
使用NVIDIA官方镜像运行模型-容器模式
更新时间:2022-12-01
1、概述
本文介绍,如何使用NVIDIA官方的L4T Base镜像搭配EasyEdge SDK实现云边协同模型下发。
2、生成模型包
- 创建run.sh,该文件为容器的启动文件
Plain Text
1#SDK序列号,需要在线申请,此处为测试序列号
2license_key=E60A-5124-5ACD-3C9B
3#curr_dir为/sdk,后续在BIE推断服务配置当中用到,作为容器内的工作目录
4curr_dir=/sdk
5demo_dir=${curr_dir}/cpp/sdk/demo/build
6lib_dir=${curr_dir}/cpp/sdk/lib
7res_dir=${curr_dir}/RES
8export LD_LIBRARY_PATH=${lib_dir}:${LD_LIBRARY_PATH}
9#run
10${demo_dir}/easyedge_serving ${res_dir} ${license_key}- 获取模型二进制运行程序
参考获得模型二进制运行程序。
3.将cpp目录、RES目录,以及run.sh文件打包成一个fruit-ai-model.zip文件。目录结构如下图所示:

- 此处是将多个目录和文件压缩为一个zip文件,而不是直接压缩最外层的那个目录。如果压缩层级不对,将导致模型下载到边缘设备以后解压的目录不匹配。
- 编译好的模型包参考:fruit-ai-model.zip
- 这个模型包必须部署在能够连接公网的设备上才能生效,因为需要在线激活。如果边缘节点无法联网,则模型无法正常加载运行。
3、上传模型文件包至对象存储
将模型文件包fruit-ai-model.zip上传至BOS。
4、云端配置
4.1. 创建边缘节点
如下图所示,创建边缘节点jetson-nano

4.2. 创建AI模型配置项
如下图所示,创建配置项:fruit-demo。引入上传至BOS对象存储的模型文件。
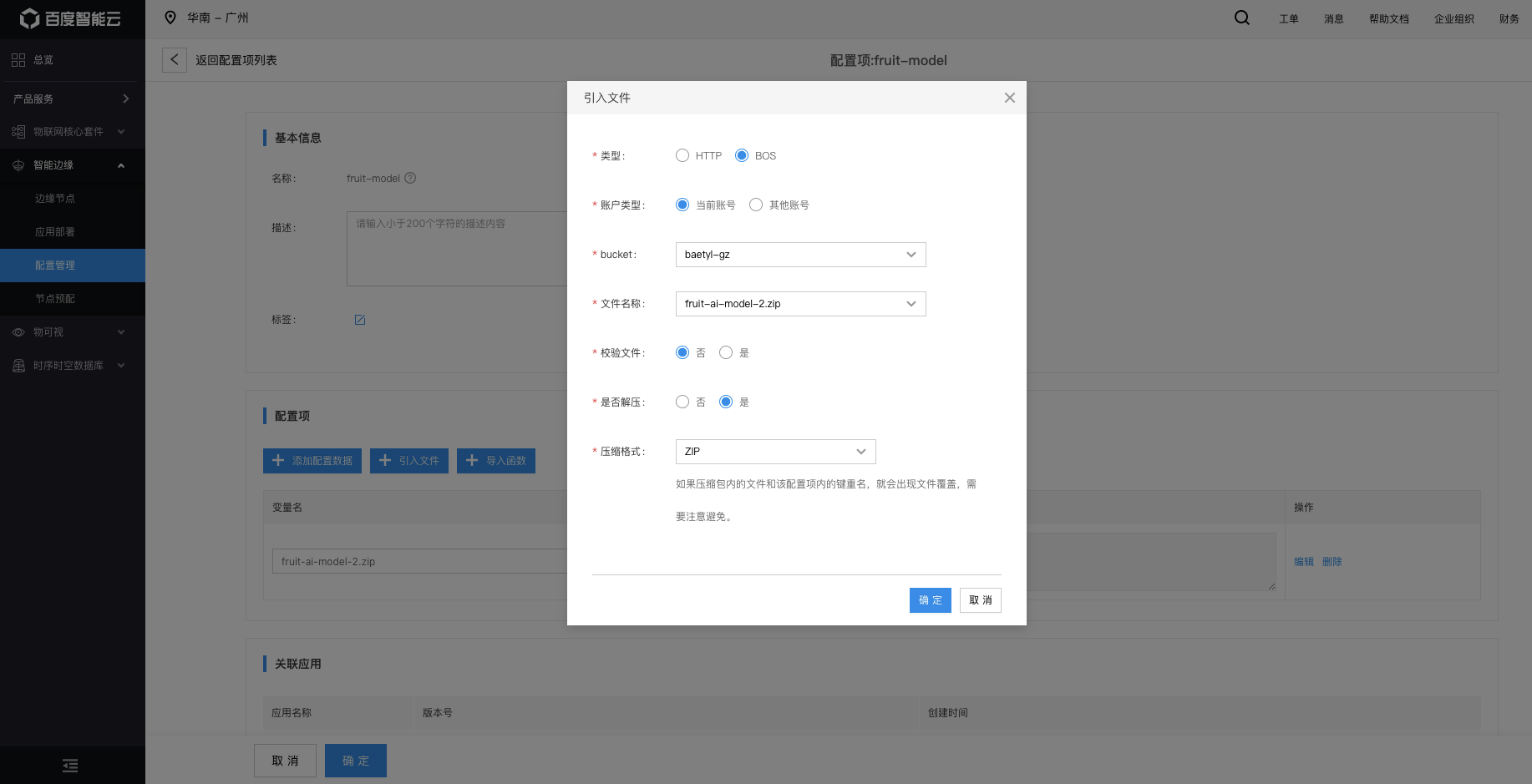
4.3. 创建AI推断服务
如下图所示,创建应用fruit-detection
