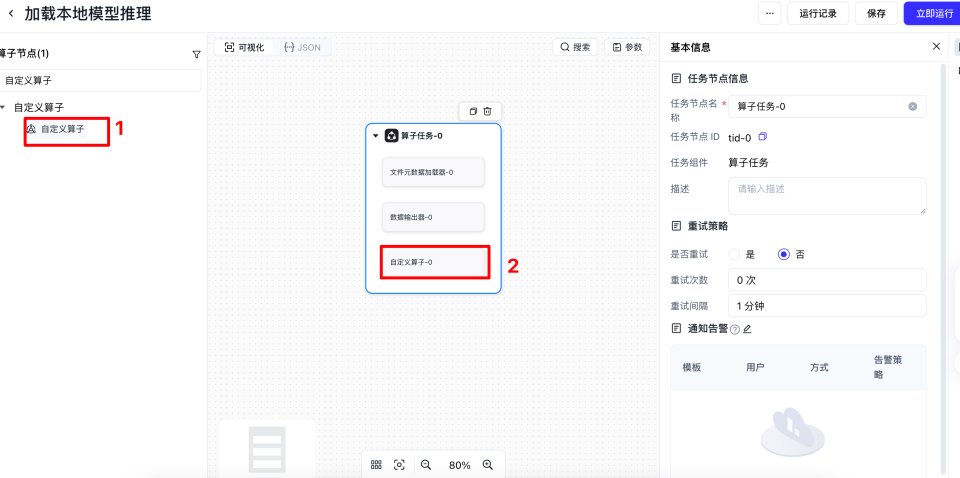 单击浏览,选择我们算子所在的路径,并选择正确的版本,最后把补充模型运行参数,其中model_path可以直接在元数据处进行复制。
单击浏览,选择我们算子所在的路径,并选择正确的版本,最后把补充模型运行参数,其中model_path可以直接在元数据处进行复制。
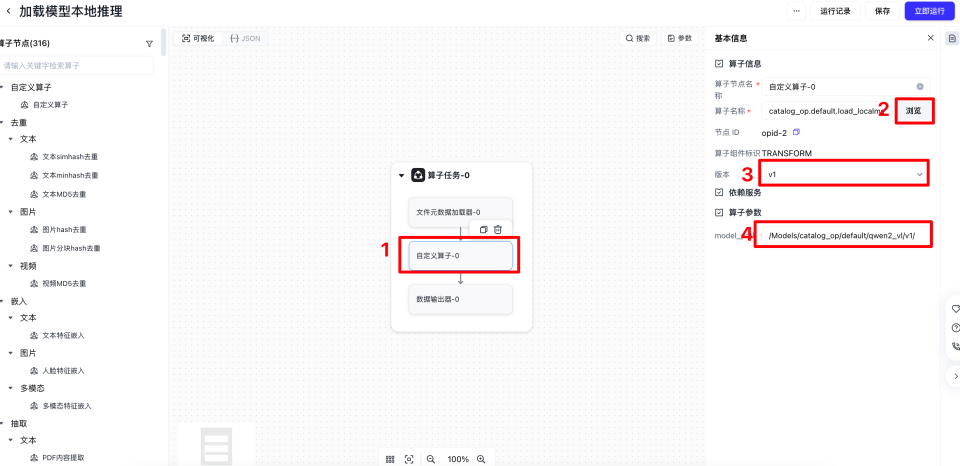
 把画布里的算子顺序进行连线调整,然后单击保存,并单击立即运行,开始运行工作流。
把画布里的算子顺序进行连线调整,然后单击保存,并单击立即运行,开始运行工作流。
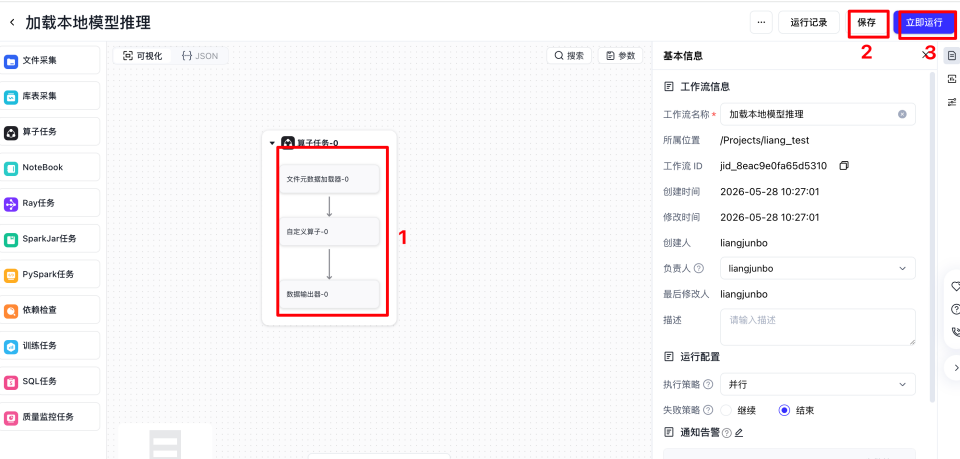
查看工作流运行结束后的输出结果
-
查看工作流运行结果
