
数据血缘
数据血缘概述
功能介绍
EDAP数据血缘,监控元数据和相关任务变化状态,进行血缘解析,提供数据在生产流转过程中的血缘关系。旨在帮助您分析元数据的上下游关联关系,定位影响层级和任务依赖关系,可快速发现和回溯对其他元数据对象的影响。
本功能支持通过可视化图表查看数据血缘图谱,支持的数据源类型包括EDAP、Postgresql、Oracle、Hana、Doris、SQLServer、Greenplum、TiDB、MySQL、Hive、ClickHouse。您可以切换表视图、字段视图,灵活选择上下游层级,其中表视图是查看表的上下游血缘图,字段视图可查看表中的字段的上下游血缘图,支持查看节点详情和产生指定血缘关系链路的任务详情。EDAP平台提供了多种作业类型的血缘关系自动解析服务,针对部分无法解析的使用场景,可以通过手动填报入口进行血缘关系的填报。
名词解释
数据血缘
数据血缘是元数据管理、数据治理、数据质量的重要一环,追踪数据的来源、处理、出处,对数据价值评估提供依据,描述源数据流程、表之间的流向关系,表与表的依赖关系、表与平台作业,计算引擎之间的依赖关系。
活跃血缘
血缘图谱当前仅展示活跃状态的血缘。活跃血缘指的是已上线作业产出的血缘,且作业执行时间间隔在35d内。已上线作业包括作业组调度、单节点调度、离线同步作业调度。
静默血缘
血缘图谱当前不展示活跃状态的血缘。静默血缘指的是未来可能不会更新或即将失效的血缘,包括开发模式运行、线上调度已运行过但是已取消调度超过35d、线上模式逾期35d执行。
应用场景
场景一:帮助用户快速找到想要的数据,并且了解数据表的详情和上下游血缘关系。
场景二:帮助开发人员高效地定位问题,在问题排查时能评估故障影响范围。
- 归因分析(上游):采用向上追溯的方式查找数据来源于哪里,经过了哪些加工和处理。常用于在发现数据问题时,追溯上游表、字段,快速定位和找到数据问题的原因。
- 影响分析(下游):影响分析是向下游追踪,用来查询和定位数据去了哪里。常用于当元数据发生变更时,分析和评估变更对下游业务的影响。
血缘关系查询
EDAP提供两个数据血缘关系查询入口,分别为数据血缘-血缘图谱和元数据-数据血缘,用户可根据使用场景进行选择。
血缘图谱查询
操作步骤:
- 登录并进入百度智能云数据湖管理与分析EasyDAP。
