
EDAP Spark作业运行TPC-DS Benchmark
在【我的项目】中新建项目,用于后续在其中开发Spark作业。
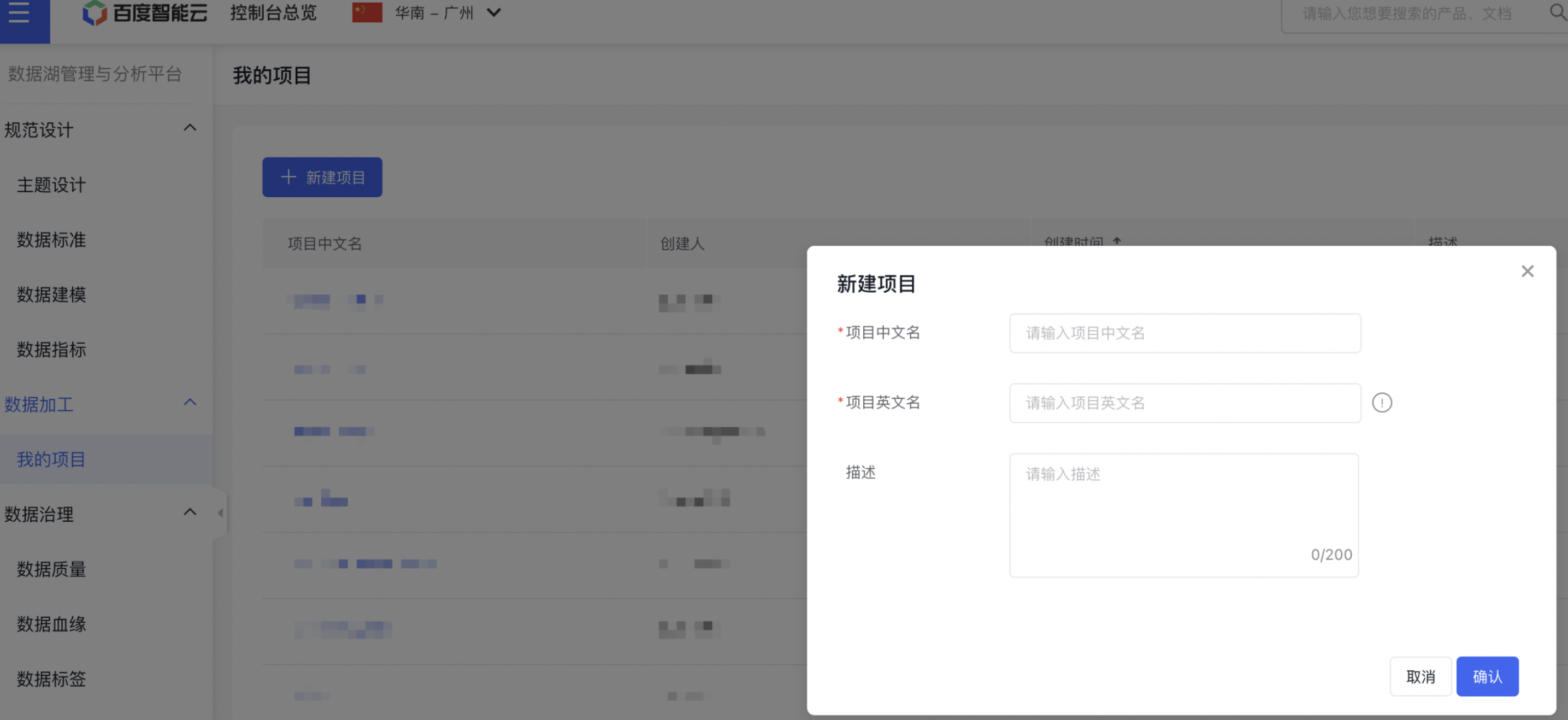
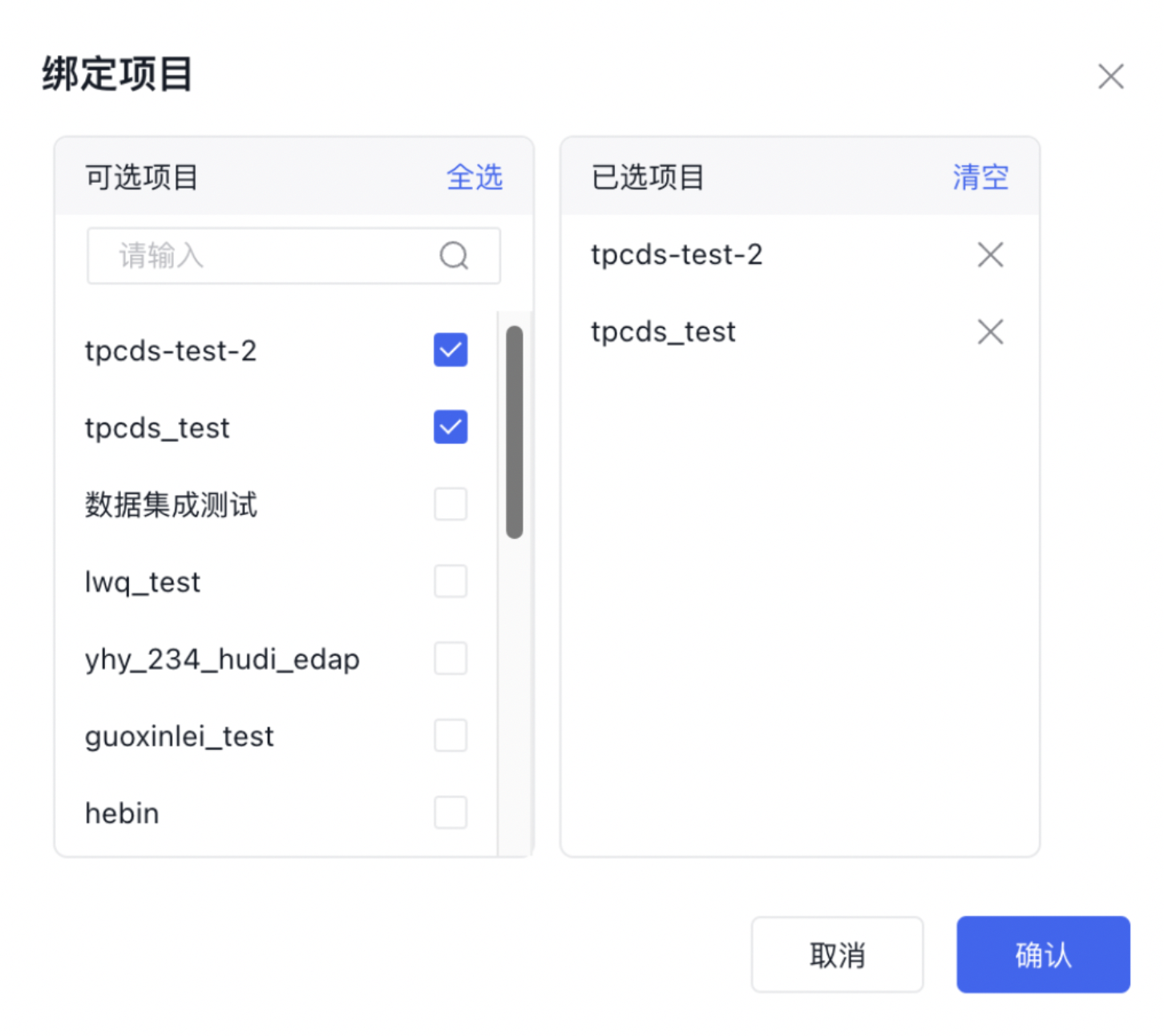
在BMR控制台创建BMR集群后,在EDAP界面【资源管理】中添加资源,选择【BMR实例】、选择刚