- 点击运行记录,可以查看运行结果。
- 在运行记录界面,可以不断刷新浏览器的刷新按钮,更新运行记录的状态,当状态变为成功时,即可进入记录详情页面。
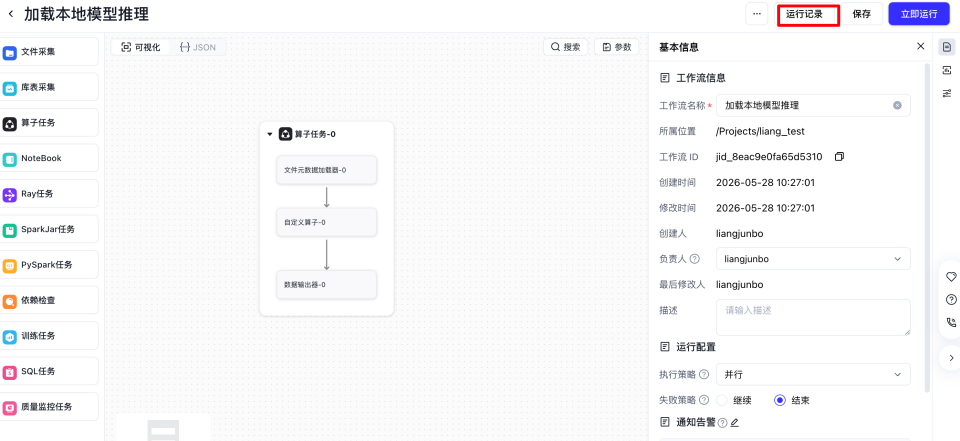
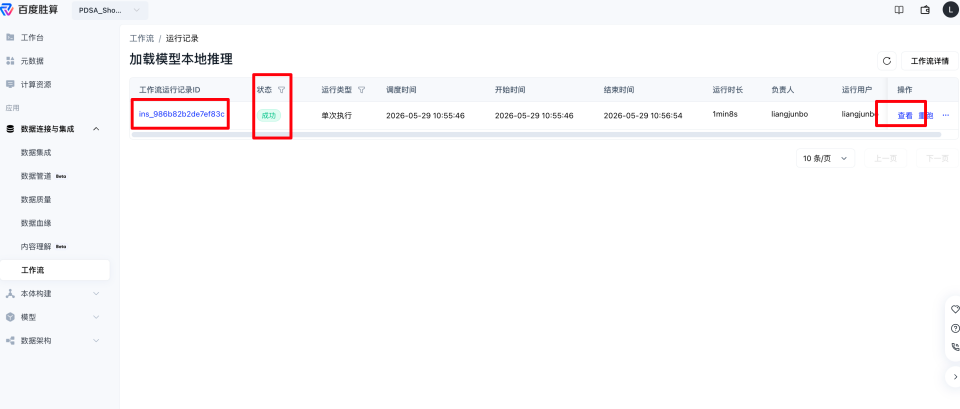
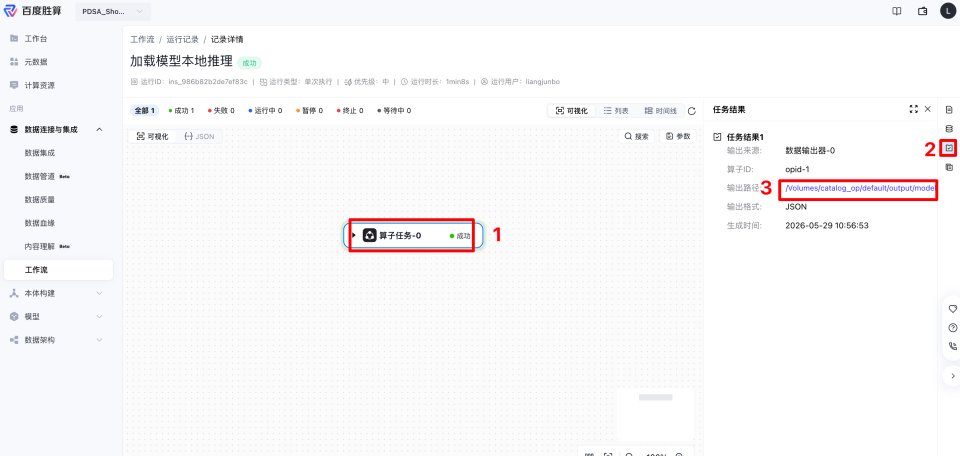
- 在记录详情页面,单击工作流,右侧会出现任务结果、任务日志等按钮,单击任务结果按钮后,会出现任务结果的详情,然后单击输出路径,会跳转到输出结果的数据页面。
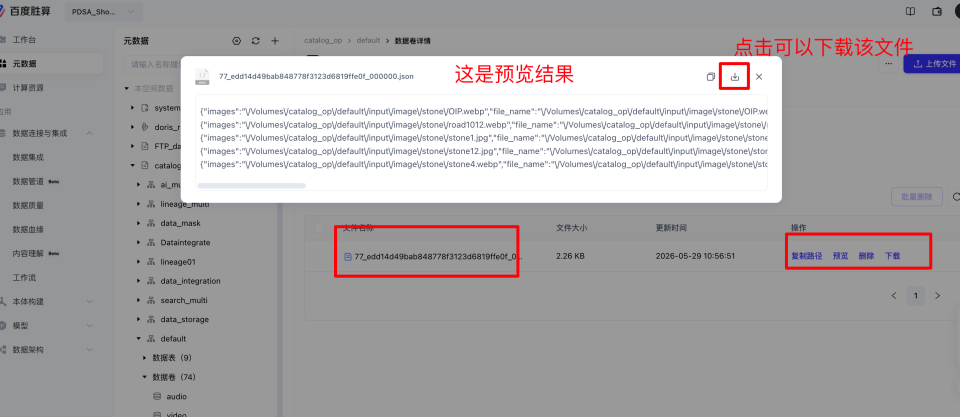
- 在输出结果中,可以通过直接点击文件名称或者预览、下载的按钮,来查看工作流的运行结果。
评价此篇文章