
数据集读写
1.背景百度胜算
在百度胜算产品中提供了Python SDK和ray.data的接口完成数据集读写的功能。
- Python SDK:可以将百度胜算的数据集版本读成huggingface的Dataset和IterableDataset;也可以将huggingface的Dataset和IterableDataset写到百度胜算的数据集版本。
- ray.data接口:可以将百度胜算的数据集版本读成ray的Dataset;也可以将ray的Dataset写到百度胜算的数据集版本。
2.Python SDK
2.1数据集读
2.1.1接口定义
databuilder.dataset.load_dataset(path:str, format:str, stream:bool=False, download_mode:str = 'reuse_dataset_if_exists') -> Union[Dataset, IterableDataset]
path:数据集中数据路径,是百度胜算中的虚拟路径。
format:加载数据使用的格式(非必填),目前支持csv、json、text、parquet、arrow、imagefolder、videofolder、audiofolder、webdataset。不填写使用元数据中数据预览格式。
stream:数据集是否流式懒加载,默认为false。
download_mode:在非流式加载时配置起作用,目前支持三种类型:reuse_dataset_if_exists、reuse_cache_if_exists、force_redownload
2.1.2读格式支持
| 格式 | stream读 | 非stream读 |
|---|---|---|
| csv | ✅ | ✅ |
| json | ✅ | ✅ |
| text | ✅ | ✅ |
| parquet | ✅ | ✅ |
| arrow | ✅ | |
| imagefolder | ✅ | |
| videofolder | ✅ | |
| audiofolder | ✅ | |
| webdataset | ✅ |
2.1.3使用示例
- 非stream读json格式的数据集
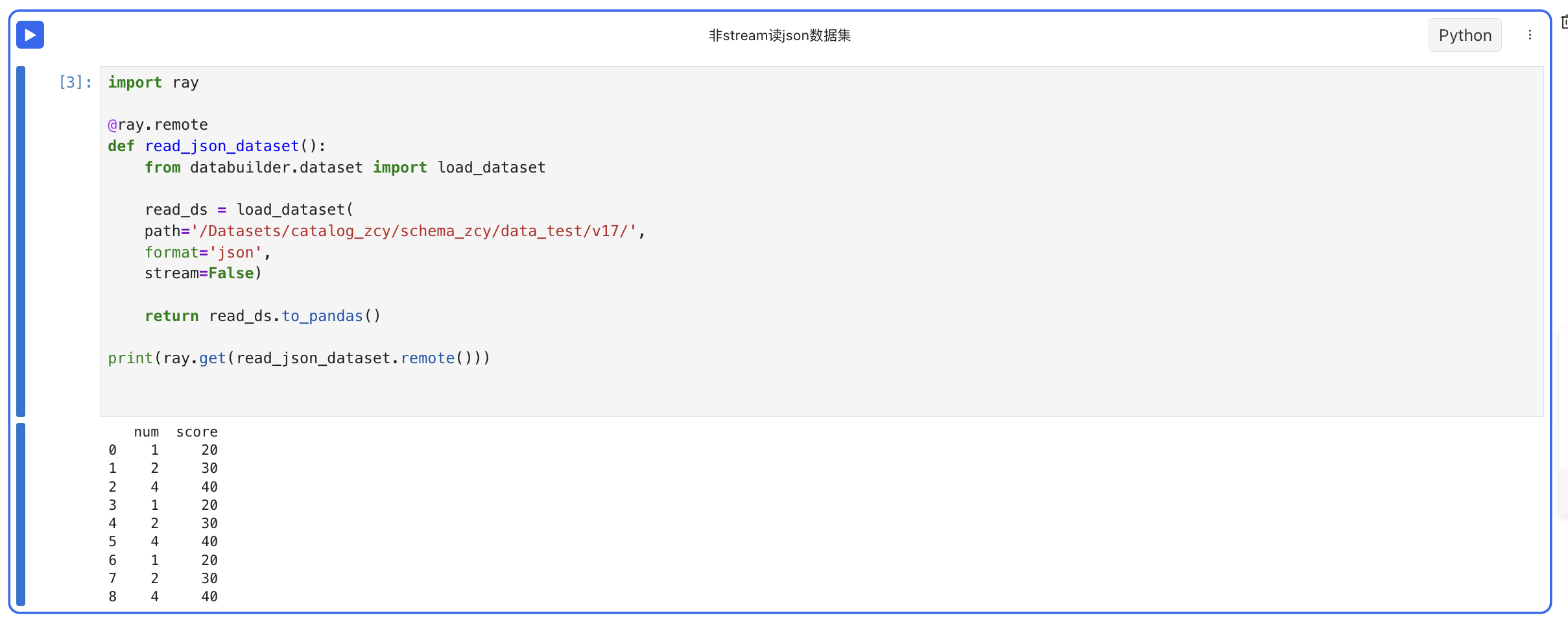
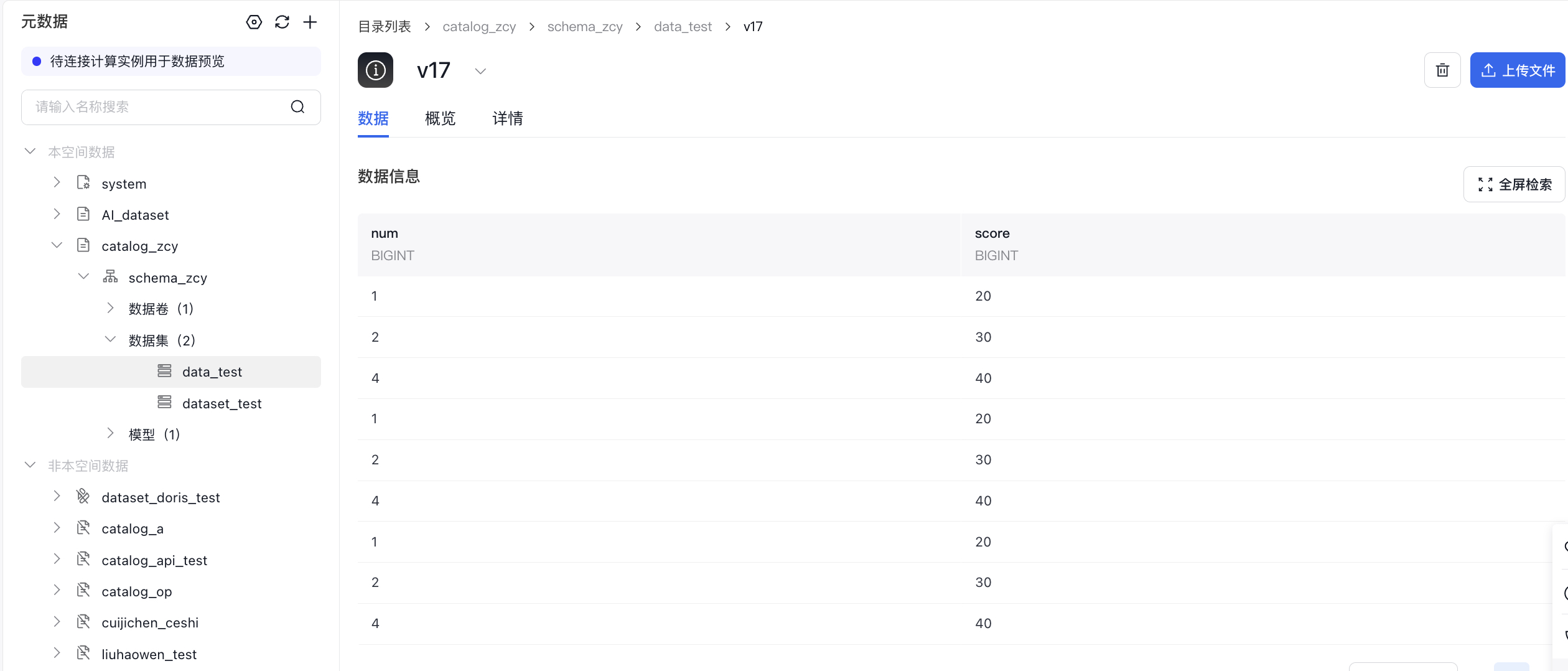
- 非读csv格式的数据集
