
挂载比特大陆边缘计算盒子tpu资源
更新时间:2021-12-24
场景
本demo说明了如何挂载tpu资源在比特大陆AI计算盒上进行运行人脸检测模型。
硬件
本demo用到了比特大陆的SOPHON AI计算盒SE5。这个是一款高性能、低功耗边缘计算产品,搭载比特大陆自主研发的第三代TPU芯片BM1684,INT8算力高达17.6TOPS,可同时处理16路高清视频,支持38路1080P高清视频硬件解码与2路编码。
AI计算盒SE5介绍官方链接:https://sophon.cn/product/introduce/se5.html
方案一:通过device-plugin动态加载tpu资源
device-plugin应用
- 创建bitmain-tpu-plugin-arm64应用
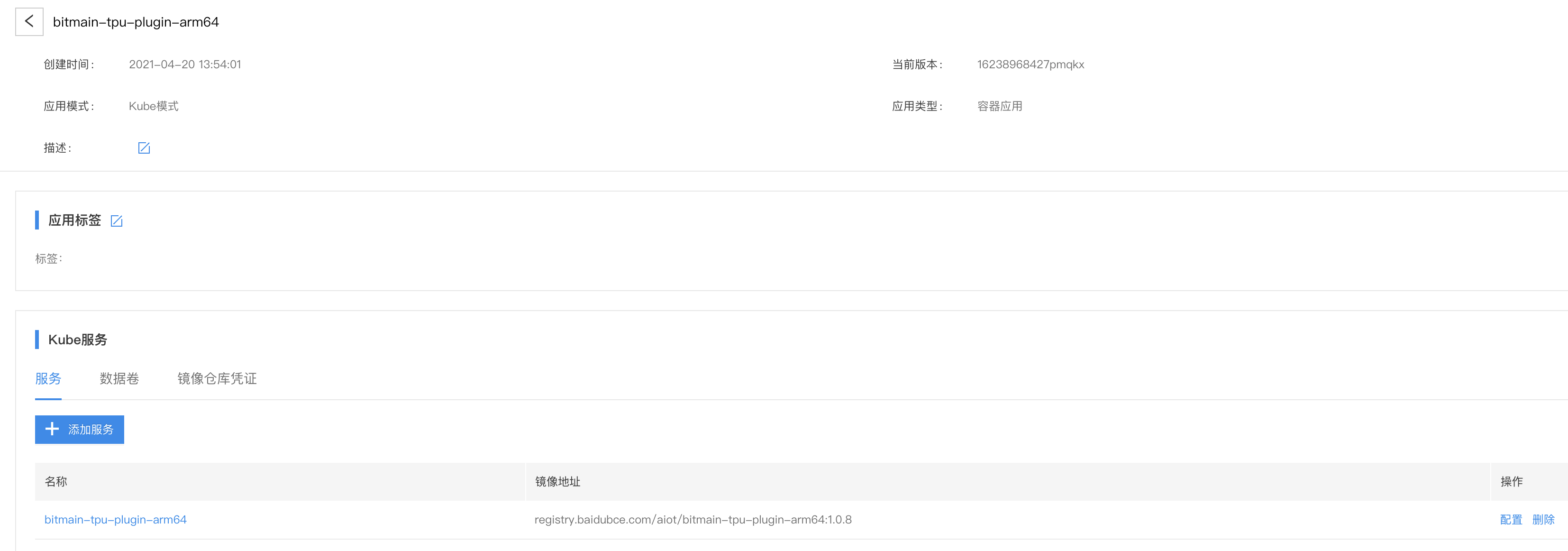
- 配置服务
