
EDAP资源组SparkSQL作业读取BOS写入RDS
更新时间:2024-08-28
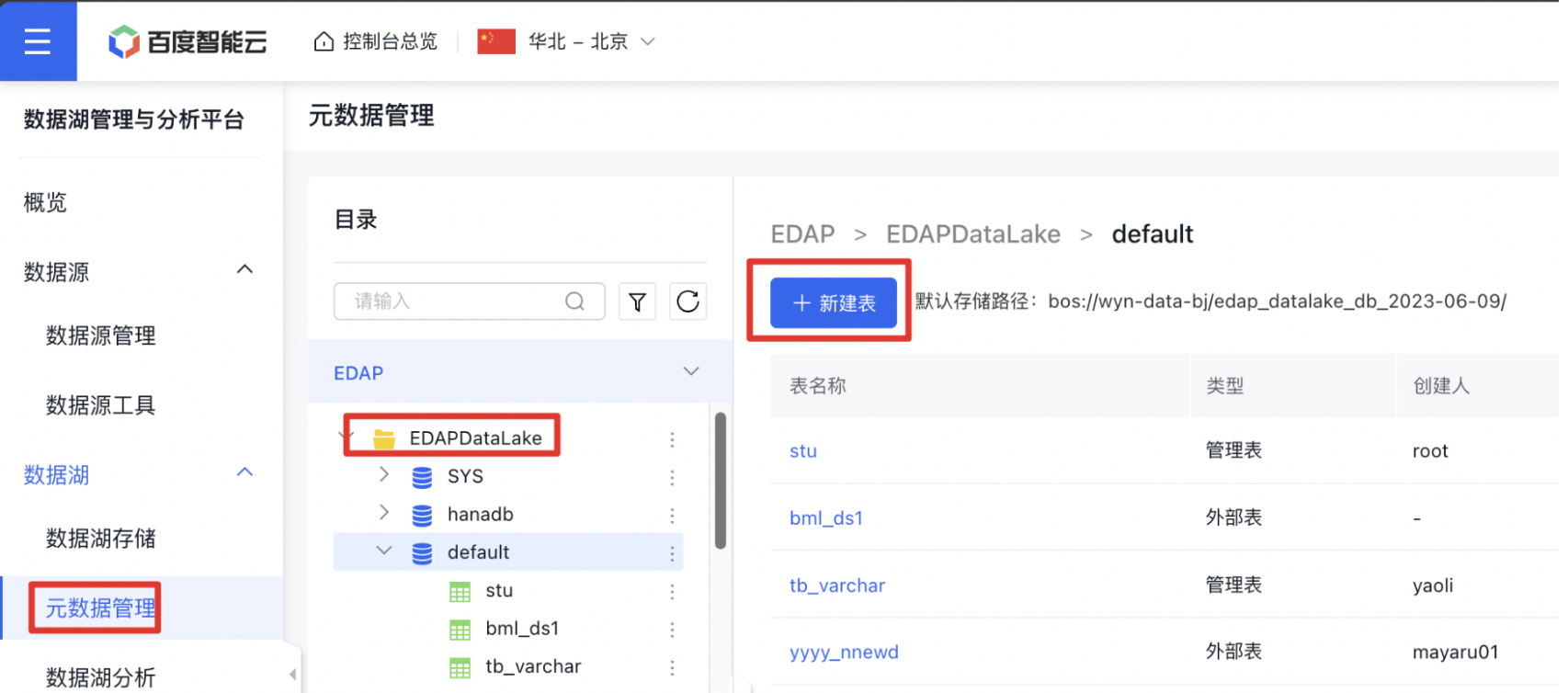
首先,在【元数据管理】中选择【EDAPDataLake】中的某个database新建表。
 假设BOS文件内容如下,每行为一个json字符串,每行之间以换行符分隔。
假设BOS文件内容如下,每行为一个json字符串,每行之间以换行符分隔。
Plain Text
1{"key1":"value1","key2":"value2","properties":{"temperature":15}}
2{"key1":"value1+","key2":"value2+","properties":{"temperature":18}}