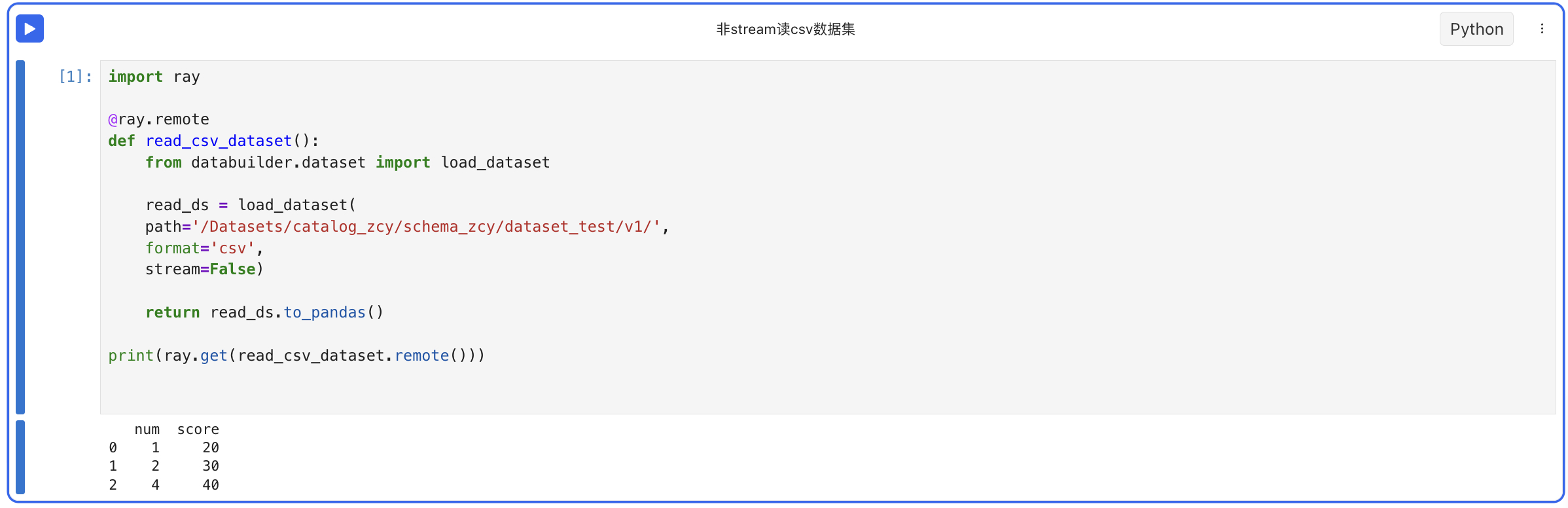
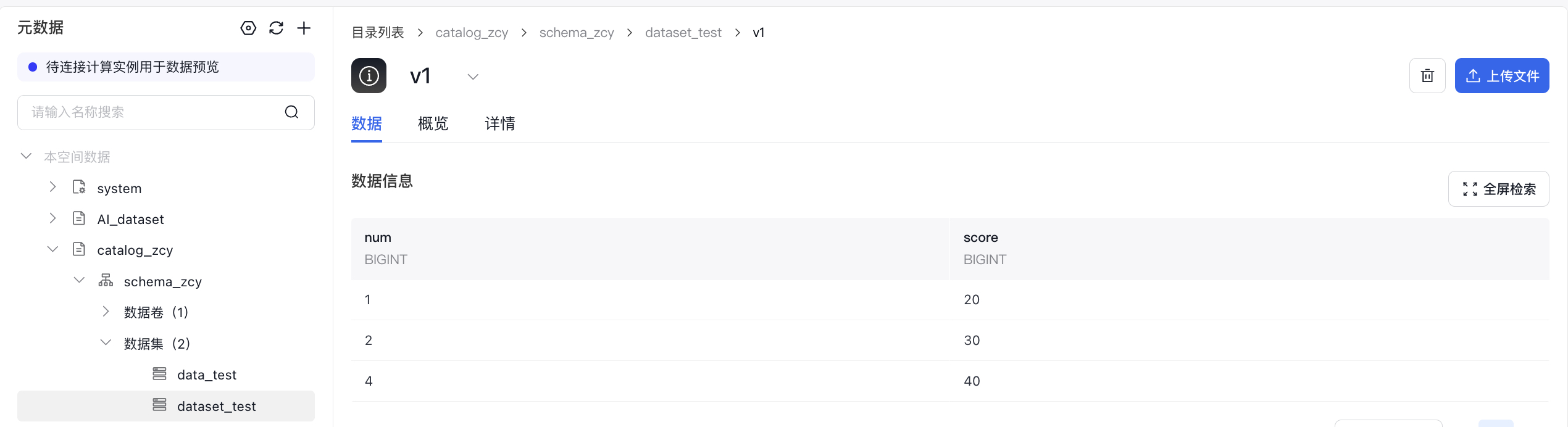
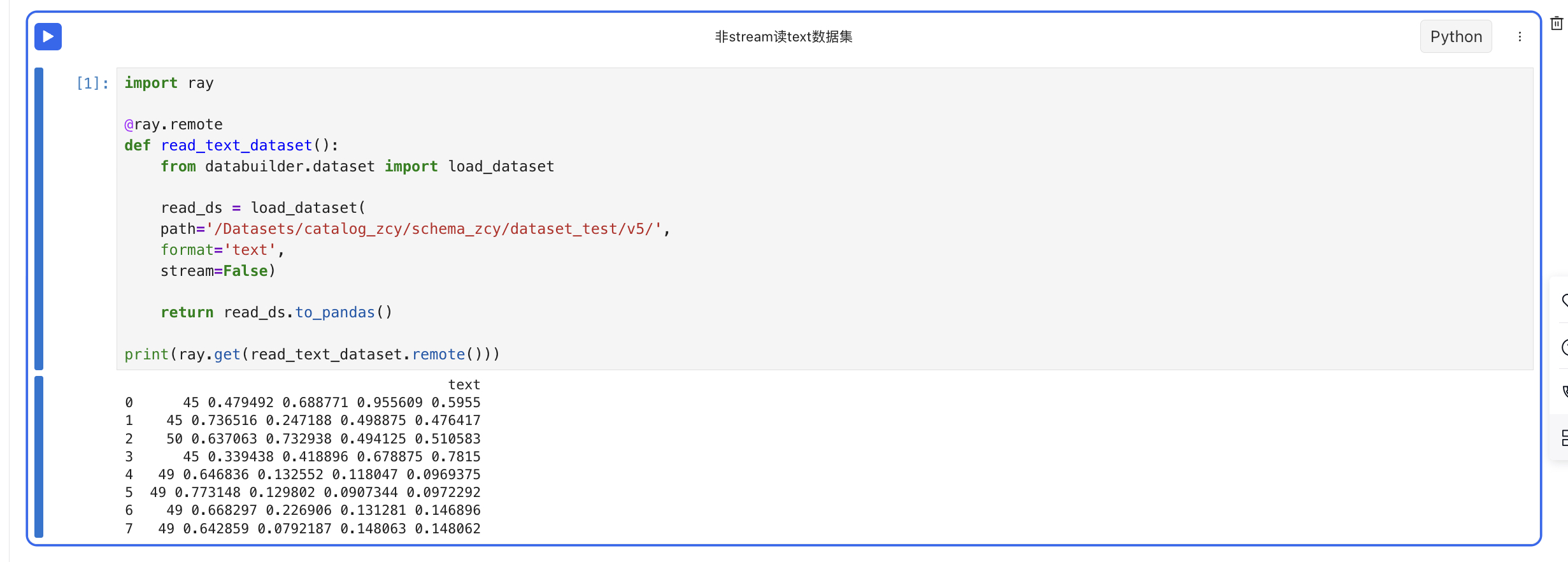
- 非stream读text格式的数据集
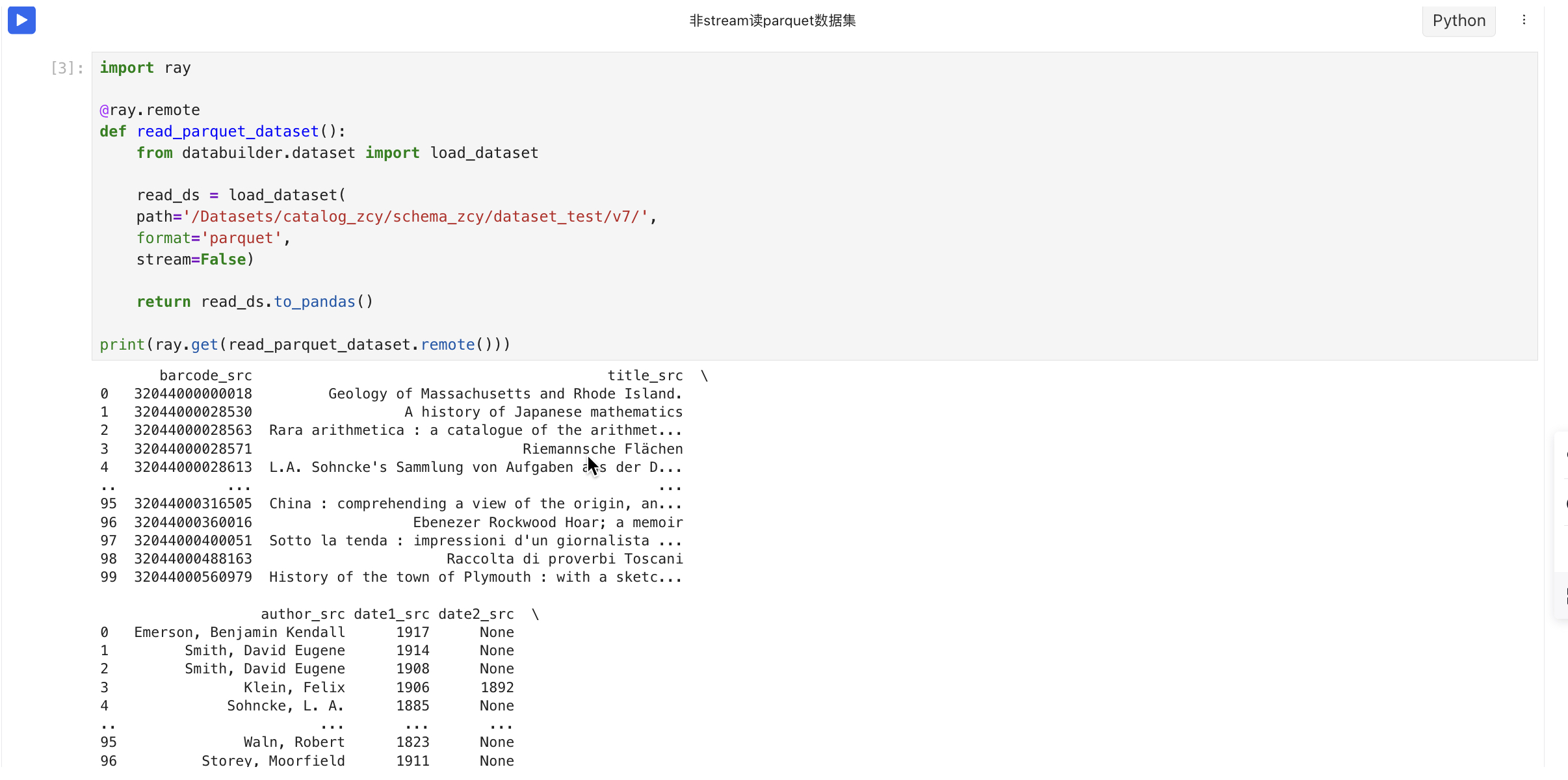
- 非stream读parquet格式的数据集
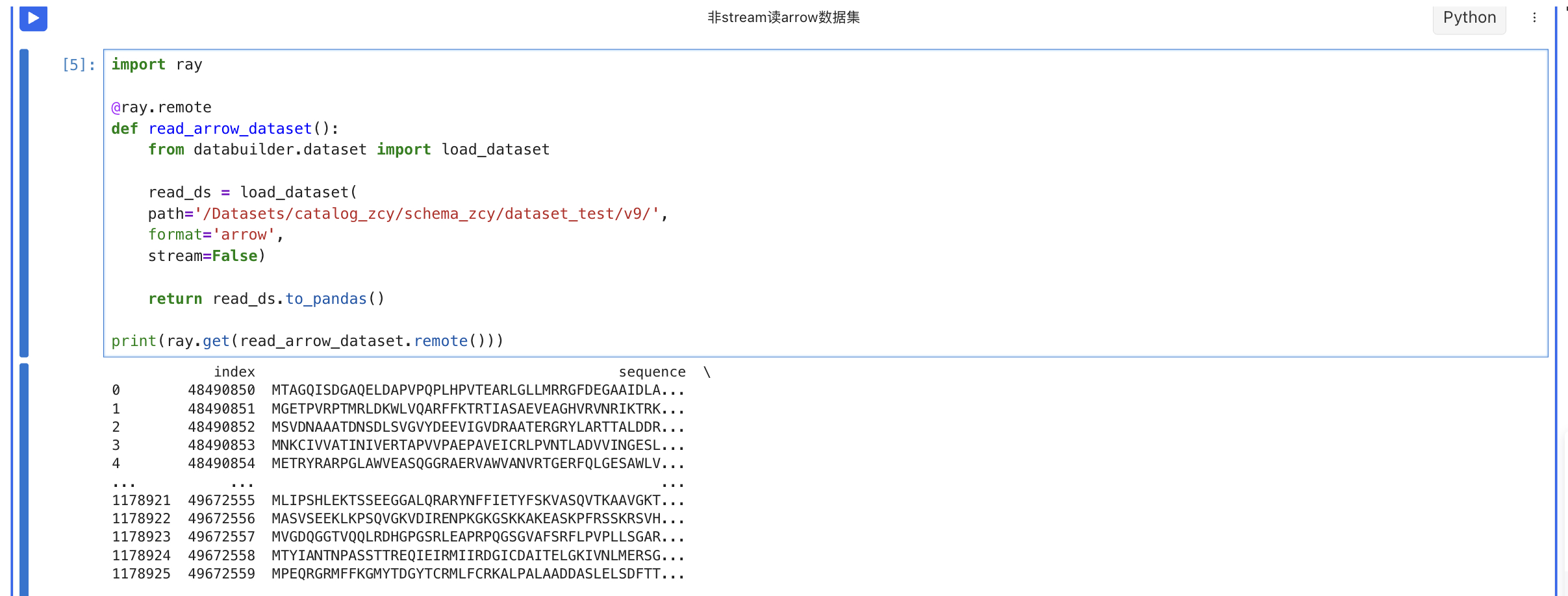
- 非stream读arrow格式的数据集
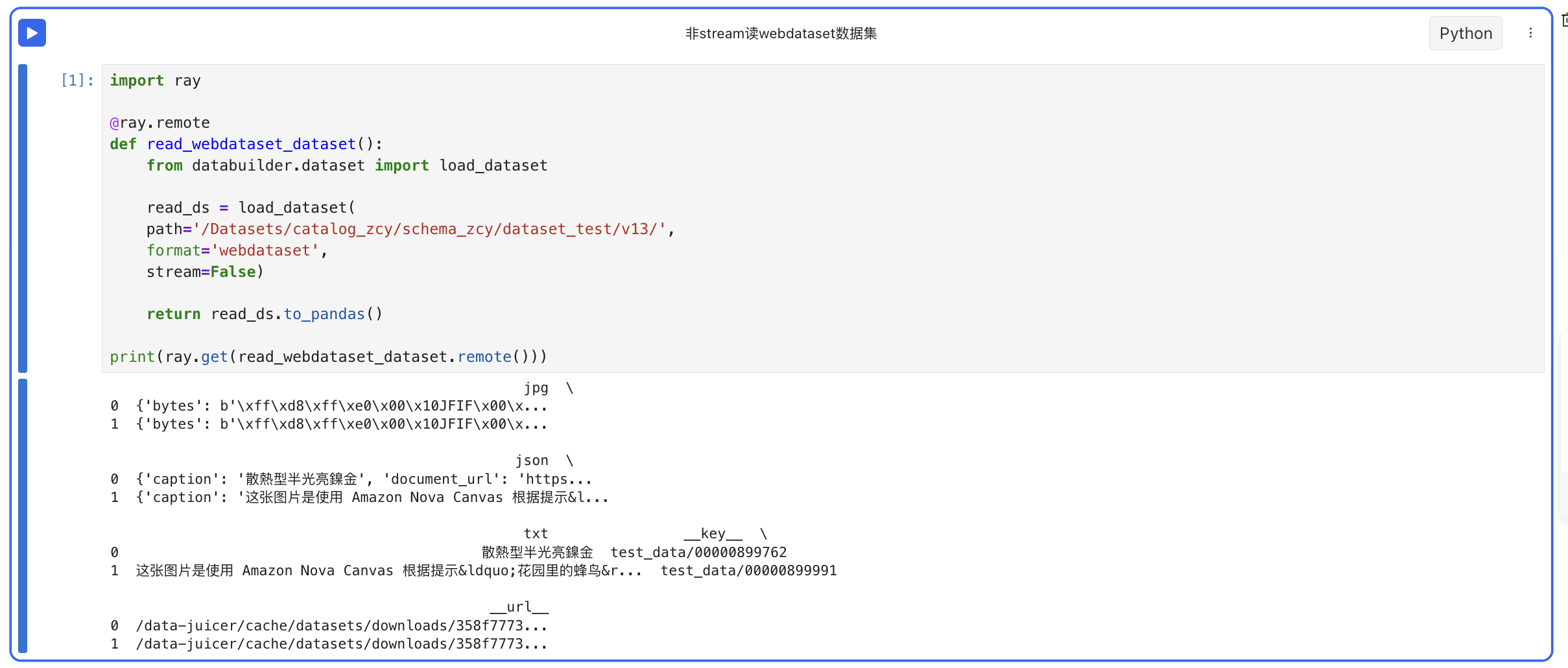
- 非stream读webdataset格式的数据集
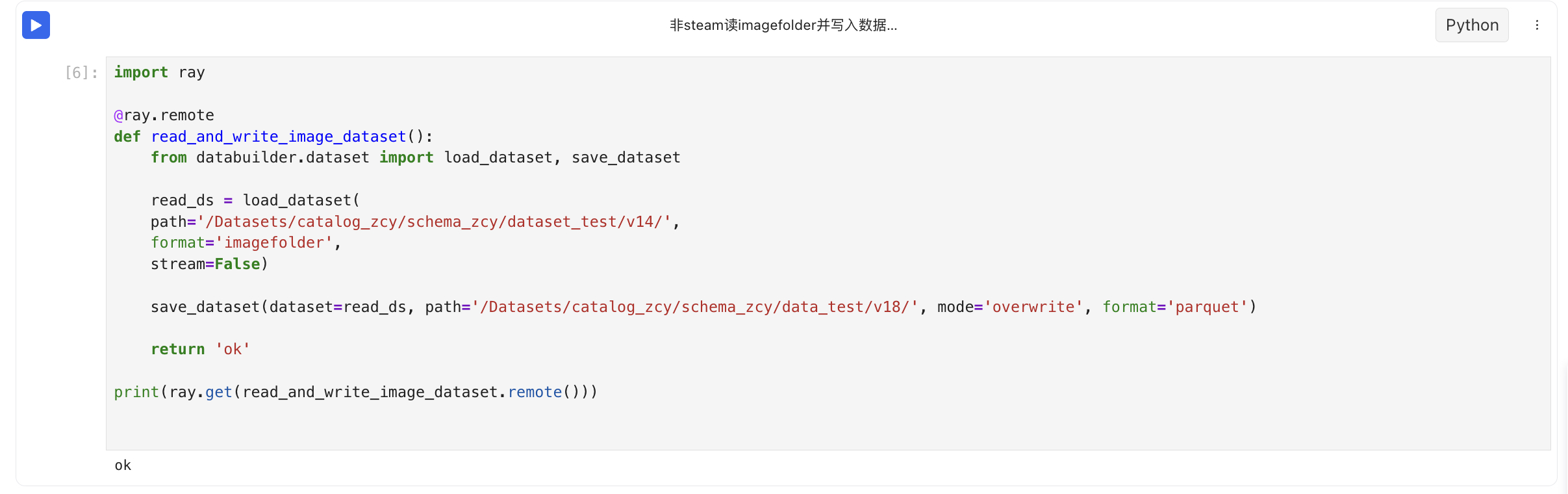
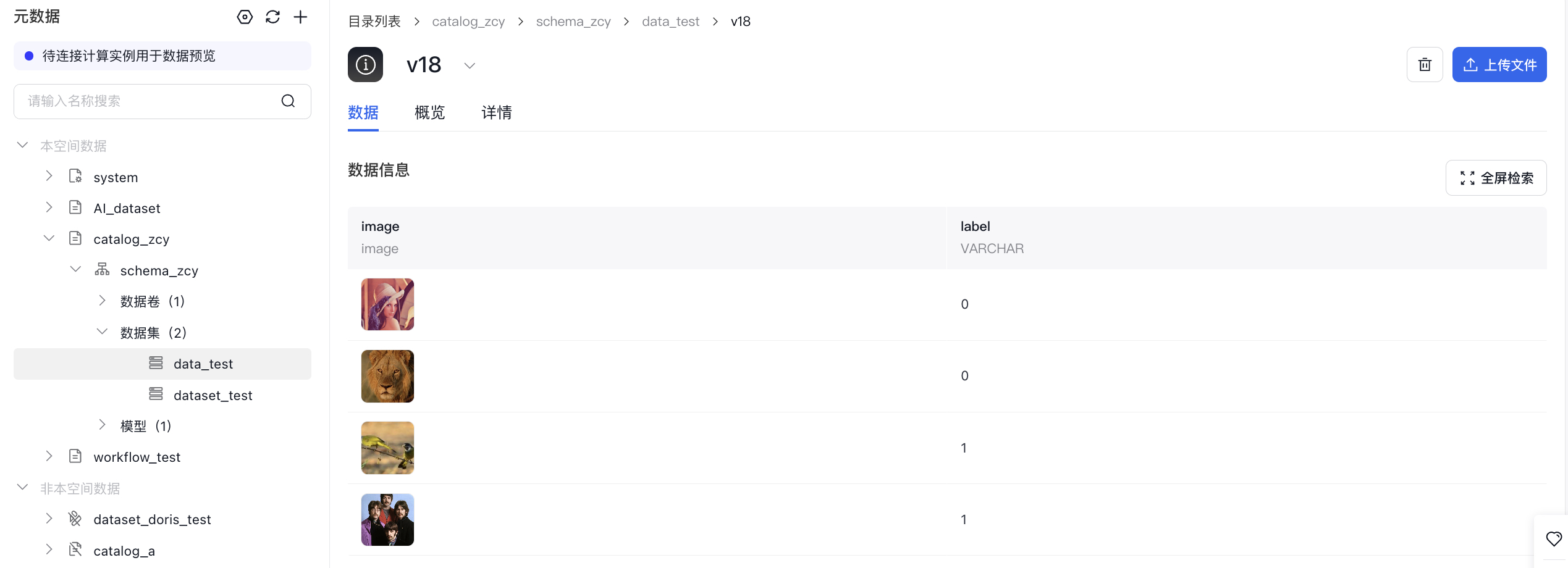
- 非stream读imagefolder格式数据集再以parquet格式写入新数据集
- 非stream读取videofolder格式数据集
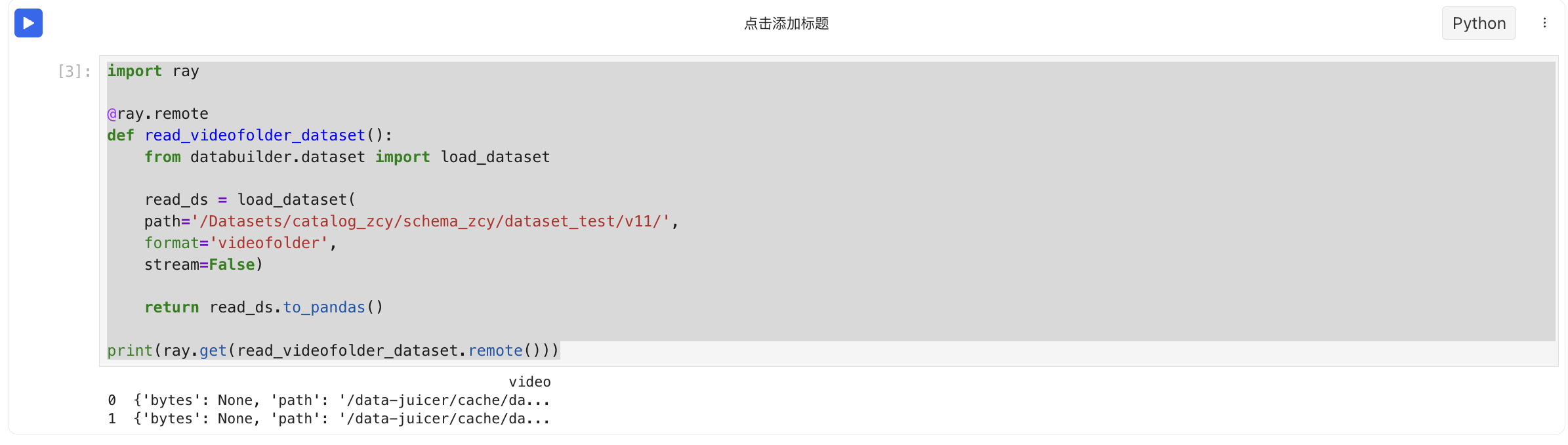
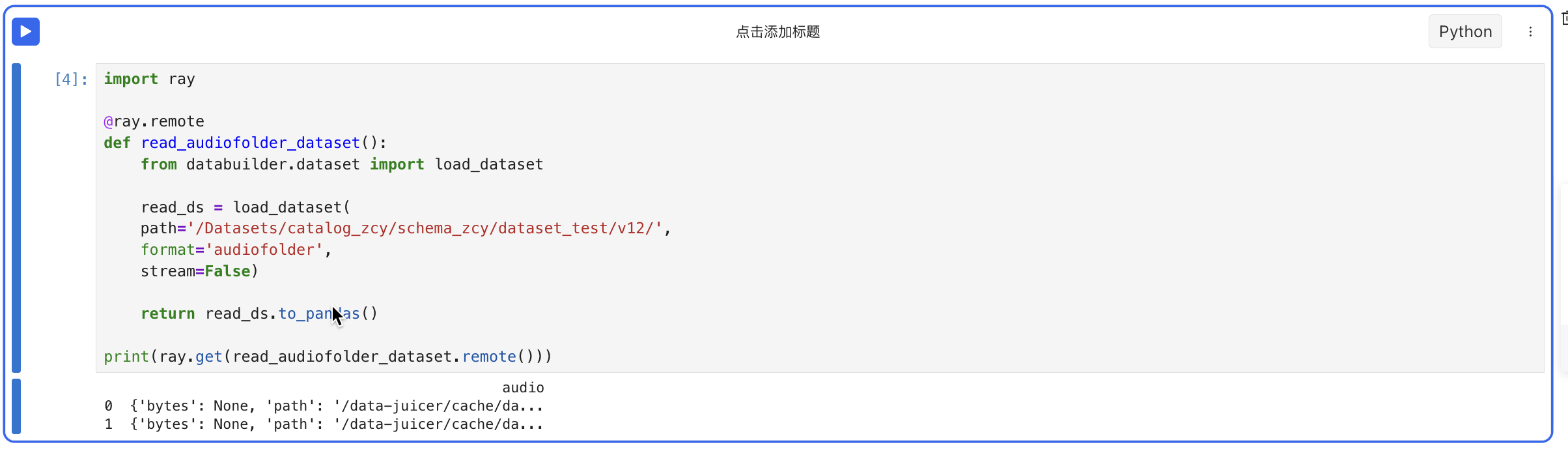
- 非stream读取audiofolder格式数据集
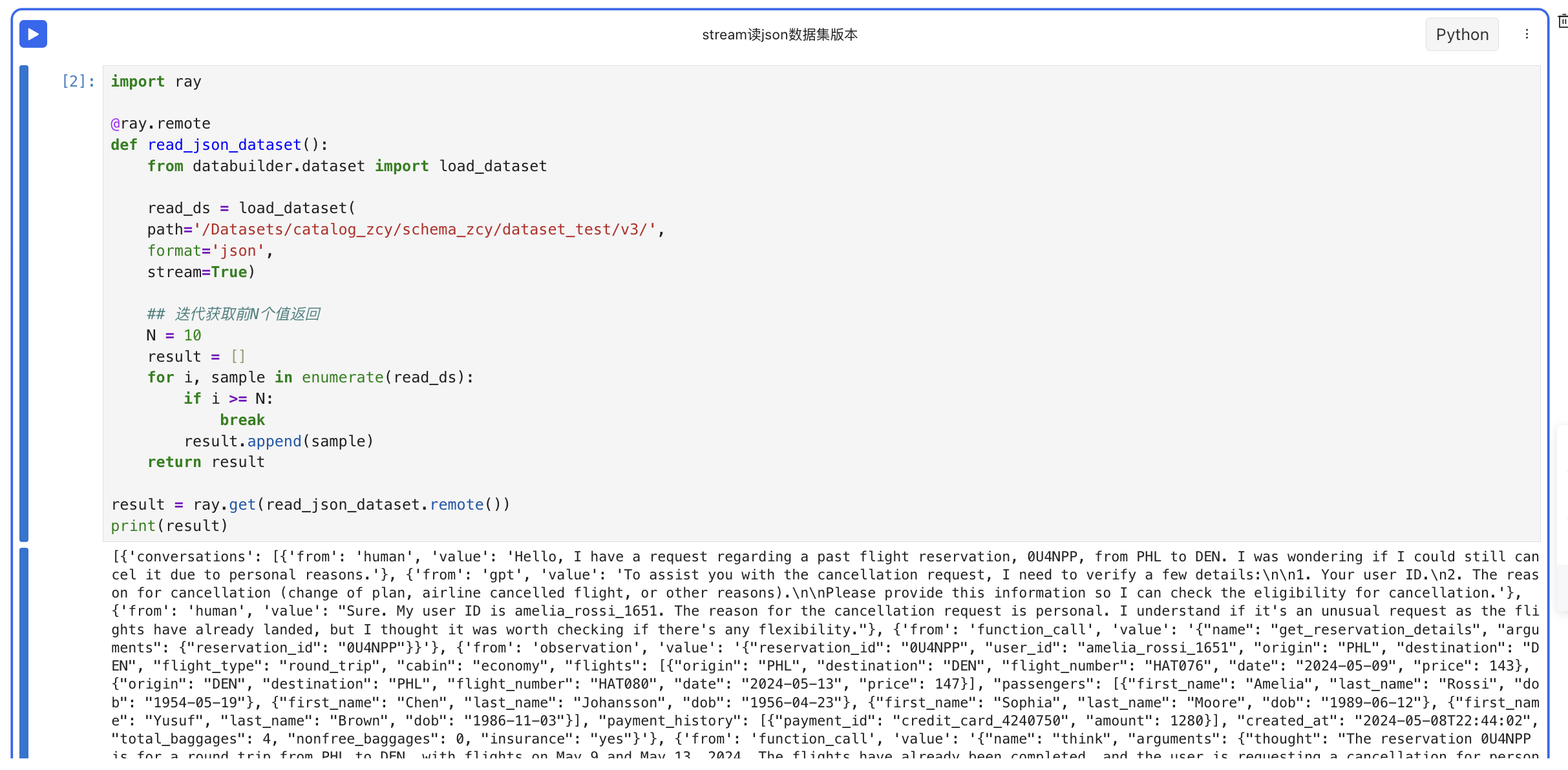
- stream读取json文件
2.2数据集写
2.2.1接口定义
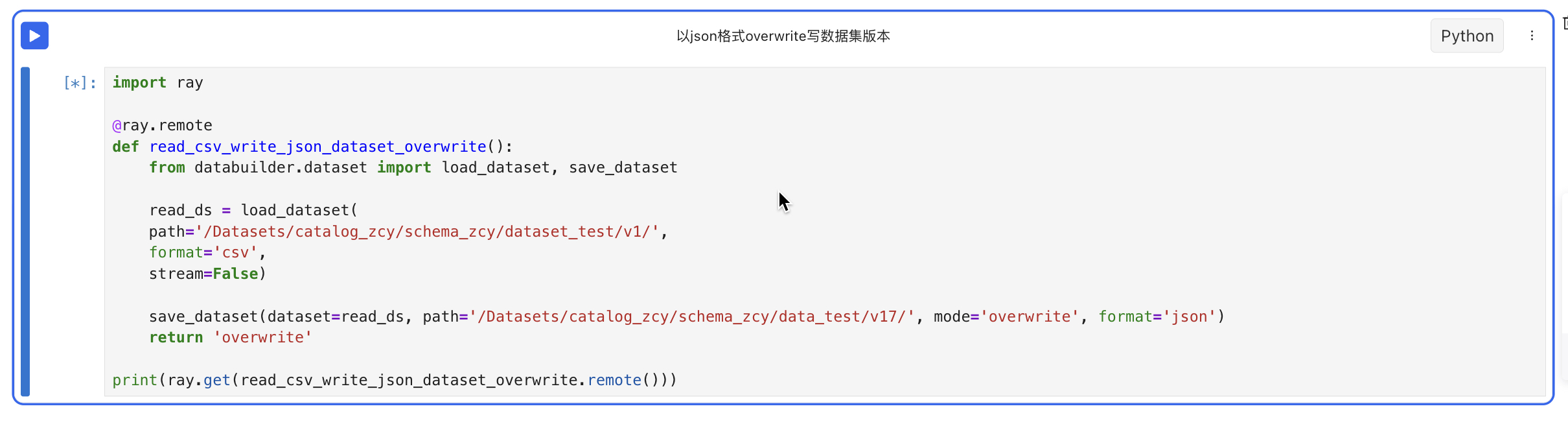
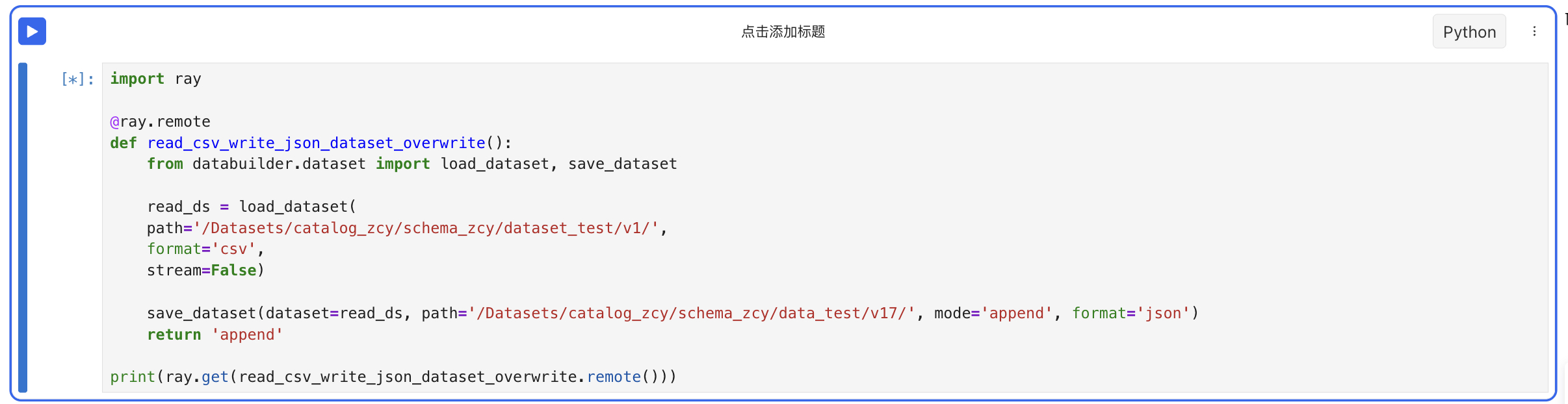
databuilder.dataset.save_dataset(dataset:Union[Dataset, IterableDataset], format:str, path:str**, **mode:str) -> None
dataset:待写的huggingface dataset,可以是流式也可以是非流式Dataset,两种类型Dataset, IterableDataset。
format:dataset导出的数据类型,目前支持csv、json、parquet。其中如果导出为parquet时,多模态数据(图片、视频和音频)会被保存至parquet文件中。