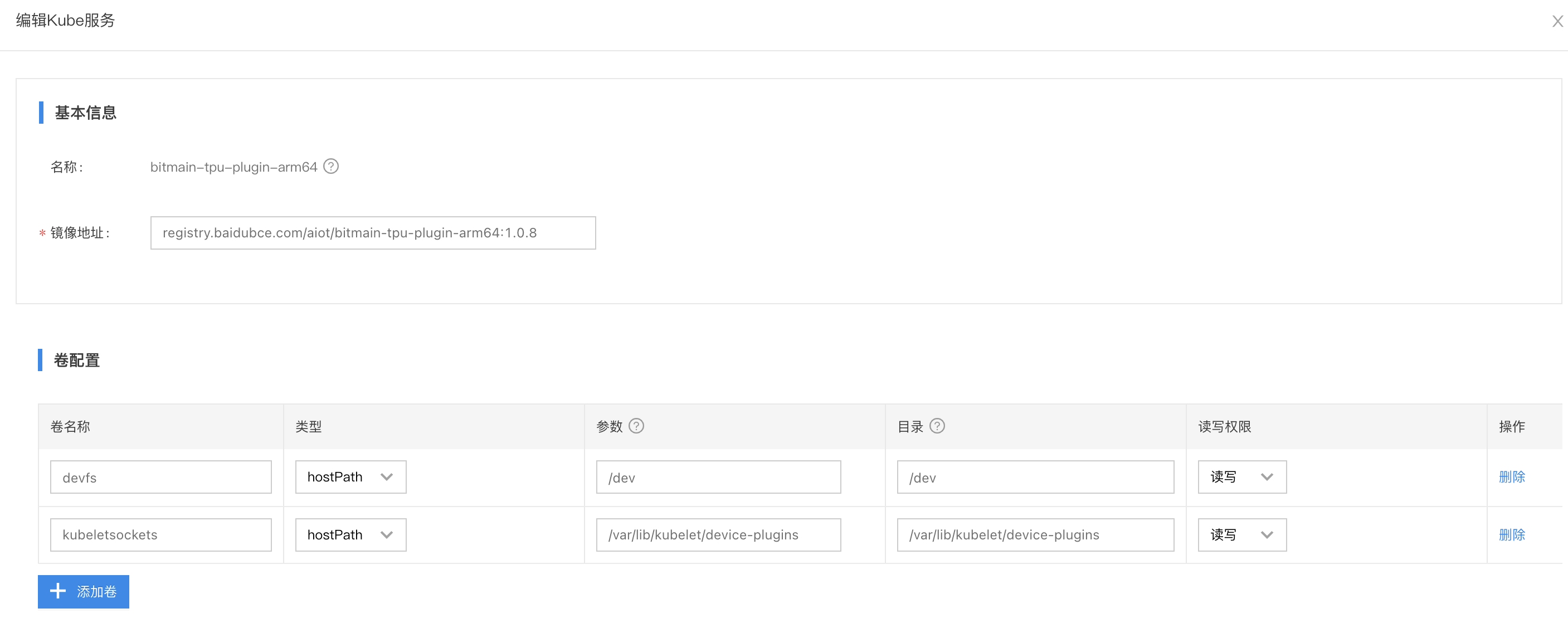


- 卷配置:挂载
/dev和/var/lib/kubelet/device-plugins- 负载类型:如果是集群,选择
DaemonSet,如果是单机模式,两种都可- 特权模式:
是
边缘AI应用
- 创建边缘AI应用
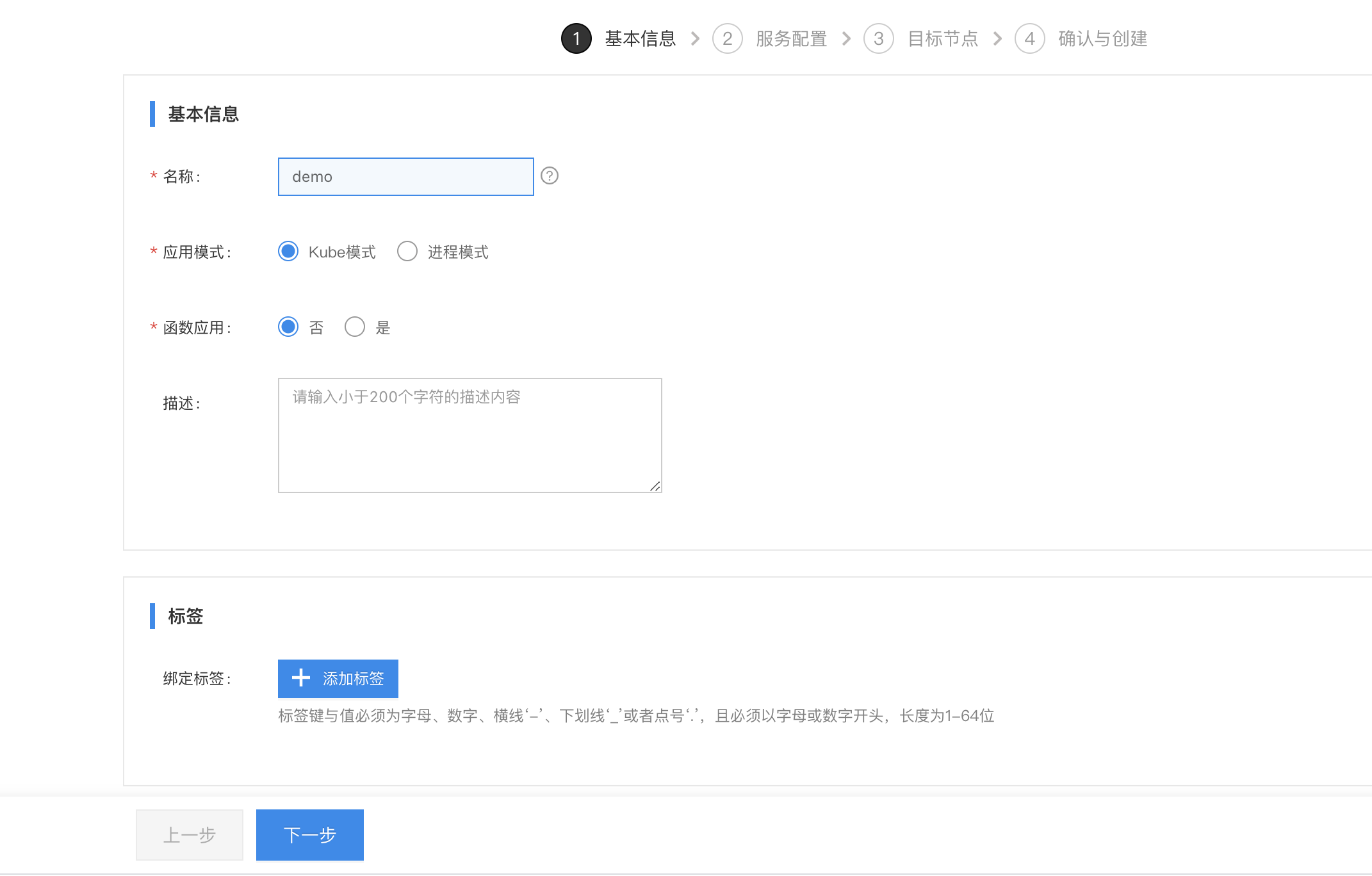
- 配置服务