刚创建的BMR集群,用于后续作业中使用该【BMR实例】向其对应的BMR集群提交作业。然后在【绑定项目】中绑定刚刚新建的项目,使得新建项目中的作业有权限使用该【BMR实例】。
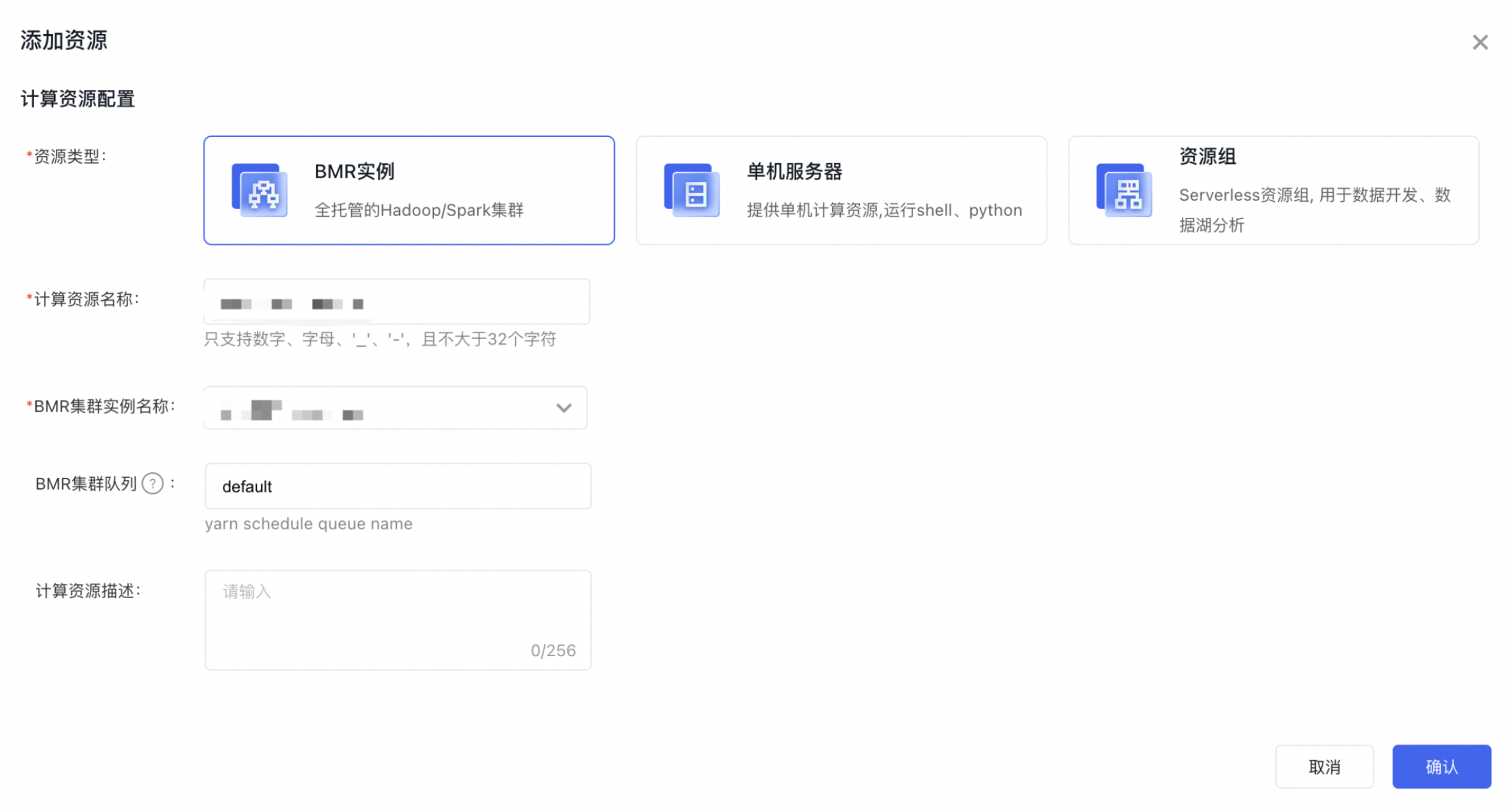
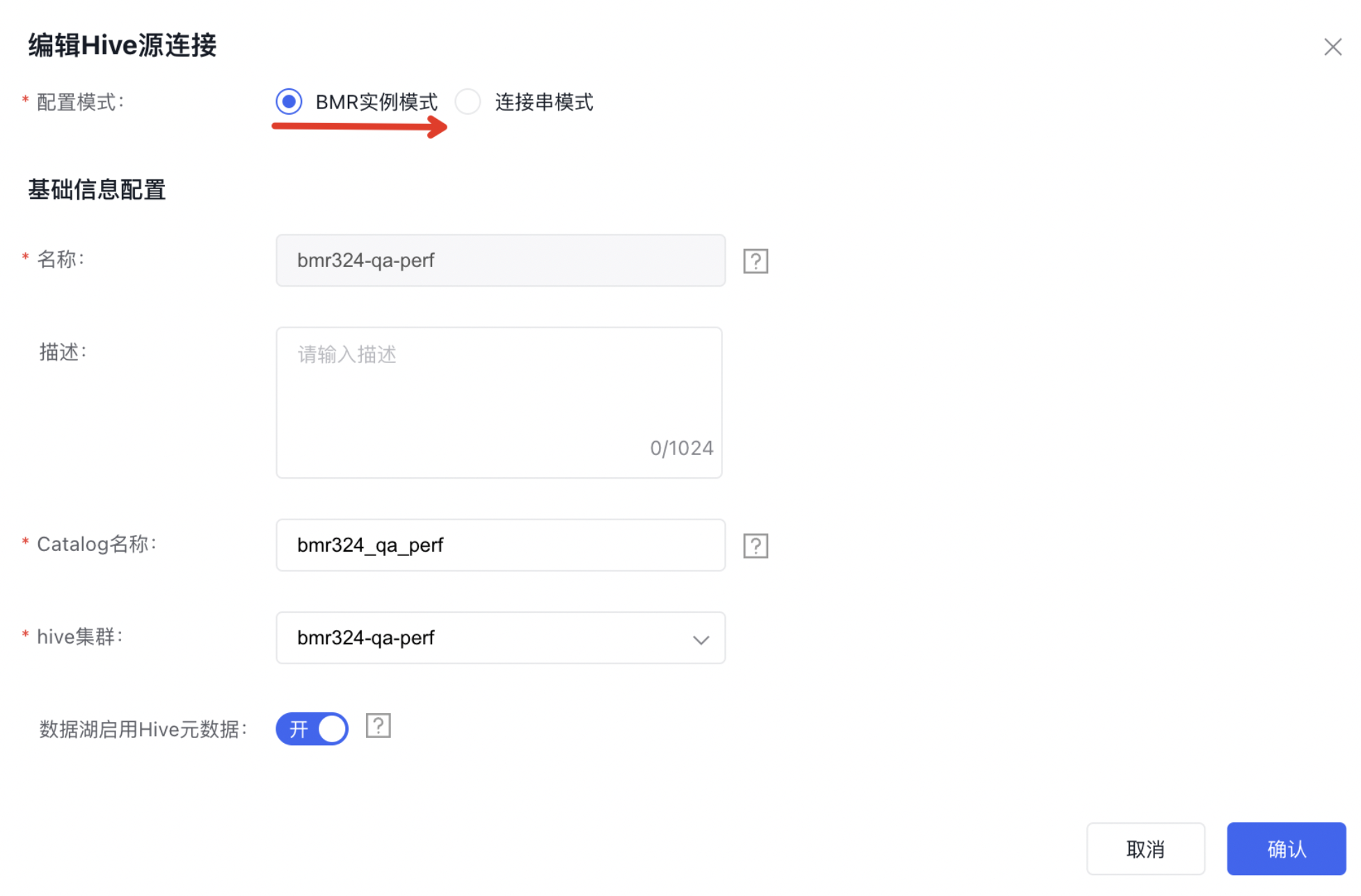