3{"key1":"value1++","key2":"value2++","properties":{"temperature":27}}表类型选择【物理表】【外部表】,存储路径指定为BOS路径。
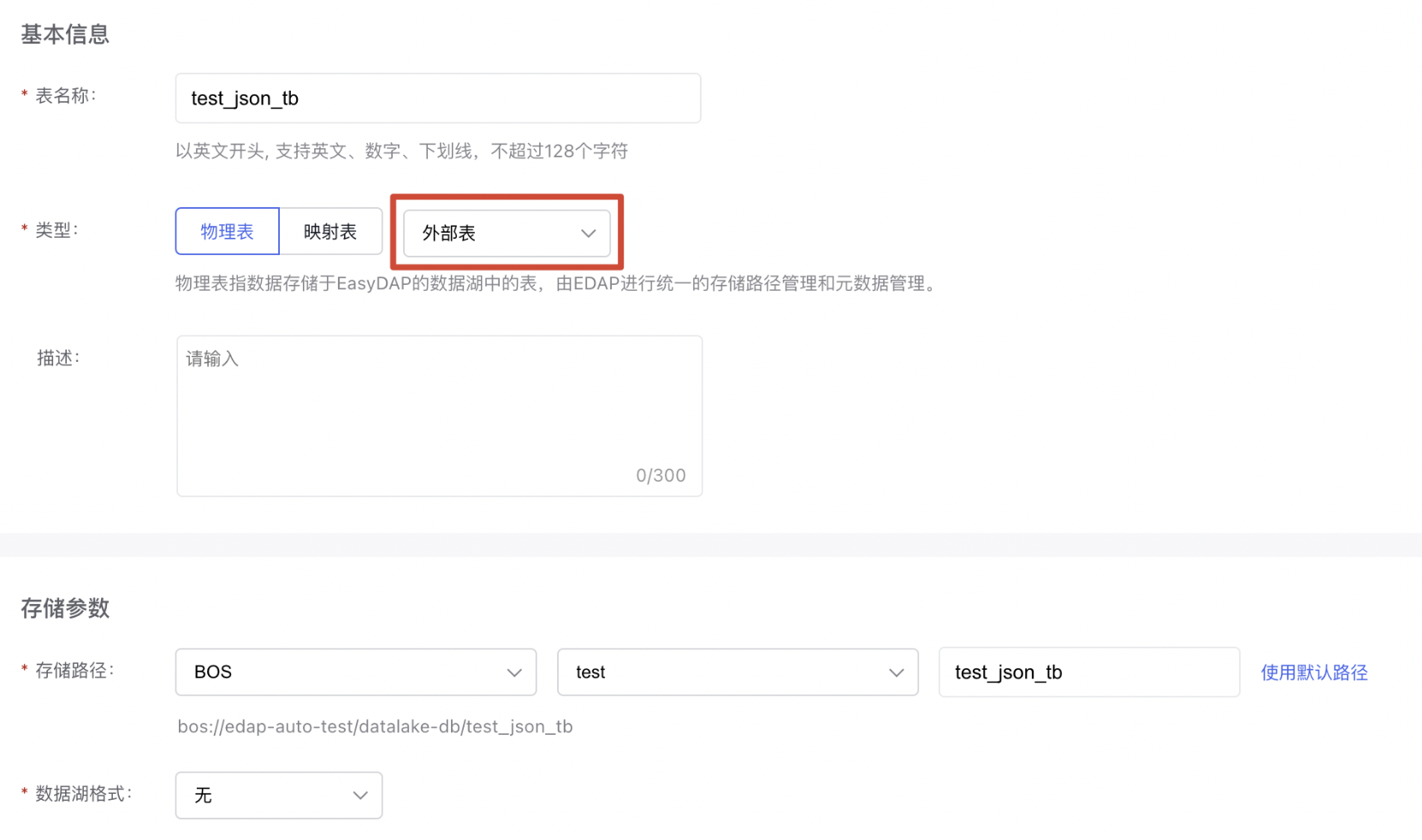 【数据存储格式】选择【TEXTFILE】,【分隔符】输入"\n",添加value字段,date分区。
【数据存储格式】选择【TEXTFILE】,【分隔符】输入"\n",添加value字段,date分区。
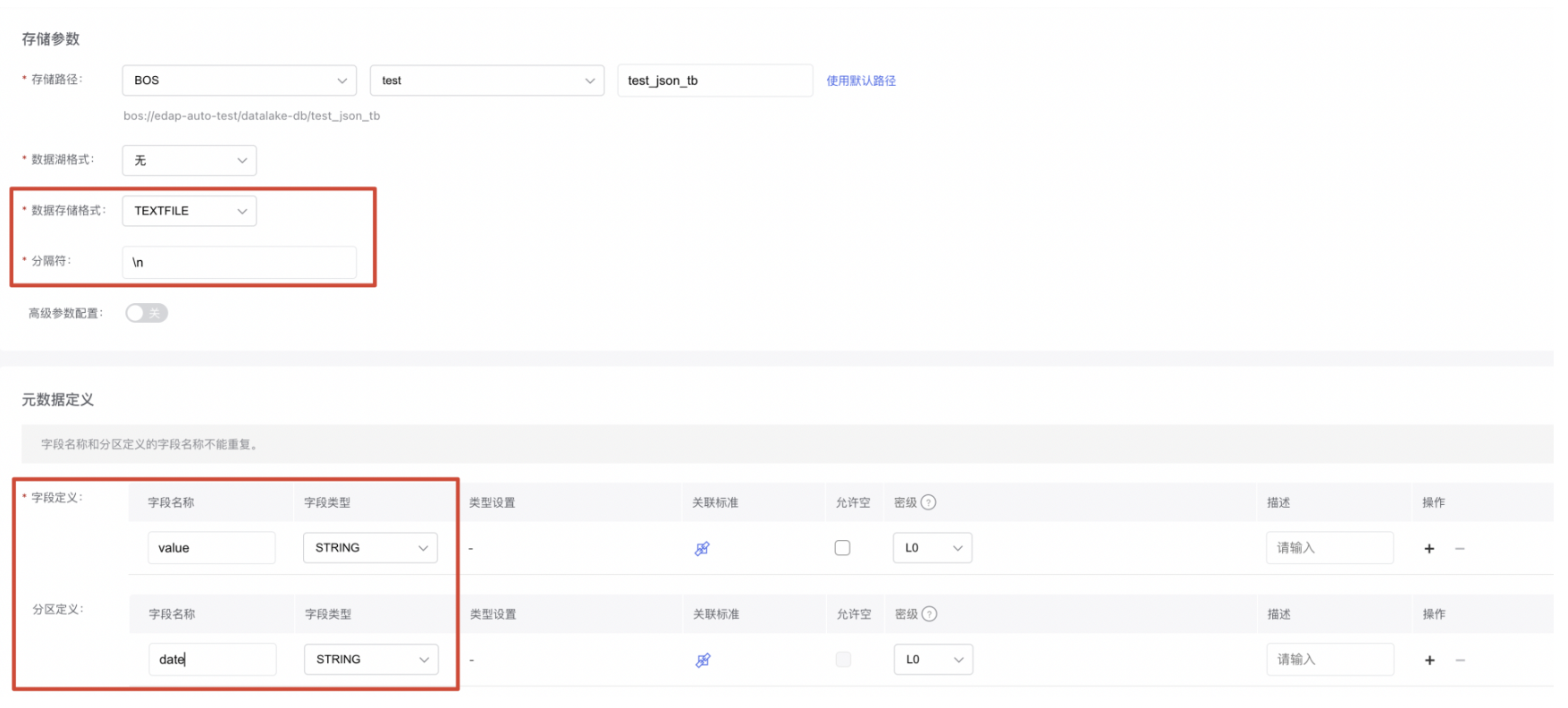 注意:要保证表bos路径下的子目录以"date="为前缀,即刚刚创建表时指定的分区字段名称。