- 在左侧导航栏,单击数据治理-数据血缘。
- 单击上方血缘图谱览即可进入血缘查询页面。
元数据检索
操作步骤:
- 登录并进入百度智能云数据湖管理与分析EasyDAP。
- 在左侧导航栏,单击数据治理-数据血缘,进入后,默认在血缘图谱页面。
- 选择你需要查看的表,从左侧依次选择数据源类型、数据库、表,查看该表的数据血缘。
表级血缘
在选择表后,以该表为中心,显示上下游血缘关系。
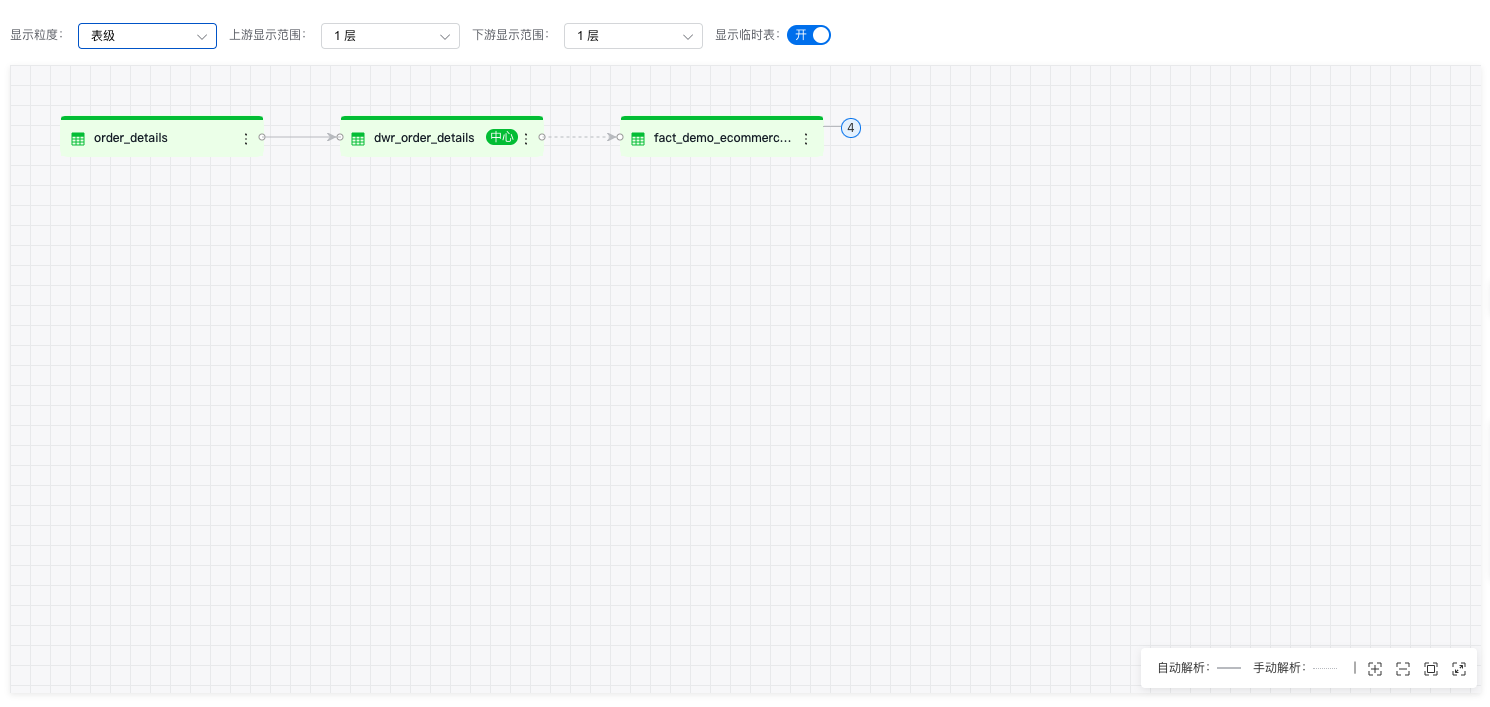
操作步骤:
- 选择显示粒度
血缘图谱支持表级、字段级两种显示粒度,默认显示表级。
- 选择显示范围
默认直系父子,即上游1层、下游1层,如果没有上游或下游,则显示0层。
支持用户自定义上下游层级,可下拉选择:0层、1层、2层、3层。
在图谱中点击节点左侧的“+”、“-”可以展开或折叠上一层级,末端节点无展开/折叠按钮。
- 查看节点信息
点击节点右侧“更多”,选择“查看节点信息“,右侧显示节点信息:表名称、数据源类型、数据源链接、数据库、更新时间、schema信息。对于数据湖的表,点击“查看表详情”,可跳转到元数据详情页面。
