
实时同步
实时同步即将源端数据实时同步至目标端,确保目标数据持续更新以反映源端的变化。此过程对于需要最新数据的应用程序至关重要,例如实时分析和运营监控等。本文主要介绍了实时同步的基础条件、进入实时同步的步骤、操作步骤和任务配置等内容,旨在帮助读者理解和掌握实时同步的功能和操作方法。
基础条件
资源配置
资源配置在EDAP首页侧边栏系统中心>资源管理中,点击+添加资源配置需要的数据源。
源端数据源配置说明
目前,数据集成源端类型支持 MySQL、SQL Server、Oracle、Hana、PostgreSQL 版本,下面是关于版本和源端类型具体说明。
表一 目前数据集成源端类型支持的版本
| 数据源 | 支持版本 |
|---|---|
| MySQL | 支持MySQL5.5, 5.6, 5.7, 8.0 |
| SQLServer | SQLServer2016, 2014, 2012 |
| Oracle | 支持Oracle11, 12.1, 19 |
| PostgreSQL | 支持PostgreSQL8.2及以上 |
MySQL
1.开启mysql binlog功能
判断mysql是否开启binlog,并且binlog_format配置为ROW
执行:
1# OFF:关闭, ON:开启
2SHOW VARIABLES LIKE 'log_bin';
3#
4show variables like '%binlog_format%';- 如果log_bin是ON,且则表明mysql已开启binlog;binlog_format值需为ROW
- 如果前置配置不满足按照2步骤配置
2.开启cdc配置
1#第一种方式:
2#开启binlog日志
3log_bin=ON
4#binlog日志的基本文件名
5log_bin_basename=/var/lib/mysql/mysql-bin
6#binlog文件的索引文件,管理所有binlog文件
7log_bin_index=/var/lib/mysql/mysql-bin.index
8#配置serverid
9server-id=1
10
11#第二种方式:#此一行等同于上面log_bin三行
12log-bin=/var/lib/mysql/mysql-bin
13#配置serverid
14server-id=1
15
16# binlog_format默认值是ROW,如果配置文件中修改成其他值,需要改回ROW
17binlog_format = ROW具体的log-bin文件位置根据需要进行修改
配置完毕后,重启mysql
再次执行SHOW VARIABLES LIKE 'log_bin';查看是否开启。
3.用户需要的权限
表二 对应权限说明
| 权限 | 权限说明 |
|---|---|
| SELECT | 用于从数据库中读取数据,在snapshot阶段使用 |
| RELOAD | 用于执行flush语句来刷新数据库内部缓存,在snapshot阶段使用 |
| SHOW DATABASES | 用于显示database名字,在snapshot阶段使用 |
| REPLICATION SLAVE | 允许connector连接并读取mysql binlog |
| REPLICATION CLIENT | 运行connector使用SHOW MASTER STATUS,SHOW SLAVE STATUS,SHOW BINARY LOGS命令 |
SQL Server
1.开启数据库cdc
1-- 选择要开启cdc的数据库
2USE ${database}
3GO
4-- 执行procedure
5EXEC sys.sp_cdc_enable_db
6GO开启数据表cdc
前提条件:
- 数据库开启了cdc
- sql server agent处于运行中
- 当前用户属于db_owner
1USE ${database}
2GO
3
4EXEC sys.sp_cdc_enable_table
5@source_schema = N'${schema}',
6@source_name = N'${tableName}',
7@role_name = N'${roleName}',
8@filegroup_name = N'${filegroupName}',
9@supports_net_changes = 0
10GO注意:1. roleName表示要给予select权限的用户,如果设置为Null表示只允许在sysadmin或db_owner的角色有完全权限去读取cdc数据
- cdc文件的文件组名最好不要和源表的文件组名一致
2.检查用户权限
表三 SQL Server权限说明
| 数据库级别的角色名称 | 说明 |
|---|---|
| db_owner | db_owner固定数据库角色的成员可以执行数据库的所有配置和维护活动,还可以删除数据库。 |
| db_securityadmin | db_securityadmin固定数据库角色的成员可以修改角色成员身份和管理权限。向此角色中添加主体可能会导致意外的权限升级。 |
| db_accessadmin | db_accessadmin固定数据库角色的成员可以为Windows登录名、Windows组和SQLServer登录名添加或删除数据库访问权限 |
| db_backupoperator | db_backupoperator固定数据库角色的成员可以备份数据库。 |
| db_ddladmin | db_ddladmin固定数据库角色的成员可以在数据库中运行任何数据定义语言(DDL)命令。 |