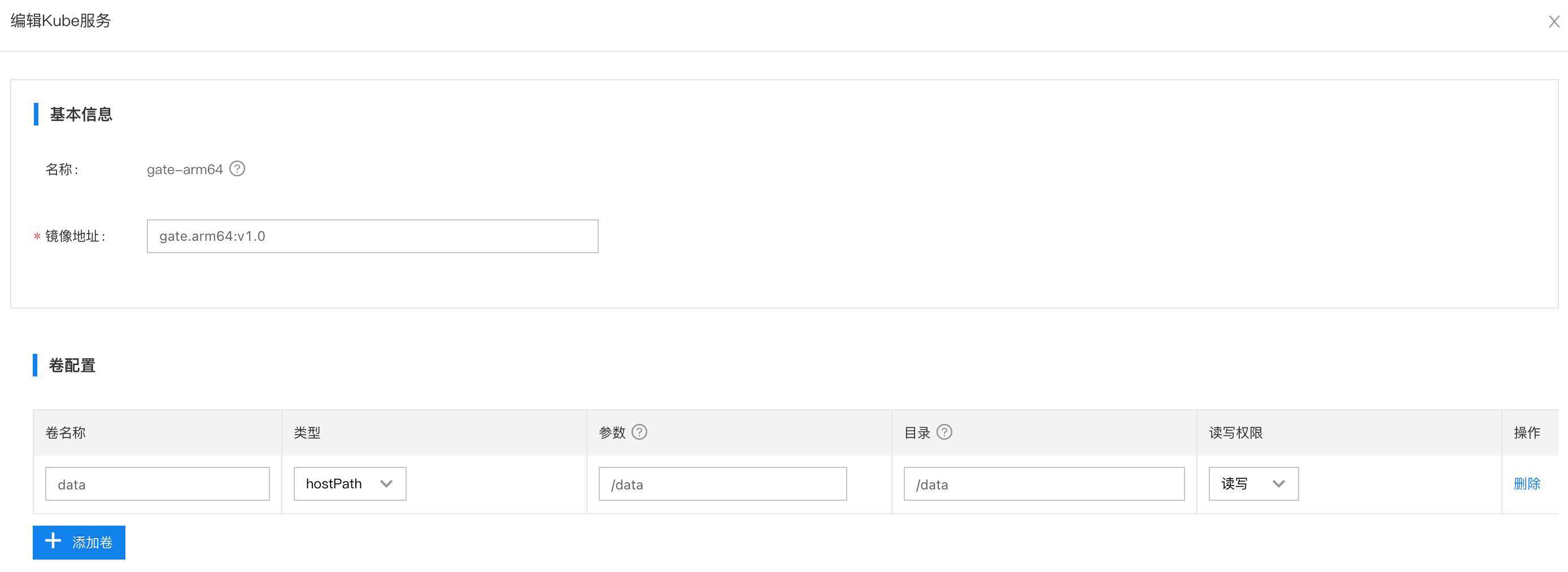
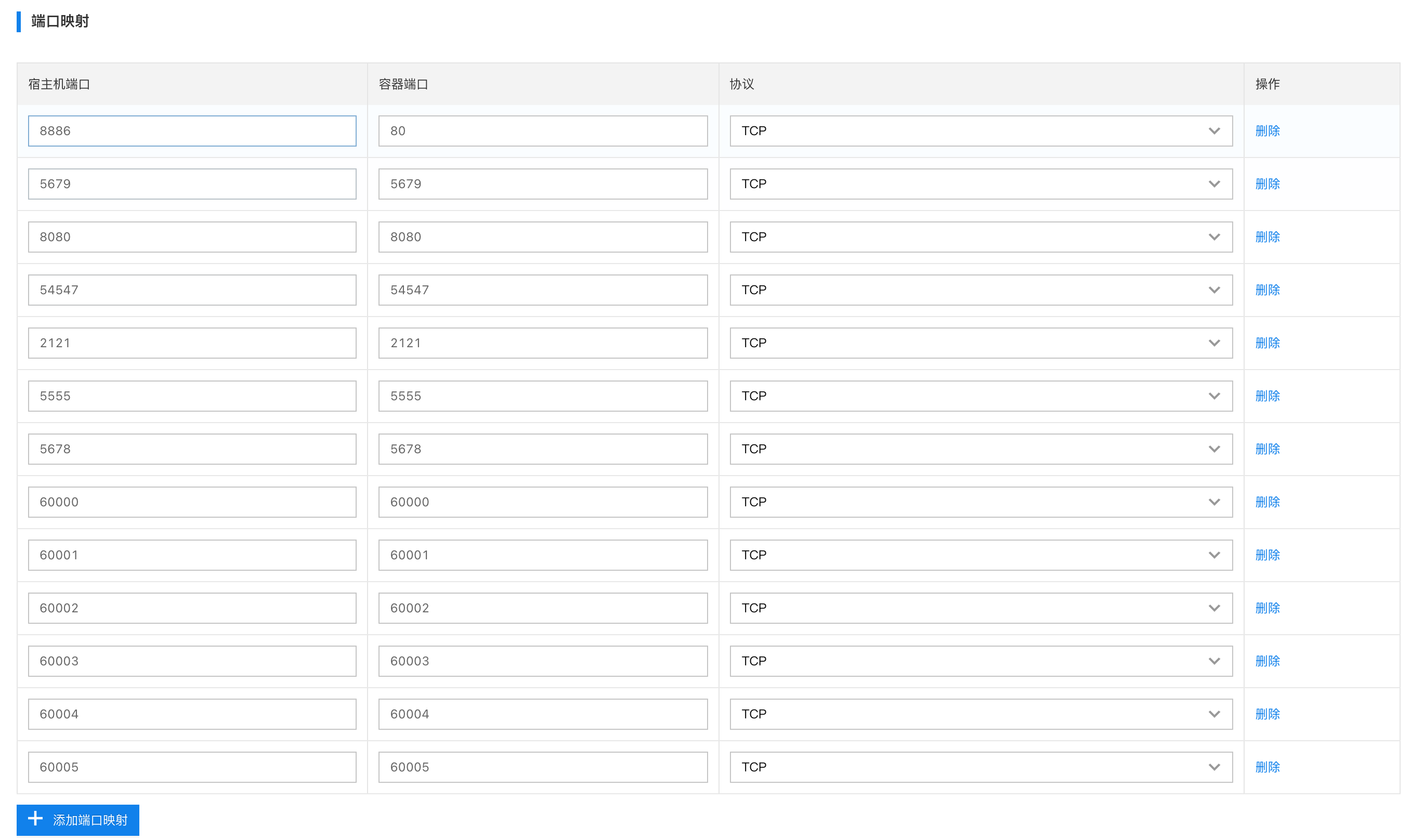
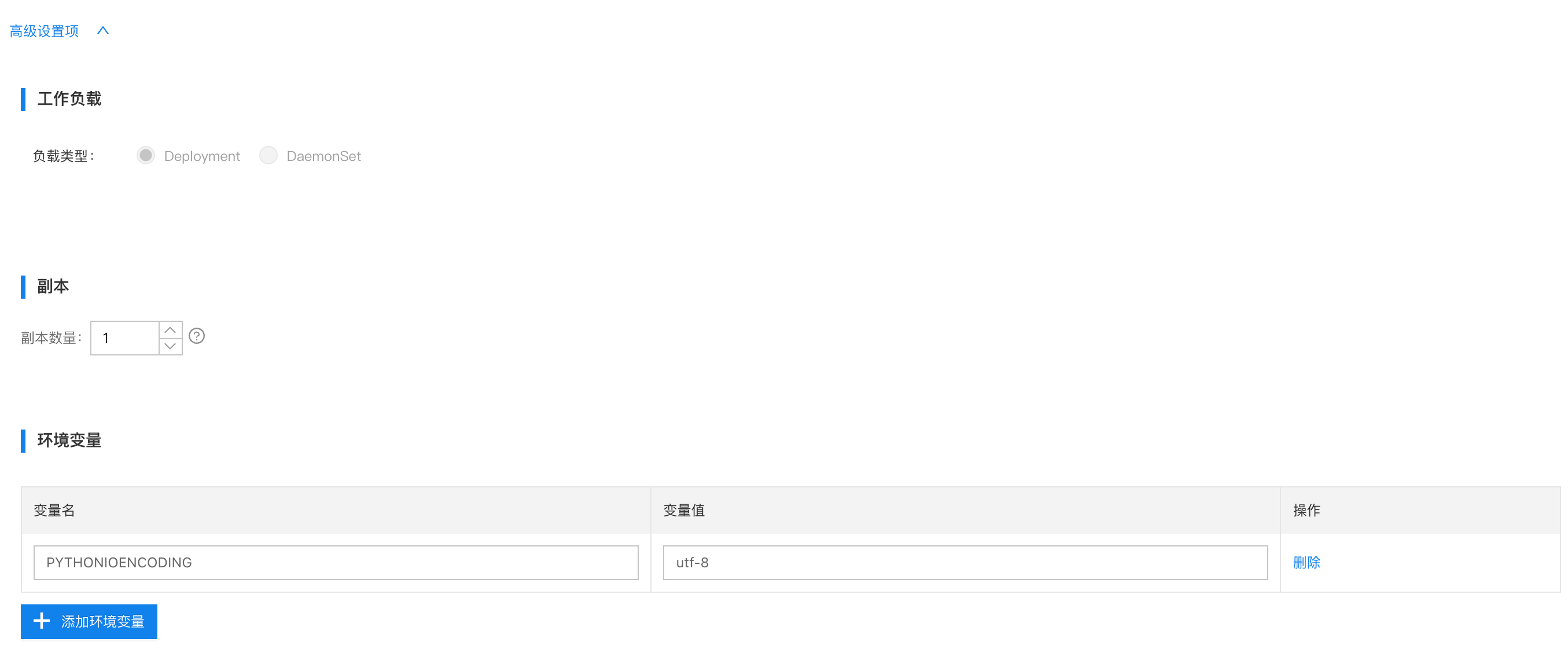
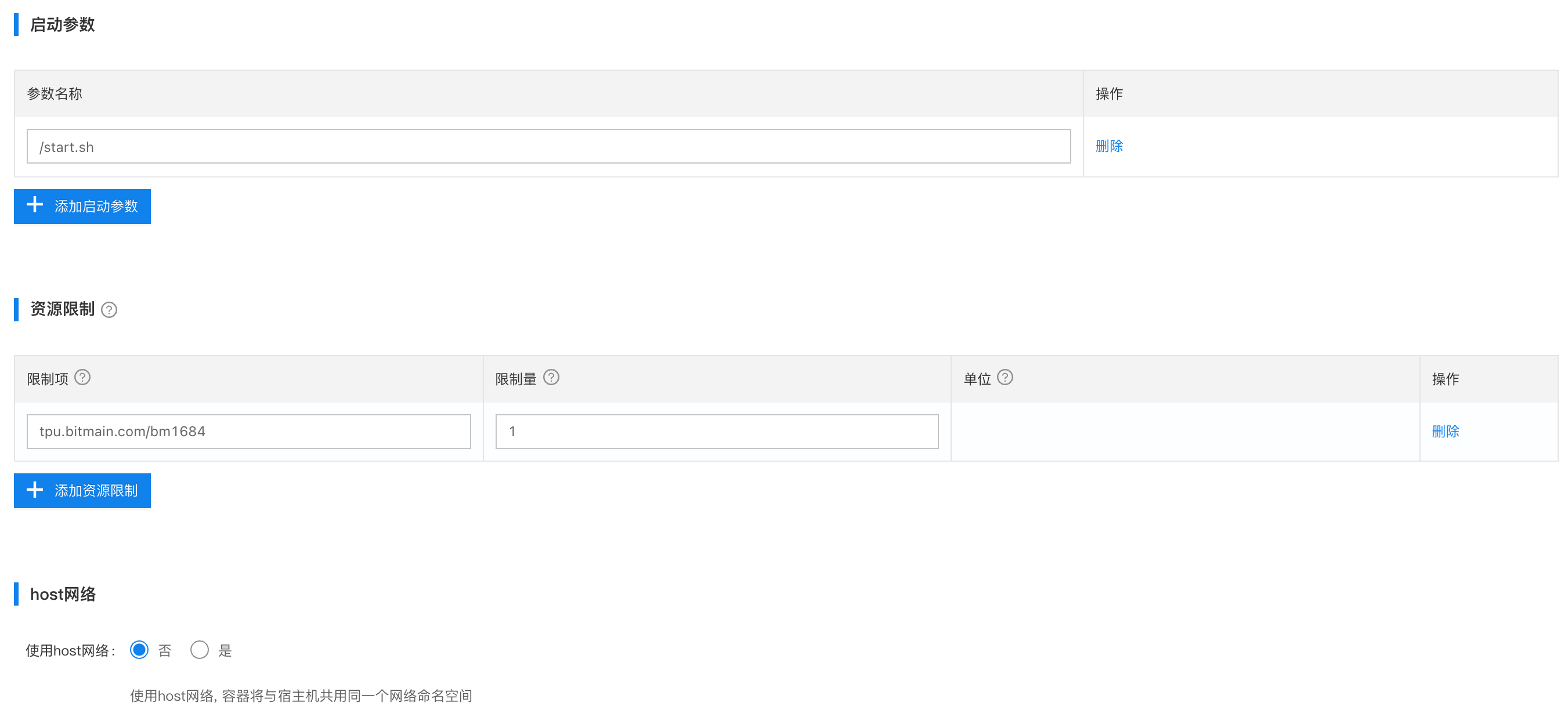

配置说明
- 卷配置:不需要挂载
/dev- 负载类型:选择
Deployment即可资源限制:
- 如果边缘服务(容器)要加载tpu算力,则限制项填写
tpu.bitmain.com/bm1684,限制量填写1,一个容器最多只能加载一个tpu算力资源,不支持跨卡跨芯片调用。- 当只有一个tpu资源时,如果限制量填写
2,则这个边缘服务(容器)将一直处于pending状态。同样如果再部署一个边缘服务(容器),也申请1个tpu,则那个边缘服务也将处于pending状态,因为tpu资源不够。- 假如这个设备有3张加速卡,每张加速卡有3颗tpu芯片,则最多可以让9个边缘服务(容器)都申请到1个tpu资源。
- 如果希望多个模型希望共用1个tpu算力,则需要将多个模型打包在一个容器内,再去统一去申请1个tpu资源(前提是1张tpu的显存能够同时加载多个模型)。针对只有1个tpu算力卡的场景,使用方案2会更加合适,方案2支持多个容器同时挂载/dev/,实现算力卡共享。
- 特权模式:不需要特权模式,选择
否
方案二:通过设备映射加载tpu资源
该方案只需要配置边缘AI应用本身,不需要device-plugin应用。
- 创建边缘AI应用
- 配置边缘AI服务
让边缘容器加载tpu算力的配置指南:
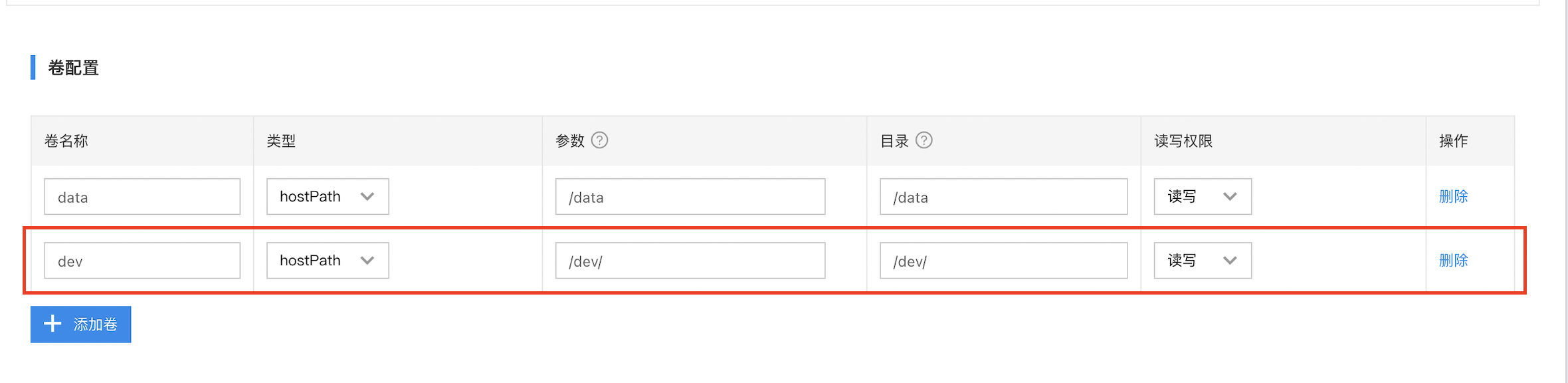
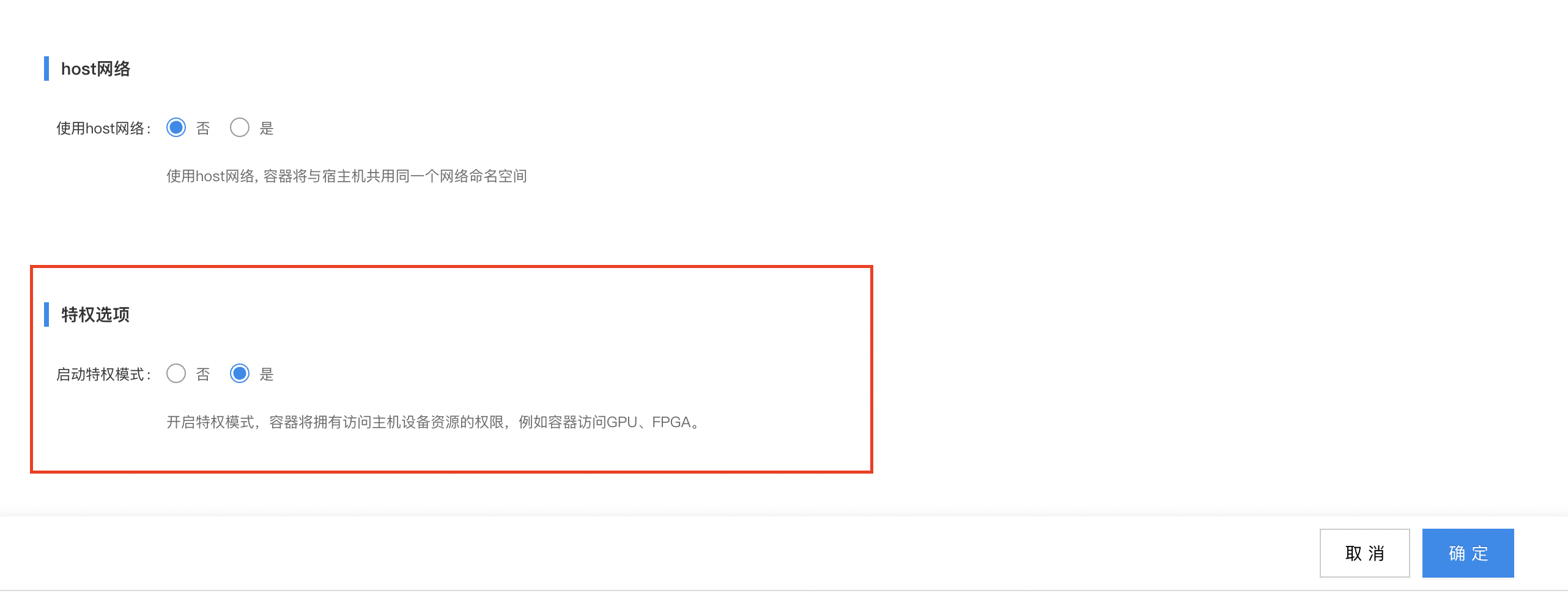
- 卷配置:需要挂载设备映射
/dev/- 特权选项:选择