注意:要保证表bos路径下的子目录以"date="为前缀,即刚刚创建表时指定的分区字段名称。
 同时,新建test_dwd中间表用于存储从原始json字符串中提取的字段。
同时,新建test_dwd中间表用于存储从原始json字符串中提取的字段。
 接下来需要在【我的项目】界面创建项目,【资源管理】界面创建资源组,并用该资源组绑定刚刚创建的项目。
接下来需要在【我的项目】界面创建项目,【资源管理】界面创建资源组,并用该资源组绑定刚刚创建的项目。
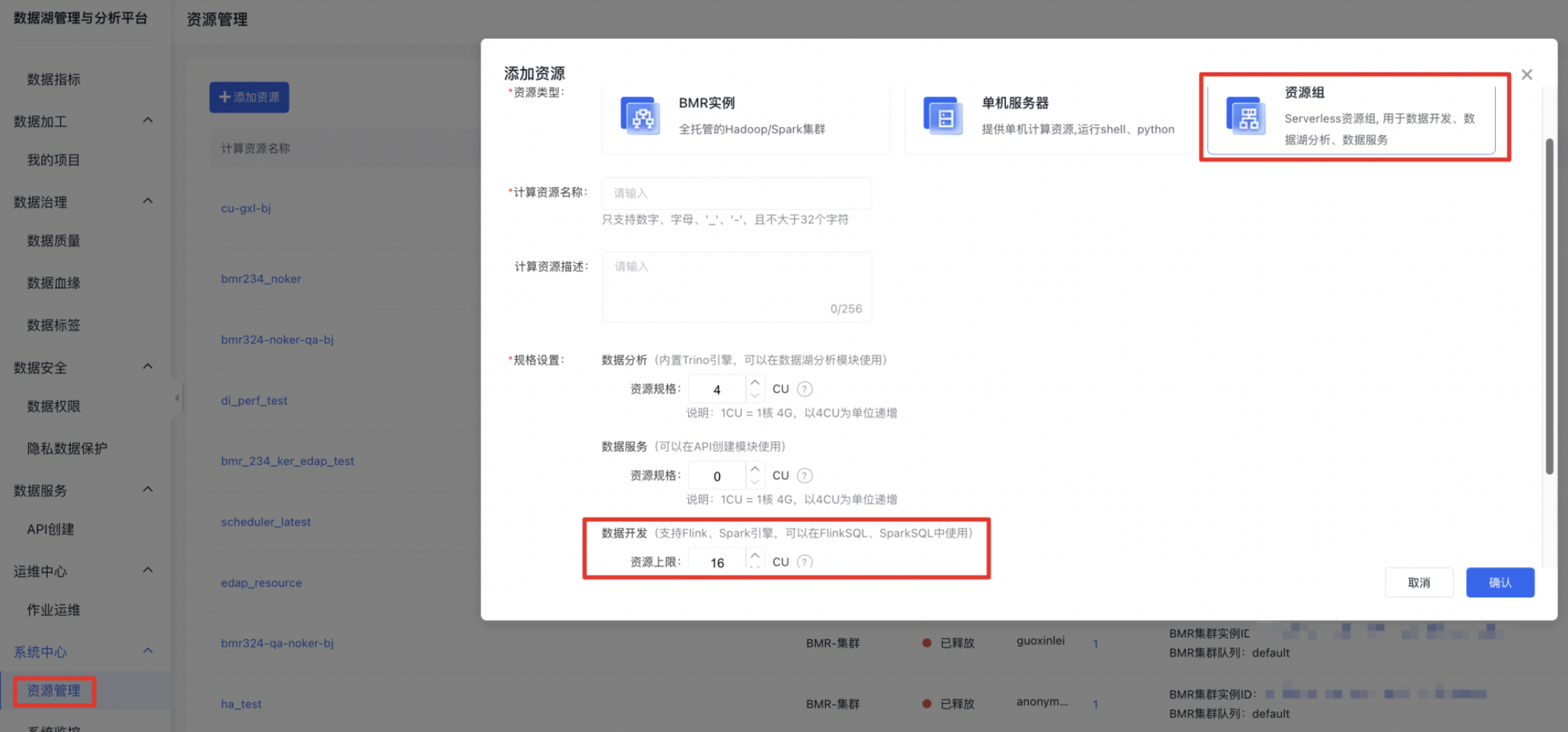 需要保证RDS服务与资源组属于相同VPC,且资源组与RDS服务的安全组配置允许资源组访问RDS服务,资源组的VPC、安全组配置如下图。