| db_datawriter | db_datawriter固定数据库角色的成员可以在所有用户表中添加、删除或更改数据。 |
| db_datareader | db_datareader固定数据库角色的成员可以从所有用户表中读取所有数据。 |
| db_denydatawriter | db_denydatawriter固定数据库角色的成员不能添加、修改或删除数据库内用户表中的任何数据。 |
| db_denydatareader | db_denydatareader固定数据库角色的成员不能读取数据库内用户表中的任何数据。 |
您可以通过以下命令检查:
1USE ${database};通过
2GO
3EXEC sys.sp_cdc_help_change_data_capture
4GO如果返回结果为空,说明该用户没有相应权限。
Oracle
1.开启数据表cdc
开启oracle logminer
1ORACLE_SID=ORACLCDB dbz_oracle sqlplus /nolog
2
3-- 配置归档日志大小和地址,重启oracle
4CONNECT sys/top_secret AS SYSDBA
5alter system set db_recovery_file_dest_size = 10G;
6alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
7shutdown immediate
8startup mount
9-- 开启归档日志
10alter database archivelog;
11alter database open;
12
13-- 查看归档日志,如果打印“Database log mode: Archive Mode”,则表明文件归档功能已经开启
14archive log list
15
16exit;开启logminer的时候需要重新启动
开启supplemental logging(辅助 logminer)
1-- 给表开启增强日志功能
2ALTER TABLE FLINKUSER.CUSTOMERS ADD SUPPLEMENTAL LOG DATA(ALL)COLUMNS;
3
4-- 开给数据库开启增强日志功能
5ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;2.用户权限
表四 权限和权限说明
| 权限 | 权限说明 | 补充说明 |
|---|---|---|
| CREATE SESSION | 用于连接oracle | |
| SET CONTAINER | 让connector可以在pluggable databases中进行切换,仅限于开启了CDB(container database support)模式 | 版本大于oracle11g才需要该权限 |
| SELECT ON V_$DATABASE | 读取V$DATABASE表(一种视图) | |
| SELECT ANY TABLE | 允许读取各个表 | |
| SELECT_CATALOG_ROLE | 允许读取data dictionary,主要用于LogMiner阶段 | |
| EXECUTE_CATALOG_ROLE | 允许把data dictionary写入redo log中,主要用于监控schema变化 | |
| SELECT ANY TRANSACTION | 允许在snapshot阶段,对每个事务进行flashback snapshot。当FLASHBACK ANY TABLE开启后,该权限也需要开启 | |
| LOGMINING | 在新版本的oracle中,给予访问oracle的LogMiner和相应包的权限 | 版本大于oracle11g才需要该权限 |
| CREATE TABLE | 允许connector在default namespace中创建flush table,flush table允许connector显示得把LGWR缓存写入到磁盘中 | |
| ALTER ANY TABLE | 修改任何表 | |
| CREATE SEQUENCE | 创建序列 | |
| EXECUTE ON DBMS_LOGMNR | 允许connector在DBMS_LOGMNR package中运行方法,如果要和Oracle LogMiner进行交互,这个权限是必须的 | |
| SELECT ON V$LOG TO ${user} SELECT ON V$LOGHISTORY TO ${user} SELECT ON V$LOGMNRLOGS TO ${user} SELECT ON V$LOGMNRCONTENTS TO ${user} SELECT ON V$LOGMNRPARAMETERS TO ${user} SELECT ON V$LOGFILE TO ${user} SELECT ON V$ARCHIVED_LOG TO ${user} SELECT ON V$ARCHIVEDEST_STATUS TO ${user} SELECT ON V$TRANSACTION TO ${user} |
允许connector读取这些表,主要是让connector读取oracle的redo和archive日志和当前事务状态。 |
PostgreSQL
1.开启cdc
编辑postgresql.conf使用replication slots方式针对pg的wals日志实现logical decoding
1# Use logical decoding with the write-ahead log.