- 查看任务信息
点击连线上的任务节点,右侧显示产生该血缘关系的任务信息,包括:来源任务名称、任务类型、创建人、创建时间、运行时间、任务内容等。点击“查看任务详情”可以跳转到具体作业。
- 切换中心节点
双击其他节点,或点击节点右侧“更多”,选择“设为中心表”,可以进行中心节点的切换。
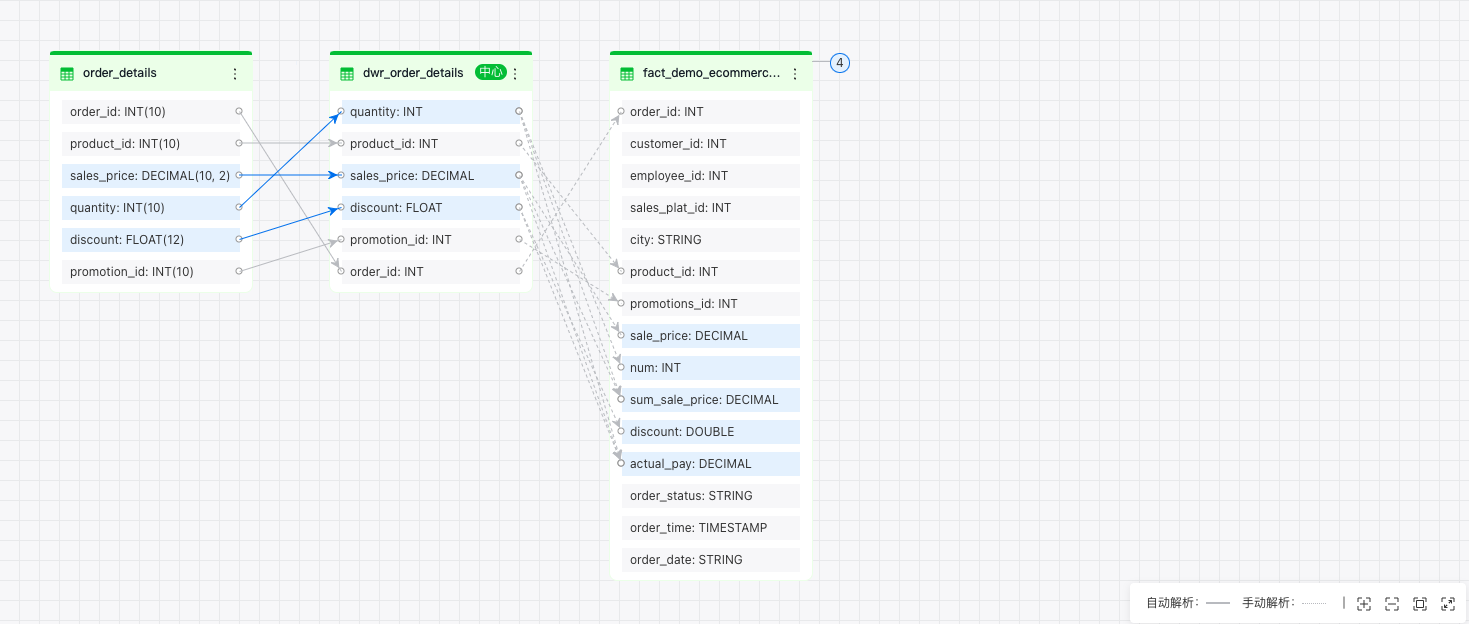
字段血缘
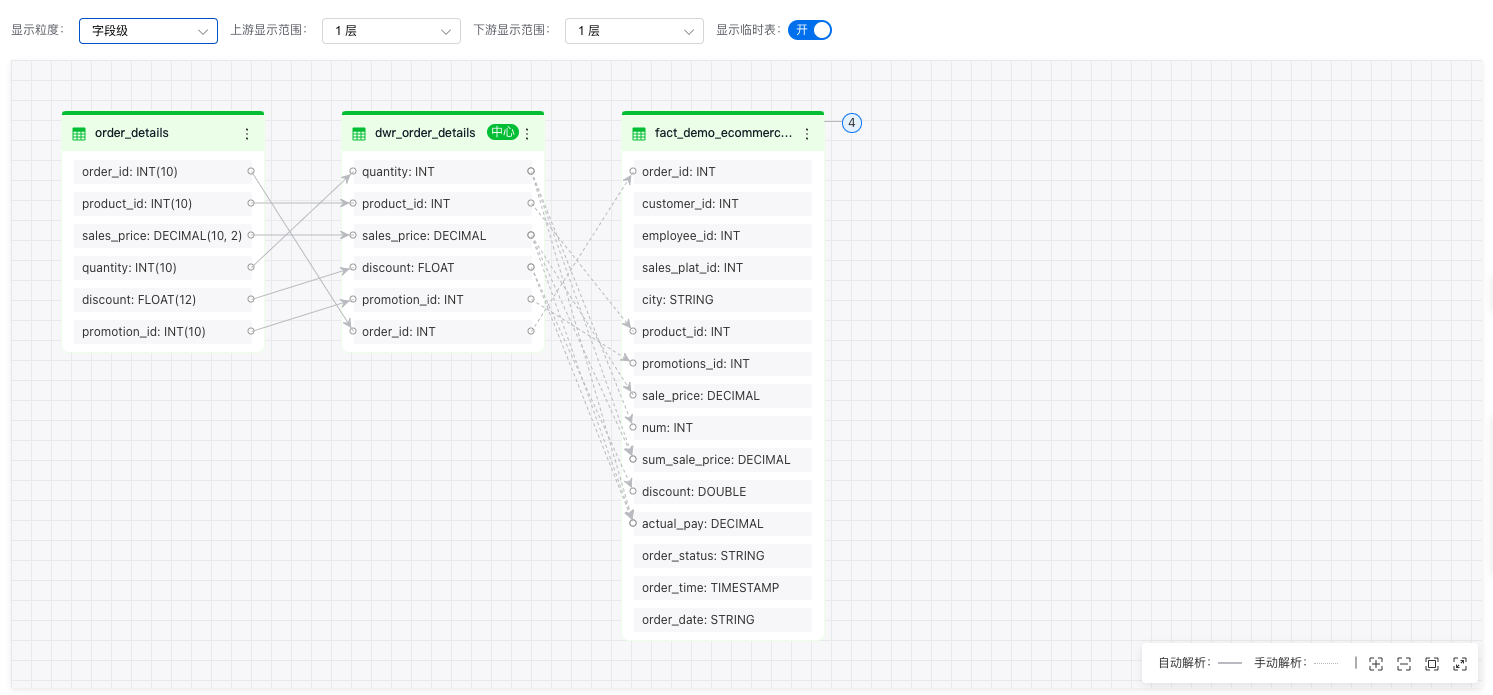
操作步骤:
- 切换显示粒度
下拉“显示粒度”选择字段级,血缘图谱会展开数据表的所有字段,并显示字段间的血缘关系连线。
- 指定字段查询
选中某一个字段,图谱上高亮显示该字段的上下游字段。
血缘关系解析
自动解析
EDAP平台支持数据集成作业、大部分脚本开发作业、特定场景可视化ETL作业的血缘关系自动解析,支持范围详情如下。
数据集成
| 源端 | 目标端 | 血缘获取方式 |
|---|---|---|