需要保证RDS服务与资源组属于相同VPC,且资源组与RDS服务的安全组配置允许资源组访问RDS服务,资源组的VPC、安全组配置如下图。
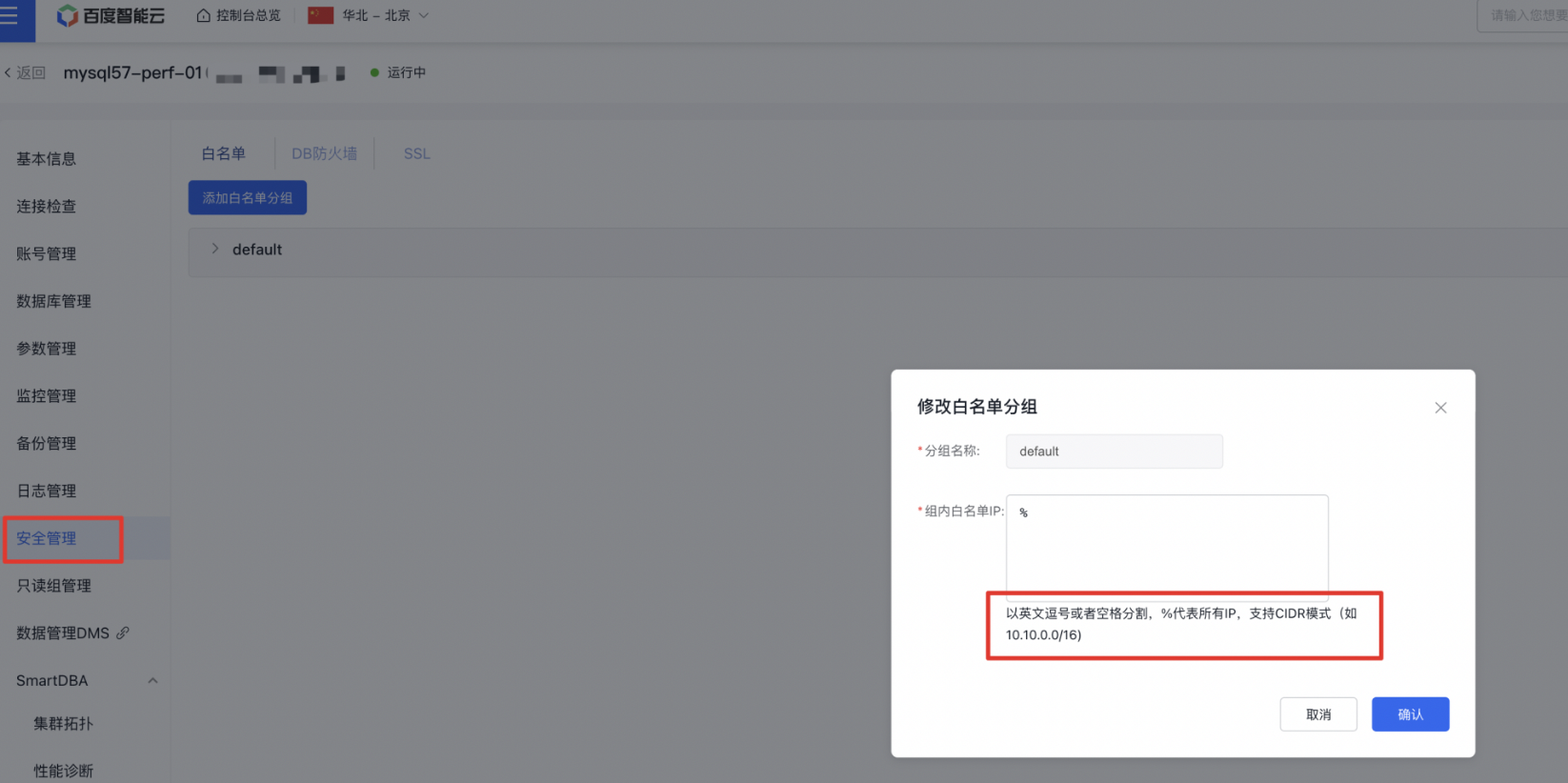
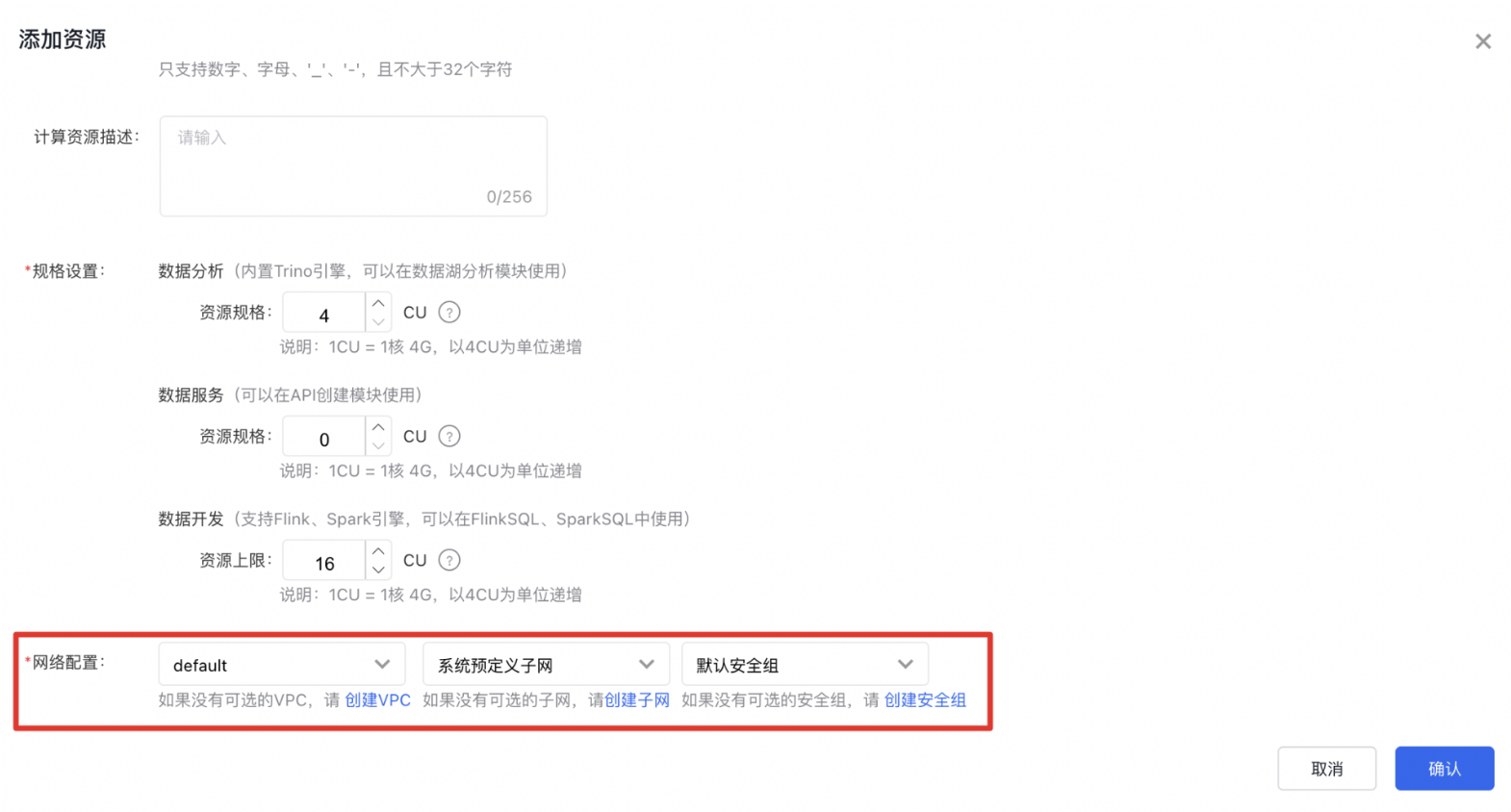 RDS服务【安全管理】的【白名单】配置如下图。
RDS服务【安全管理】的【白名单】配置如下图。
 从【我的项目】界面进入刚刚创建的项目,在【脚本作业开发】中创建SparkSQL作业,【数据源类型】选择EDAPDatalake,【计算资源】选择刚刚创建的资源组,使用如下SQL可读取BOS文件数据写入中间表。