2wal_level=logical
3# maximum of one separate process for processing WAL changes.
4max_wal_senders=10
5# Allow a maximum of one replication slot to be created for streaming WAL changes.
6# 每个cdc_job会创建一个独立的slot,该参数需要根据实际情况进行设计,任务失效时会自动drop
7max_replication_slots=10以上三个配置修改后需要重启pg
检查方式:
1show wal_level; #返回logical则正确
2show server_version; #查看版本2.用户权限
表五 权限和权限说明
| 权限 | 权限说明 | 检查方式 |
|---|---|---|
| REPLICATION | 用户需要有RELICATION权限 新建用户:CREATE USER cdc_user WITH PASSWORD '***' REPLICATION; 增加权限:alter user cdc_user REPLICATION; |
select rolreplication from PG_ROLES where rolname='cdc_user' 返回结果是t有权限,f无权限 |
| USAGE | 用户需要schema的USAGE权限 grant USAGE on SCHEMA di_test to cdc_user; |
select * from pg_namespace where nspname='di_test'; 返回的nspacl字段中是否包含cdc_user,cdc_userd的权限是否包含U |
| SELECT | 用户需要对同步表的SELECT权限 grant select on TABLE di_test.company to cdc_user; |
SELECT * FROM information_schema.table_privileges WHERE GRANTEE='cdc_user' and privilege_type='SELECT' and table in ('t1', t2) ; 会返回cdc_user有权限的表列表 |
进入实时同步
创建实时同步任务的入口点位于EDAP首页数据加工>我的项目中数据集成模块内。要启动创建过程,您需要进入数据集成模块页面。
启动创建过程:
- 启动方式:
进入数据集成模块页面。
- 创建实时同步任务入口
数据加工>我的项目中数据集成模块内。
1.如没有项目,需先新建项目。
点击我的项目>【新建项目】,填入您的项目相关属性后点击提交项目即创建成功。
项目创建步骤:
- 进入界面:点击我的项目
- 开始新建:选择【新建项目】
- 填写信息:填入项目相关属性
- 完成创建:点击提交项目
注:项目中文名和英文名是必填项,且项目英文名创建后不允许修改。
2.已有项目,进入实时同步界面
通过选择导航栏中的【数据加工】,然后选择“我的项目”来访问实时同步界面。选择对应项目后单击项目名称,查找【数据集成】使用实时同步功能。
访问实时同步界面:
- 通过选择导航栏中的【数据加工】。
- 然后选择“我的项目”。
使用实时同步功能:
- 单击项目名称选择对应项目。
- 查找【数据集成】使用实时同步功能。
操作步骤
任务创建 --> 任务配置 --> 任务运维
任务创建
在开始特定数据集成任务的配置之前,必须在平台内创建任务。无论所涉及的数据源或目标的类型如何,都需要执行此预备步骤。
以下是两种创建任务的概述:
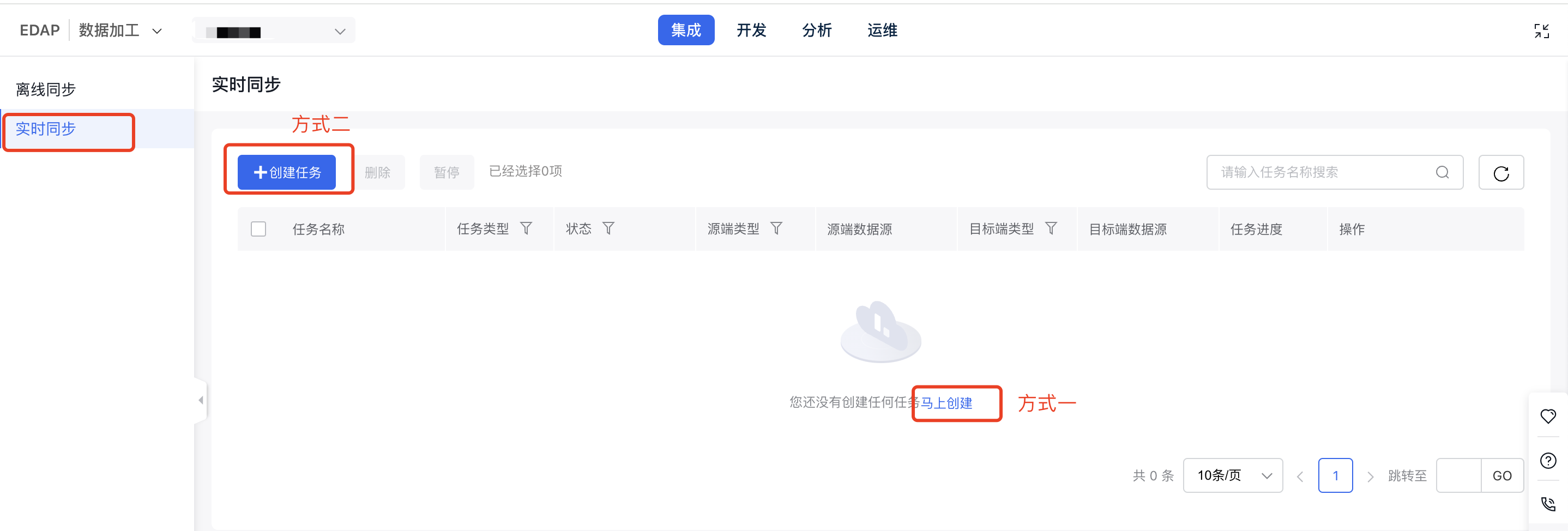
1.进入实时同步界面,单击+创建任务图标。
2.在实时同步界面中,点击列表页面中央的马上创建。
以上两种方式创建任务后,跳转任务配置界面。
图一 创建任务界面
任务配置
目标端数据源类型为Doris、EDAP,配置一个数据集成任务分为“设置同步来源与目标”、“读取设置”、“批量设置”、“写入设置”四个步骤。其中,“设置同步来源与目标”、“读取设置”属于公共配置,“写入设置”在目标端上有所不同。
本章节首先以EDAP为例分析公共配置,然后按照目标端类型分别介绍“写入设置”的操作说明。
设置同步来源与目标
基本信息
配置任务基本名称
注意命名规范要求:只能包含英文字母、数字、中划线和下划线,且以英文字母开头,不大于64个字符),同一个项目中的同步任务名不能重复
源端设置
在源端设置配置数据类型和选择已配置好的数据源,数据源配置在EDAP主页配置栏,详见基础条件-源端配置说明。
目标端设置
在目标端设置目标类型、数据源和数据库,目前类型支持Doris、EDAP 数据湖。
迁移类型
迁移类型针对所有目标端类型,目前可支持的迁移类型:全量及增量迁移
其中,目标端如果为EDAP类型,需增加资源配置选项,可以选择计算资源。
资源配置
资源配置需要在 EDAP 界面上配置资源,选择【资源管理】,找到合适的计算资源,点击计算资源右侧的【绑定项目】来绑定到该 EDAP 项目中。
读取设置
1.点击读取设置旁边“+”按钮,在读取列表中可以在单个同步任务中批量选择多个数据库和表进行读取,还可以在编辑阶段向任务添加更多表。
图一 选择读取列表界面
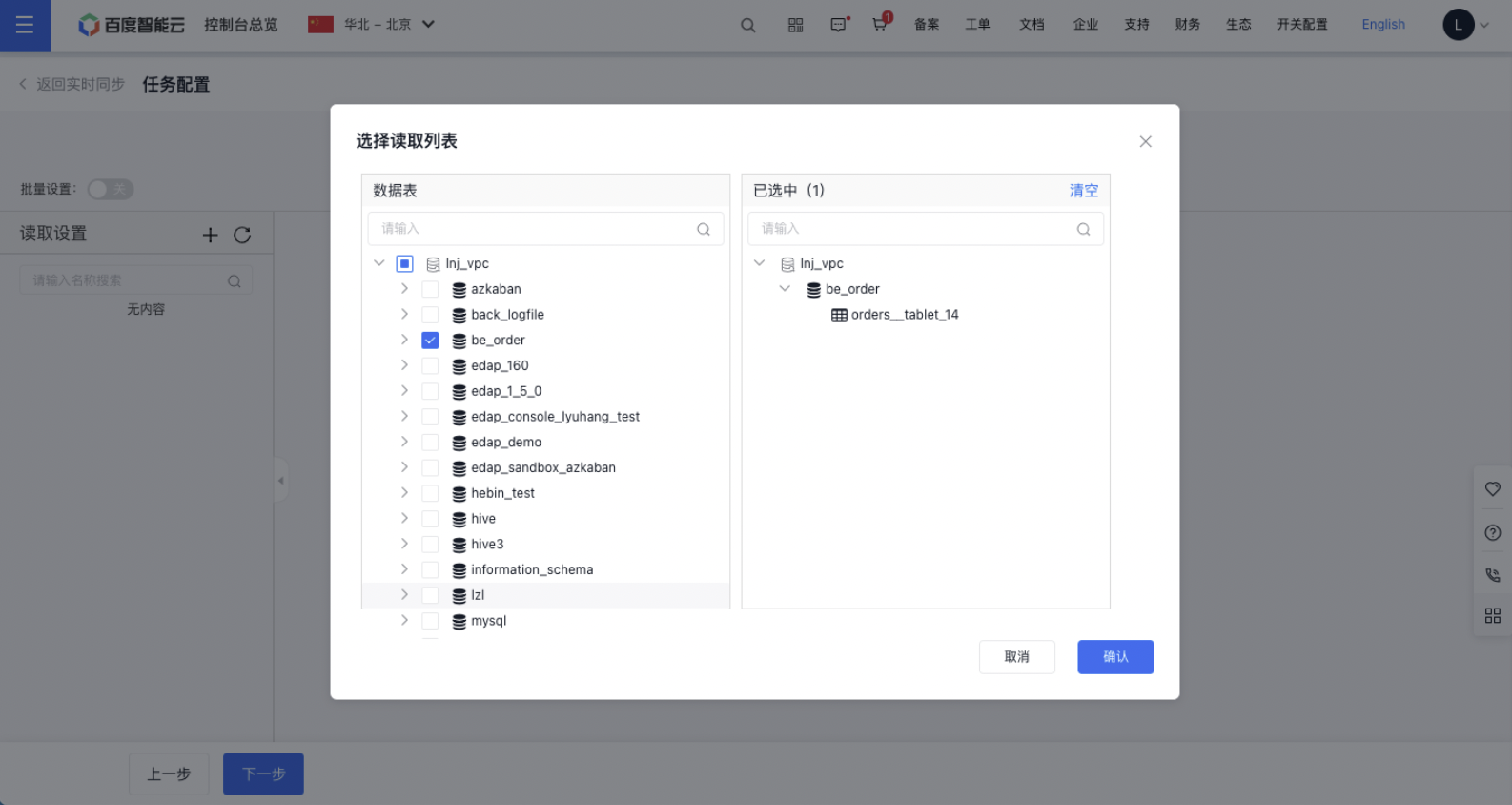
2.读取设置中,左上方默认为关闭“批量设置”的状态,点击左边的表,针对每个单表进行配置,通过下方的where语句过滤单表的数据,目前仅支持 logicStartTime 宏。
注:LST宏表达式格式: ${logicalStartTime(yyyy.?MM.?dd.? HH.?mm.?ss.?(SSS)?(,[+-]?[0-9]*[yMdhms])? )}
批量设置
可批量设置所有表的部分写入设置。可打开左上方“批量设置”按钮,通过where语句批量过滤不需要的数据,在执行中是将此where语句应用在每个单表上,分别过滤每个所选择的表中的数据。在读取设置结束后,进入批量设置。填入副本数和需要的表名设置后点击下一步即设置成功。
批量设置仅在⽬标端建表⽅式为“⾃动建表“时⽣效
EDAP类型
EDAP批量设置界面,可批量配置表的存储格式、表名的前后缀、新增字段、静态分区。
目标表设置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 数据糊格式 | 无 | 必选,枚举值:无、hudi |