path:数据集中数据路径,是百度胜算中的虚拟路径。
mode:导出模式,目前支持append和overwrite。
2.2.2写格式支持
| 格式 | append模式 | overwrite模式 |
|---|---|---|
| csv | ✅ | ✅ |
| json | ✅ | ✅ |
| parquet | ✅ | ✅ |
2.2.3使用示例
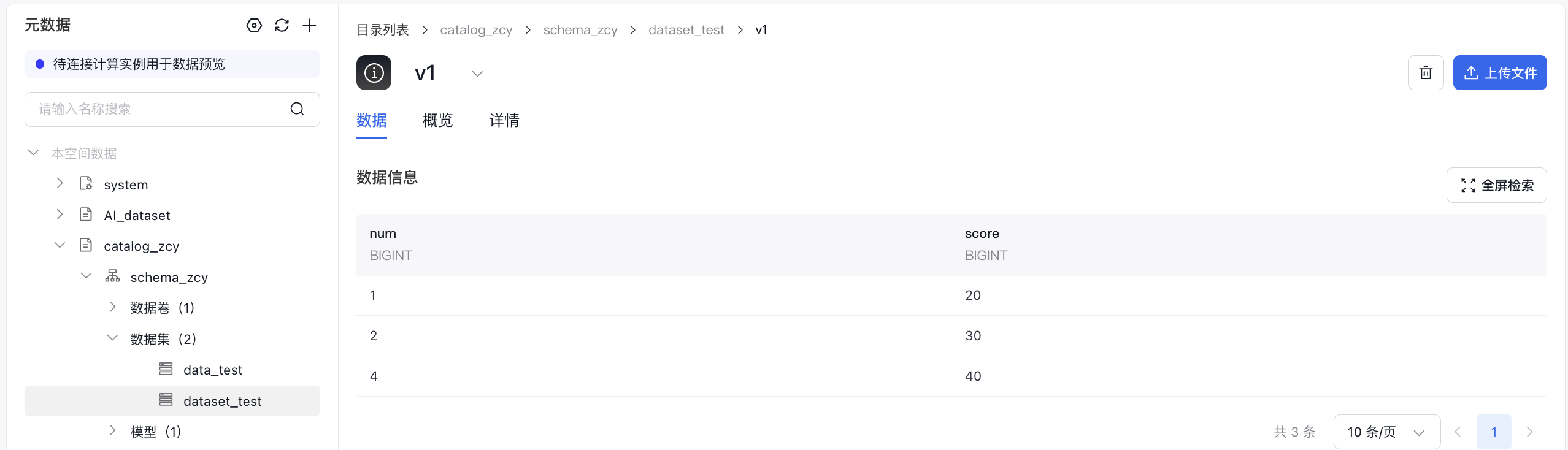
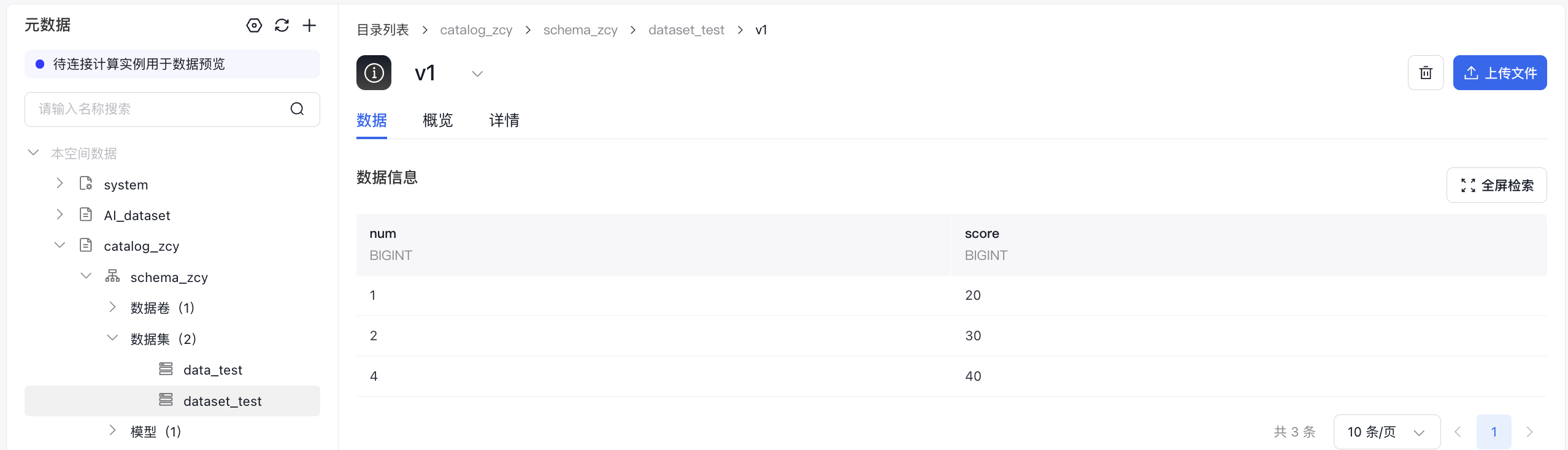
- 读csv格式数据集再以json格式overwrite写入新数据集
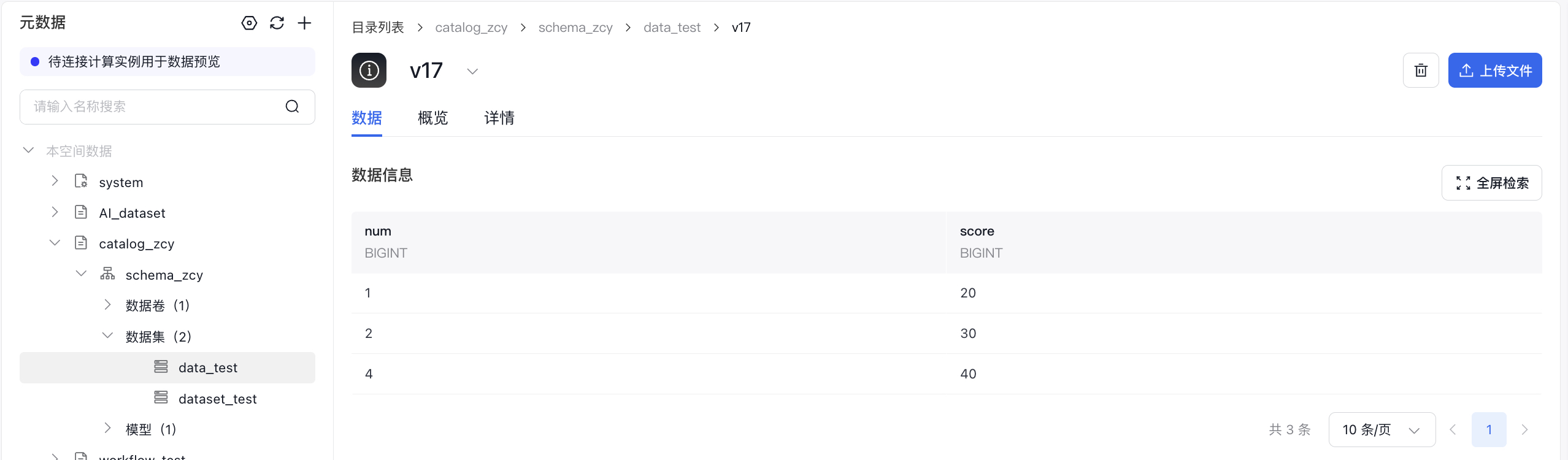
- 读csv格式数据集再以json格式append写入新数据集
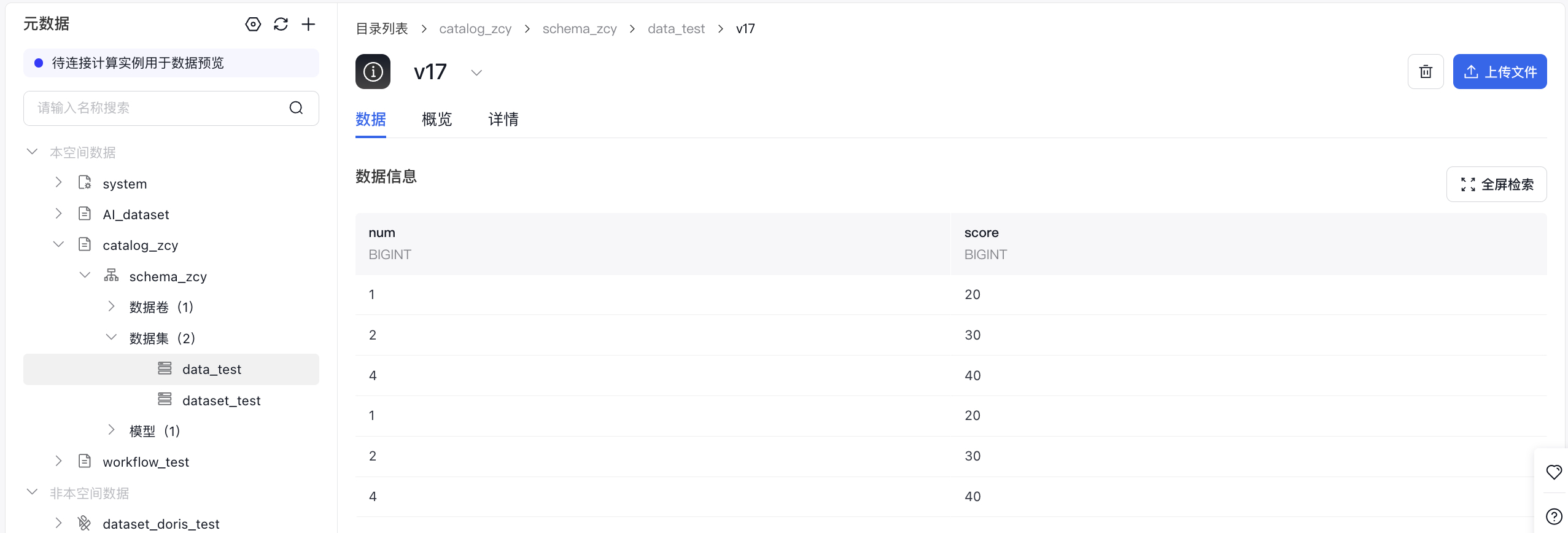
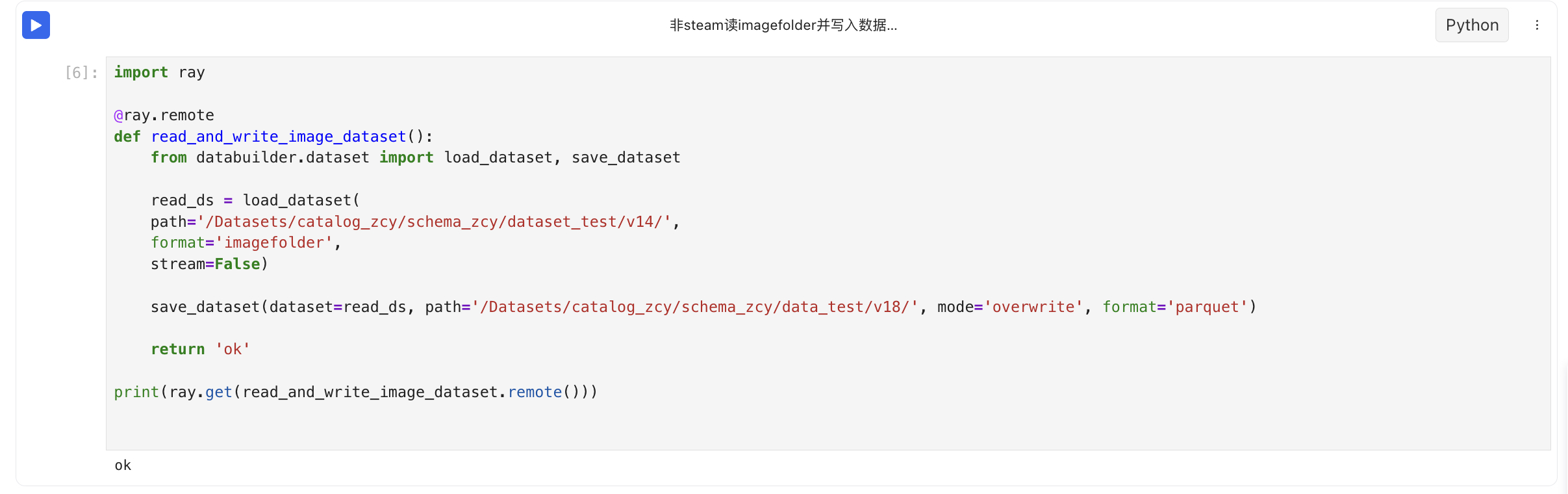
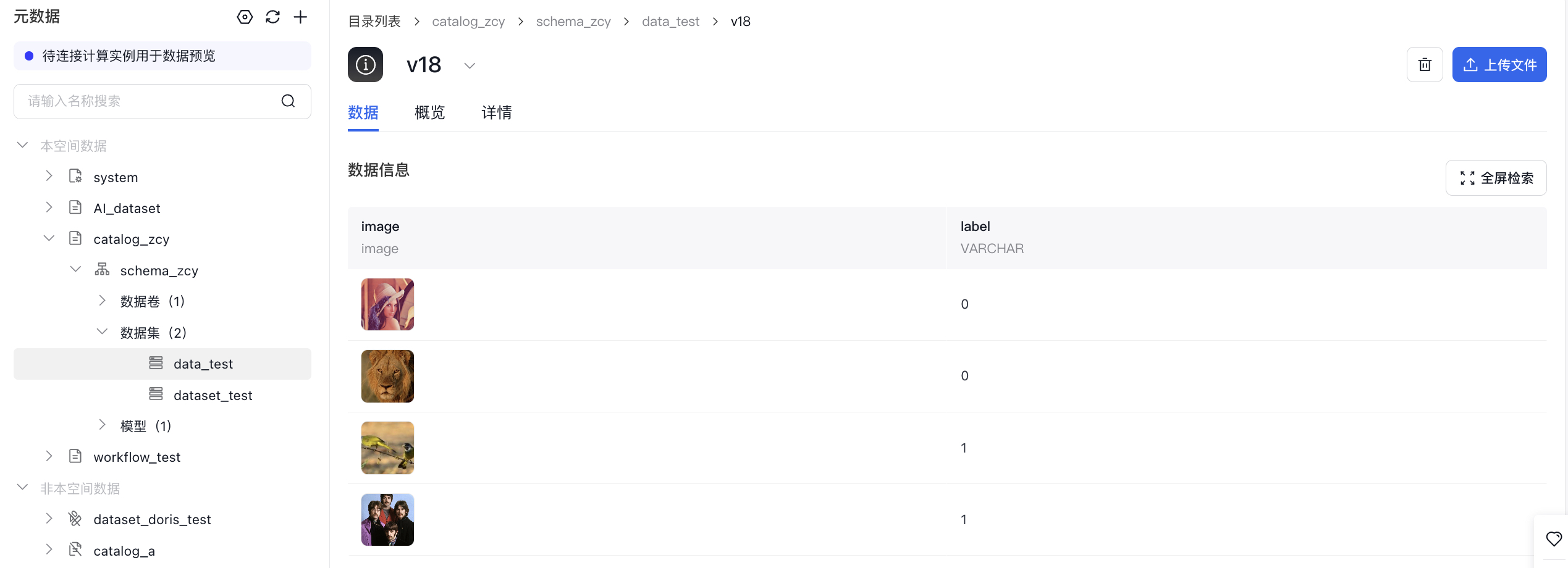
- 读imagefolder格式数据集再以parquet格式写入新数据集
3.Ray.data接口
3.1数据集读
3.1.1接口定义
ray.data.read_databuilder_dataset(path: str, format: str=None, stream: bool=False, download_mode: str = 'reuse_dataset_if_exists') -> Union[Dataset, MaterializedDataset]
path:数据集中数据路径,是百度胜算中的虚拟路径。
format:加载数据使用的格式(非必填),目前支持csv、json、text、parquet、arrow、imagefolder、videofolder、audiofolder、webdataset。不填写使用元数据中数据预览格式。
stream:数据集是否流式懒加载,默认为false。
download_mode:在非流式加载时配置起作用,目前支持三种类型:reuse_dataset_if_exists、reuse_cache_if_exists、force_redownload
3.1.2读格式支持
| 格式 | stream读 | 非stream读 |
|---|---|---|
| csv | ✅ | ✅ |