在【数据源管理】中创建Hive类型的数据源,数据源【配置模式】选择【BMR实例模式】、hive集群选择刚刚创建的【BMR实例】资源,使得后续Spark作业可以使用该源连接与其对应的BMR集群交互。
在【脚本作业开发】中导入Spark TPCDS测试所用的SparkJar、SparkScala、Shell作业。
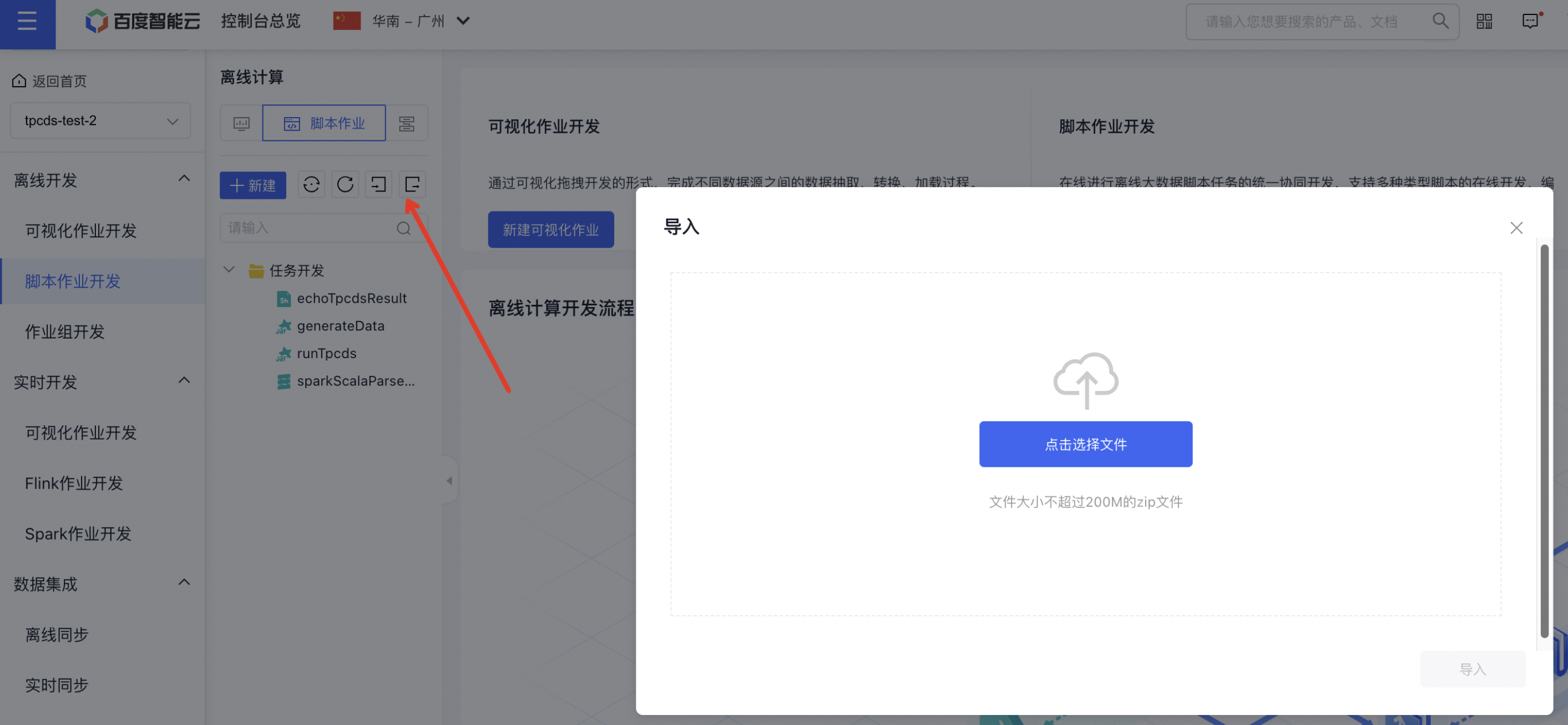