| 存储格式 | Parquet | 必选无:Parquet、ORChudi:Parquet |
| hudi表类型 | 默认无此项 | hudi表枚举值:MOR、COW,默认MOR |
| hudi表主键 | 默认无此项 | 字段名允许修改, 提示说明:可指定目标端主键名称,若不指定目标端主键,默认生成EDAP_UUID字段作为表主键,字段值为随机UUID字符串 |
| 表名设置 | 无 | 无前后缀、增加前后缀、增加前缀、增加后缀 |
新增字段设置
可以批量增加目标端表字段,同时支持固定值及时间宏函数变量:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 字段名称 | 无 | 新增字段名称,若新增字段名称与表已有字段冲突,则单表配置或任务完成时进行右上角报错提示:新增字段与表已有字段冲突! |
| 字段类型 | String | 枚举值:String、INT、BIGINT、DOUBLE、DECIMAL |
| 默认值 | 无 | 可填写固定值,如,1可填写时间宏函数 |
| 操作 | 无 | 增加/删除 |
分区设置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 字段名称 | 无 | 新增字段名称 |
| 字段类型 | String | 枚举值:String、INT、BIGINT、DOUBLE、DECIMAL |
| 分区值 | 无 | 填写分区值 |
| 操作 | 无 | 增加/删除 |
Doris类型
Doris批量设置界面,可批量配置表的存储格式、表名的前后缀、新增字段
目标表设置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| Doris表格式 | Duplicate明细表 | 下拉,必选枚举值:Duplicate明细表、Unique唯一表实时仅支持唯一表 |
| 表名设置 | 无 | 无前后缀、增加前后缀、增加前缀、增加后缀 |
| 副本数 | 3 | 默认副本数为3。如果 BE 节点数量小于3,则需指定副本数小于等于 BE 节点数量。 |
| 后缀 | 无 | 输入后缀值 |
写入设置
EDAP类型
表类型、存储方式等均在上一步做了批量设置,此步可在左侧目录树中指定表,进行建表方式、表达式、分区等个性化设置,接下来展开说明:
-
EDAP支持“自动建表”和“选择已有表”两种方式。
当【建表方式】选择“自动建表”时,数据集成会在目标端自动创建对应表,字段名称和类型默认与数据源端一致,页面中的“箭头”表示数据源和目的端表的字段映射关系。用户可根据需要更改目的端表名、字段名称、字段类型、默认值。
此外,用户可在目的表点击每个字段最右侧的删除符号将此字段删除,表示在数据集成过程中过滤此字段,不同步源端的此字段。然后,在右侧列表最下方可以添加普通字段或分区字段;
- EDAP表类型支持hudi表,hudi表类型默认为MOR
表六 hudi表说明
| 配置项 | 默认值 | 说明 |
|---|---|---|
| EDAP表类型 | hudi | 枚举值:hudi |
| 存储格式 | Parquet | Hudi表:Parquet |