| json | ✅ | ✅ |
| text | ✅ | ✅ |
| parquet | ✅ | ✅ |
| arrow | ✅ | |
| imagefolder | ✅ |
3.1.3使用示例
1## 使用ray以text格式读数据集版本,非stream模式
2import ray
3ray_dataset = ray.data.read_databuilder_dataset(
4 path='/Datasets/catalog_zcy/schema_zcy/dataset_test/v5/',
5 format='text',
6 stream=False)
7ray_dataset.show()
8
9## 使用ray以text格式读数据集版本,stream模式
10import ray
11ray_dataset = ray.data.read_databuilder_dataset(
12 path='/Datasets/catalog_zcy/schema_zcy/dataset_test/v5/',
13 format='text',
14 stream=True)
15ray_dataset.show()
16
17#######打印结果
18#{'text': '45 0.479492 0.688771 0.955609 0.5955'}
19#{'text': '45 0.736516 0.247188 0.498875 0.476417'}
20#{'text': '50 0.637063 0.732938 0.494125 0.510583'}
21#{'text': '45 0.339438 0.418896 0.678875 0.7815'}
22#{'text': '49 0.646836 0.132552 0.118047 0.0969375'}
23#{'text': '49 0.773148 0.129802 0.0907344 0.0972292'}
24#{'text': '49 0.668297 0.226906 0.131281 0.146896'}
25#{'text': '49 0.642859 0.0792187 0.148063 0.148062'}3.2数据集写
3.2.1接口定义
ray.data.Dataset.write_databuilder_dataset(
1path: str,
2
3mode: str,