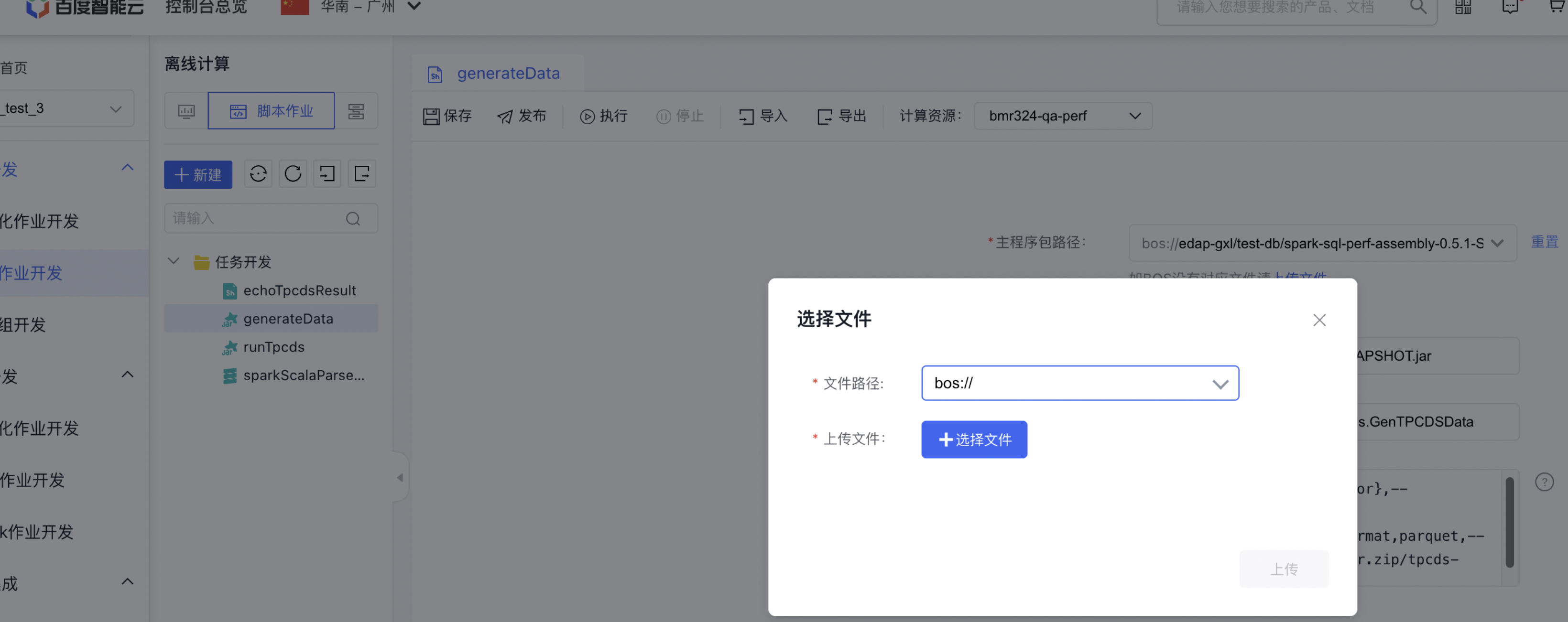
在generateData作业【主程序包路径】中上传文件https://poc-resources.bj.bcebos.com/spark-sql-perf-assembly-0.5.1-SNAPSHOT.jar 至bos bucket,使得【主程序包路径】为刚刚上传文件的bos路径,runTpcds作业中修改【主程序包路径】为刚刚上传文件的bos路径。