| mysql、sqlserver、oracle、hana、postgresql | hive、doris、edapdatalake | 系统解析 |
数据集成完全支持字段级血缘系统解析。
脚本作业
| 脚本作业类型 | 数据源类型 | 血缘获取方式 |
|---|---|---|
| HIVE SQL | hive、edapdatalake | 系统解析 |
| JDBC SQL | mysql、sqlserver、clickhouse、oracle、doris、hana | 系统解析 |
| Spark SQL | hive、edapdatalake | 系统解析 |
| PySpark | 手动配置 | |
| Scala | 手动配置 | |
| Shell | 手动配置 | |
| Python | 手动配置 |
SQL类脚本作业支持字段级血缘系统解析。
-
Hive SQL
- 支持Create table as等DDL操作产生的【Hive表/数据湖表】之间的血缘。
- 支持Insert into/overwrite等DML操作产生的【Hive表/数据湖表】表之间的血缘。
-
JDBC SQL
- 支持Create table as等DDL操作产生的【数据源表】之间的血缘。
- 支持Insert into等DML操作产生的【数据源表】之间的血缘。
-
Spark SQL
- 支持Create table as等DDL操作产生的【Hive表/数据湖表】之间的血缘。
- 支持Insert into/overwrite等DML操作产生的【Hive表/数据湖表】表之间的血缘。
对于程序类脚本作业,支持“手动配置”的方式,补齐血缘。
可视化ETL
| 插件类型 | 数据源类型 | 血缘获取方式 |
|---|---|---|
| Hive、Hive3 | hive | 自动解析 |
| DataLakeSource DataLakeSink |
edapdatalake | 自动解析 |
| Doris | doris | 自动解析 |
| Database | mysql、tidb、oracle、sqlserver、hana、postgresql、greenplum | 自动解析 |
| 其它 | 手动配置 |
支持的场景:数据同步,即源端插件——>目标端插件,数据处理插件、开发分析插件不支持