4
5format: str = None,
6
7ray_remote_args: Dict[str, Any] = None,
8
9concurrency: Optional[int] = None,) -> None
path:数据集中数据路径,是百度胜算中的虚拟路径。
1 **mode**:导出模式,目前支持append和overwrite。
2
3 **format:** dataset导出的数据类型,目前支持csv、json、parquet。其中如果导出为parquet时,多模态数据(图片、视频和音频)会被保存至parquet文件中。3.2.2写格式支持
| 格式 | append模式 | overwrite模式 |
|---|---|---|
| csv | ✅ | ✅ |
| json | ✅ | ✅ |
| parquet | ✅ | ✅ |
3.2.3使用示例
- 读imagefolder格式数据集再以parquet格式写出
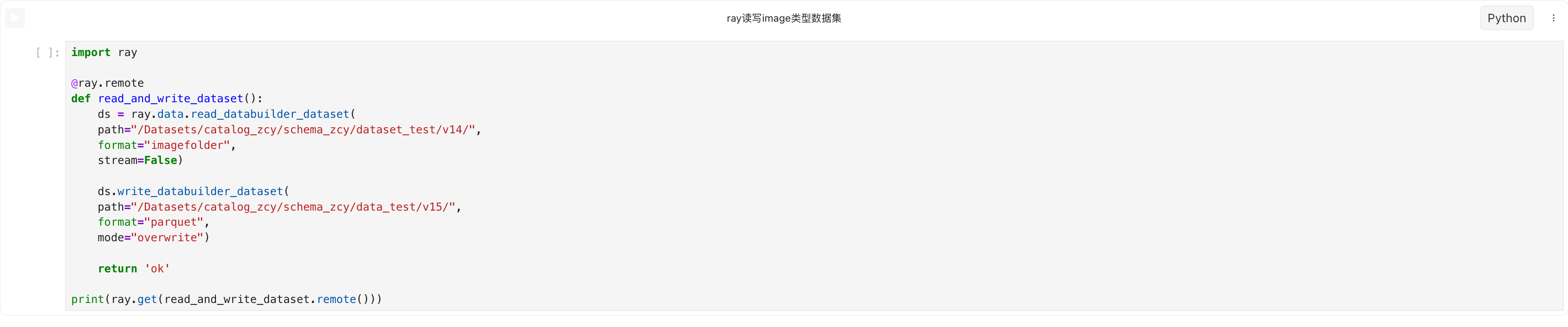
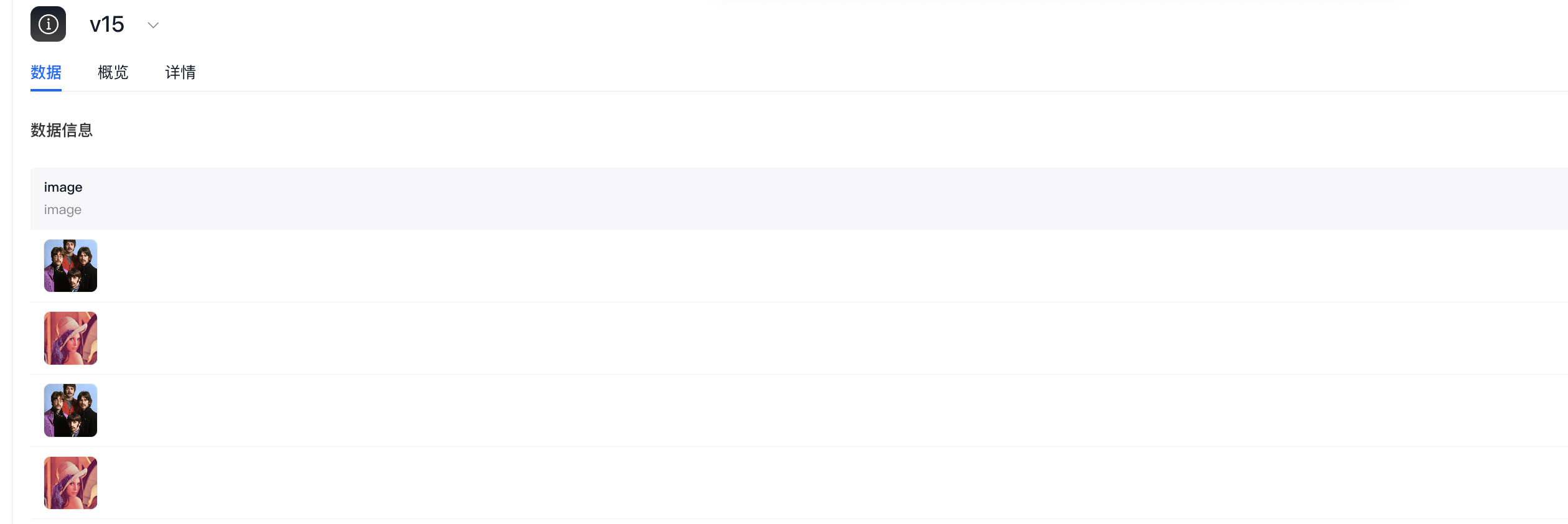
4.数据集读写与Pytorch实践
4.1 Dataset Pytorch Format
- 简单测试
1from datasets import Dataset
2data = [[1, 2],[3, 4]]
3ds = Dataset.from_dict({"data": data})
4ds = ds.with_format("torch")
5print(ds[0])
6>>>{'data': tensor([1, 2])}
7print(ds[:2])
8>>>{'data': tensor([[1, 2],
9 [3, 4]])} - 结合json格式数据集
1from databuilder.dataset import load_dataset
2ds = load_dataset(
3path="/Datasets/catalog_zcy/schema_zcy/data_test/v17/",
4format="json",stream=False)
5
6ds = ds.with_format("torch")
7print(ds[0])
8
9>>>{'num': tensor(1), 'score': tensor(20)}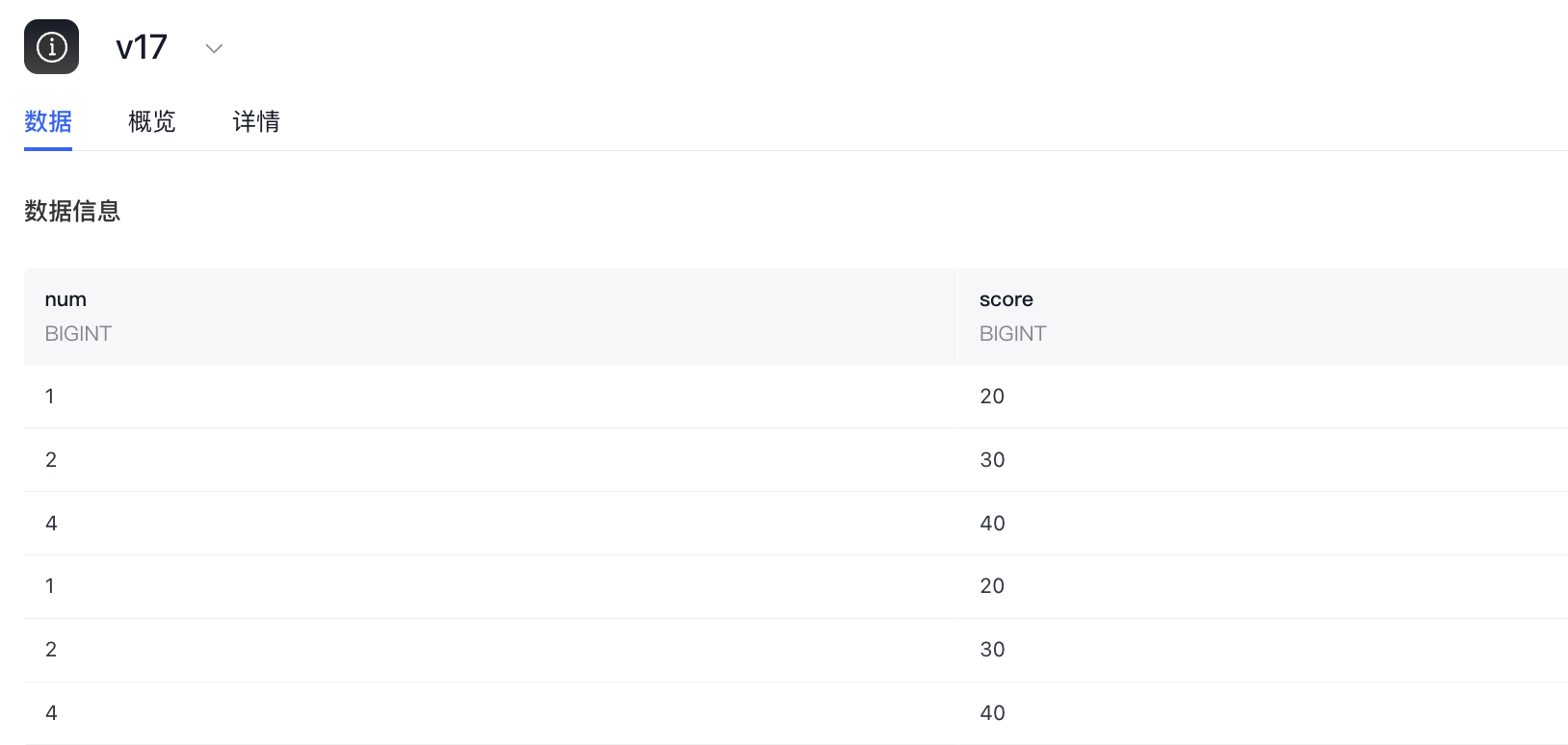