然后将各个作业点击【发布】,使得可以在【作业组】中引用刚刚发布的作业。
然后在【作业组开发】中导入该作业组。修改各个节点引用刚刚发布的作业的最新版本,并修改各个节点使用的【计算资源】为刚刚创建的【BMR实例】。
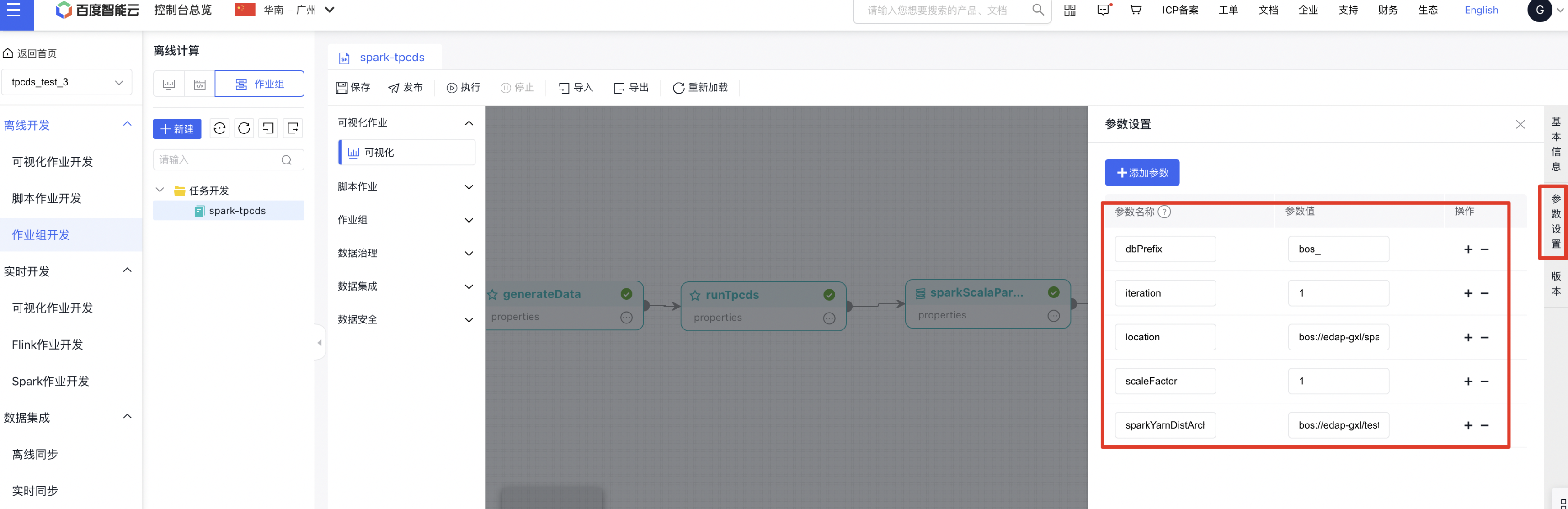
在bos控制台上传文件https://poc-resources.bj.bcebos.com/tpcds-kit-master.zip ,将该文件bos路径填入作业组【参数设置】的sparkYarnDistArchives参数的值中。
"sparkYarnDistArchives"为生成数据需要使用的TPC-DS kit编译产出文件路径。
"dbPrefix"为生成数据后在BMR集群Hive中创建的database name前缀。
"location"为生成数据存储的路径。
"scaleFactor"为生成数据的规模,1相当于1 GB,100相当于100 GB。
"iteration"为一次运行TPCDS测试的语句执行轮数。
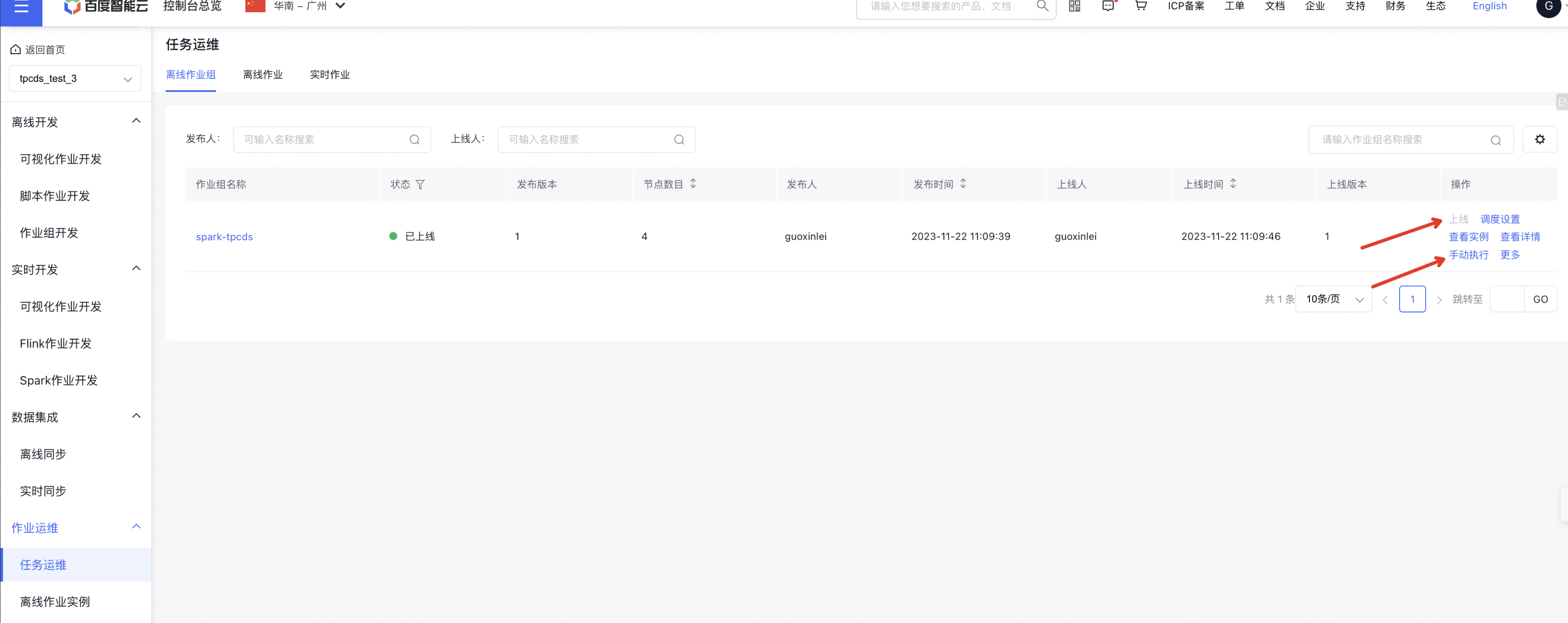
然后发布该作业组,在【任务运维】中上线、手动执行该作业组,即可启动TPCDS生成数据、运行测试、解析结果、展示结果的流程。
评价此篇文章