从【我的项目】界面进入刚刚创建的项目,在【脚本作业开发】中创建SparkSQL作业,【数据源类型】选择EDAPDatalake,【计算资源】选择刚刚创建的资源组,使用如下SQL可读取BOS文件数据写入中间表。
Plain Text
1-- 在分布式存储中直接添加新分区目录时,表的元数据存储不会自动感知到这些新分区,此时需要运行 MSCK REPAIR TABLE 命令来同步元数据存储
2MSCK REPAIR TABLE test_json_tb;
3INSERT OVERWRITE TABLE test_dwd PARTITION(date='20240402')
4SELECT
5 get_json_object(value, "$.key1") AS key1,
6 get_json_object(value, "$.key2") AS key2,
7 cast(get_json_object(value, "$.properties.temperature") AS int) AS temperature
8FROM test_json_tb
9where date='20240402';
10select * from test_dwd;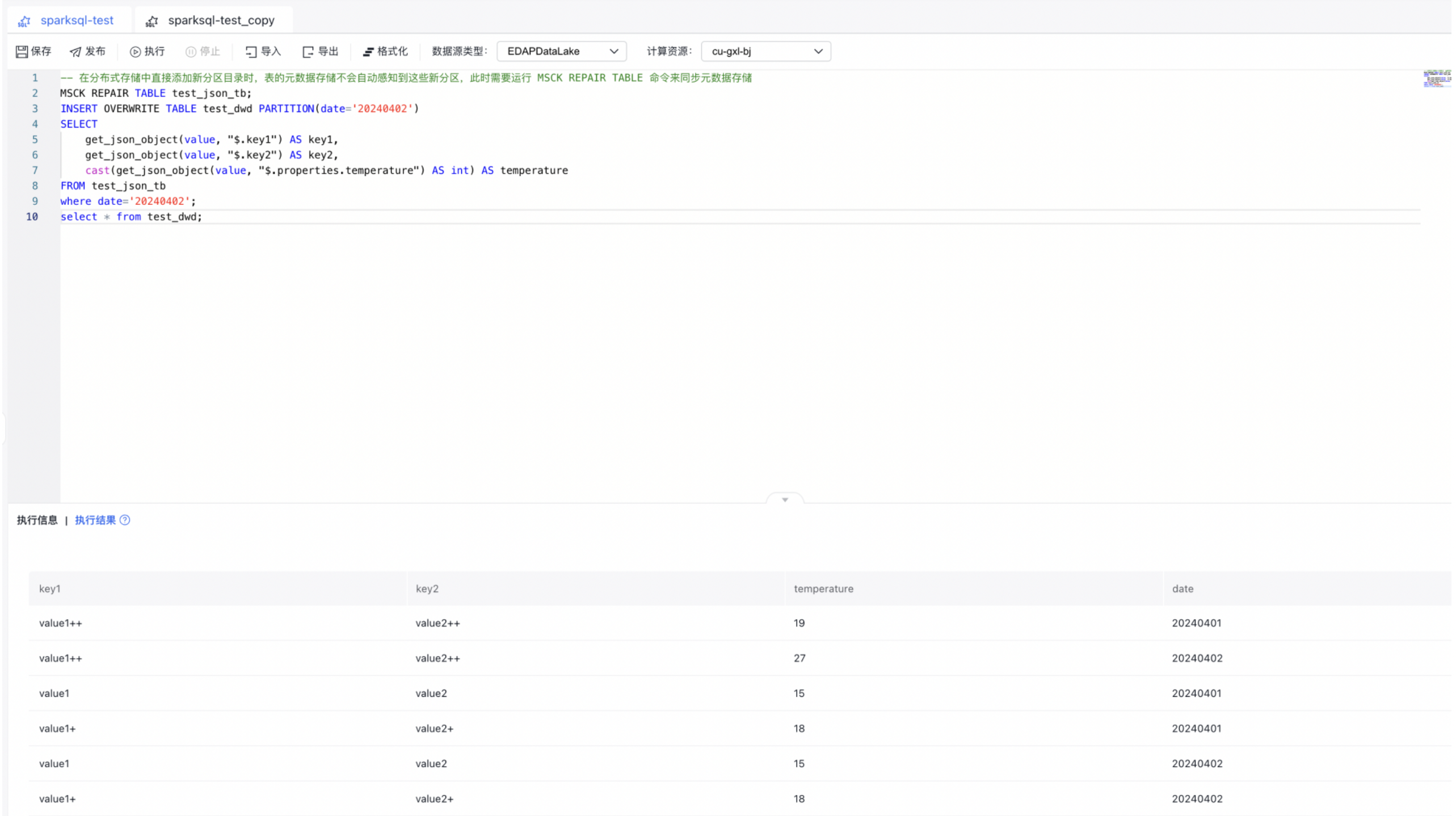 接下来将BOS数据写入RDS服务。在RDS服务中执行如下语句准备好database、table。