- 结合百度胜算 imagefolder数据集
1from databuilder.dataset import load_dataset
2ds = load_dataset(
3path="/Datasets/AI_dataset/default/dataset_read/v6/",
4format="imagefolder",stream=False)
5ds = ds.with_format("torch")
6print(ds[0])
7print(ds[0]["image"].shape)
8
9>>> {'image': tensor([[[19, 19, 19, ..., 24, 26, 24],
10 [19, 18, 19, ..., 26, 24, 26],
11 [24, 24, 24, ..., 26, 24, 26],
12 ...,
13 [21, 24, 23, ..., 4, 4, 4],
14 [21, 23, 23, ..., 4, 4, 4],
15 [21, 29, 23, ..., 4, 4, 4]]], dtype=torch.uint8), 'label': tensor(0)}
16>>>torch.Size([1, 200, 220])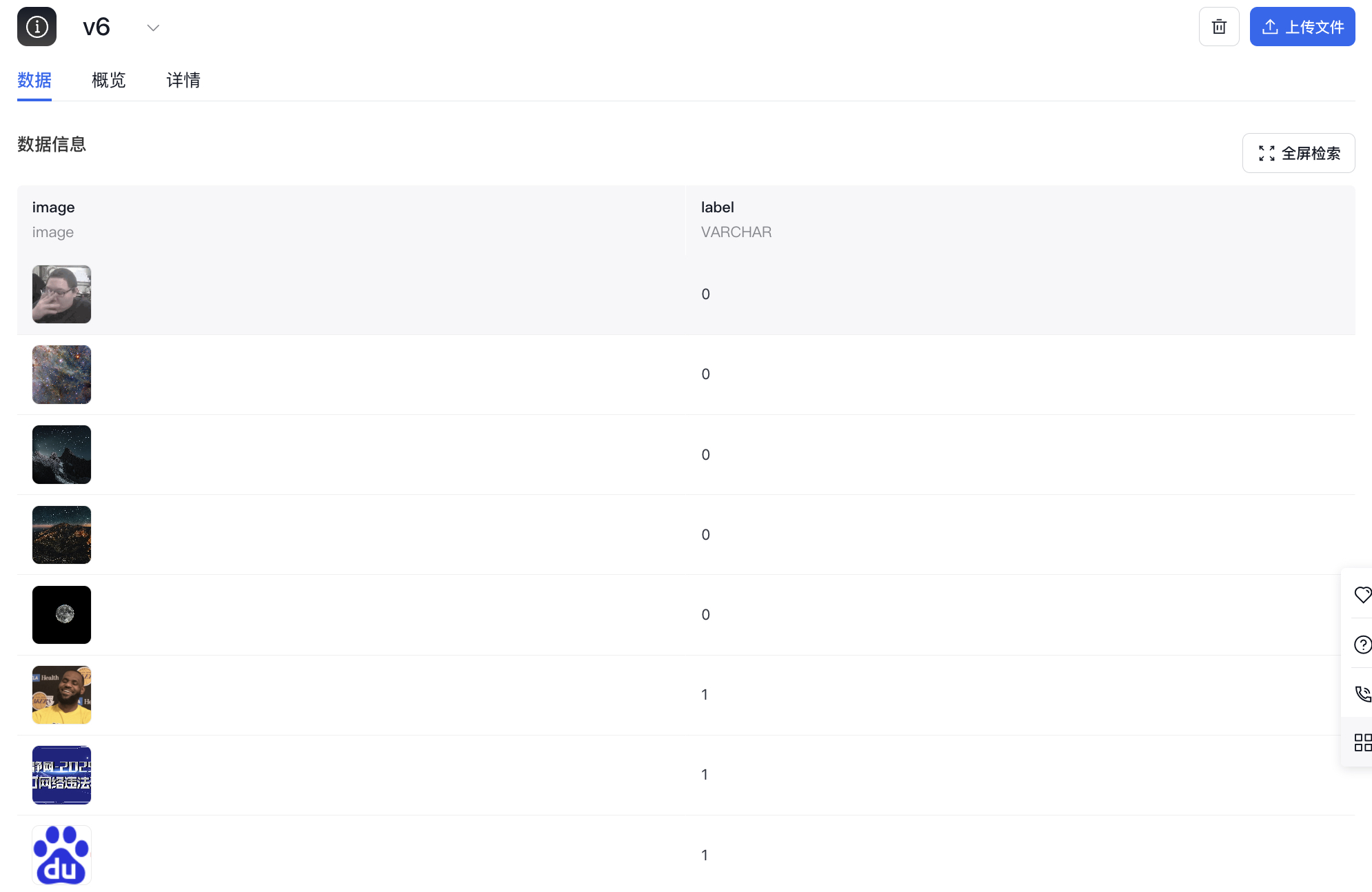
4.2 PyTorch DataLoader
1import numpy as np
2from datasets import Dataset
3from torch.utils.data import DataLoader
4data = np.random.rand(16)
5label = np.random.randint(0, 2, size=16)
6ds = Dataset.from_dict({"data": data, "label": label}).with_format("torch")
7dataloader = DataLoader(ds, batch_size=4)
8for batch in dataloader:
9 print(batch)
10>>>{'data': tensor([0.0047, 0.4979, 0.6726, 0.8105]), 'label': tensor([0, 1, 0, 1])}