插件范围包括:Hive、Hive3、DataLakeSource、DataLakeSink、Doris。对于暂未支持的插件,支持“手动配置”的方式,补齐血缘。
手动填报
血缘手工填报
1、点击“数据治理——数据血缘”进入该界面,在当前界面内切换进入“血缘填报”tab页,点击“+新建血缘填报”按钮,进入新建页。
2、在“新建血缘填报”界面选择“项目名称”和“来源任务名称”,选填“描述”。选中来源任务后,可在选框下的灰色注释框内点击“查看任务详情”按钮,跳转至任务的脚本开发界面。
3、在“血缘关系填报”部分可为选中的任务新增或编辑上下游关系。所选任务内已有的填报记录会同步展现在此处,若对其重新编辑并点击确认,则新的填报内容将会覆盖。
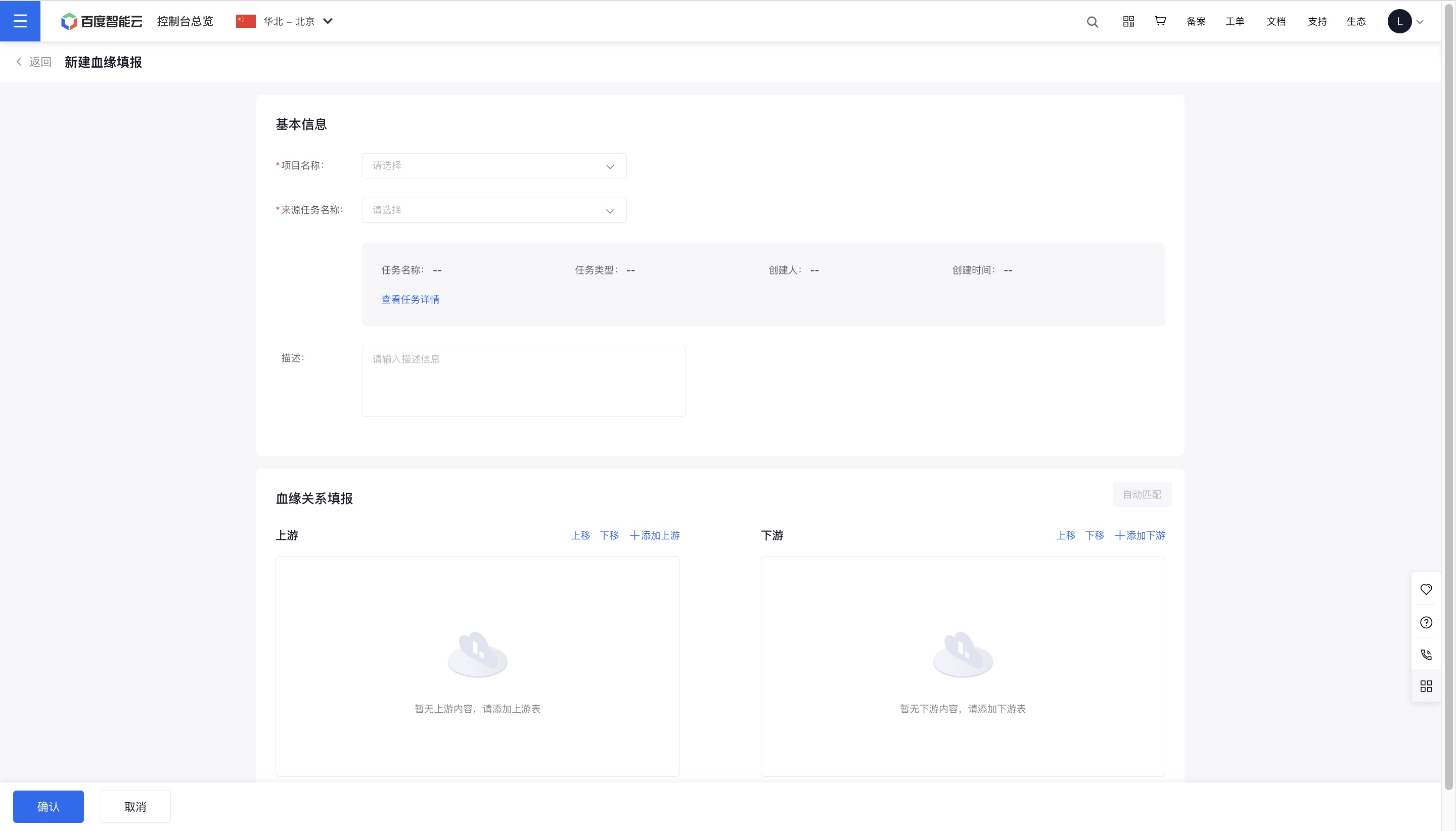
4、点击“血缘关系填报”部分的蓝字按钮可对其进行相应操作。点击“+添加上游”,打开添加弹窗页,选择“数据库类型”、“数据源连接”、“数据库”和“数据表”,选择完成后点击确认按钮。添加下游操作同理。