接下来将BOS数据写入RDS服务。在RDS服务中执行如下语句准备好database、table。
Plain Text
1CREATE DATABASE test_db;
2USE test_db;
3CREATE TABLE test_ads (
4 min_temperature int,
5 max_temperature int,
6 avg_temperature double,
7 date varchar(255)
8);执行如下SQL可将BOS数据经过聚合计算后写入RDS服务。注意:url字段填写RDS服务的内网IP。
Plain Text
1CREATE TEMPORARY VIEW jdbcTable
2USING jdbc
3OPTIONS (
4 url 'jdbc:mysql://192.168.64.20',
5 dbtable 'edap_test.test_ads',
6 user 'xx',
7 password 'xx'
8);
9INSERT INTO jdbcTable
10SELECT
11 min(temperature),
12 max(temperature),
13 avg(temperature),
14 date
15FROM test_dwd
16WHERE date='20240402'
17group by date;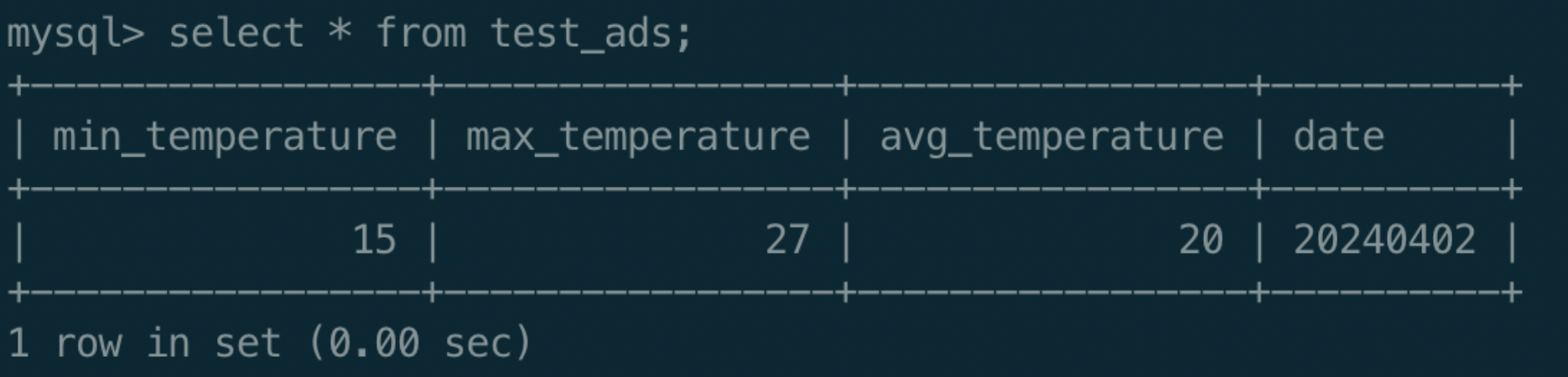
评价此篇文章