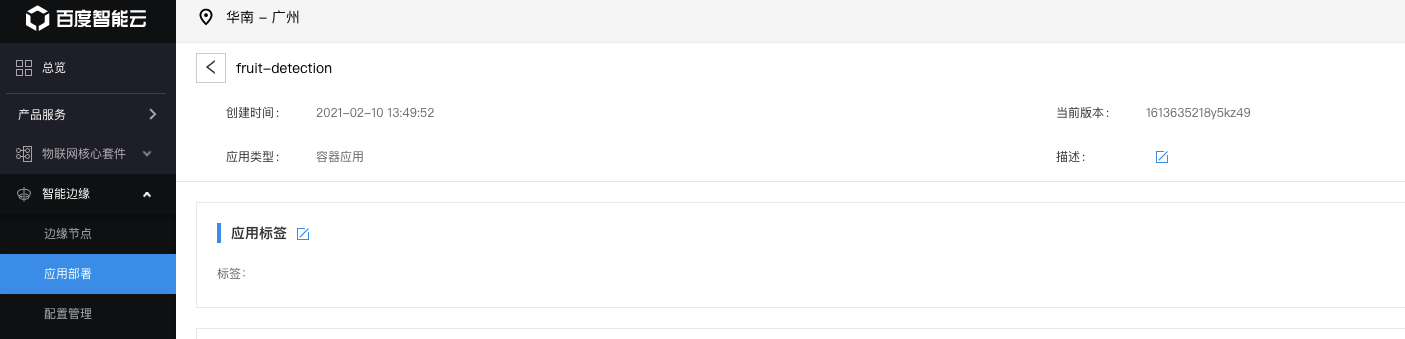
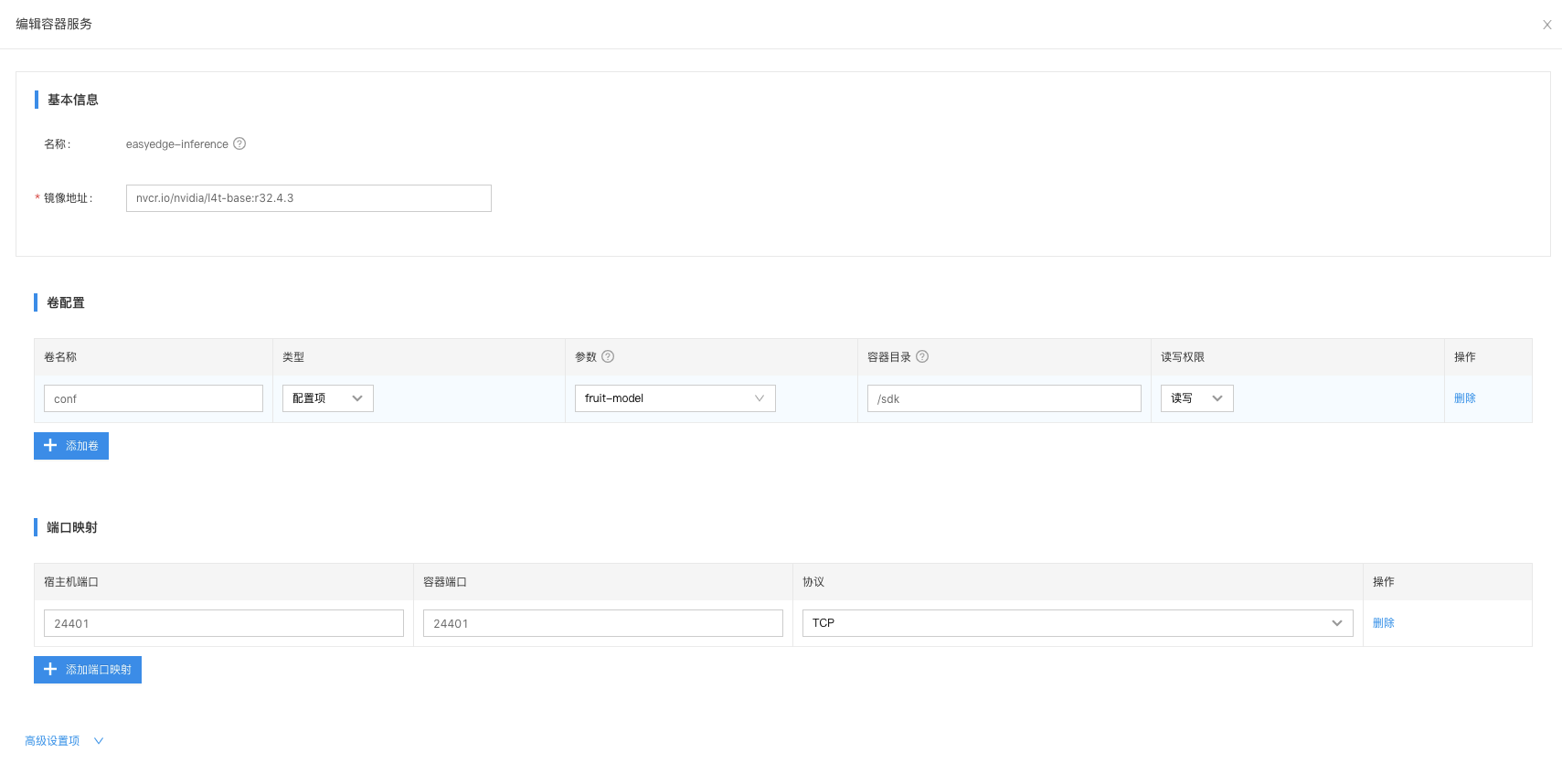
在应用当中添加一个容器服务,如下图所示:

-
镜像地址:
- nvidia提供了一个面向NVIDIA Jetson系列的容器镜像:NVIDIA L4T Base。nvidia官网获取方式:
https://ngc.nvidia.com/catalog/containers/nvidia:l4t-base - 该容器镜像提供nvidia jetson的运行环境,能够实现在容器内跑支持jetson设备的AI模型服务。在支持容器化以后,可以通过BIE来管理边缘节点设备,以及提升模型服务部署的效率。
- NVIDIA L4T Base官网镜像获取地址:
nvcr.io/nvidia/l4t-base:r32.4.3。如果国内下载速度很慢,可以从百度cce上下载镜像:hub.baidubce.com/nvidia/l4t-base:r32.4.3-arm64