是- 镜像是基于比特大陆SDK开发的模型镜像,用于加载tpu算力卡,可联系比特大陆厂商获取SDK。
- 针对只有1个tpu算力卡的场景,如果有多个容器都需要使用算力卡,多容器可以同时挂载/dev/,算力卡支持多进程,实现算力卡资源共享。
边缘验证
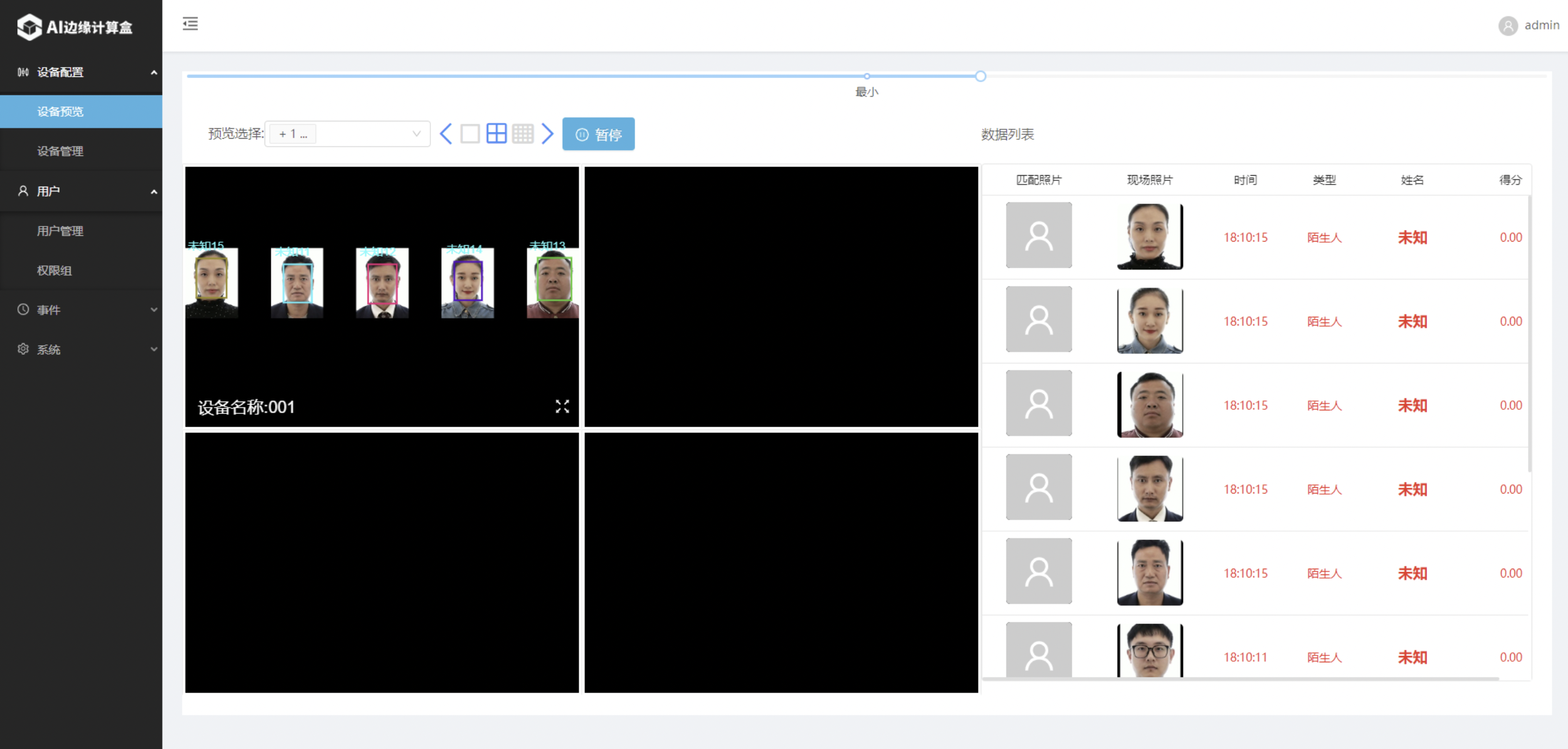
打开边缘AI应用,查看边缘AI推断情况,如下图所示,tpu算力正常加载,边缘AI推断正常执行。
评价此篇文章