| Hudi表类型 | MOR | hudi表枚举值:MOR、COW,默认MOR |
3.EDAP类型支持批量配置,点击批量配置按钮弹出批量设置弹窗,详见批量设置
表七 批量设置字段属性说明
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 数据湖格式 | hudi | 枚举值:hudi |
| 存储格式 | Parquet | hudi:Parquet |
| hudi表类型 | MOR | hudi表枚举值:MOR、COW,默认MOR |
| hudi表主键 | EDAP_UUID | 字段名允许修改,提示说明:若不指定目标端主键,Hudi表默认生成EDAP_UUID字段作为表主键,字段值为随机UUID字符串 |
4.当建表方式设置为【选择现有表】时,需要指定目标表名称。您可以使用“同名映射”或“同行映射”来批量确定数据源端和目的端表的字段映射方式。
此外,还可以在可视化界面中绘制手动连接以自定义字段映射。
5.打开表达式设置时,
表八 目前支持的transform函数列表
| 类别 | 中文名称 | 英文名称及参数 | 返回值 | 详细功能描述 |
|---|---|---|---|---|
| 数学函数 | 绝对值 | abs() | T | T是数值类型,包括int、long、float、double、decimal |
| 字符串函数 | 连接字符串 | concat(String str1, String str2) | String | 连接str1和str2两个字符串 |
| 去掉字符串前后的空格 | trim() | 去掉操作字符串前后的空格 | ||
| 翻转字符串 | reverse() | 翻转操作字符串 | ||
| 返回大写字符 | toupper() | 返回操作字符串的大写形式 | ||
| 返回小写字符 | tolower() | 返回操作字符串的小写形式 | ||
| 字符串替换 | replace(String old, String new) | 搜索操作字符串中的old子串,如果能够找到则使用new子串来替换 | ||
| 功能函数 | 条件过滤 | filter(String operator, String criteria) | boolean | operator是支持的运算符,criteria是过滤值,其支持的运算符如表2所示 |
表九 条件过滤的支持运算符类型关系如下
| 序号 | 操作符 | boolean | int | long | float | double | bytes | string | date | decimal | timestamp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | = | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| 2 | != | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| 3 | != | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| 4 | > | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
