
EDAP非结构化数据入湖:使用pyspark提取pdf元信息下载并写入BOS存储
更新时间:2024-11-27
场景功能
基于非结构化文件在数据湖表中存储的元信息,使用PySpark任务批量拉取文件服务器中的pdf入湖。 本例中数据湖选用(DeltaLake)
数据湖元信息
Deltalake管理表

1.Schema
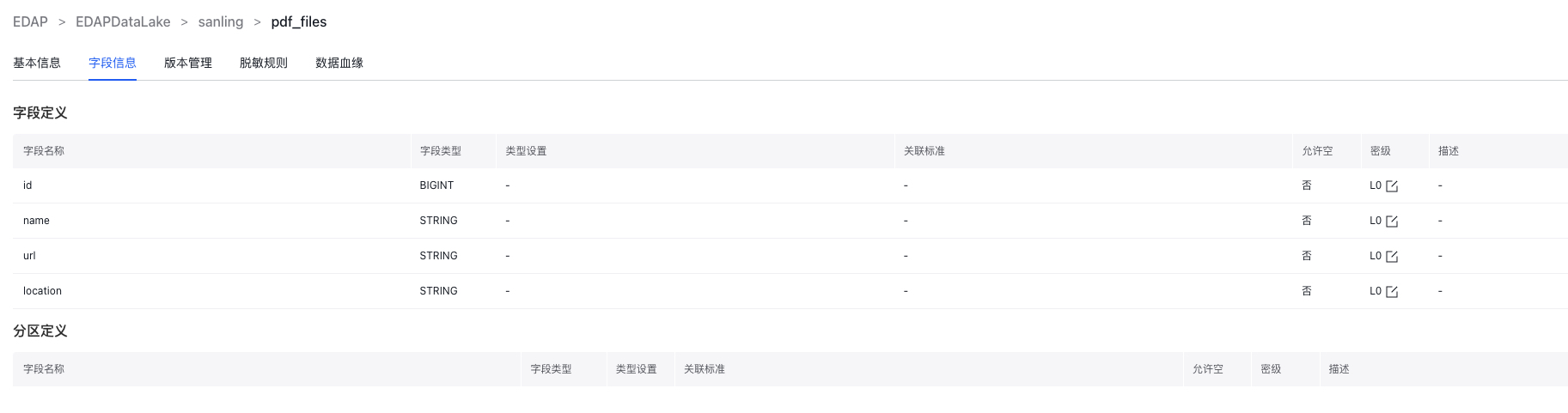
离线入湖
SDK依赖
执行资源BMR预装bce python sdk
PySpark
Plain Text
1import requests
2from baidubce.bce_client_configuration import BceClientConfiguration
3from baidubce.auth.bce_credentials import BceCredentials
4from baidubce import exception
5from baidubce.services import bos
6from baidubce.services.bos import canned_acl
7from baidubce.services.bos.bos_client import BosClient
8
9# bos
10bos_host = "bj.bcebos.com"
11access_key_id = "${access_key}"
12secret_access_key = "${secret_key}"
13config = BceClientConfiguration(credentials=BceCredentials(access_key_id, secret_access_key), endpoint = bos_host)
14bos_client = BosClient(config)
15bucket_name = "${bucket_name}"
16object_prefix = "${object_prefix}" # example: /upload/
17
18def process_row(row):
19 url = row.url
20 name = row.name
21 local_filename = name + ".pdf"
22
23 response = requests.get(url, stream=True)
24 response.raise_for_status()
25 with open(local_filename, 'wb') as file_handle:
26 for chunk in response.iter_content(chunk_size=8192):
27 file_handle.write(chunk)
28
29 object_key = object_prefix + local_filename
30 data = open(local_filename, 'rb')
31 bos_client.put_object_from_file(bucket_name, object_key, local_filename)
32 bos_location = f"bos://{bucket_name}{object_key}"
33 return (row.id, row.name, row.url, bos_location)
34
35
36df = spark.sql("select * from sanling.pdf_files")
37processed_rdd = df.rdd.map(process_row)
38processed_df = spark.createDataFrame(processed_rdd, df.schema)
39
40processed_df.write.mode("overwrite").insertInto("sanling.pdf_files")
41
42spark.sql("select * from sanling.pdf_files").show()引擎设置
Plain Text
1spark.hadoop.edap.endpoint=http://edap.bj.baidubce.com
2spark.hadoop.fs.AbstractFileSystem.bos.impl=org.apache.hadoop.fs.bos.BaiduBosFileSystemAdapter
3spark.hadoop.hive.metastore.client.class=com.baidubce.edap.catalog.metastore.EdapCatalogHiveClient
4spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog
5spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension评价此篇文章