- nvidia提供了一个面向NVIDIA Jetson系列的容器镜像:NVIDIA L4T Base。nvidia官网获取方式:
-
卷配置:
- 类型为配置项
- 参数选择之前创建的文件配置项
- 容器目录:/sdk(与run.sh文件对应)
- 通过卷配置,实现AI推断服务与模型文件绑定。将推断服务下发至边缘节点的时候,会自动下载AI模型文件。
-
容器服务的端口映射:
- 端口为24401
- 协议为TCP
-
容器服务的启动参数:
bash/sdk/run.sh
- 无需开启特权模式
4.4. 将应用部署至节点
在边缘应用当中,添加目标节点标签

5、边缘端配置
5.1 安装Jetson依赖
参考 Jetson依赖说明 。
5.2 运行安装命令
- copy云端边缘节点安装命令
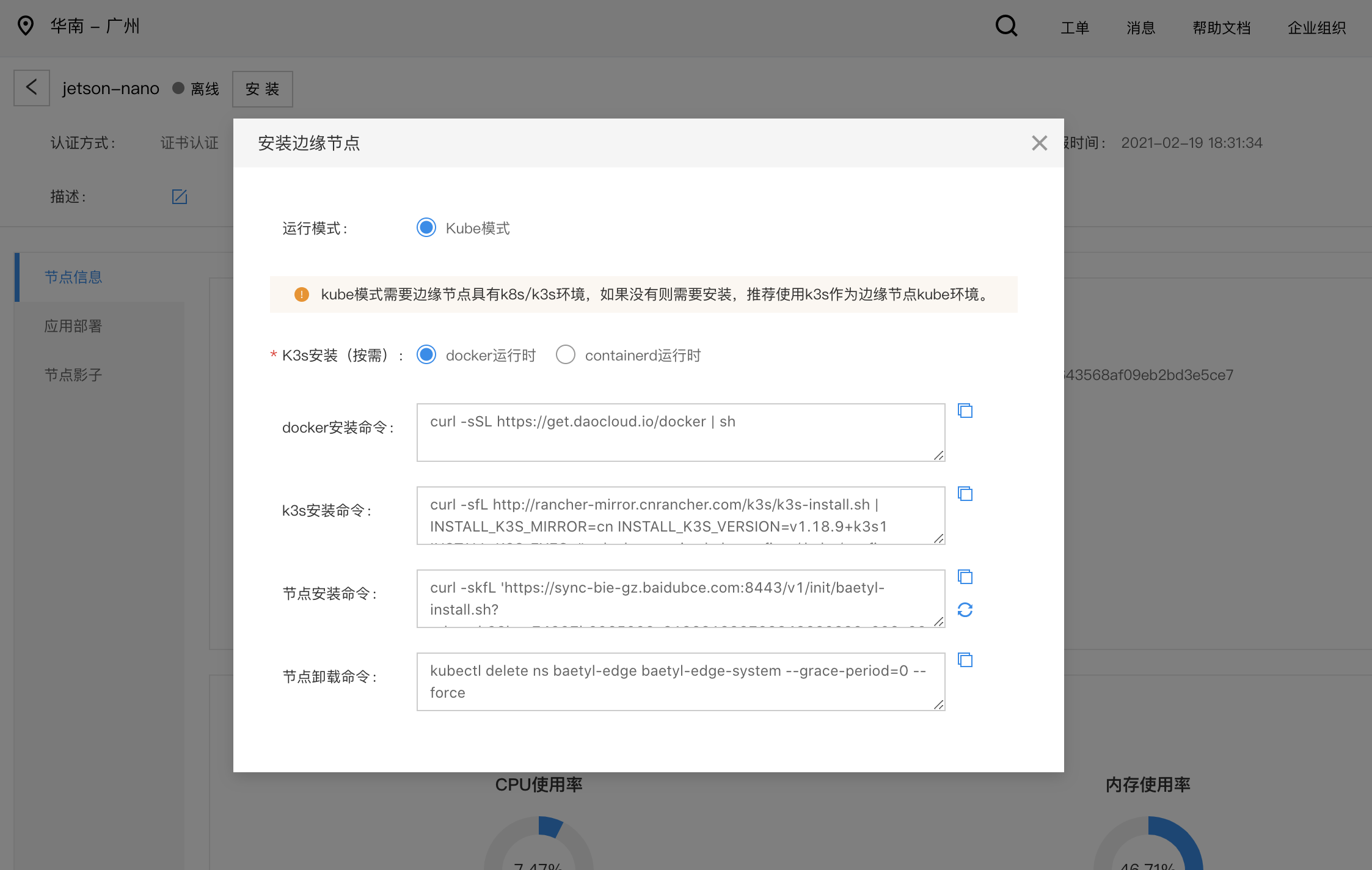
- 在边缘节点执行安装命令
6、验证边缘节点AI推断服务
通过浏览器打开在线推断服务:http://「ip」 :24401/,上传测试图片,推断结果如下,证明AI服务正常启动。

评价此篇文章