11>>>{'data': tensor([0.4832, 0.2723, 0.4259, 0.2224]), 'label': tensor([0, 0, 0, 0])}
12>>>{'data': tensor([0.5837, 0.3444, 0.4658, 0.6417]), 'label': tensor([0, 1, 0, 0])}
13>>>{'data': tensor([0.7022, 0.1225, 0.7228, 0.8259]), 'label': tensor([1, 1, 1, 1])}- 简单测试
1import numpy as np
2from datasets import Dataset
3from torch.utils.data import DataLoader
4data = np.random.rand(16)
5label = np.random.randint(0, 2, size=16)
6ds = Dataset.from_dict({"data": data, "label": label}).with_format("torch")
7dataloader = DataLoader(ds, batch_size=4)
8for batch in dataloader:
9 print(batch)
10>>>{'data': tensor([0.0047, 0.4979, 0.6726, 0.8105]), 'label': tensor([0, 1, 0, 1])}
11>>>{'data': tensor([0.4832, 0.2723, 0.4259, 0.2224]), 'label': tensor([0, 0, 0, 0])}
12>>>{'data': tensor([0.5837, 0.3444, 0.4658, 0.6417]), 'label': tensor([0, 1, 0, 0])}
13>>>{'data': tensor([0.7022, 0.1225, 0.7228, 0.8259]), 'label': tensor([1, 1, 1, 1])}- 结合json格式数据集
1from databuilder.dataset import load_dataset
2from torch.utils.data import DataLoader
3ds = load_dataset(