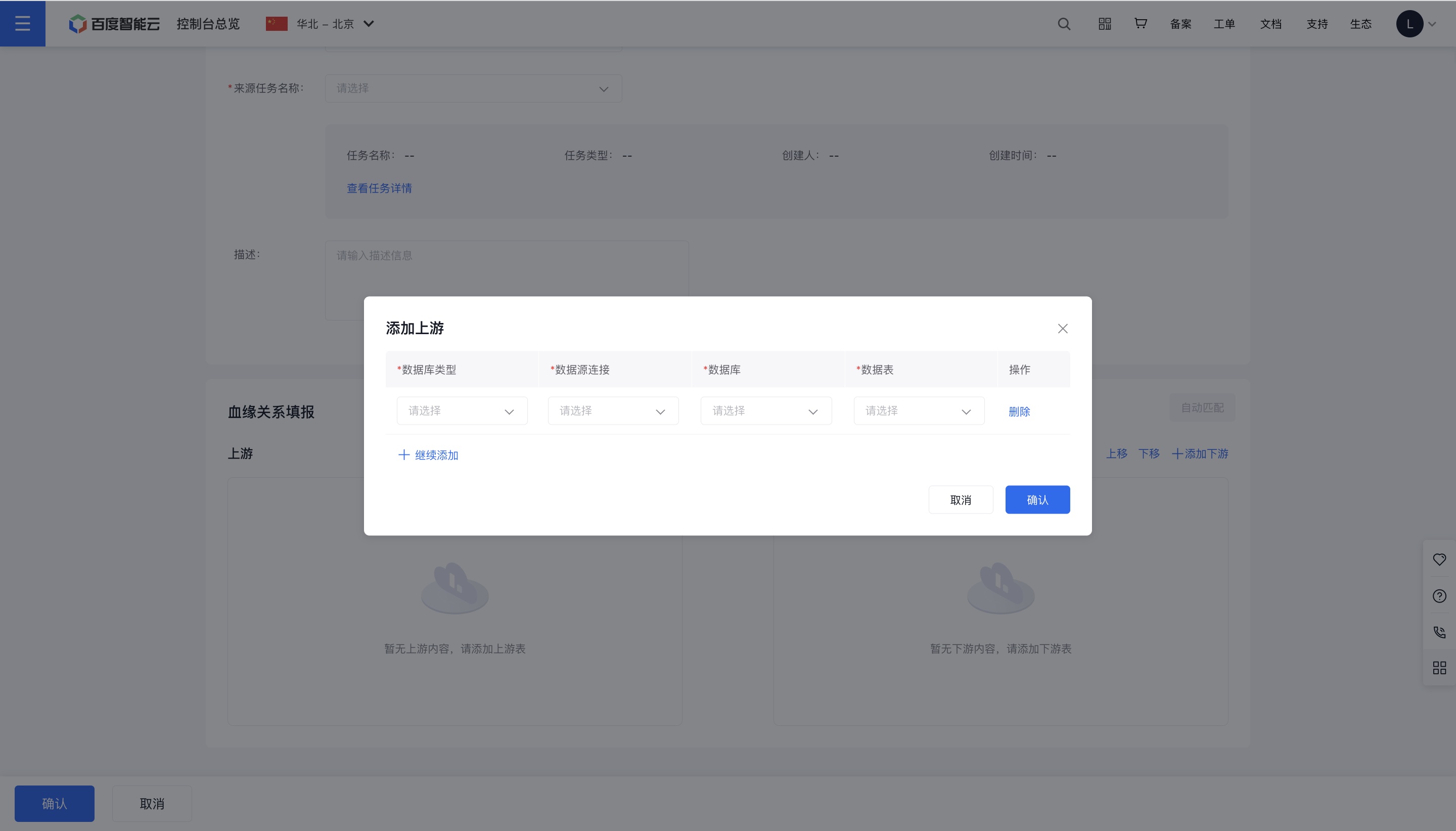
5、在上游表和下游表之间,可以分别在其末端和首端手动拖拽箭头进行血缘关系的连线;也可点击“自动匹配”按钮,快速连接上下游同名字段。若想清除某条线的连接,点击箭头并拖拽离开下游表单首端即可。
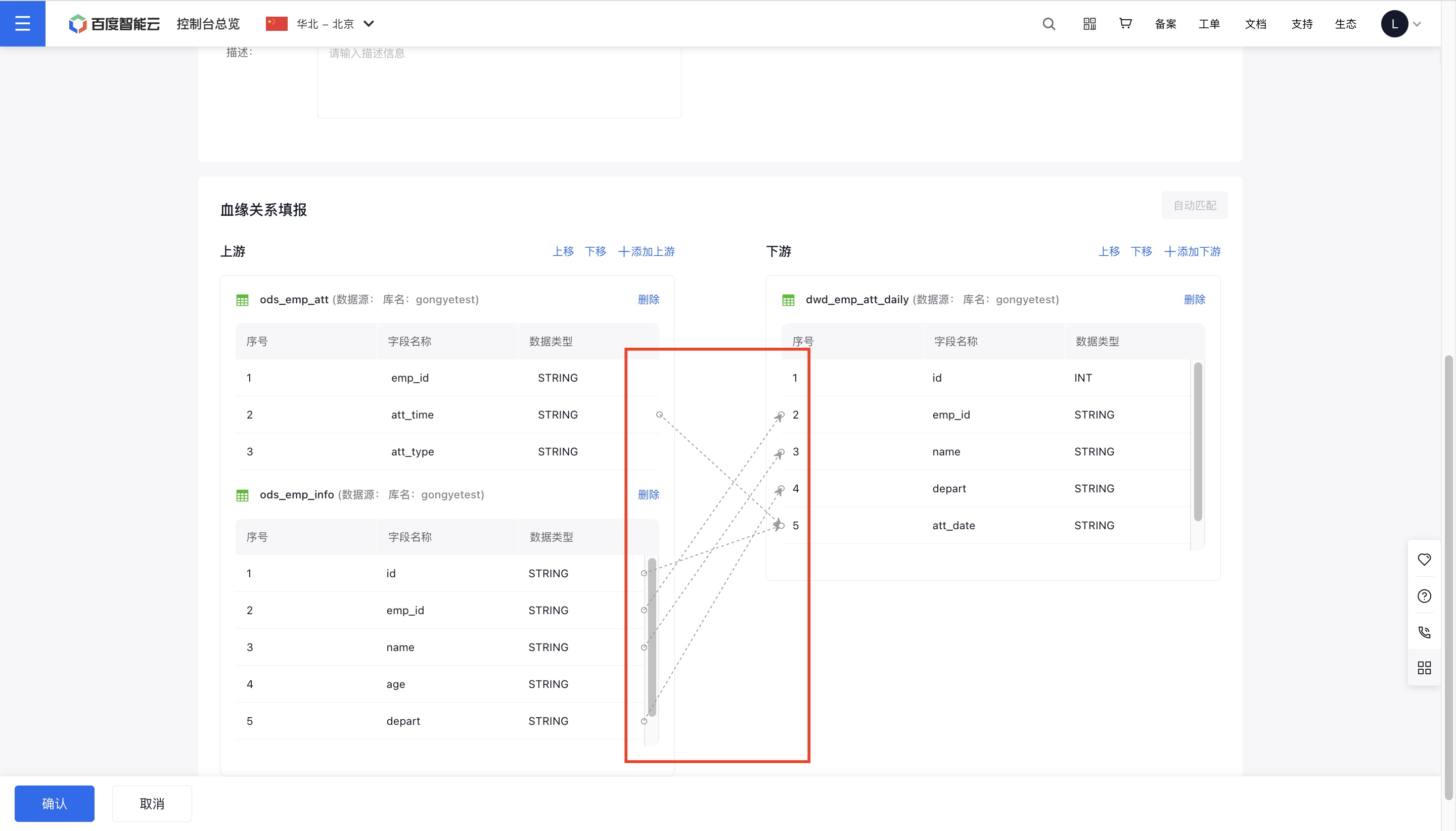
6、完成后点击页面下方“确认”按钮,完成手工填报操作。
查看项目内血缘关系
1、在左侧导航栏,单击“数据加工-我的项目”,进入后再点击“离线开发-可视化作业开发”或“离线开发-脚本作业开发”。
2、选中一个任务后,单击右侧“基本信息”,可查看该作业是否产生元数据血缘。
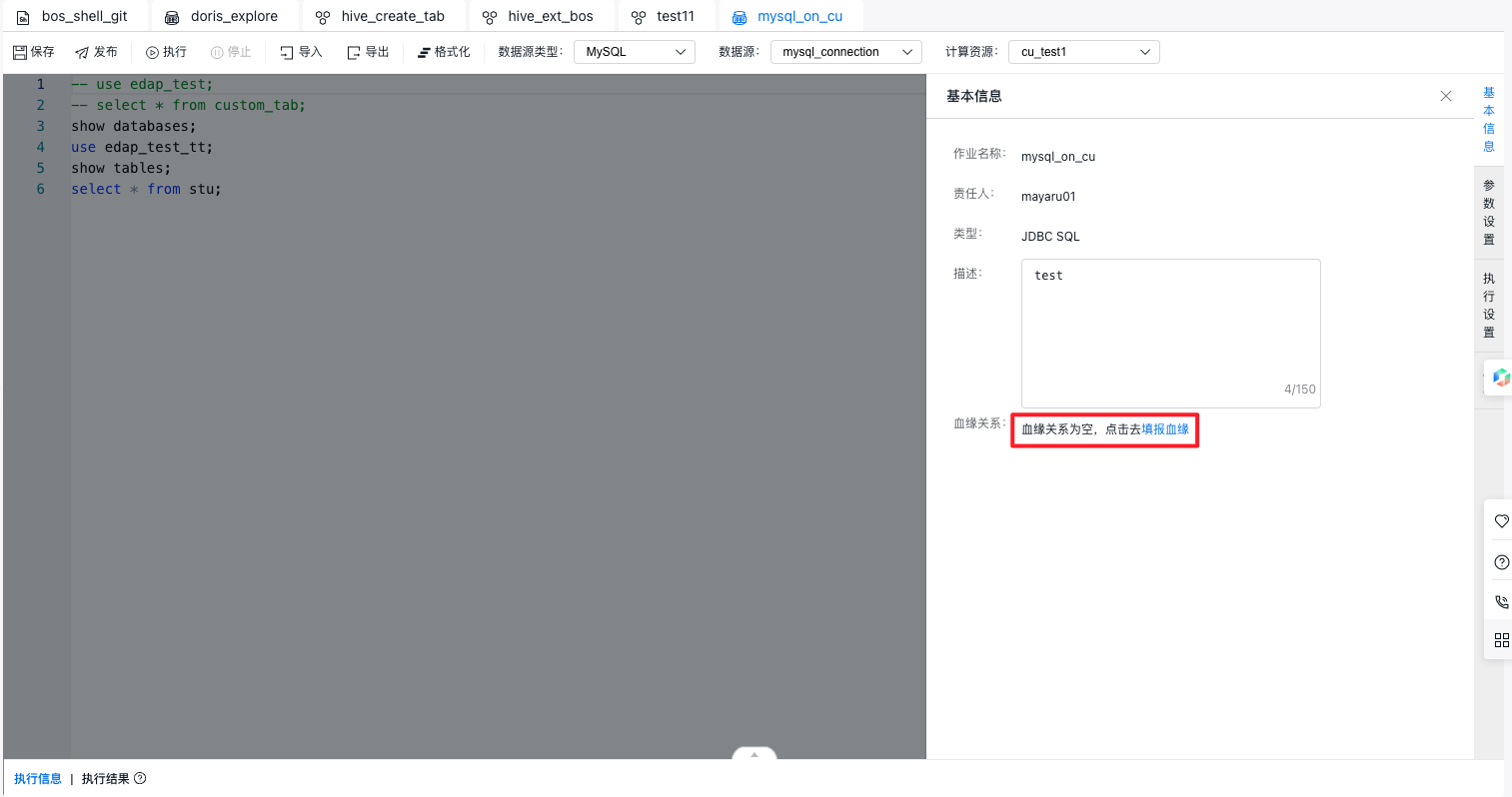
任务基本信息下方显示:
- 该任务支持/暂不支持血缘关系自动解析。
- 存在血缘关系手动填报记录,点击“查看”蓝字按钮,点击后在新页面打开“血缘填报详情”页面。
- 暂无血缘关系手动填报记录,点击“新建”蓝字按钮,点击后在新页面打开“血缘填报新建”页面,自动填充项目、任务名称。
评价此篇文章