| 5 | >= | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
| 6 | < | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
| 7 | <= | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ||
| 8 | contains | ✔️ | |||||||||
| 9 | notContain | ✔️ | |||||||||
| 10 | startsWith | ✔️ | |||||||||
| 11 | endsWith | ✔️ | |||||||||
| 12 | notStartWith | ✔️ | |||||||||
| 13 | notEndWith | ✔️ | |||||||||
| 14 | matchesRegex | ✔️ | |||||||||
| 15 | notMatchRegex | ✔️ |
Doris类型
选择数据集成目的端的类型为Doris时,相关配置操作大部分与EDAP的配置操作类似,本小节重点说明Doris类型相关配置操作的不同之处,其他操作可参考上小节。
1.【数据源变化设置】中,以Doris为目的端的配置只支持“数据源删除正在同步的表”设置和“同步的表字段被删除”设置,不支持“同步的表发现新增字段”设置;
2.【写入设置】中,建表方式支持自动建表/选择已有表。自动建表情况下,表的类型支持2种:Duplicate明细表和Unique唯一表。
前置检查
完成任务配置后,转到实时任务创建列表并选择【前置检查】。单击开始检查以验证任务配置是否可以正常运行。
检查结果:
- 通过:如果检查通过,则任务可以正常运行。
- 失败:如果检查失败,检查内容会列出具体的错误原因。您需要根据这些错误修改任务配置并再次执行检查,直至成功通过。
任务运维
任务操作
任务运维列表显示任务名称、类型、来源和目标等详细信息。您可以运行、暂停或删除任务。点击运行,任务即开始运行,一次性任务在一次运行后结束;而定时任务则继续,刚创建的任务处于“已发布”状态,可以根据用户需求更改为“正在运行”或“暂停”状态。如果任务失败,则任务状态显示“失败”;如果运行成功,任务状态为“成功”。
任务概况
点击任务名称,可具体查看任务概况。概况内容包括任务的具体详细信息,且在监控界面右上角的【编辑】可编辑作业配置。
注:更新作业配置时任务的状态需要提前“暂停”,失败或者正在运行等状态的任务无法编辑。
表十 任务概况说明
| 任务概况内容 | 说明 |
|---|---|
| 概览 | 概览可看见任务目前正在执行情况,包含读写数据量等,并且可以单独重试失败的单表任务和查看操作日志。 |
| 集成基本信息 | 在“集成基本信息”部分,您可以详细的查看创建任务时设置的基本信息。包括源端设置、目标端设置、任务配置等。 |
| 读取设置和写入设置 | 单击读取设置或写入设置,然后从左侧选择库或表,即可查看任务创建过程中设置的过滤器配置。 |
评价此篇文章