4path="/Datasets/catalog_zcy/schema_zcy/data_test/v17/",
5format="json",stream=False)
6
7ds = ds.with_format("torch")
8dataloader = DataLoader(ds, batch_size=4)
9for batch in dataloader:
10 print(batch)
11
12>>>{'num': tensor([1, 2, 4, 1]), 'score': tensor([20, 30, 40, 20])}
13>>>{'num': tensor([2, 4]), 'score': tensor([30, 40])}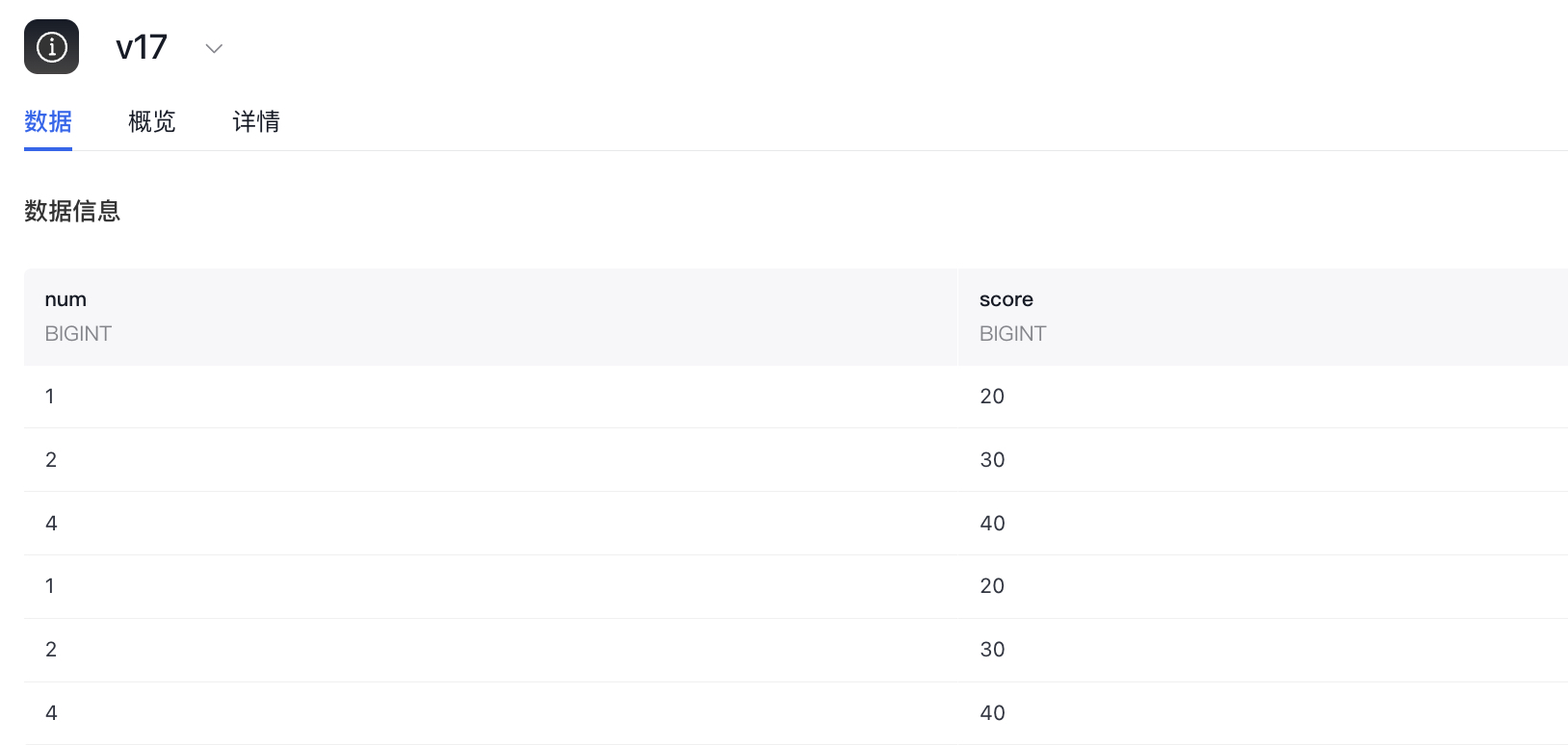
- 结合百度胜算 imagefolder数据集
1from databuilder.dataset import load_dataset
2from torch.utils.data import DataLoader
3ds = load_dataset(
4path="/Datasets/AI_dataset/default/dataset_read/v6/",
5format="imagefolder",stream=False)
6ds = ds.with_format("torch")
7
8def my_collate_fn(batch):
9 return batch
10dataloader = DataLoader(ds, batch_size=1, collate_fn=my_collate_fn)
11
12for batch in dataloader:
13 print(batch[0]["image"].shape)
14
15>>>torch.Size([1, 200, 220])
16>>>torch.Size([3, 4000, 2784])
17>>>torch.Size([3, 5472, 3648])
18>>>torch.Size([3, 4500, 3000])
19>>>torch.Size([3, 3326, 4989])
20>>>torch.Size([1, 400, 400])
21>>>torch.Size([3, 529, 1242])
22>>>torch.Size([4, 64, 204])评价此篇文章